使用联机表提供实时功能
重要
联机表位于以下区域的公共预览版中:westus、、eastuseastus2、northeuropewesteurope。 有关定价信息,请参阅 联机表定价。
联机表是增量表的只读副本,它以针对行的格式存储,针对联机访问进行优化。 联机表是完全无服务器表,可自动缩放请求负载的吞吐量容量,并提供对任何规模的数据的低延迟和高吞吐量访问。 联机表可与 Mosaic AI 模型服务、功能服务以及检索扩充生成 (RAG) 应用程序配合使用,用于快速查找数据。
还可使用 Lakehouse Federation 在查询中使用联机表。 使用 Lakehouse Federation 时,必须使用无服务器 SQL 仓库来访问联机表。 仅支持读取操作 (SELECT)。 此功能仅用于交互式或调试目的,不应用于生产或任务关键型工作负载。
使用 Databricks UI 创建联机表是一个单步过程。 只需从目录资源管理器中选择增量表,然后选择“创建联机表”。 还可使用 REST API 或 Databricks SDK 来创建和管理联机表。 请参阅使用 API 处理联机表。
要求
- 必须为 Unity Catalog 启用工作区。 若要创建 Unity Catalog 元存储、在工作区中启用它和创建目录,请按照文档。
- 必须在 Unity Catalog 中注册模型才能访问联机表。
使用 UI 处理联机表
本部分介绍如何创建和删除联机表,以及如何检查联机表的状态和触发更新。
使用 UI 创建联机表
可以使用目录资源管理器创建联机表。 有关所需权限的信息,请参阅用户权限。
要创建联机表,源 Delta 表必须具有主键。 如果要使用的 Delta 表没有主键,请按照以下的说明创建一个:使用 Unity Catalog 中的现有 Delta 表作为特征表。
在目录资源管理器中,导航到要同步到联机表的源表。 在“创建”菜单中,选择“联机表”。
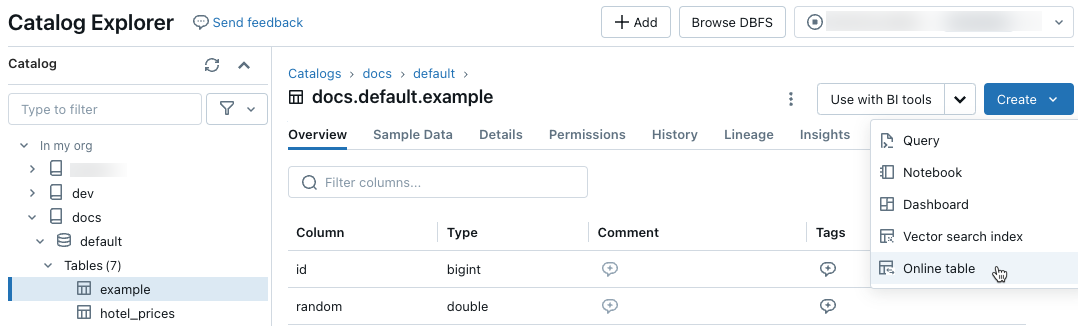
使用对话框中的选择器配置联机表。
名称:用于 Unity 目录中联机表的名称。
主键:要用作联机表中主键的源表中的列。
时序密钥:(可选)。 要用作时序键的源表中的列。 指定时,联机表仅包含每个主键具有最新时序键值的行。
同步模式:指定同步管道如何更新联机表。 选择快照、触发的或连续的之一。
策略 说明 Snapshot 管道运行一次,以拍摄源表的快照,并将其复制到联机表。 对源表的后续更改通过拍摄源的新快照并创建新副本,自动反映在联机表中。 联机表的内容会以原子方式更新。 触发 管道运行一次,以在联机表中创建源表的初始快照副本。 与快照同步模式不同,刷新联机表时,仅检索到最后一次管道执行以来的更改,并将其应用于联机表。 可以根据计划手动触发或自动触发增量刷新。 连续 管道持续运行。 对源表的后续更改以增量方式应用于联机表,采取实时流式处理模式。 无需手动刷新。
注意
若要支持触发或连续同步模式,源表必须启用更改数据馈送。
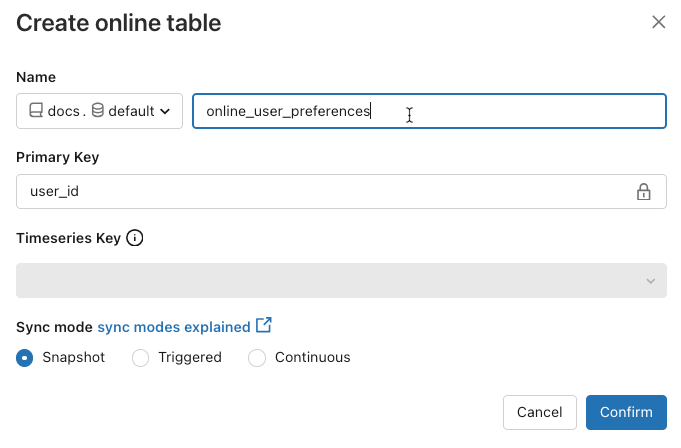
- 完成后,单击“确认”。 会显示联机表页。
- 新的联机表是在创建对话框中指定的目录、架构和名称下创建的。 在目录资源管理器中,联机表由
 指示。
指示。
使用 UI 获取状态并触发更新
若要检查联机表的状态,请单击目录中表的名称将其打开。 此时会显示联机表页,其中打开“概述”选项卡。 “数据引入”部分显示最新更新的状态。 若要触发更新,请单击“立即同步”。 “数据引入”部分还包括更新表的增量实时表管道的链接。
