使用基础模型微调 API 创建训练运行
重要
该功能在以下区域提供公共预览版:centralus、eastus、eastus2、northcentralus 和 westus。
本文介绍如何使用基础模型微调(现在是马赛克 AI 模型训练的一部分)API 创建和配置训练运行,并介绍了 API 调用中使用的所有参数。 也可以使用 UI 创建运行。 有关说明,请参阅 使用基础模型微调 UI 创建训练运行。
要求
请参阅 要求。
创建训练运行
若要以编程方式创建训练运行,请使用 create() 函数。 此函数基于提供的数据集训练模型,并将最终的 Composer 检查点转换为 Hugging Face 格式的检查点进行推理。
所需的输入是要训练的模型、训练数据集的位置以及注册模型的位置。 还有一些可选参数可用于执行计算和更改运行的超参数。
运行完成后,保存已完成的运行和最终检查点,克隆模型,并将该克隆注册到 Unity Catalog 作为模型版本进行推理。
已完成运行的模型(而不是 Unity Catalog 中的克隆模型版本)及其 Composer 和 Hugging Face 检查点将保存到 MLflow。 Composer 检查点可用于持续的微调任务。
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-2-7b-chat-hf',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
配置训练运行
下表汇总了 foundation_model.create() 函数的参数。
| 参数 | 必选 | 类型 | 说明 |
|---|---|---|---|
model |
x | str | 要使用的模型的名称。 请参阅支持的模型。 |
train_data_path |
x | str | 训练数据的位置。 这可以是 Unity Catalog 中的位置(<catalog>.<schema>.<table> 或 dbfs:/Volumes/<catalog>/<schema>/<volume>/<dataset>.jsonl),也可以是 HuggingFace 数据集。对于 INSTRUCTION_FINETUNE,应使用包含 prompt 和 response 字段的每一行设置数据格式。对于 CONTINUED_PRETRAIN,这是 .txt 文件的文件夹。 有关已接受的数据格式以及针对数据大小建议的模型训练的建议数据大小,请参阅“准备基础模型模型微调数据”。 |
register_to |
x | str | Unity Catalog 目录和架构(<catalog>.<schema> 或 <catalog>.<schema>.<custom-name>),训练后在其中注册模型,以便于部署。 如果未提供 custom-name,则默认为运行的名称。 |
data_prep_cluster_id |
str | 要用于 Spark 数据处理的群集的群集 ID。 对于训练数据位于 Delta 表中的受监督训练任务,这是必需的。 有关如何查找群集 ID 的信息,请参阅获取群集 ID。 | |
experiment_path |
str | MLflow 试验的路径,其中保存了训练运行输出(指标和检查点)。 默认为用户的个人工作区中的运行名称(即 /Users/<username>/<run_name>)。 |
|
task_type |
str | 要运行的任务的类型。 可以是 CHAT_COMPLETION(默认值)、CONTINUED_PRETRAIN 或 INSTRUCTION_FINETUNE。 |
|
eval_data_path |
str | 评估数据(如果有)的远程位置。 必须遵循与 train_data_path 相同的格式。 |
|
eval_prompts |
List[str] | 用于在评估期间生成响应的提示字符串列表。 默认值为 None(不生成提示)。 每次对模型设置检查点时,结果都会记录到试验中。 生成发生在具有以下生成参数的每个模型检查点上:max_new_tokens: 100、temperature: 1、top_k: 50、top_p: 0.95、do_sample: true。 |
|
custom_weights_path |
str | 用于训练的自定义模型检查点的远程位置。 默认值为 None,表示运行从所选模型的原始预训练权重开始。 如果提供了自定义权重,则使用这些权重,而不使用模型的原始预训练权重。 这些权重必须是 Composer 检查点,并且必须与指定的体系结构 model 匹配。 请参阅 “基于自定义模型权重生成” |
|
training_duration |
str | 运行的总持续时间。 默认值为一个纪元或 1ep。 可以按纪元 (10ep) 或标记 (1000000tok) 指定。 |
|
learning_rate |
