在 Unity Catalog 中使用特征表
本页介绍了如何创建和使用 Unity Catalog 中的特征表。
此页面仅适用于为 Unity Catalog 启用的工作区。 如果没有为你的工作区启用 Unity Catalog,请参阅使用工作区特征存储中的特征表(旧版)。
有关此页面上的示例中使用的命令和参数的详细信息,请参阅特征工程 Python API 参考。
要求
Unity Catalog 中的特征工程需要 Databricks Runtime 13.2 或更高版本。 此外,Unity Catalog 元存储必须具有特权模型版本 1.0。
在 Unity Catalog Python 客户端中安装特征工程
Unity Catalog 中的特征工程有一个 Python 客户端 FeatureEngineeringClient。 该类在 PyPI 上的 databricks-feature-engineering 包中提供,并且预安装在 Databricks Runtime 13.3 LTS ML 及更高版本中。 如果使用非 ML Databricks Runtime,则必须手动安装客户端。 使用兼容性矩阵可找到适用于你的 Databricks Runtime 版本的正确版本。
%pip install databricks-feature-engineering
dbutils.library.restartPython()
创建 Unity Catalog 中特征表的目录和架构
必须新建目录或使用现有目录作为特征表。
CREATE CATALOG IF NOT EXISTS <catalog-name>
要使用现有目录,必须具有对目录的USE CATALOG特权。
USE CATALOG <catalog-name>
Unity Catalog 中的特征表必须存储在架构中。 要在目录中新建架构,必须具有对目录的CREATE SCHEMA特权。
CREATE SCHEMA IF NOT EXISTS <schema-name>
创建 Unity Catalog 中的特征表
注意
可以使用 Unity Catalog 中的现有 Delta 表,该表包含主键约束作为特征表。 如果表未定义主键,则必须使用 ALTER TABLE DDL 语句更新表以添加约束。 请参阅使用 Unity Catalog 中的现有 Delta 表作为特征表。
但要向通过 Delta Live Tables 管道发布到 Unity Catalog 的流式处理表或具体化视图添加主键,则需要修改流式处理表或具体化视图定义的架构,使其包含主键,然后刷新流式处理表或具体化视图。 请参阅使用由 Delta Live Tables 管道创建的流式处理表或具体化视图作为特征表。
Unity Catalog 中的特征表为 Delta 表。 特征表必须具有主键。 特征表(如 Unity Catalog 中的其他数据资产)可使用三级命名空间进行访问:<catalog-name>.<schema-name>.<table-name>。
可以使用 Databricks SQL、Python FeatureEngineeringClient 或 Delta Live Tables 管道在 Unity Catalog 中创建特征表。
Databricks SQL
可以使用具有主键约束的 Delta 表作为特征表。 下面的代码演示如何使用主键创建表:
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
);
若要创建时序特征表,请将时间列添加为主键列,并指定 TIMESERIES 关键字。 TIMESERIES 关键字需要 Databricks Runtime 13.3 LTS 或更高版本。
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
);
创建表后,可以像写入其他 Delta 表一样将数据写入表中,并可将该表用作特征表。
Python
有关以下示例中使用的命令和参数的详细信息,请参阅特征工程 Python API 参考。
- 编写 Python 函数来计算特征。 每个函数的输出应是具有唯一主键的 Apache Spark 数据帧。 主键可由一个或多个列组成。
- 实例化
FeatureEngineeringClient并使用create_table以创建特征表。 - 使用
write_table填充特征表。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
# Prepare feature DataFrame
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
customer_features_df = compute_customer_features(df)
# Create feature table with `customer_id` as the primary key.
# Take schema from DataFrame output by compute_customer_features
customer_feature_table = fe.create_table(
name='ml.recommender_system.customer_features',
primary_keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_table` and specify the `df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fe.create_table(
# ...
# df=customer_features_df,
# ...
# )
# To use a composite primary key, pass all primary key columns in the create_table call
# customer_feature_table = fe.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# ...
# )
# To create a time series table, set the timeseries_columns argument
# customer_feature_table = fe.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# timeseries_columns='date',
# ...
# )
使用增量实时表管道在 Unity Catalog 中创建特征表
从 Delta Live Tables 管道发布的任何表(包括主键约束)都可以用作特征表。 若要在增量实时表管道中创建一个包含主键的表,可以使用 Databricks SQL 或增量实时表 Python 编程接口。
若要在增量实时表管道中创建一个包含主键的表,可以使用以下语法:
Databricks SQL
CREATE LIVE TABLE customer_features (
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
) AS SELECT * FROM ...;
Python
import dlt
@dlt.table(
schema="""
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
""")
def customer_features():
return ...