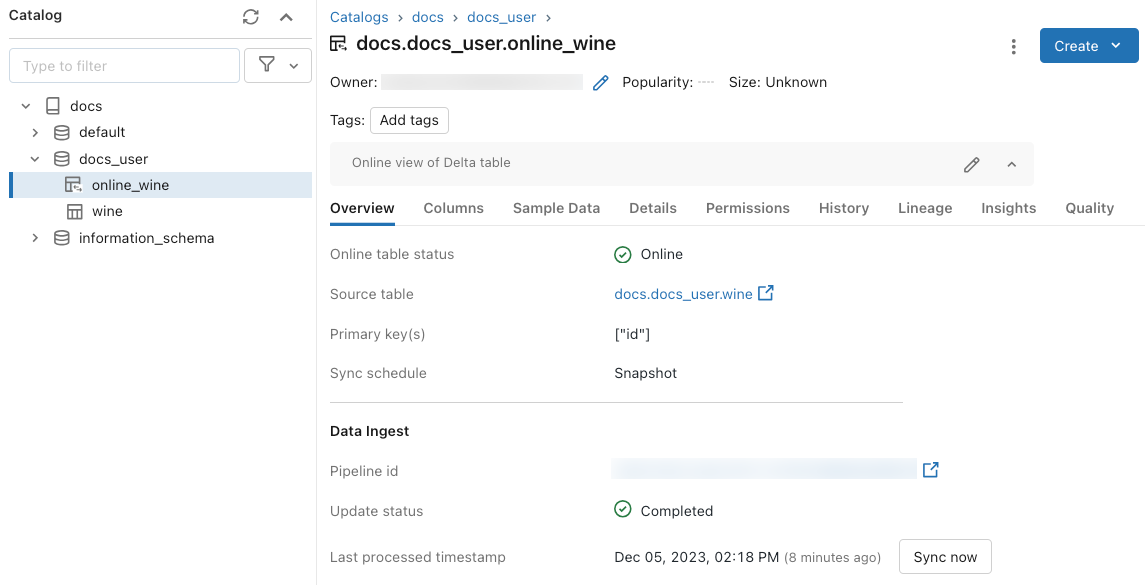
计划定期更新
对于具有 快照 或 触发 同步模式的联机表,可以计划自动定期更新。 更新计划由更新表的 Delta Live Tables 管道管理。
- 在目录资源管理器中,导航到联机表。
- 在 “数据引入 ”部分中,单击指向管道的链接。
- 在右上角,单击“计划”,然后添加新计划或更新现有计划。
使用 UI 删除联机表
从联机表页中,从 串形菜单中选择“删除”Kebab menu。
使用 API 处理联机表
还可使用 Databricks SDK 或 REST API 来创建和管理联机表。
有关参考信息,请参阅 Databricks SDK for Python 或 REST API 的参考文档。
要求
Databricks SDK 版本 0.20 或更高版本。
使用 API 创建联机表
Databricks SDK - Python
from pprint import pprint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import *
w = WorkspaceClient(host='https://xxx.databricks.com', token='xxx')
# Create an online table
spec = OnlineTableSpec(
primary_key_columns=["pk_col"],
source_table_full_name="main.default.source_table",
run_triggered=OnlineTableSpecTriggeredSchedulingPolicy.from_dict({'triggered': 'true'})
)
online_table = OnlineTable(
name="main.default.my_online_table", # Fully qualified table name
spec=spec # Online table specification
)
w.online_tables.create_and_wait(table=online_table)
REST API
curl --request POST "https://xxx.databricks.com/api/2.0/online-tables" \
--header "Authorization: Bearer xxx" \
--data '{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["a"]
}
}'
联机表在创建后自动开始同步。
使用 API 获取状态和触发刷新
可以按照以下示例查看联机表的状态和规格。 如果联机表不是连续的,并且你想要触发其数据的手动刷新,则可以使用管道 API 执行此操作。
使用与联机表规格中的联机表关联的管道 ID,并在管道上启动新的更新以触发刷新。 这相当于在 Catalog Explorer 的联机表 UI 中单击“立即同步”。
Databricks SDK - Python
pprint(w.online_tables.get('main.default.my_online_table'))
# Sample response
OnlineTable(name='main.default.my_online_table',
spec=OnlineTableSpec(perform_full_copy=None,
pipeline_id='some-pipeline-id',
