提高 RAG 数据管道质量
本文从实现数据管道变更的实际角度讨论如何尝试数据管道选择。
数据管道的关键组件
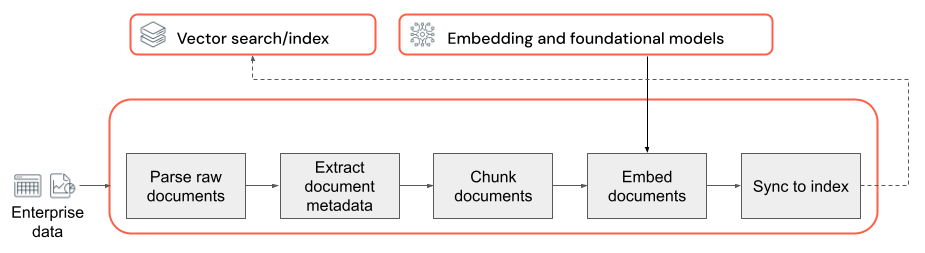
任何具有非结构化数据的 RAG 应用程序的基础都是数据管道。 此管道负责以 RAG 应用程序可有效利用的格式准备非结构化数据。 这个数据管道可能会具有任意复杂性,以下是首次生成 RAG 应用程序时需要考虑的关键组件:
- 语料库构成:根据具体用例选择正确的数据源和内容。
- 分析:使用适当的分析技术从原始数据中提取相关信息。
- 分块:将已分析的数据分解为较小的可管理区块,以便高效检索。
- 嵌入:将分块文本数据转换为可捕获其语义含义的数字矢量表示形式。
语料库构成
如果没有正确的数据语料库,RAG 应用程序就无法检索回答用户查询所需的信息。 正确的数据完全取决于应用程序的具体要求和目标,因此花时间了解可用数据的细微差别至关重要(请参阅需求收集部分获取相关指导)。
例如,在生成客户支持机器人时,可以考虑包含以下内容:
- 知识库文档
- 常见问题 (FAQ)
- 产品手册和规格
- 疑难解答指南
从任何项目一开始就让领域专家和利益干系人参与进来,以帮助识别和评判可提高数据语料库质量和覆盖范围的相关内容。 他们可以提供有关用户可能提交的查询类型的见解,并帮助确定要包含的最重要信息的优先级。
分析
标识 RAG 应用程序的数据源后,下一步就是从原始数据中提取所需的信息。 此过程称为分析,涉及将非结构化数据转换为 RAG 应用程序可有效利用的格式。
使用的特定分析技术和工具取决于处理的数据类型。 例如:
- 文本文档(PDF、Word 文档):现成的库(如非结构化和 PyPDF2)可以处理各种文件格式并提供用于自定义分析过程的选项。
- HTML 文档:可以使用 BeautifulSoup 等 HTML 分析库从网页中提取相关内容。 借助它们,可以浏览 HTML 结构,选择特定元素并提取所需的文本或属性。
