你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
在 Azure HDInsight 上的 Apache Spark 群集中使用 Apache Zeppelin 笔记本
HDInsight Spark 群集包括 Apache Zeppelin 笔记本。 使用笔记本运行 Apache Spark 作业。 本文介绍如何在 HDInsight 群集中使用 Zeppelin 笔记本。
先决条件
- HDInsight 上的 Apache Spark 群集。 有关说明,请参阅在 Azure HDInsight 中创建 Apache Spark 群集。
- 群集主存储的 URI 方案。 对于 Azure Blob 存储,此架构为
wasb://;对于 Azure Data Lake Storage Gen2,此架构为abfs://;对于 Azure Data Lake Storage Gen1,此架构为adl://。 如果为 Blob 存储启用了安全传输,则 URI 将为wasbs://。 有关详细信息,请参阅在 Azure 存储中要求安全传输。
启动 Apache Zeppelin 笔记本
在 Spark 群集的“概述”中,从群集仪表板选择“Zeppelin 笔记本”。 输入群集的管理员凭据。
注意
也可以在浏览器中打开以下 URL 来访问群集的 Zeppelin 笔记本。 将 CLUSTERNAME 替换为群集的名称:
https://CLUSTERNAME.azurehdinsight.net/zeppelin创建新的笔记本。 在标题窗格中,导航到“笔记本”>“创建新笔记”。
输入笔记本的名称,然后选择“创建笔记”。
确保笔记本标题显示“已连接”状态。 该状态由右上角的一个绿点表示。
将示例数据载入临时表。 在 HDInsight 中创建 Spark 群集时,系统会将示例数据文件
hvac.csv复制到\HdiSamples\SensorSampleData\hvac下的关联存储帐户。将以下代码段粘贴到新笔记本中默认创建的空白段落处。
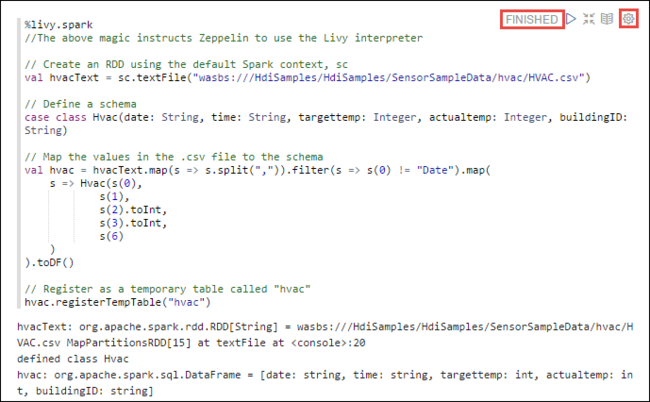
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")按 SHIFT + ENTER 或为段落选择“播放”按钮以运行代码片段。 段落右上角的状态应从“就绪”逐渐变成“挂起”、“正在运行”和“已完成”。 输出会显示在同一段落的底部。 屏幕截图如下图所示:
也可以为每个段落提供标题。 在段落的右侧一角,选择“设置”图标(齿轮图标),然后选择“显示标题”。
注意
所有 HDInsight 版本中的 Zeppelin 笔记本均不支持 %spark2 解释器,HDInsight 4.0 及更高版本不支持 %sh 解释器。
现在可以针对
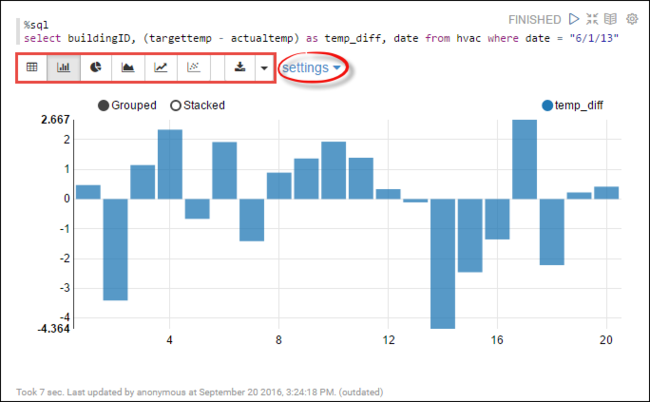