primary_key_columns=['pk_col'],
run_continuously=None,
run_triggered={},
source_table_full_name='main.default.source_table',
timeseries_key=None),
status=OnlineTableStatus(continuous_update_status=None,
detailed_state=OnlineTableState.PROVISIONING,
failed_status=None,
message='Online Table creation is '
'pending. Check latest status in '
'Delta Live Tables: '
'https://xxx.databricks.com/pipelines/some-pipeline-id',
provisioning_status=None,
triggered_update_status=None))
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
w.pipelines.start_update(pipeline_id='some-pipeline-id', full_refresh=True)
REST API
curl --request GET \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
# Sample response
{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["pk_col"],
"pipeline_id": "some-pipeline-id"
},
"status": {
"detailed_state": "PROVISIONING",
"message": "Online Table creation is pending. Check latest status in Delta Live Tables: https://xxx.databricks.com#joblist/pipelines/some-pipeline-id"
}
}
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
curl --request POST "https://xxx.databricks.com/api/2.0/pipelines/some-pipeline-id/updates" \
--header "Authorization: Bearer xxx" \
--data '{
"full_refresh": true
}'
使用 API 删除联机表
Databricks SDK - Python
w.online_tables.delete('main.default.my_online_table')
REST API
curl --request DELETE \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
删除联机表会停止任何正在进行的数据同步并释放其所有资源。
使用功能服务终结点提供联机表数据
对于在 Databricks 外部托管的模型和应用程序,可以创建一个功能服务终结点来提供联机表中的功能。 终结点使用 REST API 以低延迟提供功能。
创建功能规格。
