你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
将数据移到 Azure Blob 存储
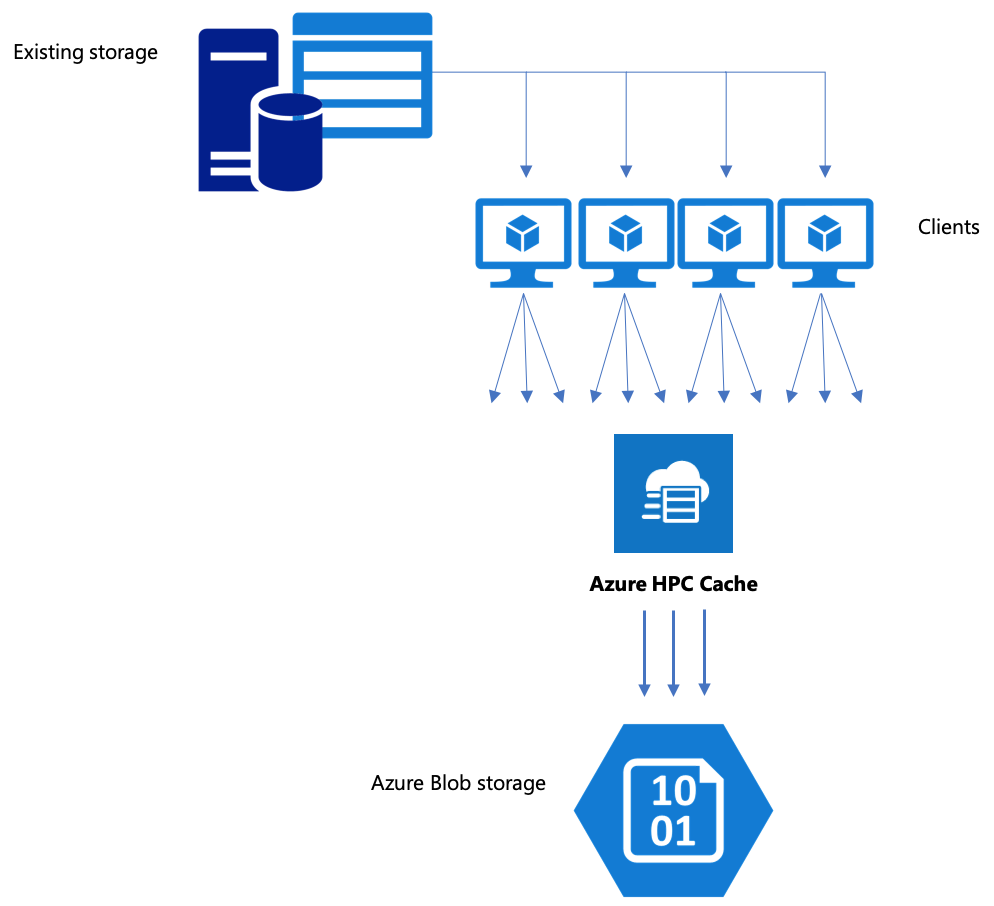
如果工作流中包括将数据移动到 Azure Blob 存储,确保采用有效的策略操作。 应创建缓存,将 Blob 容器添加为存储目标,然后使用 Azure HPC 缓存复制数据。
本文介绍将数据移动到 blob 存储以用于 Azure HPC 缓存的最佳方式。
提示
本文不适用于已安装 NFS 的 blob 存储(ADLS-NFS 存储目标)。 在将 ADLS-NFS blob 容器添加到 HPC 缓存之前或之后,可以使用任何基于 NFS 的方法填充该容器。 请参阅预加载数据与 NFS 协议以了解详细信息。
请注意以下内容:
Azure HPC 缓存会使用专门的存储格式来组织 blob 存储中的数据。 因此,blob 存储目标必须是新的空容器,或者是以前用于 Azure HPC 缓存数据的 blob 容器。
当使用多个客户端和并行操作时,通过 Azure HPC 缓存将数据复制到后端存储目标,效率将更高。 从一个客户端发出的简单的复制命令将缓慢地移动数据。
本文中概述的策略适用于填充空 Blob 容器或将文件添加到以前使用的存储目标。
通过 Azure HPC 缓存复制数据
Azure HPC 缓存可同时服务多个客户端,因此,若要通过缓存复制数据,应使用多个客户端的并行写入。
专门用于将数据从一个存储系统传输到另一个存储系统的 cp 和 copy 命令是单线程进程,它们每次只复制一个文件。 这意味着,文件服务器每次只会引入一个文件 - 这给群集资源造成了浪费。
本部分介绍了使用 Azure HPC 缓存创建多客户端、多线程文件复制系统以将数据移到 blob 存储的有效策略。 其中解释了文件传输的概念,以及可用于有效通过多个客户端和简单复制命令来复制数据的决策点。
此外,本文还介绍了一些有用的实用工具。 msrsync 实用工具可用于部分自动化将数据集分割成桶和使用 rsync 命令的过程。 parallelcp 脚本是可以读取源目录和自动发出复制命令的另一个实用工具。
策略规划
在制定并行复制数据的策略时,应该知道如何在文件大小、文件计数和目录深度方面做出取舍。
- 如果文件较小,应该关注的指标是每秒文件数。
- 如果文件较大(10MiBi 或更大),则应该关注的指标是每秒字节数。
每个复制进程都有相关的吞吐率和文件传输速率,可以通过计量复制命令的时长和分解文件大小与文件计数来测量这些参数。 有关如何测量速率超出了本文档的范畴,但必须了解要处理的是小型还是大型文件。
通过 Azure HPC 缓存引入并行数据的策略包括:
手动复制 - 可以通过针对预定义的文件或路径集在后台一次性运行多个复制命令,在客户端上手动创建多线程复制。 有关详细信息,请参阅 Azure HPC 缓存数据引入 - 手动复制方法。
部分自动复制
msrsync-msrsync是一个运行多个并行rsync进程的包装实用工具。 有关详细信息,请参阅 AZURE HPC 缓存数据引入 - msrsync 方法。使用脚本复制
parallelcp- 在 Azure HPC 缓存数据引入 - 并行复制脚本方法中了解如何创建和运行并行复制脚本。
后续步骤
设置存储后,了解客户端如何装载缓存。