Databricks 如何支持用于机器学习的 CI/CD?
CI/CD(持续集成和持续交付)是指开发、部署、监视和维护应用程序的自动化过程。 与仍在许多数据工程和数据科学团队中普遍使用的手动过程相比,通过自动执行代码的生成、测试和部署,开发团队能够更频繁、更可靠地交付发布版本。 用于机器学习的 CI/CD 汇集了 MLOps、DataOps、ModelOps 和 DevOps 技术。
本文介绍 Databricks 如何支持用于机器学习解决方案的 CI/CD。 在机器学习应用程序中,CI/CD 不仅对于代码资产非常重要,而且还会应用于数据管道,包括输入数据和模型生成的结果。
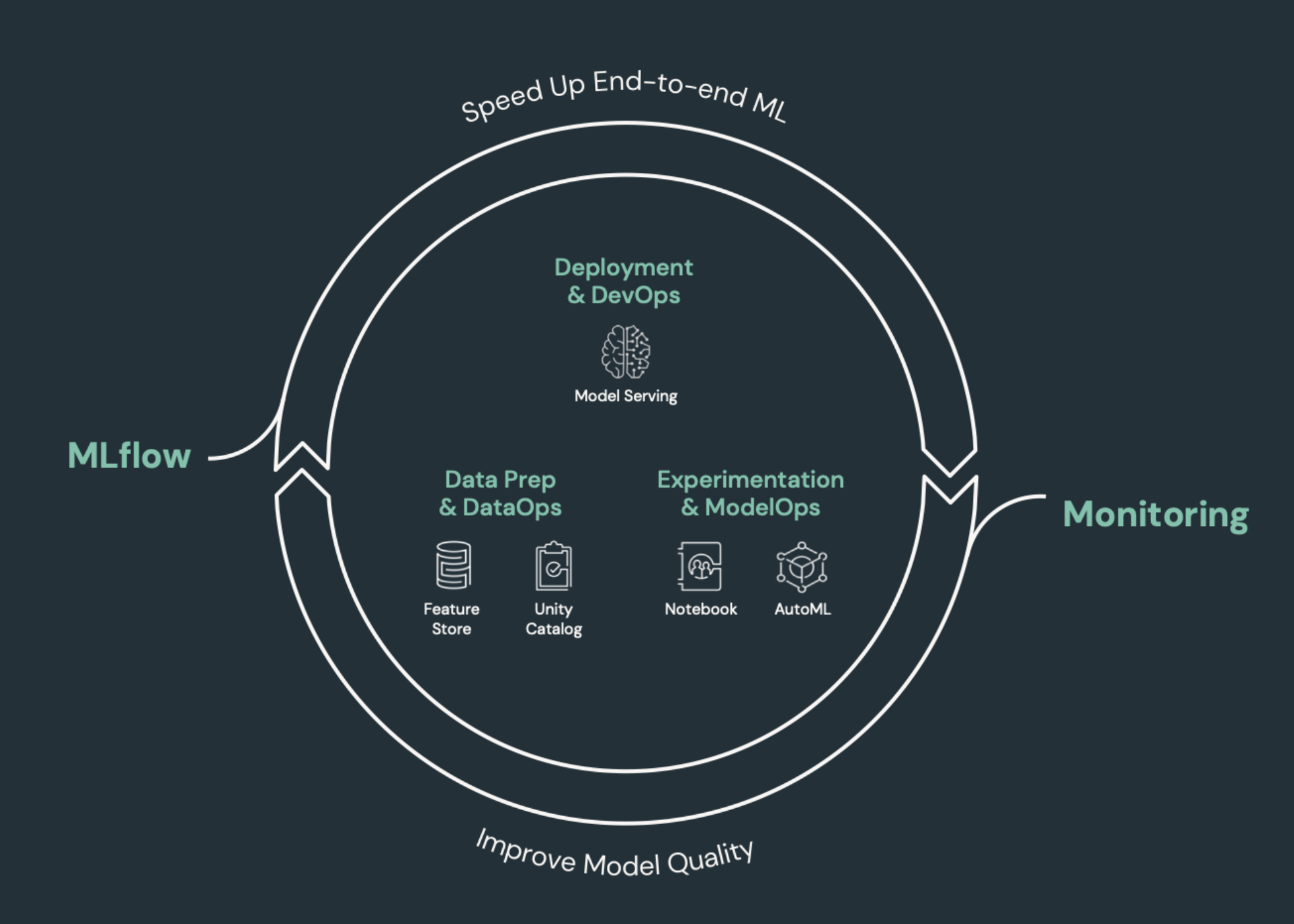
需要 CI/CD 的机器学习元素
ML 开发的挑战之一是不同的团队需要负责开发过程的不同部分。 团队可能依赖不同的工具并有不同的发布日程安排。 Azure Databricks 提供单个统一的数据和 ML 平台以及集成的工具,以提高团队的效率并确保数据和 ML 管道的一致性和可重复性。
一般而言,对于机器学习任务,应在自动化 CI/CD 工作流中跟踪以下各项:
- 训练数据,包括数据质量、架构更改和分发更改。
- 输入数据管道。
- 用于训练、验证和维护模型的代码。
- 模型预测和性能。
将 Databricks 集成到 CI/CD 过程中
MLOps、DataOps、ModelOps 和 DevOps 是指开发过程与“运营”的集成 - 使过程和基础结构可预测且可靠。 本系列文章介绍如何将运营(“ops”)原则集成到 Databricks 平台上的 ML 工作流中。
Databricks 整合了 ML 生命周期所需的所有组件,包括用于生成“配置即代码”以确保可再现性的工具,以及用于生成“基础结构即代码”以自动预配云服务的工具。 它还包括日志记录和警报服务,以帮助你检测问题并在问题发生时排查问题。
DataOps:可靠且安全的数据
良好的 ML 模型依赖于可靠的数据管道和基础结构。 使用 Databricks Data Intelligence Platform,可以确保整个数据管道(从引入数据,到维护的模型的输出)都位于单个平台上并使用相同的工具集,这有助于提高生产力、可再现性、共享和故障排除。

Databricks 中的 DataOps 任务和工具
下表列出了 Databricks 中常用的 DataOps 任务和工具:
| DataOps 任务 | Databricks 中的工具 |
|---|---|
| 引入和转换数据 | 自动加载程序和 Apache Spark |
| 跟踪数据更改,包括版本控制和世系 | Delta 表 |
| 生成、管理和监视数据处理管道 | 增量实时表 |
| 确保数据安全和治理 | Unity Catalog |
| 探索性数据分析和仪表板 | Databricks SQL、仪表板和 Databricks 笔记本 |
| 常规编码 | Databricks SQL 和 Databricks 笔记本 |
| 计划数据管道 | Databricks 作业 |
| 自动化常规工作流 | Databricks 作业 |
| 创建、存储、管理和发现用于模型训练的特征 | Databricks 特征存储 |
| 数据监视 | Lakehouse Monitoring |
ModelOps:模型开发和生命周期
开发模型需要进行一系列试验,并通过某种方式来跟踪和比较这些试验的条件和结果。 Databricks Data Intelligence Platform 提供 MLflow 用于跟踪模型开发,并提供 MLflow 模型注册表用于管理模型生命周期(包括暂存、维护和存储模型项目)。
将模型发布到生产环境后,有许多事情可能会发生变化,从而影响模型的性能。 除了监视模型的预测性能之外,还应该监视输入数据的质量或统计特征的变化,发生这些变化可能需要重新训练模型。
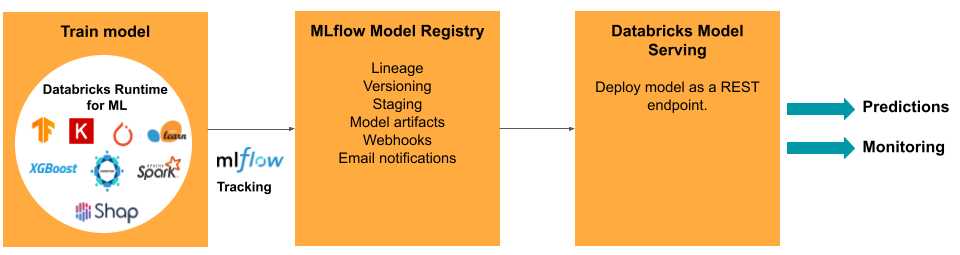
Databricks 中的 ModelOps 任务和工具
下表列出了 Databricks 提供的常用 ModelOps 任务和工具:
| ModelOps 任务 | Databricks 中的工具 |
|---|---|
| 跟踪模型开发 | MLflow 模型跟踪 |
| 管理模型生命周期 | Unity Catalog 中的模型 |
| 模型代码版本控制和共享 | Databricks Git 文件夹 |
| 无代码模型开发 | AutoML |
| 模型监视 | Lakehouse Monitoring |
DevOps:生产和自动化
Databricks 平台通过以下方式支持生产环境中的 ML 模型:
- 端到端数据和模型世系:在同一平台上提供从生产模型回溯到原始数据源的世系信息。
- 生产级模型维护:根据业务需求自动纵向扩展或缩减。
- 作业:自动完成作业并创建计划的机器学习工作流。
- Git 文件夹:实现代码版本控制和从工作区共享,并帮助团队遵循软件工程最佳做法。
- Databricks Terraform 提供程序:自动化跨云部署基础结构,以执行 ML 推理作业、终结点维护和特征化作业。
模型服务
为了将模型部署到生产环境,MLflow 大幅简化了过程,对于涉及大量数据的任务,它以批处理作业的形式提供一键式部署;在自动缩放群集上,它以 REST 终结点的形式提供部署方法。 Databricks 特征存储与 MLflow 的集成还能确保训练和维护特征的一致性;此外,MLflow 模型可以自动在特征存储中查找特征,甚至可以实现低延迟联机维护。
Databricks 平台支持许多模型部署选项:
- 代码和容器。
- 批处理维护。
- 低延迟联机维护。
- 设备上或边缘维护。
- 多云方案,例如,在一个云上训练模型,在另一个云上部署模型。
有关详细信息,请参阅 Mosaic AI 模型服务。
作业
Databricks 作业让你可以自动化和计划从 ETL 到 ML 的任何类型的工作负载。 Databricks 还支持与流行的第三方业务流程协调程序(例如 Airflow)集成。
Git 文件夹
Databricks 平台在工作区中提供了 Git 支持,以帮助团队通过 UI 执行 Git 操作来遵循软件工程最佳做法。 管理员和 DevOps 工程师可以通过 API 使用他们偏好的 CI/CD 工具设置自动化。 Databricks 支持任何类型的 Git 部署,包括专用网络。
有关使用 Databricks Git 文件夹进行代码开发的最佳做法的详细信息,请参阅使用 Git 集成和 Databricks Git 文件夹的 CI/CD 工作流和使用 CI/CD。 将这些技术与 Databricks REST API 相结合,可以使用 GitHub Actions、Azure DevOps 管道或 Jenkins 作业生成自动化部署过程。
用于治理和安全性的 Unity Catalog
Databricks 平台包含Unity Catalog,管理员可以利用它来为 Databricks 中的所有数据和 AI 资产设置精细访问控制、安全策略和治理。