若要创建时序特征表,请将时间列添加为主键列,并指定 TIMESERIES 关键字。
Databricks SQL
CREATE LIVE TABLE customer_features (
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
) AS SELECT * FROM ...;
Python
import dlt
@dlt.table(
schema="""
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
""")
def customer_features():
return ...
创建表后,可以像写入其他 Delta Live Tables 数据集一样将数据写入表中,并可将该表用作特征表。
使用 Unity Catalog 中的现有 Delta 表作为特征表
Unity Catalog 中具有主键的任何 Delta 表都可以是 Unity Catalog 中的特征表,可以将特征 UI 和 API 与表配合使用。
注意
- 只有表所有者才能声明主键约束。 所有者的姓名显示在目录资源管理器的表详细信息页面。
- 验证 Unity 目录中的特征工程是否支持 Delta 表中的数据类型。 请参阅支持的数据类型。
- TIMESERIES 关键字需要 Databricks Runtime 13.3 LTS 或更高版本。
如果现有 Delta 表没有主键约束,则可以按如下所示创建一个:
将主键列设置为
NOT NULL。 对于每个主键列,请运行:ALTER TABLE <full_table_name> ALTER COLUMN <pk_col_name> SET NOT NULL更改表以添加主键约束:
ALTER TABLE <full_table_name> ADD CONSTRAINT <pk_name> PRIMARY KEY(pk_col1, pk_col2, ...)pk_name是主键约束的名称。 按照约定,可以使用带_pk后缀的表名(无架构和目录)。 例如,名称为"ml.recommender_system.customer_features"的表使用customer_features_pk作为其主键约束的名称。若要使表成为时序特征表,请在一个主键列指定 TIMESERIES 关键字,如下所示:
ALTER TABLE <full_table_name> ADD CONSTRAINT <pk_name> PRIMARY KEY(pk_col1 TIMESERIES, pk_col2, ...)在表上添加主键约束后,该表将显示在特征 UI 中,并且可以用作特征表。
使用由 Delta Live Tables 管道创建的流式处理表或具体化视图作为特征表
Unity Catalog 中具有主键的任何流式处理表或具体化视图都可以是 Unity Catalog 中的特征表,可以将特征 UI 和 API 与表配合使用。
注意
若要为现有流式处理表或具体化视图设置主键,请更新负责管理对象的笔记本中的流式处理表或具体化视图的架构。 然后,刷新表以更新 Unity Catalog 对象。
将主键添加到具体化视图的语法如下所示:
Databricks SQL
CREATE OR REFRESH MATERIALIZED VIEW existing_live_table(
id int NOT NULL PRIMARY KEY,
...
) AS SELECT ...
Python
import dlt
@dlt.table(
schema="""
id int NOT NULL PRIMARY KEY,
...
"""
)
def existing_live_table():
return ...
