为基础模型微调准备数据
重要
该功能在以下区域提供公共预览版:centralus、eastus、eastus2、northcentralus 和 westus。
本文介绍基础模型微调(现在是马赛克 AI 模型训练的一部分)任务的接受训练和评估数据文件格式: 监督的微调、 聊天完成和 继续预先训练。
以下笔记本演示了如何验证数据。 它设计为在开始训练之前独立运行。 它验证数据是否采用正确的基础模型微调格式,并包含代码,以帮助你通过标记原始数据集在训练运行期间估算成本。
验证训练运行笔记本的数据
准备好数据进行监督式微调
对于监督式微调任务,训练数据可以采用以下架构之一:
提示和响应对。
{"prompt": "your-custom-prompt", "response": "your-custom-response"}提示和补全对。
{"prompt": "your-custom-prompt", "completion": "your-custom-response"}
接受的数据格式包括:
具有
.jsonl文件的 Unity Catalog 卷。 训练数据必须采用 JSONL 格式,其中的每一行都是有效的 JSON 对象。 下例展示了一对提示和响应的示例:{"prompt": "What is Databricks?","response": "Databricks is a cloud-based data engineering platform that provides a fast, easy, and collaborative way to process large-scale data."}遵循上述接受的架构之一的 Delta 表。 对于 Delta 表,必须提供用于数据处理的
data_prep_cluster_id参数。 请参阅配置训练运行。公共 Hugging Face 数据集。
如果使用公共 Hugging Face 数据集作为训练数据,请使用拆分指定完整路径,例如,
mosaicml/instruct-v3/train and mosaicml/instruct-v3/test。 这导致数据集具有不同的拆分架构。 不支持 Hugging Face 中的嵌套数据集。有关更全面的示例,请参阅 Hugging Face 上的
mosaicml/dolly_hhrlhf数据集。下面的示例数据行摘自
mosaicml/dolly_hhrlhf数据集。{"prompt": "Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: what is Databricks? ### Response: ","response": "Databricks is a cloud-based data engineering platform that provides a fast, easy, and collaborative way to process large-scale data."} {"prompt": "Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Van Halen famously banned what color M&Ms in their rider? ### Response: ","response": "Brown."}