hvac表运行 Spark SQL 语句。 将以下查询粘贴到新段落中。 该查询将检索建筑物 ID, 以及每栋建筑物在指定日期的目标温度与实际温度之间的差异。 按 SHIFT + ENTER。%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"开头的 %Sql 语句告诉笔记本要使用 Livy Scala 解释器。
选择“条形图”图标以更改显示内容。 使用“设置”(选择“条形图”后显示)可以选择“键”和“值”。 以下屏幕快照显示了输出。
还可以在查询中使用变量来运行 Spark SQL 语句。 以下代码片段演示如何在查询中使用可以用来查询的值定义
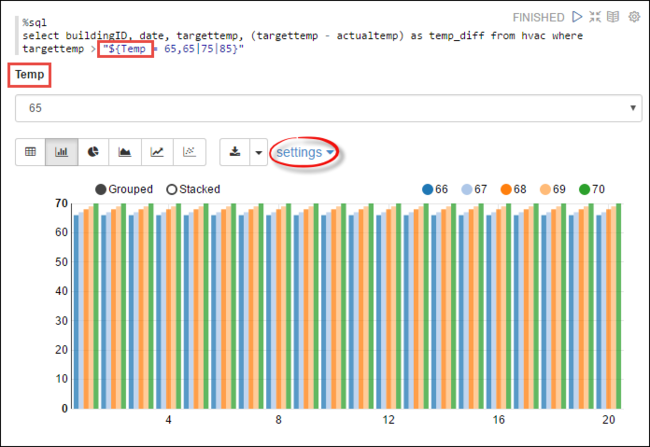
Temp变量。 首次运行查询时,下拉列表中会自动填充你指定的变量值。%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"将此代码段粘贴到新段落,并按 SHIFT + ENTER。 然后,从“温度”下拉列表中选择“65”。
选择“条形图”图标以更改显示内容。 然后选择“设置”并进行以下更改:
组:添加 targettemp。
值: 1. 删除 date。 2. 添加 temp_diff。 3. 将聚合器从“SUM”更改为“AVG”。
以下屏幕快照显示了输出。
如何在笔记本中使用外部包?
HDInsight 上 Apache Spark 群集中的 Zeppelin 笔记本可以使用群集中未包含的、社区提供的外部包。 在 Maven 存储库中搜索可用包的完整列表。 也可以从其他源获取可用包的列表。 例如, Spark 包中提供了社区贡献包的完整列表。
本文将介绍如何在 Jupyter Notebook 中使用 spark-csv 包。
打开解释器设置。 选择右上角的登录用户名,然后选择“解释器”。
滚动到“livy2”,然后选择“编辑”。
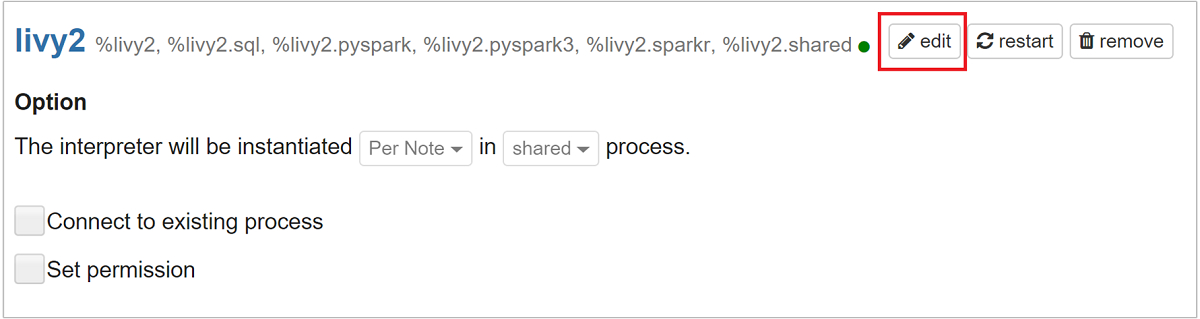
导航到键
livy.spark.jars.packages,并以group:id:version格式设置其值。 因此,如果要使用 spark-csv 包,必须将键的值设置为com.databricks:spark-csv_2.10:1.4.0。
依次选择“保存”、“确定”,以重启 Livy 解释器。
要了解如何访问输入的键的值,请查看以下内容。
a. 在 Maven 存储库中找出该包。 在本文中,使用了 spark-csv。
b. 从存储库中收集 GroupId、ArtifactId 和 Version 的值。
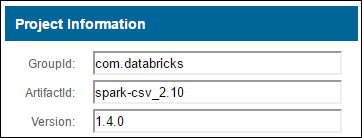
c. 串连这三个值并以冒号分隔 ( : )。
com.databricks:spark-csv_2.10:1.4.0
Zeppelin 笔记本保存在何处?
