教程:部署和查询自定义模型
本文提供了使用 Mosaic AI Model Serving 部署和查询自定义模型(即传统 ML 模型)的基本步骤。 该模型必须在 Unity Catalog 或工作区模型注册表中注册。
若要了解如何提供和部署生成式 AI 模型,请参阅以下文章:
步骤 1:记录模型
可以通过多种方法记录执行模型服务的模型:
| 日志记录技术 | 说明 |
|---|---|
| 自动日志记录 | 使用 Databricks Runtime 进行机器学习时,系统会自动启用此功能。 这是最简单的方法,但受控性较低。 |
| 使用 MLflow 的内置风格进行日志记录 | 可以使用 MLflow 的内置模型风格手动记录模型。 |
使用 pyfunc 自定义日志记录 |
如果有自定义模型或者在推理之前或之后需要执行额外步骤,请使用此选项。 |
以下示例演示如何使用 transformer 风格记录 MLflow 模型,并指定模型所需的参数。
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
记录模型后,请务必检查模型是否已在 Unity 目录或 MLflow 模型注册表中注册。
步骤 2:使用服务 UI 创建终结点
记录已注册的模型并准备好提供服务后,可以使用服务 UI 创建模型服务终结点。
单击边栏中的“服务”以显示服务 UI。
单击“创建服务终结点”。
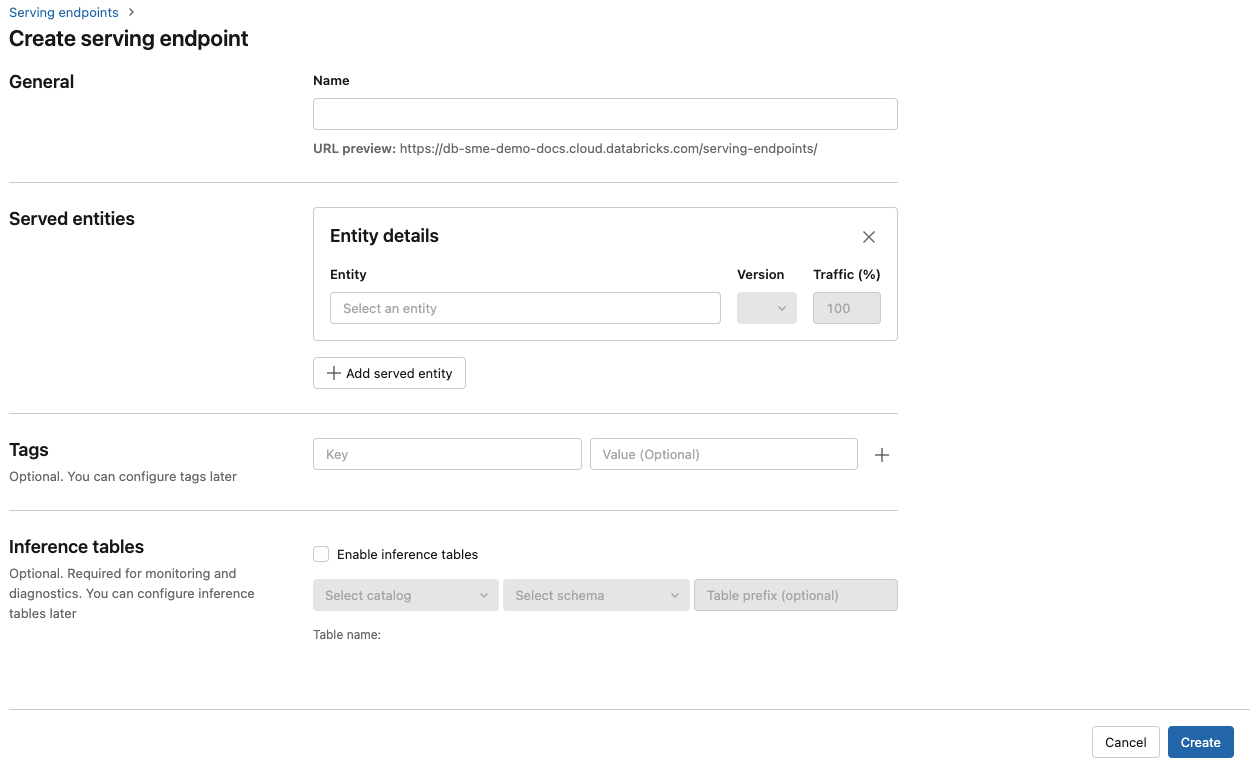
在“名称1”字段中,提供终结点的名称。
在“服务的实体”部分
- 单击“实体”字段以打开“选择服务的实体”窗体。
- 选择要服务的模型类型。 窗体会根据所选内容动态更新。
- 选择要服务的模型和模型版本。
- 选择要路由到服务的模型的流量百分比。
- 选择要使用的计算大小。
- 在“计算横向扩展”下,选择与该被服务模型可以同时处理的请求数相对应的计算横向扩展的大小。 该数字应大致等于 QPS x 模型执行时间。
- 可用大小包括:小(适用于 0-4 个请求)、中(适用于 8-16 个请求)、大(适用于 16-64 个请求)。
- 指明终结点是否应在不使用时缩放为零。
单击 “创建” 。 此时将显示“服务终结点”页,其中“服务终结点状态”显示为“未就绪”。
如果想要使用 Databricks 服务 API 以编程方式创建终结点,请参阅创建自定义模型服务终结点。
步骤 3:查询终结点
测试评分请求并将其发送到服务模型的最简单、最快的方法是使用服务 UI。
在“服务终结点”页中,选择“查询终结点”。
插入 JSON 格式的模型输入数据,并单击“发送请求”。 如果已使用输入示例记录了模型,请单击“显示示例”来加载输入示例。
{ "inputs" : ["Hello, I'm a language model,"], "params" : {"max_new_tokens": 10, "temperature": 1} }
要发送评分请求,请通过使用以下支持的键之一和与输入格式对应的 JSON 对象来构造 JSON。 请参阅模型的查询服务终结点,了解支持的格式以及有关如何使用 API 发送评分请求的指南。
如果计划访问 Azure Databricks 服务 UI 之外的服务终结点,则需要 DATABRICKS_API_TOKEN。
重要
作为适用于生产场景的安全最佳做法,Databricks 建议在生产期间使用计算机到计算机 OAuth 令牌来进行身份验证。
对于测试和开发,Databricks 建议使用属于服务主体(而不是工作区用户)的个人访问令牌。 若要为服务主体创建令牌,请参阅管理服务主体的令牌。
示例笔记本
请参阅以下笔记本,了解如何使用模型服务提供 MLflow transformers 模型。
部署 Hugging Face transformers 模型笔记本
请参阅以下笔记本,了解如何使用模型服务提供 MLflow pyfunc 模型。 有关自定义模型部署的其他详细信息,请参阅使用模型服务部署 Python 代码。