你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Azure Toolkit for IntelliJ 通过 VPN 在 HDInsight 中远程调试 Apache Spark 应用程序
我们建议通过 SSH 远程调试 Apache Spark 应用程序。 有关说明,请参阅使用 Azure Toolkit for IntelliJ 通过 SSH 远程调试 HDInsight 群集上的 Apache Spark 应用程序。
本文提供有关如何在 HDInsight Spark 群集上使用用于 IntelliJ 的 Azure 工具包中的 HDInsight 工具插件提交 Spark 作业,并从台式机远程调试该作业的逐步指导。 若要完成这些任务,必须执行以下概要步骤:
- 创建站点到站点或点到站点 Azure 虚拟网络。 本文档中的步骤假设你使用站点到站点网络。
- 在 HDInsight 中创建属于站点到站点虚拟网络一部分的 Spark 群集。
- 验证群集头节点与台式机之间的连接。
- 在 IntelliJ IDEA 中创建 Scala 应用程序,并对它进行配置以进行远程调试。
- 运行和调试应用程序。
必备条件
- Azure 订阅。 有关详细信息,请参阅获取 Azure 免费试用版。
- HDInsight 中的 Apache Spark 群集。 有关说明,请参阅在 Azure HDInsight 中创建 Apache Spark 群集。
- Oracle Java 开发工具包。 可以从 Oracle 网站安装该工具包。
- IntelliJ IDEA。 本文使用版本 2017.1。 可以从 JetBrains 网站进行安装。
- Azure Toolkit for IntelliJ 中的 HDInsight 工具。 用于 IntelliJ 的 Azure 工具包随附了用于 IntelliJ 的 HDInsight 工具。 有关 Azure 工具包的安装方法说明,请参阅安装用于 IntelliJ 的 Azure 工具包。
- 从 IntelliJ IDEA 登录到 Azure 订阅。 遵照使用 Azure Toolkit for IntelliJ 为 HDInsight 群集创建 Apache Spark 应用程序中的说明操作。
- 异常解决方法。 在 Windows 计算机上运行 Spark Scala 应用程序进行远程调试时,可能会出现异常。 SPARK-2356 中解释了此异常,其原因是 Windows 中缺少 WinUtils.exe 文件。 若要解决此错误,必须将 Winutils.exe 下载到某个位置(例如 C:\WinUtils\bin)。 添加环境变量 HADOOP_HOME,并将其值设置为 C\WinUtils。
步骤 1:创建 Azure 虚拟网络
遵照以下链接中的说明创建 Azure 虚拟网络,并验证台式机与虚拟网络之间的连接。
步骤 2:创建 HDInsight Spark 群集
我们建议额外在 Azure HDInsight 上创建属于所创建 Azure 虚拟网络一部分的 Apache Spark 群集。 请参考在 HDInsight 中创建基于 Linux 的群集中提供的信息。 选择在上一步骤中创建的 Azure 虚拟网络作为可选配置的一部分。
步骤 3:验证群集头节点与台式机之间的连接。
获取头节点的 IP 地址。 打开群集的 Ambari UI。 在群集边栏选项卡中,选择“仪表板” 。
在 Ambari UI 中,选择“主机”。