准备数据以进行聊天补全
对于聊天补全任务,聊天格式的数据必须采用 .jsonl 文件格式,其中的每一行都是表示单个聊天会话的单独 JSON 对象。 每个聊天会话都表示为一个 JSON 对象,其中包含单个键 "messages",该键映射到消息对象的数组。 若要训练聊天数据,只需提供 task_type = 'CHAT_COMPLETION'。
聊天格式的消息根据模型的聊天模板自动设置格式,因此无需添加特殊的聊天标记即可手动发出聊天轮次开始或结束的信号。 使用自定义聊天模板的模型示例是 Mistral-instruct。
注意
Mistral 模型在其数据格式中不接受 system 角色。
数组中的每个消息对象都表示对话中的单条消息,并具有以下结构:
role:指示消息创建者的字符串。 可能的值为"system"、"user"和"assistant"。 如果角色为system,则它必须是消息列表中的第一个聊天。 必须至少有一条消息具有角色"assistant",并且(可选)系统提示之后的任何消息都必须交替具有用户/助手角色。 相邻的两条消息不能具有相同的角色。"messages"数组中的最后一条消息必须具有角色"assistant".content:包含消息文本的字符串。
下面是聊天格式的数据示例:
{"messages": [
{"role": "system", "content": "A conversation between a user and a helpful assistant."},
{"role": "user", "content": "Hi there. What's the capital of the moon?"},
{"role": "assistant", "content": "This question doesn't make sense as nobody currently lives on the moon, meaning it would have no government or political institutions. Furthermore, international treaties prohibit any nation from asserting sovereignty over the moon and other celestial bodies."},
]
}
准备数据以继续预先训练
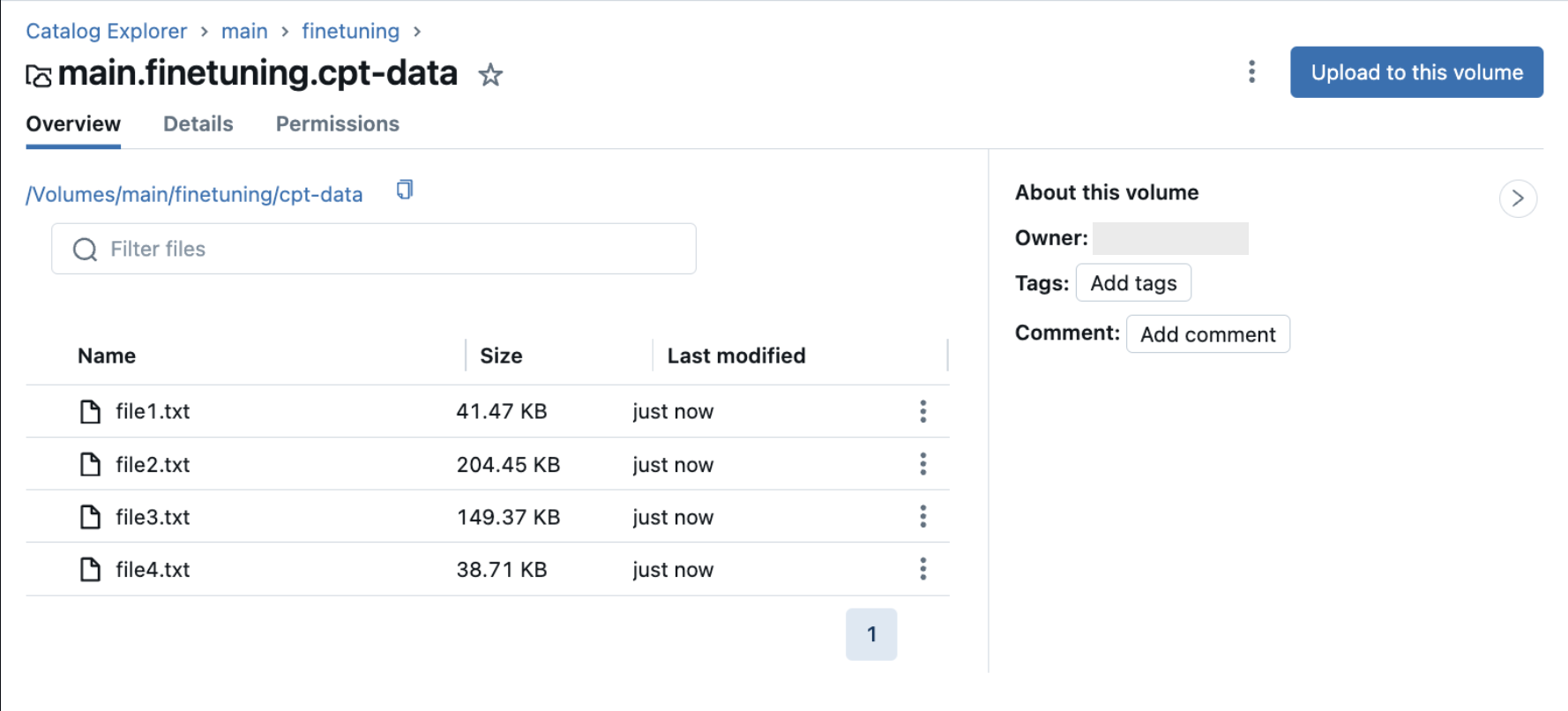
对于继续预先训练任务,训练数据是非结构化文本数据。 该训练数据必须位于包含 .txt 文件的 Unity Catalog 卷中。 每个 .txt 文件均被视为单一示例。 如果 .txt 文件位于 Unity Catalog 卷文件夹中,则还会为训练数据获取这些文件。 卷中的任何非 txt 文件都将被忽略。 请参阅将文件上传到 Unity Catalog 卷。
下图显示了 Unity Catalog 卷中的示例 .txt 文件。 若要在继续预训练运行配置中使用此数据,请设置 train_data_path = "dbfs:/Volumes/main/finetuning/cpt-data"。