使用 Unity 目录中的现有视图作为功能表
若要将视图用作特征表,必须使用 databricks-feature-engineering 0.7.0 或更高版本,其内置于 Databricks Runtime 16.0 ML 中。
Unity 目录中的简单 SELECT 视图可以是 Unity 目录中的功能表,可以将功能 API 与表一起使用。
注意
- 简单的 SELECT 视图定义为从 Unity Catalog 中的单个 Delta 表创建的视图,该表可用作特征表,其主键在没有 JOIN、GROUP BY 或 DISTINCT 子句的情况下被选中。 SQL 语句中的可接受关键字是 SELECT、FROM、WHERE、ORDER BY、LIMIT和 OFFSET。
- 有关支持的数据类型,请参阅支持的数据类型。
- 视图支持的特征表不出现在特征 UI 中。
- 如果在源 Delta 表中重命名列,则必须重命名视图定义的 SELECT 语句中的列以匹配。
下面是可用作特征表的简单 SELECT 视图的示例:
CREATE OR REPLACE VIEW ml.recommender_system.content_recommendation_subset AS
SELECT
user_id,
content_id,
user_age,
user_gender,
content_genre,
content_release_year,
user_content_watch_duration,
user_content_like_dislike_ratio
FROM
ml.recommender_system.content_recommendations_features
WHERE
user_age BETWEEN 18 AND 35
AND content_genre IN ('Drama', 'Comedy', 'Action')
AND content_release_year >= 2010
AND user_content_watch_duration > 60;
基于视图的特征表可用于离线模型训练和评估。 它们不能发布到在线商店。 无法基于这些特征提供这些表和模型的特征。
更新 Unity Catalog 中的特征表
可以添加新特征或基于主键修改特定的行,从而更新 Unity Catalog 中的特征表。
不应更新以下特征表元数据:
- 主密钥。
- 分区键。
- 现有特征的名称或数据类型。
更改它们将导致将特征用于训练和服务模型的下游管道中断。
将新特征添加到 Unity Catalog 中的现有特征表
可通过以下两种方式之一将新特征添加到现有的特征表:
- 更新现有的特征计算函数,并使用返回的数据帧作为参数来运行
write_table。 这会更新特征表架构,并基于主键合并新的特征值。 - 创建新的特征计算函数来计算新的特征值。 此新计算函数返回的数据帧必须包含特征表的主键和分区键(如果已定义)。 使用数据帧作为参数来运行
write_table,以使用同一主键将新特征写入现有的特征表。
仅更新特征表中的特定行
在 mode = "merge" 中使用 write_table。 write_table 调用中发送的数据帧内不存在其主键的行将保持不变。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.write_table(
name='ml.recommender_system.customer_features',
df = customer_features_df,
mode = 'merge'
)
计划一个作业来更新特征表
为确保特征表中的特征始终采用最新值,Databricks 建议创建一个作业,以便定期(例如每天)运行某个笔记本来更新特征表。 如果你已创建一个非计划作业,可将其转换为计划作业,以确保特征值始终是最新的。 请参阅 Databricks 编排概述。
用于更新特征表的代码使用 mode='merge',如以下示例所示。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_features_df = compute_customer_features(data)
fe.write_table(
df=customer_features_df,
name='ml.recommender_system.customer_features',
mode='merge'
)
存储每日特征的既往值
定义一个带有复合主键的特征表。 在主键中包含日期。 例如,对于特征表 customer_features,可以使用复合主键 (date, customer_id) 和分区键 date 实现高效的读取。
Databricks 建议在表上启用 Liquid 聚类分析,以实现高效的读取。 如果不使用 Liquid 聚类分析,请将日期列设置为分区键,以提高读取性能。
Databricks SQL
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
`date` date NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (`date`, customer_id)
)
-- If you are not using liquid clustering, uncomment the following line.
-- PARTITIONED BY (`date`)
COMMENT "Customer features";
Python
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.create_table(
name='ml.recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
# If you are not using liquid clustering, uncomment the following line.
# partition_columns=['date'],
schema=customer_features_df.schema,
