模型部署模式
本文介绍了将 ML 工件从过渡阶段转移到生产环境中的两种常见模式。 模型和代码更改的异步性质意味着 ML 开发过程可能遵循多种可能的模式。
模型是由代码创建的,但生成的模型工件和创建它的代码可以异步运行。 也就是说,新模型版本和代码更改可能不会同时发生。 例如,考虑以下情况:
- 为了检测欺诈性交易,请开发一个每周可重新训练模型的 ML 管道。 代码可能不会经常更改,但模型可能会每周进行重新训练以合并新数据。
- 可以创建一个大型的深度神经网络来对文档进行分类。 在这种情况下,训练模型的计算成本高且耗时,并且重新训练模型可能不会频繁发生。 但是,可以在不重新训练模型的情况下更新部署、服务和监视此模型的代码。
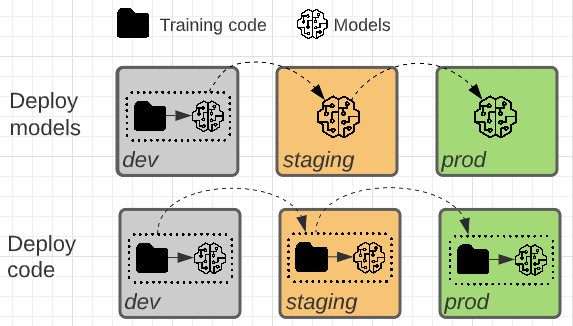
这两种模式的不同之处在于是否将模型工件或生成模型工件的训练代码提升到生产。
部署代码(建议)
在大多数情况下,Databricks 建议使用“部署代码”方法。 此方法已纳入建议的 MLOps 工作流。
在此模式中,用于训练模型的代码是在开发环境中开发的。 相同的代码移至过渡阶段,然后移至生产。 模型在每个环境中进行训练:最初在开发环境中作为模型开发的一部分,在过渡阶段(在有限的数据子集上)作为集成测试的一部分,在生产环境中(在完整的生产数据上)生成最终模型。
优点:
- 在组织中,如果对生产数据的访问受到限制,此模式允许在生产环境中对模型进行生产数据训练。
- 自动重新训练模型会更安全,因为训练代码经过审查、测试和审批后可用于生产。
- 支持代码遵循与模型训练代码相同的模式。 两者都在过渡阶段进行集成测试。
缺点:
- 数据科学家将代码交给合作者的学习曲线可能很陡峭。 预定义的项目模板和工作流非常有用。
同样在这种模式下,数据科学家必须能够查看生产环境中的训练结果,因为他们拥有识别和修复特定于 ML 的问题的知识。
如果情况要求模型在整个生产数据集上进行分段训练,可以使用混合方法,将代码部署到分段,训练模型,然后将模型部署到生产。 这种方法节省了生产中的训练成本,但增加了过渡阶段的额外运营成本。
部署模型
在此模式中,模型工件是通过在开发环境中训练代码生成的。 然后,在部署到生产环境之前,该工件在过渡阶段环境中进行了测试。
当以下一项或多项适用时,请考虑此选项:
- 模型训练非常昂贵或难以重现。
- 所有工作都在单个 Azure Databricks 工作区中完成。
- 你未使用外部存储库或 CI/CD 流程。
优点:
- 为数据科学家提供更简单的交接
- 在模型训练成本高昂的情况下,只需要训练一次模型。
缺点:
- 如果无法从开发环境访问生产数据(出于安全原因,可能会出现这种情况),则此体系结构可能不可行。
- 在此模式下,自动重新训练模型会很棘手。 可以在开发环境中自动进行重新训练,但负责在生产中部署模型的团队可能不接受生成的模型为生产就绪。
- 支持代码(例如用于特征工程、推理和监视的管道)需要单独部署到生产环境中。
通常,环境(开发、过渡或生产)对应于 Unity Catalog 中的目录。 有关如何实现此模式的详细信息,请参阅升级指南。
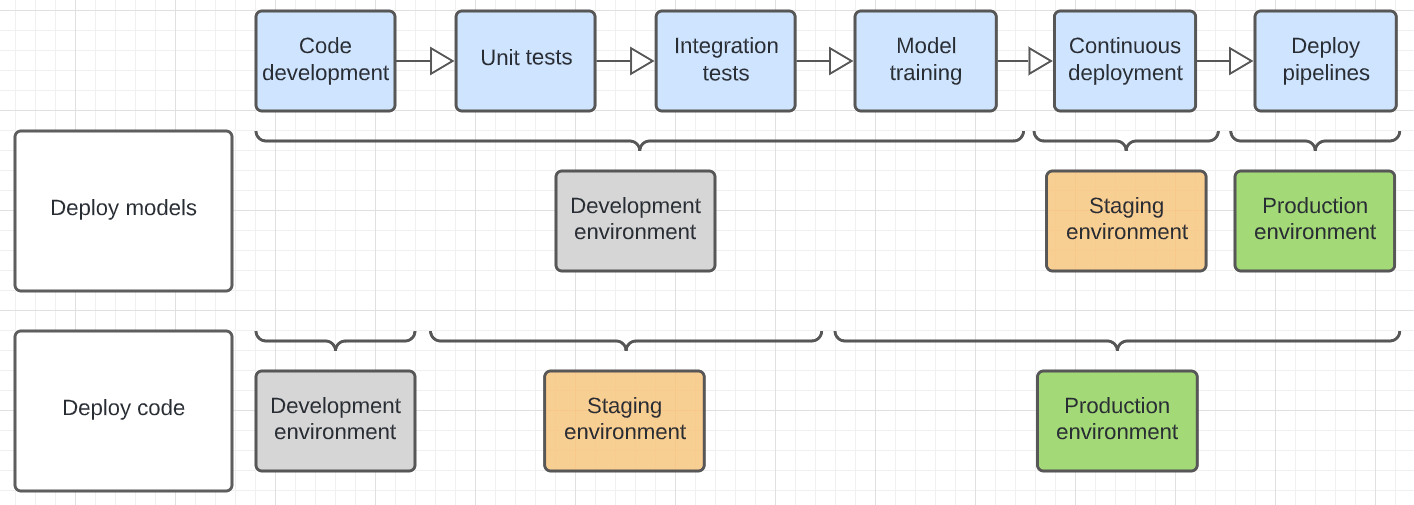
下图对比了上述部署模式在不同执行环境中的代码生命周期。
图中显示的环境是运行步骤的最终环境。 例如,在部署模型模式中,最终单元和集成测试是在开发环境中执行的。 在部署代码模式中,单元测试和集成测试在开发环境中运行,而最终单元和集成测试则在过渡环境中执行。