此时会显示头节点、工作节点和 zookeeper 节点的列表。 头节点带有 hn* 前缀。 选择第一个头节点。
在打开的页面底部的“摘要”窗格中,复制头节点的“IP 地址”和“主机名”。
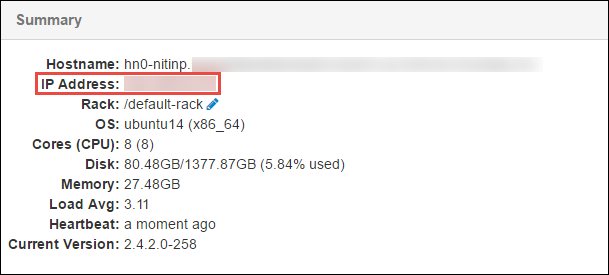
将头节点的 IP 地址和主机名添加到要从中运行和远程调试 Spark 作业的计算机上的 hosts 文件中。 这样,便可以使用 IP 地址和主机名来与头节点通信。
a. 以提升的权限打开一个记事本文件。 在“文件”菜单中选择“打开” ,并找到 hosts 文件的位置。 在 Windows 计算机上,该位置为 C:\Windows\System32\Drivers\etc\hosts。
b. 将以下信息添加到 hosts 文件:
# For headnode0 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.net # For headnode1 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.net在连接到 HDInsight 群集所用 Azure 虚拟网络的计算机中,验证是否能够使用该 IP 地址和主机名 ping 通两个头节点。
遵照使用 SSH 连接到 HDInsight 群集中的说明,使用 SSH 连接到群集头节点。 从群集头节点,对台式机的 IP 地址执行 ping 操作。 测试是否能够连接到分配给计算机的两个 IP 地址:
- 一个是网络连接的地址
- 另一个是 Azure 虚拟网络的地址
针对另一个头节点重复上述步骤。
步骤 4:使用 Azure Toolkit for IntelliJ 中的 HDInsight 工具创建 Apache Spark Scala 应用程序,并对其进行配置以远程调试
打开 IntelliJ IDEA 并创建一个新项目。 在“新建项目” 对话框中执行以下操作:
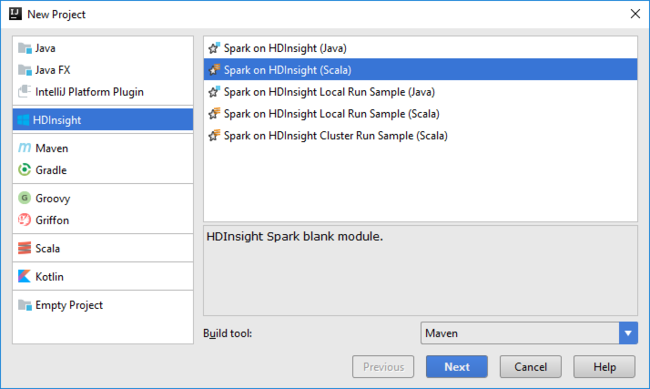
a. 选择“HDInsight” > “Spark on HDInsight (Scala)”
b. 选择“下一页”。
在接下来显示的“新建项目” 对话框中执行以下操作,并选择“完成”:
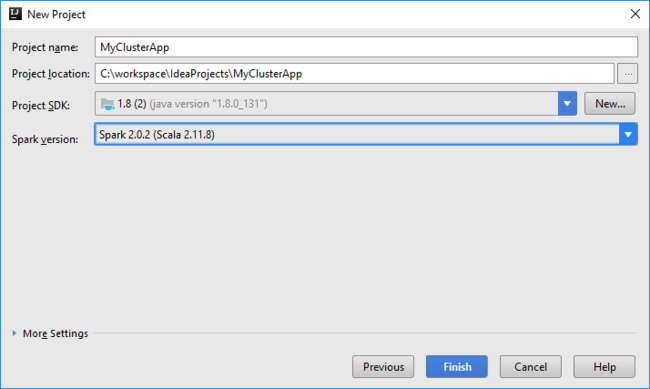
输入项目名称和位置。
在“项目 SDK”下拉列表中,选择“Java 1.8”(适用于 Spark 2.x 群集),或选择“Java 1.7”(适用于 Spark 1.x 群集) 。
在“Spark 版本”下拉列表中,Scala 项目创建向导集成了 Spark SDK 和 Scala SDK 的适当版本。 如果 Spark 群集版本低于 2.0,请选择“Spark 1.x” 。 否则,请选择“Spark 2.x” 。 此示例使用“Spark 2.0.2 (Scala 2.11.8)” 。
Spark 项目自动为你创建项目。 若要查看项目,请执行以下操作:
a. 在“文件” 菜单中,选择“项目结构” 。
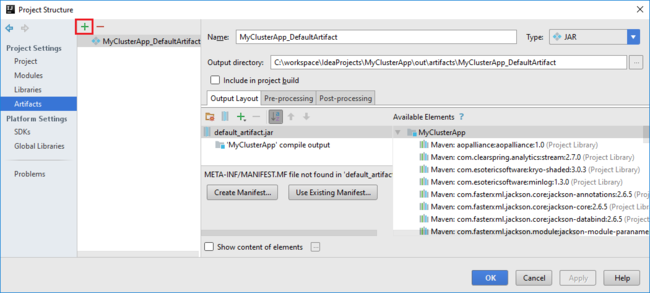
b. 在“项目结构”对话框中,选择“项目”以查看创建的默认项目 。 也可以通过选择加号 (+) 来创建自己的项目 。
将库添加到项目。 若要添加库,请执行以下操作:
a. 在项目树中右键单击项目名称,并单击“打开模块设置” 。
b. 在“项目结构”对话框中选择“库”,选择 (+) 符号,并选择“从 Maven”。
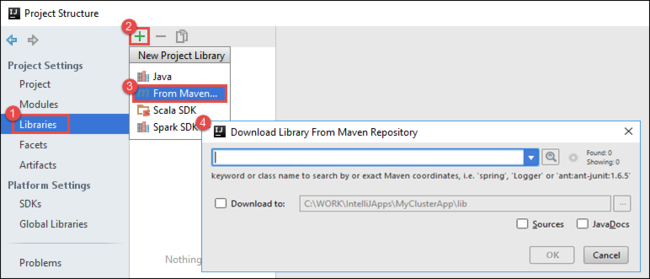