Zeppelin 笔记本的保存位置为群集头节点。 因此,如果删除群集,笔记本也会被删除。 要将笔记本保存到其他群集以供将来使用,则必须在完成作业运行后将其导出。 若要导出笔记本,请选择下图所示的“导出”图标。
此操作可在下载位置将笔记本另存为 JSON 文件。
注意
在 HDI 4.0 中,zeppelin 笔记本目录路径为:
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/例如 /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
而在 HDI 5.0 中,此路径不同
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/例如 /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
HDI 5.0 中存储的文件名不同。 它存储为
<notebook_name>_<sessionid>.zpln例如 testzeppelin_2JJK53XQA.zpln
在 HDI 4.0 中,文件名只是存储在 session_id 目录下的 note.json。
例如 /2JMC9BZ8X/note.json
HDI Zeppelin 始终将笔记本保存在 hn0 本地磁盘的以下路径:
/usr/hdp/<version>/zeppelin/notebook/。如果希望笔记本在删除群集后仍然可用,可以尝试使用 Azure 文件存储(使用 SMB 协议),并将其链接到本地路径。 有关详细信息,请参阅在 Linux 上装载 SMB Azure 文件共享
装载后,可以将 zeppelin 配置 zeppelin.notebook.dir 修改为 Ambari UI 中装载的路径。
- 对于 zeppelin 版本 0.10.1,不建议将 SMB 文件共享用作 GitNotebookRepo 存储
使用 Shiro 在企业安全性套餐 (ESP) 群集中配置 Zeppelin 解释器的访问权限
如上所述,从 HDInsight 4.0 开始不再支持 %sh 解释器。 此外,由于 %sh 解释器会导致潜在的安全问题(例如,使用 shell 命令访问 keytabs),因此也从 HDInsight 3.6 ESP 群集中删除了该解释器。 这意味着,默认情况下,单击“创建新注释”时或位于解释器 UI 时,%sh 解析器不可用。
特权域用户可以使用 Shiro.ini 文件来控制对解释器 UI 的访问。 只有这些用户可以创建新的 %sh 解释器并对每个新 %sh 解释器设置权限。 若要使用 shiro.ini 文件控制访问权限,请执行以下步骤:
使用现有域组名称定义新的角色。 在以下示例中,
adminGroupName是 Microsoft Entra ID 中的一组特权用户。 请勿在组名称中使用特殊字符或空格。=后的字符用于为此角色提供权限。*表示组具有完全权限。[roles] adminGroupName = *添加新的角色以访问 Zeppelin 解释器。 在以下示例中,
adminGroupName中的所有用户都授予了 Zeppelin 解释器的访问权限,并且可以创建新的解释器。 你可以在roles[]中的括号之间放置多个角色,用逗号分隔。 然后,具有必要权限的用户可以访问 Zeppelin 解释器。[urls] /api/interpreter/** = authc, roles[adminGroupName]
多个域组的示例 shiro.ini:
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Livy 会话管理
Zeppelin 笔记本中的第一个代码段会在群集中创建一个新的 Livy 会话。 此会话会在随后创建的所有 Zeppelin 笔记本中共享。 如果 Livy 会话因任何原因而被终止,则 Zeppelin 笔记本将无法运行作业。
在这种情况下,必须先执行以下步骤,然后才能开始在 Zeppelin 笔记本中运行作业。
在 Zeppelin 笔记本中重启 Livy 解释器。 为此,请选择右上角的登录用户名打开解释器设置,然后选择“解释器”。
滚动到“livy2”,然后选择“重启”。
在现有的 Zeppelin 笔记本中运行代码单元。 此代码会在 HDInsight 群集中创建新的 Livy 会话。
常规信息
验证服务
若要从 Ambari 验证服务,请导航到 https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary,其中 CLUSTERNAME 是群集的名称。
若要从命令行验证服务,请通过 SSH 连接到头节点。 使用命令 sudo su zeppelin 将用户切换到 zeppelin。 状态命令:
| 命令 | 说明 |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
服务状态。 |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
服务版本。 |
ps -aux | grep zeppelin |
标识 PID。 |
日志位置
| 服务 | `Path` |
|---|---|
| zeppelin-server | /usr/hdp/current/zeppelin-server/ |
| 服务器日志 | /var/log/zeppelin |
配置解释器、Shiro、site.xml、log4j |
/usr/hdp/current/zeppelin-server/conf or /etc/zeppelin/conf |
| PID 目录 | /var/run/zeppelin |
启用调试日志记录
导航到
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary,其中 CLUSTERNAME 是群集的名称。导航到“CONFIGS”>“Advanced zeppelin-log4j-properties”>“log4j_properties_content”。
将
log4j.appender.dailyfile.Threshold = INFO修改为log4j.appender.dailyfile.Threshold = DEBUG。添加
log4j.logger.org.apache.zeppelin.realm=DEBUG。保存更改并重启服务。