创建特征规格时,请指定源 Delta 表。 这允许在脱机和联机方案中使用功能规范。 对于联机查找,服务终结点会自动使用联机表执行低延迟功能查找。
源 Delta 表和联机表必须使用相同的主键。
功能规格可以在目录资源管理器的“函数”选项卡中查看。
from databricks.feature_engineering import FeatureEngineeringClient, FeatureLookup fe = FeatureEngineeringClient() fe.create_feature_spec( name="catalog.default.user_preferences_spec", features=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ] )创建功能服务终结点。
此步骤假定已创建一个名为
user_preferences_online_table的联机表,用于同步增量表user_preferences中的数据。 使用功能规范创建功能服务终结点。 终结点使用关联的联机表通过 REST API 提供数据。注意
执行此操作的用户必须是脱机表和联机表的所有者。
Databricks SDK - Python
from databricks.sdk import WorkspaceClient from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput workspace = WorkspaceClient() # Create endpoint endpoint_name = "fse-location" workspace.serving_endpoints.create_and_wait( name=endpoint_name, config=EndpointCoreConfigInput( served_entities=[ ServedEntityInput( entity_name=feature_spec_name, scale_to_zero_enabled=True, workload_size="Small" ) ] ) )Python API
from databricks.feature_engineering.entities.feature_serving_endpoint import ( ServedEntity, EndpointCoreConfig, ) fe.create_feature_serving_endpoint( name="user-preferences", config=EndpointCoreConfig( served_entities=ServedEntity( feature_spec_name="catalog.default.user_preferences_spec", workload_size="Small", scale_to_zero_enabled=True ) ) )从功能服务终结点获取数据。
若要访问 API 终结点,请将 HTTP GET 请求发送到终结点 URL。 此示例演示如何使用 Python API 执行此操作。 有关其他语言和工具,请参阅特征服务。