c. 在“从 Maven 存储库下载库” 对话框中,搜索并添加以下库:
org.scalatest:scalatest_2.10:2.2.1org.apache.hadoop:hadoop-azure:2.7.1
从群集头节点复制
yarn-site.xml和core-site.xml并将其添加到项目。 使用以下命令来复制文件。 可以使用 Cygwin 运行以下scp命令,以便从群集头节点复制文件:scp <ssh user name>@<headnode IP address or host name>://etc/hadoop/conf/core-site.xml .由于已将群集头节点 IP 地址和主机名添加到台式机上的 hosts 文件,因此可按以下方式使用
scp命令:scp sshuser@nitinp:/etc/hadoop/conf/core-site.xml . scp sshuser@nitinp:/etc/hadoop/conf/yarn-site.xml .若要将这些文件添加到项目,请将这些文件复制到项目树中的 /src 文件夹下(例如
<your project directory>\src)。更新
core-site.xml文件以进行以下更改:a. 替换加密的密钥。
core-site.xml文件包含与群集关联的存储帐户的已加密密钥。 在已添加到项目的core-site.xml文件中,将已加密密钥替换为与默认存储帐户关联的实际存储密钥。 有关详细信息,请参阅管理存储帐户访问密钥。<property> <name>fs.azure.account.key.hdistoragecentral.blob.core.windows.net</name> <value>access-key-associated-with-the-account</value> </property>b. 从
core-site.xml中删除以下条目:<property> <name>fs.azure.account.keyprovider.hdistoragecentral.blob.core.windows.net</name> <value>org.apache.hadoop.fs.azure.ShellDecryptionKeyProvider</value> </property> <property> <name>fs.azure.shellkeyprovider.script</name> <value>/usr/lib/python2.7/dist-packages/hdinsight_common/decrypt.sh</value> </property> <property> <name>net.topology.script.file.name</name> <value>/etc/hadoop/conf/topology_script.py</value> </property>c. 保存文件。
添加应用程序的 main 类。 在“项目资源管理器”中,右键单击“src”,指向“新建”,并选择“Scala 类”。
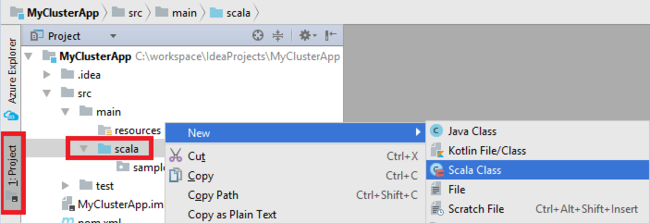
在“新建 Scala 类” 对话框中提供名称,在“种类” 对话框中选择“对象” ,并选择“确定” 。
在
MyClusterAppMain.scala文件中粘贴以下代码。 此代码创建 Spark 上下文,并从SparkSample对象打开executeJob方法。import org.apache.spark.{SparkConf, SparkContext} object SparkSampleMain { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkSample") .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }重复步骤 8 和 9,添加名为
*SparkSample的新 Scala 对象。 将以下代码添加到此类。 此代码从 HVAC.csv(用于所有 HDInsight Spark 群集)中读取数据。 它会检索在 CSV 文件的第七列中只有一个数字的行,并将输出写入群集的默认存储容器下的 /HVACOut。import org.apache.spark.SparkContext object SparkSample { def executeJob (sc: SparkContext, input: String, output: String): Unit = { val rdd = sc.textFile(input) //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) val s = sc.parallelize(rdd.take(5)).cartesian(rdd).count() println(s) rdd1.saveAsTextFile(output) //rdd1.collect().foreach(println) } }重复步骤 8 和 9,添加名为
RemoteClusterDebugging的新类。 此类实现用于调试应用程序的 Spark 测试框架。 将以下代码添加到RemoteClusterDebugging类:import org.apache.spark.{SparkConf, SparkContext} import org.scalatest.FunSuite class RemoteClusterDebugging extends FunSuite { test("Remote run") { val conf = new SparkConf().setAppName("SparkSample") .setMaster("yarn-client") .set("spark.yarn.am.extraJavaOptions", "-Dhdp.version=2.4") .set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar") .setJars(Seq("""C:\workspace\IdeaProjects\MyClusterApp\out\artifacts\MyClusterApp_DefaultArtifact\default_artifact.jar""")) .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }需要注意几个要点:
- 对于.
.set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar"),请确保 Spark 程序集 JAR 可在指定路径上的群集存储中使用。 - 对于
setJars,请指定项目 JAR 的创建位置。 这通常是<Your IntelliJ project directory>\out\<project name>_DefaultArtifact\default_artifact.jar。
- 对于.
在