description='Customer features'
)
然后,可以创建代码以从特征表中读取数据并将 date 筛选到所需的时间段。
还可以创建一个时序特征表,在使用 create_training_set 或 score_batch 时启用时间点查找。 请参阅在 Unity Catalog 中创建特征表。
为使特征表保持最新,请设置按计划定期运行的作业以写入特征,或将新特征值流式传输到特征表。
创建流特征计算管道来更新特征
若要创建流式处理特征计算管道,请将流式处理 DataFrame 作为参数传递给 write_table。 此方法将返回 StreamingQuery 对象。
def compute_additional_customer_features(data):
''' Returns Streaming DataFrame
'''
pass
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_transactions = spark.readStream.table("prod.events.customer_transactions")
stream_df = compute_additional_customer_features(customer_transactions)
fe.write_table(
df=stream_df,
name='ml.recommender_system.customer_features',
mode='merge'
)
从 Unity Catalog 中的特征表读取
使用 read_table 读取特征值。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_features_df = fe.read_table(
name='ml.recommender_system.customer_features',
)
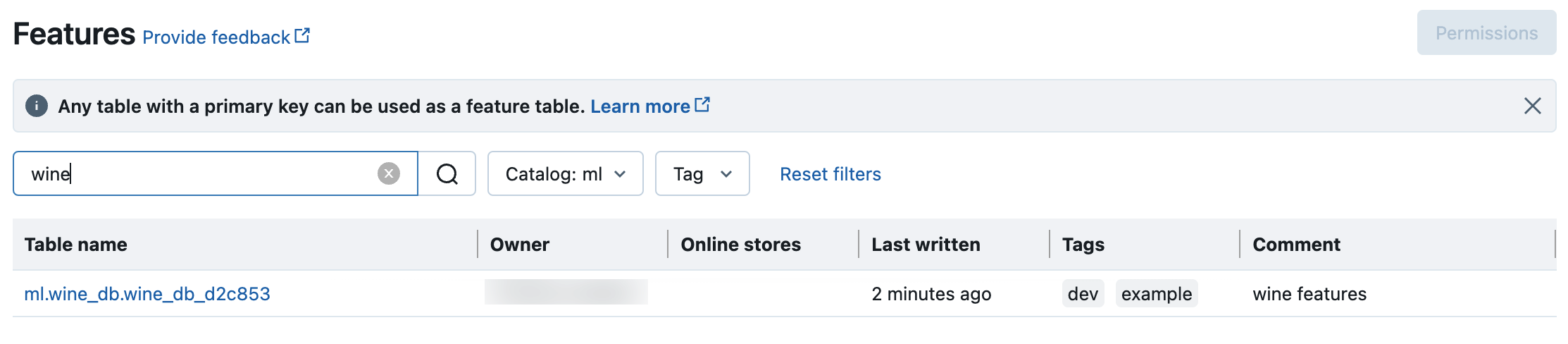
搜索和浏览 Unity Catalog 中的特征表
使用特征 UI 搜索或浏览 Unity Catalog 中的特征表。
点击侧边栏中的
 “功能”以显示功能 UI。
“功能”以显示功能 UI。使用目录选择器选择目录以查看该目录中的所有可用特征表。 在搜索框中,输入特征表、特征或注释的完整或部分名称。 你也可以输入标记的全部或部分键或值。 搜索文本不区分大小写。
获取 Unity Catalog 中特征表的元数据
使用get_table获取特征表元数据。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
ft = fe.get_table(name="ml.recommender_system.user_feature_table")
print(ft.features)
在 Unity Catalog 中将标记与特征表和特征配合使用
可以使用标记(简单的键值对)对特征表和特征进行分类和管理。
对于要素表,可以使用目录资源管理器、笔记本或 SQL 查询编辑器中的 SQL 语句或特征工程 Python API 创建、编辑和删除标记。
对于功能,可以在笔记本或 SQL 查询编辑器中使用目录资源管理器或 SQL 语句创建、编辑和删除标记。
请参阅将标记应用于 Unity Catalog 安全对象和特征工程和工作区特征存储 Python API。
以下示例演示如何使用特征工程 Python API 创建、更新和删除特征表标记。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
# Create feature table with tags
customer_feature_table = fe.create_table(
# ...
tags={"tag_key_1": "tag_value_1", "tag_key_2": "tag_value_2", ...},
# ...
)
# Upsert a tag
fe.set_feature_table_tag(name="customer_feature_table", key="tag_key_1", value="new_key_value")
# Delete a tag
fe.delete_feature_table_tag(name="customer_feature_table", key="tag_key_2")
删除 Unity Catalog 中的特征表
可以使用目录资源管理器或使用特征工程存储 Python API 直接删除 Unity Catalog 中的 Delta 表,从而删除 Unity Catalog 中的特征表。
注意
- 删除特征表可能会导致上游创建者和下游使用者(模型、终结点和计划作业)出现意外故障。 必须在云提供商的配合下删除发布的联机存储。
- 删除 Unity Catalog 中的特征表时,也会删除基础增量表。
- Databricks Runtime 13.1 ML 或更低版本不支持
drop_table。 使用 SQL 命令删除表。
可以使用 Databricks SQL 或 FeatureEngineeringClient.drop_table 删除 Unity Catalog 中的特征表:
Databricks SQL
DROP TABLE ml.recommender_system.customer_features;
Python
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.drop_table(
name='ml.recommender_system.customer_features'
)
在 Unity Catalog 中跨工作区或帐户共享功能表
Unity Catalog 中的功能表可供分配给表的 Unity Catalog 元存储的所有工作区访问。
若要与未分配给同一 Unity Catalog 元存储的工作区共享功能表,请使用增量共享。