# Set up credentials export DATABRICKS_TOKEN=...url = "https://{workspace_url}/serving-endpoints/user-preferences/invocations" headers = {'Authorization': f'Bearer {DATABRICKS_TOKEN}', 'Content-Type': 'application/json'} data = { "dataframe_records": [{"user_id": user_id}] } data_json = json.dumps(data, allow_nan=True) response = requests.request(method='POST', headers=headers, url=url, data=data_json) if response.status_code != 200: raise Exception(f'Request failed with status {response.status_code}, {response.text}') print(response.json()['outputs'][0]['hotel_preference'])
将联机表与 RAG 应用程序配合使用
RAG 应用程序是联机表的常见用例。 为 RAG 应用程序所需的结构化数据创建一个联机表,并将其托管在功能服务终结点上。 RAG 应用程序使用功能服务终结点从联机表查找相关数据。
典型步骤如下所示:
- 创建功能服务终结点。
- 使用 LangChain 或任何使用终结点查找相关数据的类似包创建一个工具。
- 使用 LangChain 代理或类似代理中的工具检索相关数据。
- 创建用于托管应用程序的模型服务终结点。
有关分步说明和示例笔记本,请参阅特征工程示例:结构化 RAG 应用程序。
笔记本示例
以下笔记本演示如何将功能发布到联机表,以实现实时处理和自动功能查找。
联机表演示笔记本
将联机表与 Mosaic AI 模型服务配合使用
可以使用联机表查找 Mosaic AI 模型服务的功能。 将功能表同步到联机表时,使用该功能表中的功能训练的模型在推理期间会自动查找联机表中的特征值。 这种方式无需任何其他配置。
使用
FeatureLookup训练模型。对于模型训练,请使用模型训练集中脱机功能表中的功能,如以下示例所示:
training_set = fe.create_training_set( df=id_rt_feature_labels, label='quality', feature_lookups=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ], exclude_columns=['user_id'], )使用 Mosaic AI 模型服务为模型提供服务。 模型自动查找联机表中的功能。 有关详细信息,请参阅使用 Databricks 模型服务自动查找特征。
用户权限
必须具有以下权限才能创建联机表:
- 源表的
SELECT特权。 - 目标目录的
USE_CATALOG特权。 - 目标架构的
USE_SCHEMA和CREATE_TABLE特权。
若要管理联机表的数据同步管道,必须是联机表的所有者,或者被授予联机表的 REFRESH 特权。 没有目录 USE_CATALOG 和 USE_SCHEMA 特权的用户将不会在目录资源管理器中看到联机表。
Unity Catalog 元存储必须具有特权模型版本 1.0。
终结点权限模型
为特征服务或模型服务终结点自动创建唯一的服务主体,该终结点具有从在线表查询数据所需的有限权限。 此服务主体允许终结点独立于创建资源的用户访问数据,并确保当创建者离开工作区时终结点可以继续运行。
此服务主体的生存期是终结点的生存期。 审核日志可能指示系统为向此服务主体授予所需权限的 Unity Catalog 目录所有者生成的记录。