str | 模型训练的学习率。 对于除 Llama 3.1 405B Instruct 以外的所有模型,默认学习速率为 5e-7。 对于 Llama 3.1 405B Instruct,默认学习速率为 1.0e-5。 优化器是 DecoupledLionW,beta 版本为 0.99 和 0.95,无权重衰减。 学习率计划程序是 LinearWithWarmupSchedule,总训练持续时间的预热率为 2%,最终学习率乘数为 0。 |
|
context_length |
str | 数据样本的最大序列长度。 这用于截断任何过长的数据,并将较短的序列打包在一起,以提高效率。 默认值为 8192 个令牌或所提供模型的最大上下文长度(以较低者为准)。 可以使用此参数来配置上下文长度,但不支持超出每个模型的最大上下文长度。 有关每个模型支持的最大上下文长度,请参阅支持的模型。 |
|
validate_inputs |
布尔 | 是否在提交训练作业之前验证对输入路径的访问权限。 默认值为 True。 |
基于自定义模型权重生成
基础模型微调支持使用可选参数 custom_weights_path 添加自定义权重来训练和自定义模型。
若要开始,请从以前的训练运行中设置为 custom_weights_pathComposer 检查点路径。 可以在上一个 MLflow 运行的“项目”选项卡中找到检查点路径。 检查点文件夹名称对应于特定快照的批处理和纪元,例如 ep29-ba30/。

- 若要提供上一次运行中的最新检查点,请设置为
custom_weights_pathComposer 检查点。 例如,custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/latest-sharded-rank0.symlink。 - 若要提供较早的检查点,请设置为
custom_weights_path包含.distcp与所需检查点对应的文件的文件夹的路径,例如custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/ep#-ba#。
接下来,更新参数 model 以匹配传递给 custom_weights_path的检查点的基本模型。
在以下示例 ift-meta-llama-3-1-70b-instruct-ohugkq 中,上一次运行 meta-llama/Meta-Llama-3.1-70B微调。 若要从中微调最新检查点 ift-meta-llama-3-1-70b-instruct-ohugkq,请按如下所示设置 model 和 custom_weights_path 变量:
from databricks.model_training import foundation_model as fm
run = fm.create(
model = 'meta-llama/Meta-Llama-3.1-70B'
custom_weights_path = 'dbfs:/databricks/mlflow-tracking/2948323364469837/d4cd1fcac71b4fb4ae42878cb81d8def/artifacts/ift-meta-llama-3-1-70b-instruct-ohugkq/checkpoints/latest-sharded-rank0.symlink'
... ## other parameters for your fine-tuning run
)
请参阅 配置训练运行 以在微调运行中配置其他参数。
获取群集 ID
检索群集 ID:
在 Databricks 工作区的左侧导航栏中,单击“计算”。
在表中,单击群集的名称。
单击右上角的
 ,然后从下拉菜单中选择“查看 JSON”。
,然后从下拉菜单中选择“查看 JSON”。此时将显示群集 JSON 文件。 复制群集 ID,这是文件中的第一行内容。
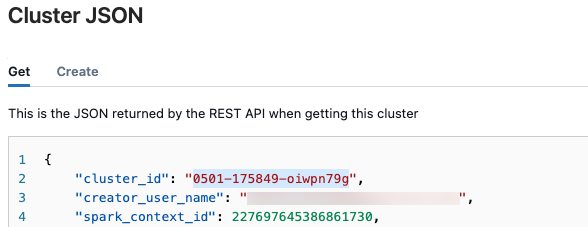
获取运行状态
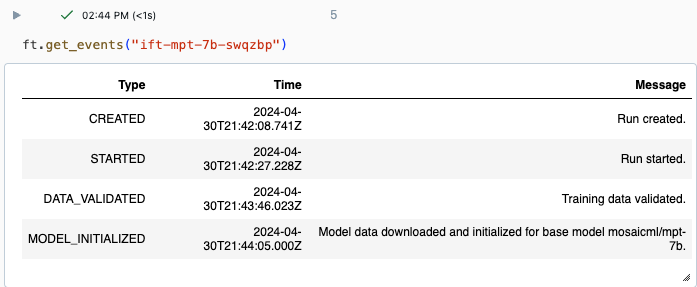
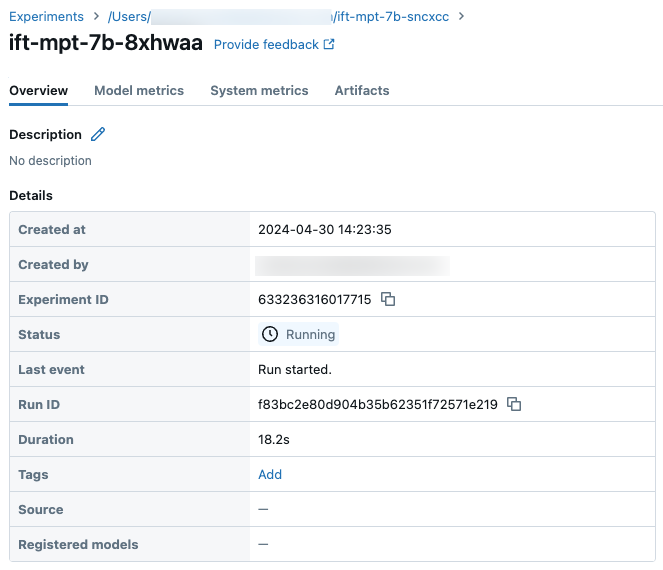
可以使用 Databricks UI 中的“试验”页或使用 API 命令 get_events() 跟踪运行进度。 有关详细信息,请参阅 “查看、管理和分析基础模型微调运行”。
get_events() 的示例输出:
“试验”页上的示例运行详细信息:
后续步骤
训练运行完成后,可以在 MLflow 中查看指标,并部署模型进行推理。 请参阅教程步骤 5 到 7 :创建和部署基础模型微调运行。
请参阅指令微调:命名实体识别演示笔记本,查看指令微调示例,按步骤进行数据准备、微调训练运行配置和部署。
笔记本示例
以下笔记本示例演示如何使用 Meta Llama 3.1 405B Instruct 模型生成合成数据,并使用该数据对模型进行微调: