MLOps Stacks:将开发过程建模为代码
本文介绍 MLOps Stacks 如何帮助你在源代码控制的存储库中以代码的形式实施开发和部署流程。 它还介绍了 Databricks 数据智能平台上模型开发的优势,该平台是一个统一模型开发和部署过程的每个步骤的平台。
什么是 MLOps Stacks?
借助 MLOps Stacks,可以在源代码控制的存储库中以代码形式实现、保存和跟踪整个模型开发过程。 以这种方式自动执行该过程可促进更加可重复、可预测和系统化的部署,并能够与 CI/CD 过程集成。 将模型开发过程表示为代码使你能够部署代码,而不是部署模型。 部署代码可自动生成模型,使在必要时重新训练模型变得更容易。
使用 MLOps Stacks 创建项目时,需定义 ML 开发和部署过程的组件,例如用于特征工程、训练、测试和部署的笔记本,用于训练和测试的管道,用于每个阶段的工作区,以及使用 GitHub Actions 或 Azure DevOps 进行代码自动测试和部署的 CI/CD 工作流。
MLOps Stacks 创建的环境可实现 Databricks 推荐的 MLOps 工作流。 可以自定义代码以创建符合组织流程或要求的堆栈。
MLOps Stacks 的工作原理是什么?
可以使用 Databricks CLI 创建 MLOps Stack。 有关分步说明,请参阅适用于 MLOps Stacks 的 Databricks 资产捆绑包。
启动 MLOps Stacks 项目时,软件将引导你输入配置详细信息,然后创建一个包含撰写项目的文件的目录。 此目录或堆栈可实现 Databricks 推荐的生产 MLOps 工作流。 示意图中显示的组件是为你创建的,只需编辑文件即可添加自定义代码。

在图中:
- 答:数据科学家或 ML 工程师使用
databricks bundle init mlops-stacks初始化项目。 初始化项目时,可以选择设置 ML 代码组件(通常由数据科学家使用)、CI/CD 组件(通常由 ML 工程师使用),或同时设置此两者。 - B:ML 工程师为 CI/CD 设置 Databricks 服务主体机密。
- C:数据科学家在 Databricks 或其本地系统上开发模型。
- D:数据科学家创建拉取请求以更新 ML 代码。
- E:CI/CD 运行程序运行笔记本、创建作业,并在过渡工作区和生产工作区中执行其他任务。
组织可以使用默认堆栈,也可以根据需要对其进行自定义,以添加、移除或修订组件来满足组织的做法。 有关详细信息,请参阅 GitHub 存储库自述文件。
MLOps Stacks 的设计采用模块化结构,允许不同的 ML 团队独立处理项目,同时遵循软件工程最佳做法并保持生产级 CI/CD。 生产工程师配置 ML 基础结构,使数据科学家能够开发、测试 ML 管道及模型并将其部署到生产中。
如图所示,默认 MLOps Stack 包含以下三个组件:
- ML 代码。 MLOps Stacks 为 ML 项目创建一组模板,包括用于训练的笔记本、批处理推理等。 标准化模板让数据科学家可以快速开始,跨团队统一项目结构,并强制实施模块化代码以供测试。
- ML 资源即代码。 MLOps Stack 为训练和批处理推理等任务定义了工作区和管道等资源。 Databricks 资产捆绑包中定义了资源,以促进 ML 环境的测试、优化和版本控制。 例如,你可以尝试更大的实例类型进行自动模型重新训练,更改会被自动跟踪以供将来参考。
- CI/CD。 你可以使用 GitHub Actions 或 Azure DevOps 测试和部署 ML 代码和资源,确保通过自动化执行所有生产更改,并且仅将测试过的代码部署到生产环境。
MLOps 项目流
默认 MLOps Stacks 项目包含一个具有 CI/CD 工作流的 ML 管道,用于测试和部署跨开发、暂存和生产 Databricks 工作区的自动化模型训练和批处理推理作业。 MLOps Stacks 可配置,因此你可以修改项目结构以满足组织的流程。
此图显示了默认 MLOps Stack 实现的过程。 在开发工作区中,数据科学家会循环访问 ML 代码和文件拉取请求 (PR)。 PR 会触发独立暂存 Databricks 工作区中的单元测试和集成测试。 将 PR 合并到 main 时,在暂存中运行的模型训练和批处理推理作业会立即更新以运行最新代码。 将 PR 合并到 main 后,可以在计划发布过程中剪切新的发布分支,并将代码更改部署到生产环境。

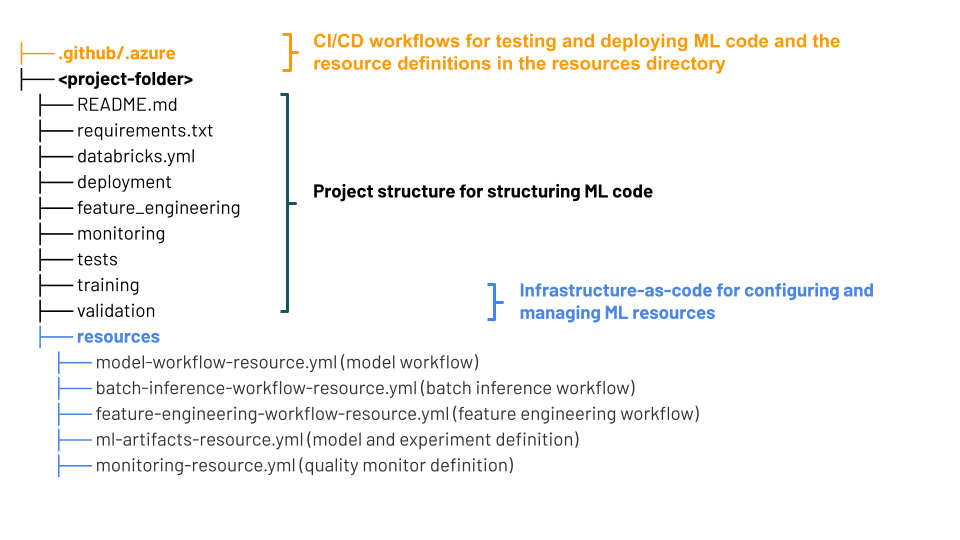
MLOps Stacks 项目结构
MLOps Stack 使用 Databricks 资产捆绑包 – 源文件的集合,这些源文件充当项目的端到端定义。 这些源文件包含有关如何进行测试和部署的信息。 将文件收集为捆绑包可以轻松地转换更改和使用数据工程最佳做法,如源代码管理、代码评审、测试和 CI/CD。
示意图显示了为默认 MLOps Stack 创建的文件。 有关堆栈中包含的文件的详细信息,请参阅 GitHub 存储库或适用于 MLOps Stacks 的 Databricks 资产捆绑包上的文档。
MLOps Stacks 组件
“堆栈”是指开发过程中使用的工具集。 默认 MLOps Stack 利用统一的 Databricks 平台,并使用以下工具:
| 组件 | Databricks 中的工具 |
|---|---|
| ML 模型开发代码 | Databricks 笔记本、MLflow |
| 特征开发和管理 | 特征工程 |
| ML 模型存储库 | Unity Catalog 中的模型 |
| ML 模型服务 | Mosaic AI 模型服务 |
| 基础结构即代码 | Databricks 资产捆绑包 |
| 业务流程协调程序 | Databricks 作业 |
| CI/CD | GitHub Actions、Azure DevOps |
| 数据和模型性能监视 | Lakehouse 监视 |
后续步骤
若要开始,请参阅 MLOps 堆栈的 Databricks 资产捆绑包或 GitHub 上的 Databricks MLOps 堆栈存储库。