- 图像和扫描文档:从图像中提取文本通常需要光学字符识别 (OCR) 技术。 常用的 OCR 库包括 Tesseract、Amazon Textract、Azure AI 视觉 OCR 和 Google Cloud Vision API。
分析数据的最佳做法
分析数据时,请考虑以下最佳做法:
- 数据清理:对提取的文本进行预处理,移除任何无关信息或干扰信息,例如页眉、页脚或特殊字符。 注意减少 RAG 链需要处理的不必要或格式不正确的信息的数量。
- 处理错误和异常:实现错误处理和日志记录机制,以识别和解决分析过程中遇到的任何问题。 这可以帮助快速识别和解决问题。 这样做通常可发现源数据质量的上游问题。
- 自定义分析逻辑:根据数据的结构和格式,可能需要自定义分析逻辑以提取最相关的信息。 虽然它可能需要在前期付出额外的努力,但请投入时间执行此操作(如果需要),这通常可避免大量下游质量问题。
- 评估分析质量:通过人工审查输出样本,定期评估已分析数据的质量。 这有助于确定分析过程中的任何问题或需要改进的领域。
分块
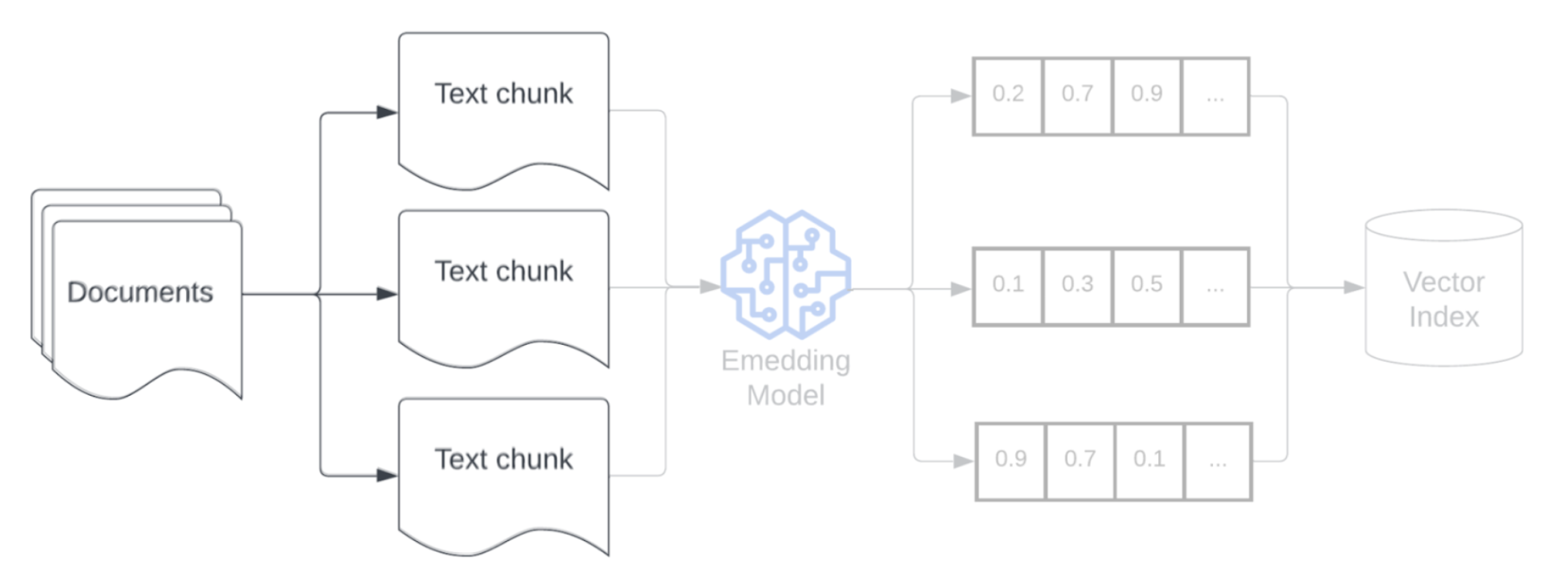
将原始数据分析为更结构化的格式后,下一步是将其分解为较小的可管理单元(称为区块)。 通过将大型文档分割为语义集中的较小区块,可确保检索到的数据适合 LLM 的上下文,同时最大限度避免包含干扰信息或不相关信息。 对分块进行的选择将直接影响向 LLM 提供的检索数据,是 RAG 应用程序中的第一层优化之一。
对数据进行分块时,请考虑以下因素:
- 分块策略:用于将原始文本划分为区块的方法。 这可能涉及基本技术(例如按句子、段落或特定字符/标记计数进行拆分)以及特定于文档的更高级拆分策略。
- 区块大小:较小的区块可能侧重于特定详细信息,但会丢失一些周边信息。 较大的区块可以捕获更多上下文,但也可能包含无关信息。
- 区块之间的重叠:为了确保在将数据拆分为区块时不会丢失重要信息,请考虑在相邻区块之间包括一些重叠。 重叠可以确保跨区块的连续性和上下文保留。
- 语义连贯性:尽可能创建语义连贯的区块,这意味着它们包含相关信息,并且可以独立成为有意义的文本单元。 这可以通过考虑原始数据的结构(例如段落、章节或主题边界)来实现。
- 元数据:在每个区块中包含相关元数据(例如源文档名称、章节标题或产品名称)可以改进检索过程。 区块中的这些附加信息可以帮助将检索查询与区块匹配。
数据分块策略
寻找正确的分块方法既需要反复迭代,又取决于具体情况。 没有一刀切的通用方法;最佳区块大小和方法取决于具体的用例和所处理数据的性质。 从广义上讲,分块策略可分为以下几种:
- 固定大小的分块:将文本拆分为预定大小(例如固定数量的字符或标记)的区块(例如 LangChain CharacterTextSplitter)。 虽然按任意数量的字符/标记进行拆分既快速又易于设置,但通常无法获得一致的语义连贯区块。
- 基于段落的分块:使用文本中的自然段落边界来定义区块。 由于段落通常包含相关信息,因此这种方法有助于保持区块的语义连贯性(例如 LangChain RecursiveCharacterTextSplitter)。
- 特定于格式的分块:markdown 或 HTML 等格式具有固有结构,可用于定义区块边界(例如 markdown 标头)。 可以使用 LangChain 的 MarkdownHeaderTextSplitter 或基于 HTML 标头/部分的拆分器等工具来实现此目的。
- 语义分块:可以应用主题建模等技术来识别文本中语义连贯的部分。 这些方法分析每个文档的内容或结构,以根据主题的转变确定最合适的区块边界。 尽管与更基本的方法相比,语义分块更复杂,但它可以帮助创建更符合文本中自然语义划分的区块(有关示例,请参阅 LangChain SemanticChunker)。
示例:固定大小的分块
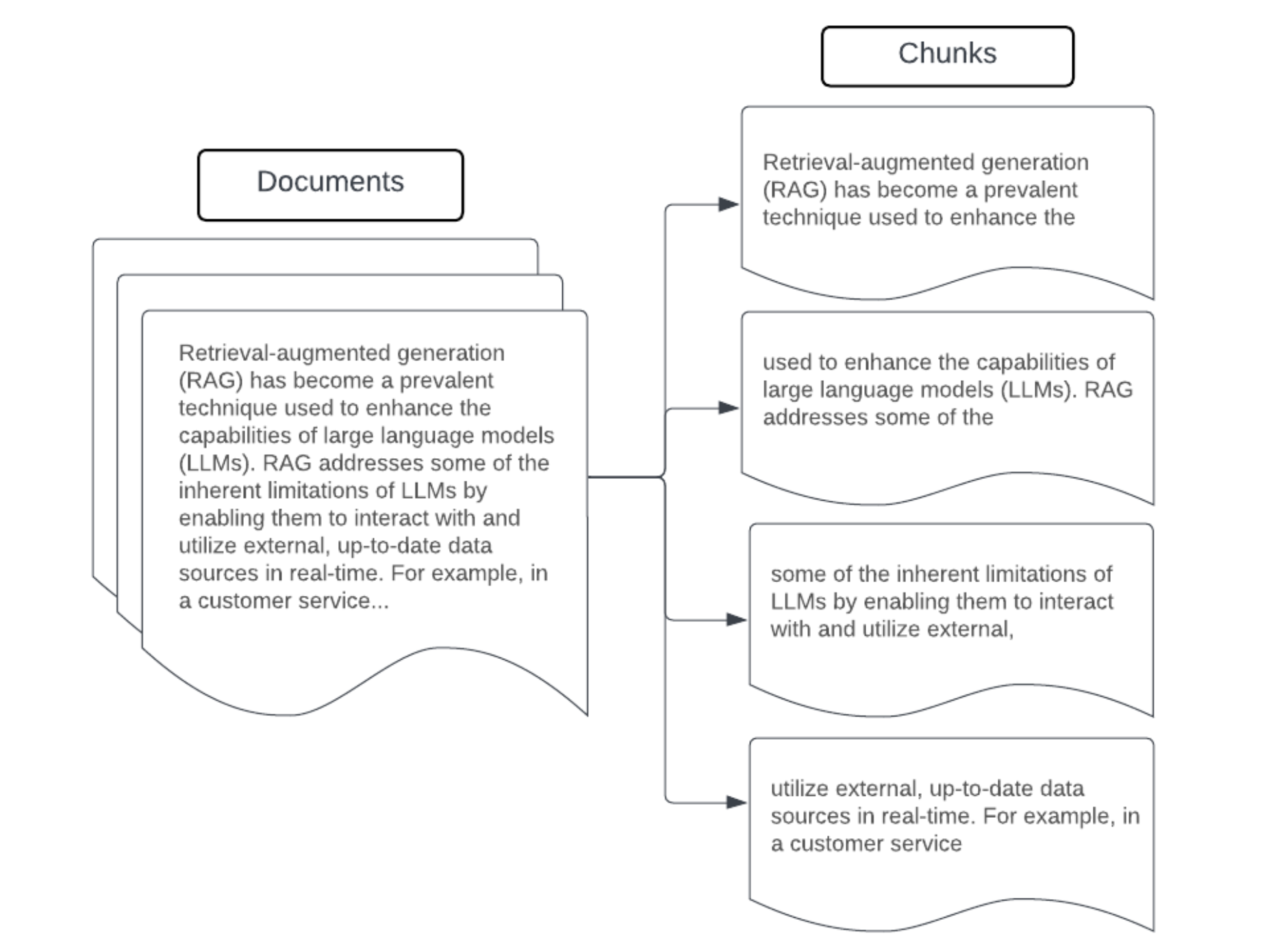
将 LangChain 的 RecursiveCharacterTextSplitter 与 chunk_size=100 和 chunk_overlap=20 配合使用的固定大小分块示例。 ChunkViz 提供了一种交互式方法,可直观显示 Langchain 字符拆分器的不同区块大小和区块重叠值如何影响生成的区块。
嵌入模型
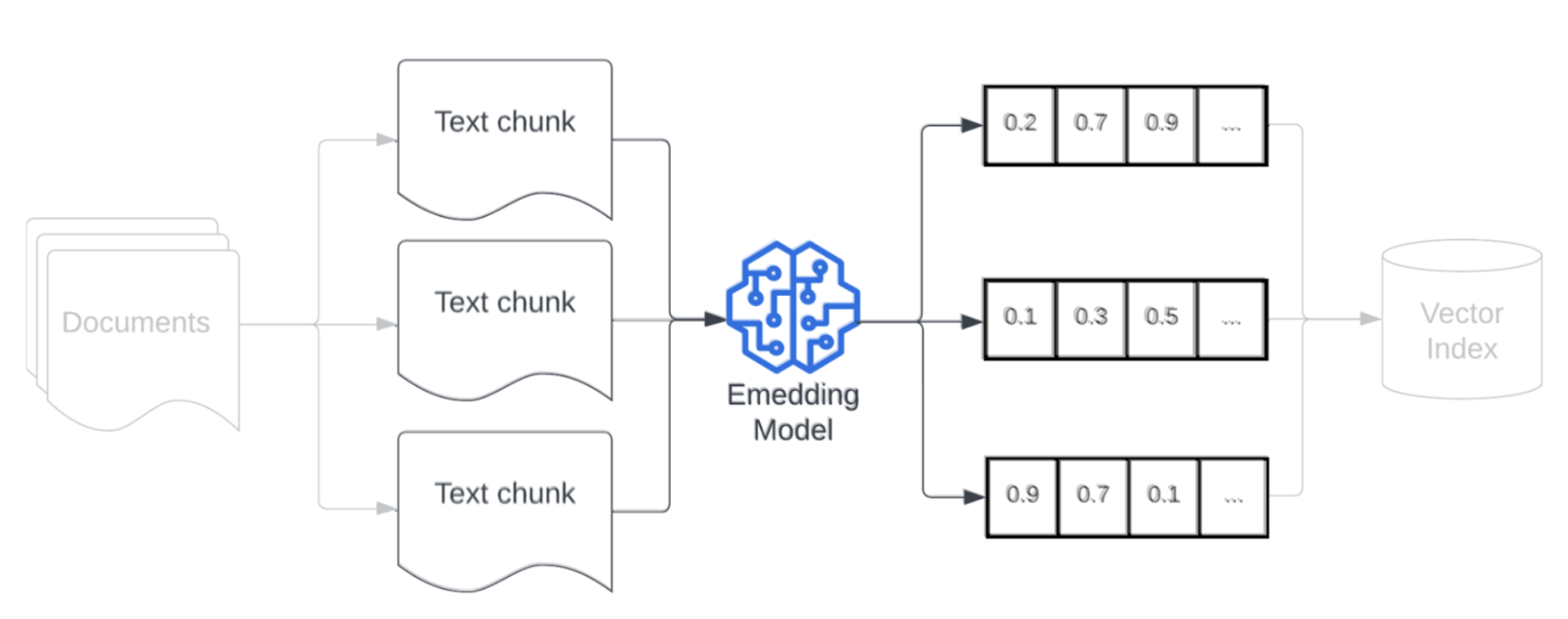
对数据进行分块后,下一步是使用嵌入模型将文本区块转换为矢量表示形式。 嵌入模型用于将每个文本区块转换为捕获其语义含义的矢量表示形式。 通过将区块表示为密集矢量,嵌入可以基于与检索查询的语义相似性快速准确地检索最相关的区块。 在查询时,将使用用于在数据管道中嵌入区块的同一嵌入模型来转换检索查询。
选择嵌入模型时,请考虑以下因素:
- 模型选择:每个嵌入模型都有其细微差别,可用的基准可能无法捕获数据的特定特征。 尝试不同的现成嵌入模型,甚至是那些在标准排行榜上排名较低的模型,例如 MTEB。 需要考虑的一些示例包括:
- 最大标记数:请注意所选嵌入模型的标记上限。 如果传递的区块超出此限制,它们会被截断,因而可能会丢失重要信息。 例如,bge-large-en-v1.5 的最大标记限制为 512。
- 模型大小:较大的嵌入模型通常提供更好的性能,但需要更多计算资源。 根据具体用例和可用资源在性能和效率之间取得平衡。
- 微调:如果 RAG 应用程序处理特定于域的语言(例如公司内部首字母缩略词或术语),请考虑根据特定于域的数据对嵌入模型进行微调。 这可以帮助模型更好地捕获特定域的细微差别和术语,并且通常可以提高检索性能。