限制
- 每个源表仅支持一个联机表。
- 联机表及其源表最多可以有 1000 列。
- 数据类型 ARRAY、MAP 或 STRUCT 的列不能用作联机表中的主键。
- 如果列用作联机表中的主键,则忽略列包含 null 值的源表中的所有行。
- 不支持将外部表、系统表和内部表用作源表。
- 未启用增量更改数据馈送的源表仅支持快照同步模式。
- 增量共享表仅在快照同步模式下受支持。
- 联机表的目录、架构和表名只能包含字母数字字符和下划线,不得以数字开头。 不允许短划线 (
-)。 - 字符串类型的列长度限制为 64KB。
- 列名称长度限定为 64 个字符。
- 行的最大大小为 2MB。
- 在公共预览版期间,Unity Catalog 元存储中所有联机表的总大小是 2TB 未压缩的用户数据。
- 每秒最大查询数 (QPS) 为 12,000。 若要提高这些限制,请联系 Databricks 客户团队。
故障排除
我看不到“创建联机表”选项
原因通常是尝试从(源表)同步的表不是受支持的类型。 确保源表的安全对象类型(显示在目录资源管理器“详细信息”选项卡)是以下支持的选项之一:
TABLE_EXTERNALTABLE_DELTATABLE_DELTA_EXTERNALTABLE_DELTASHARINGTABLE_DELTASHARING_MUTABLETABLE_STREAMING_LIVE_TABLETABLE_STANDARDTABLE_FEATURE_STORETABLE_FEATURE_STORE_EXTERNALTABLE_VIEWTABLE_VIEW_DELTASHARINGTABLE_MATERIALIZED_VIEW
创建联机表时,我无法选择“触发”或“连续”同步模式
如果源表未启用增量更改数据馈送,或者它是视图或具体化视图,则会出现这种情况。 若要使用增量同步模式,请对源表启用更改数据馈送或使用非视图表。
联机表更新失败或状态显示为脱机
若要开始排查此错误,请单击 Catalog Explorer 中联机表的“概述”选项卡中显示的管道 ID。
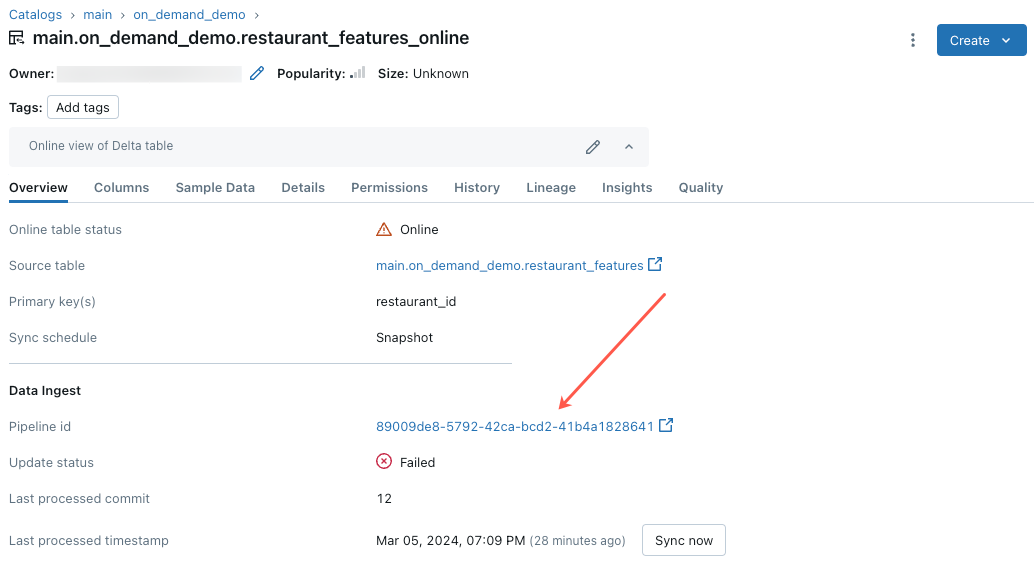
在显示的管道 UI 页上,单击显示“无法解析流‘__online_table’”的条目。
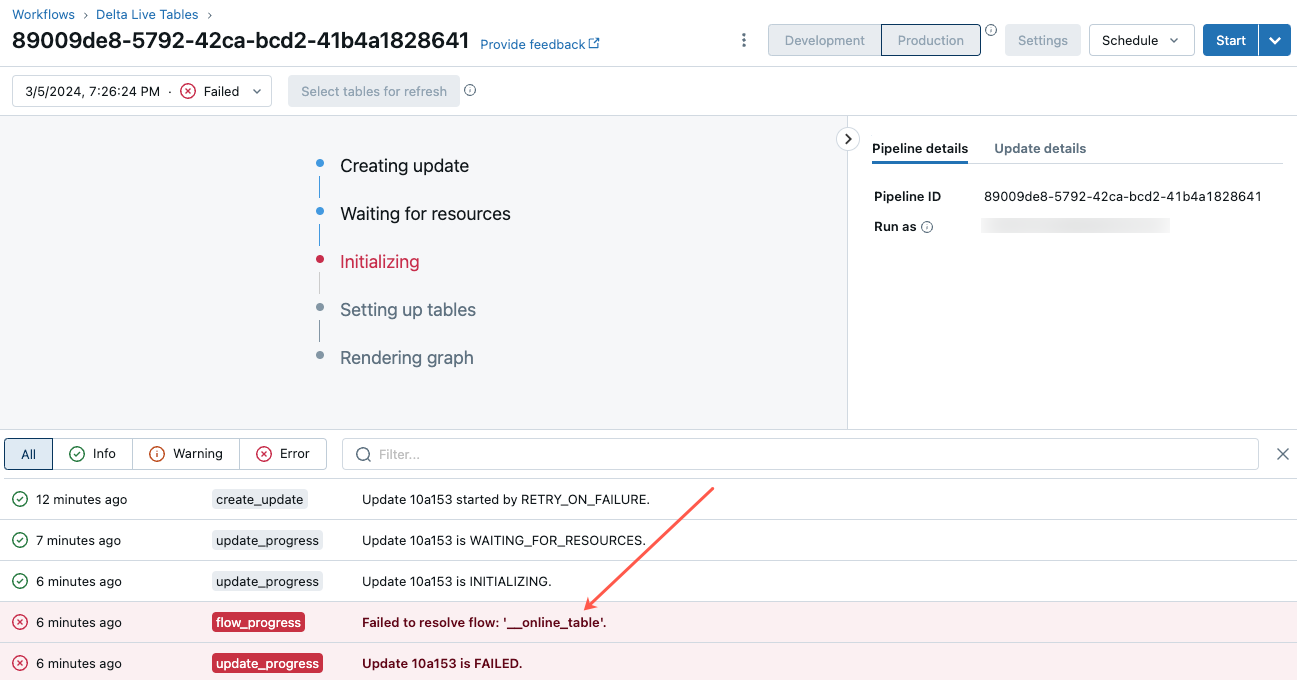
此时会显示一个弹出窗口,在“错误详细信息”部分中提供详细信息。
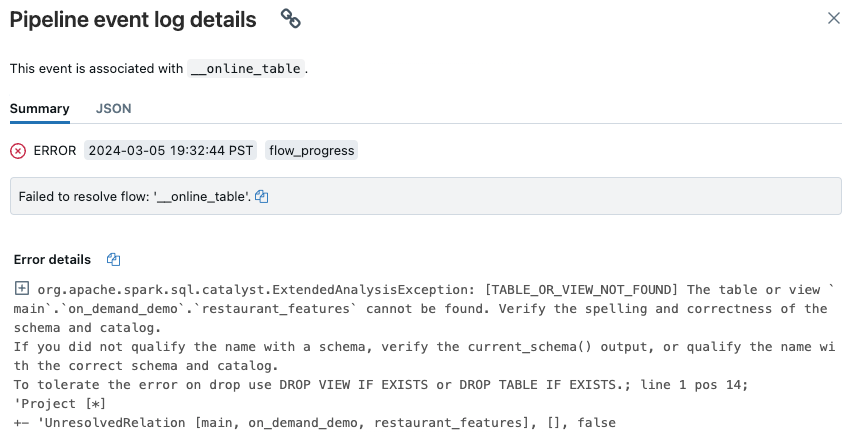
错误的常见原因包括:
在联机表同步时,源表被删除,或被删除并使用相同的名称重新创建。 这在连续联机表中尤其常见,因为它们会不断同步。
由于防火墙设置,无法通过无服务器计算访问源表。 在这种情况下,“错误详细信息”部分可能会显示错误消息“无法启动群集 xxx 上的 DLT 服务...”。
联机表的聚合大小超过 2 TB(未压缩的大小)元存储范围的限制。 2 TB 限制是指以面向行的格式扩展 Delta 表后未压缩的大小。 使用行格式的表的大小会明显大于 Catalog Explorer 中显示的 Delta 表的大小,后者是面向列的格式的表的压缩大小。 此差异可高达 100 倍,具体取决于表的内容。
若要估计 Delta 表的未压缩、行扩展的大小,请使用无服务器 SQL 仓库中的以下查询。 该查询会返回估计的扩展表大小(以字节为单位)。 成功执行此查询后,还会确认无服务器计算可以访问源表。
SELECT sum(length(to_csv(struct(*)))) FROM `source_table`;