*RemoteClusterDebugging类中,右键单击test关键字,并选择“创建 RemoteClusterDebugging 配置”。
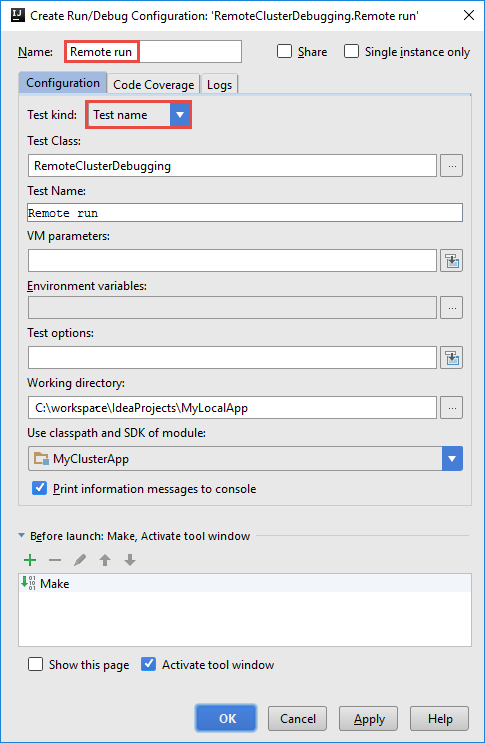
在“创建 RemoteClusterDebugging 配置”对话框中,为配置提供名称,并选择选择“测试种类”作为“测试名称”。 将其他所有值保留默认设置。 依次选择“应用”、“确定” 。
现在,菜单栏中应会显示“远程运行”配置下拉列表。

步骤 5:在调试模式下运行应用程序
在 IntelliJ IDEA 项目中打开
SparkSample.scala并在val rdd1旁边创建一个断点。 在“在为以下对象创建断点”弹出菜单中,选择“line in function executeJob”。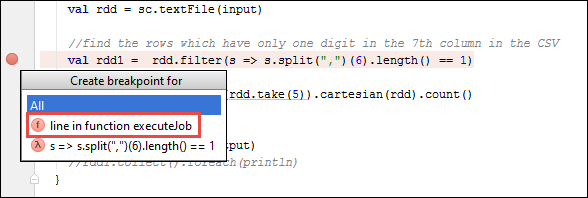
若要运行应用程序,请选择“远程运行”配置下拉列表旁边的“调试运行”按钮。

程序执行步骤到达断点时,底部窗格中应会显示“调试程序”选项卡。
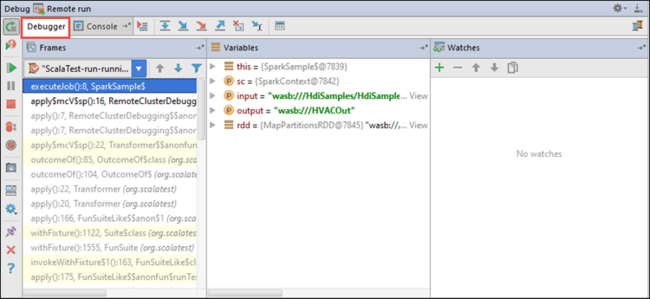
若要添加监视,请选择 ( + ) 图标。
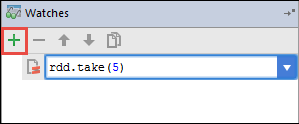
在此示例中,应用程序在创建变量
rdd1之前已中断。 使用此监视可查看变量rdd中的前五行。 选择 Enter。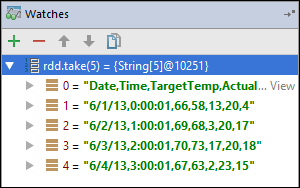
从上图可以看到,在运行时,可以查询 TB 量级的数据,并可以逐步调试应用程序。 例如,在上图显示的输出中,可以看到输出的第一行是标头。 基于此输出,可以修改应用程序代码,以根据需要跳过标头行。
现在可以选择“恢复程序”图标继续运行应用程序。
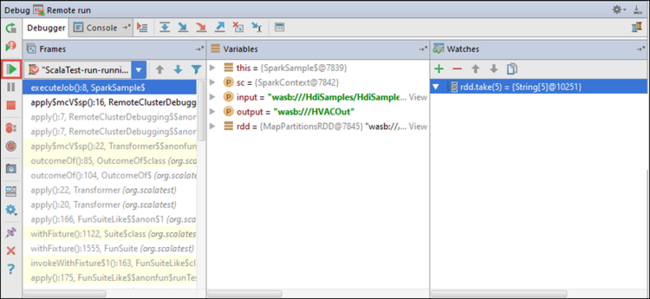
如果应用程序成功完成,应会显示类似于下面的输出:
后续步骤
方案
- Apache Spark 与 BI:使用 HDInsight 中的 Spark 和 BI 工具执行交互式数据分析
- Apache Spark 与机器学习:通过 HDInsight 中的 Spark 使用 HVAC 数据分析建筑物温度
- Apache Spark 与机器学习:使用 HDInsight 中的 Spark 预测食品检查结果
- 使用 HDInsight 中的 Apache Spark 分析网站日志
创建和运行应用程序
工具和扩展
- 使用 Azure Toolkit for IntelliJ 为 HDInsight 群集创建 Apache Spark 应用程序
- 使用 Azure Toolkit for IntelliJ 通过 SSH 远程调试 Apache Spark 应用程序
- 使用 Azure Toolkit for Eclipse 中的 HDInsight 工具创建 Apache Spark 应用程序
- 在 HDInsight 上的 Apache Spark 群集中使用 Apache Zeppelin 笔记本
- 在 HDInsight 的 Apache Spark 群集中可用于 Jupyter Notebook 的内核
- 将外部包与 Jupyter Notebook 配合使用
- Install Jupyter on your computer and connect to an HDInsight Spark cluster(在计算机上安装 Jupyter 并连接到 HDInsight Spark 群集)