先决条件:收集要求
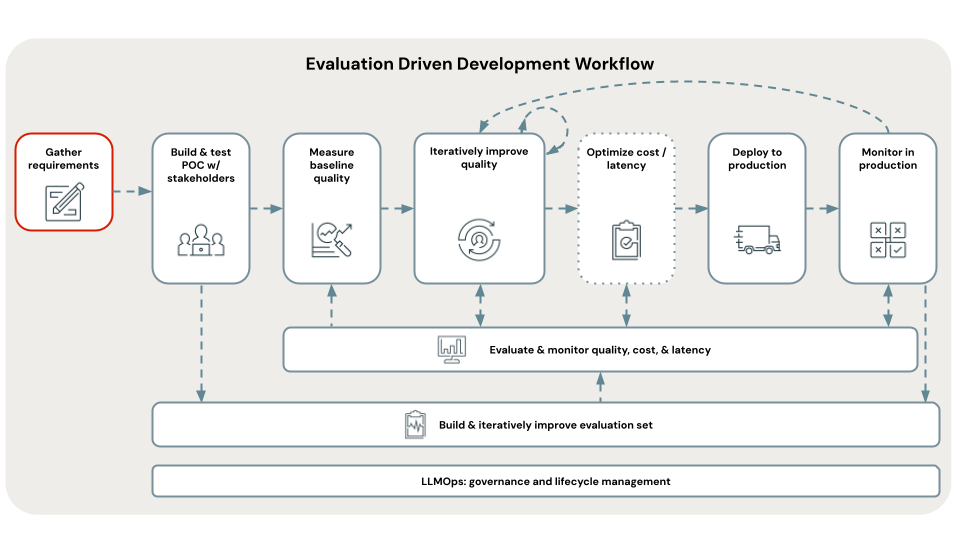
要开发成功的 RAG 应用程序,关键的第一步是定义清晰且全面的用例要求。 这些要求有两个主要目的。 首先,它们有助于确定 RAG 是否是给定用例的最合适方法。 如果 RAG 确实适合,这些要求将指导解决方案设计、实施和评估决策。 在项目开始时将时间用在收集详细的要求方面,可以防止在开发过程中出现重大挑战和挫折,并确保最终解决方案符合最终用户和利益干系人的需求。 定义完善的要求为我们将演练的开发生命周期的后续阶段奠定了基础。
有关本部分中的示例代码,请参阅 GitHub 存储库。 还可以使用存储库代码作为用于创建自己的 AI 应用程序的模板。
该用例是否适合 RAG?
需要确定的第一件事是 RAG 是否适合你的用例。 鉴于围绕 RAG 的大肆宣传,人们很容易将其视为解决任何问题的可能方案。 然而,关于 RAG 何时适用以及何时不适用,存在一些细微差别。
在以下情况下,RAG 非常适用:
- 对检索到的信息(包括非结构化和结构化信息)进行推理,这些信息不完全适合 LLM 的上下文窗口
- 汇总来自多个源的信息(例如,生成有关某个主题的不同文章的要点摘要)
- 需要基于用户查询进行动态检索(例如,给定用户查询,确定要从中检索的数据源)
- 用例需要基于检索到的信息生成新内容(例如,回答问题、提供解释、提供建议)
在以下情况下,RAG 可能不是最合适的:
- 任务不需要查询特定的检索。 例如,生成通话脚本摘要;即使单个脚本在 LLM 提示中以上下文的形式提供,检索到的信息对于每个摘要而言仍然相同。
- 要检索的整套信息可以适合 LLM 上下文窗口
- 需要超低延迟的响应(例如,需要以毫秒为单位进行响应时)
- 简单的基于规则响应或模板化的响应就已足够(例如,根据关键字提供预定义答案的客户支持聊天机器人)
发现的要求
确定 RAG 非常适合你的用例后,请考虑使用以下问题来捕获具体要求。 这些要求的优先顺序如下所示:
🟢 P0:必须在启动 POC 之前定义此要求。
🟡 P1:必须在投入生产之前定义,但可以在 POC 期间以迭代方式进行优化。
⚪ P2:最好具有要求。
此清单并未列出所有问题。 但它应为捕获 RAG 解决方案的关键要求提供坚实的基础。
用户体验
定义用户如何与 RAG 系统交互以及期望获得什么样的响应
🟢 [P0] RAG 链的典型要求是什么样的? 向利益干系人询问潜在用户查询的示例。
🟢 [P0] 用户期望获得什么样的响应(是简短的回答、详细的解释、这两者结合,还是其他类型)?
🟡 [P1] 用户如何与系统交互? 是通过聊天界面、搜索栏,还是通过其他方式?
🟡 [P1] 生成的响应应采用什么语气或风格? (是正式的、对话式的,还是技术性的?)
🟡 [P1] 应用程序如何处理不明确、不完整或不相关的查询? 在这些情况下,是否应提供任何形式的反馈或指导?
⚪ [P2] 生成的输出是否有特定的格式或演示要求? 除链的响应之外,输出是否应包含任何元数据?
数据
确定将在 RAG 解决方案中使用的数据的性质、来源和质量。
🟢 [P0] 可以使用哪些可用源?
对于每个数据源:
- 🟢 [P0] 数据是结构化还是非结构化数据?
- 🟢 [P0] 检索数据的源格式是什么(例如 PDF、带有图像/表格的文档、结构化 API 响应)?
- 🟢 [P0] 这些数据驻留在何处?
- 🟢 [P0] 有多少数据可用?
- 🟡 [P1] 数据更新的频率如何? 应如何处理这些更新?
- 🟡 [P1] 每个数据源是否存在任何已知的数据质量问题或不一致问题?
请考虑创建清单表来合并此信息,例如:
| 数据源 | Source | 文件类型 | 大小 | 更新频率 |
|---|---|---|---|---|
| 数据源 1 | Unity Catalog 卷 | JSON | 10GB | 每日 |
| 数据源 2 | 公共 API | XML | NA (API) | 实时 |
| 数据源 3 | SharePoint | PDF、.docx | 500MB | 每月 |
性能限制
了解 RAG 应用程序的性能和资源要求。
🟡 [P1] 生成响应时可接受的最大延迟是多少?
🟡 [P1] 第一个令牌的最长可接受时间是多久?
🟡 [P1] 如果输出正在进行流式传输,是否可以接受更高的总延迟?
🟡 [P1] 可用于推理的计算资源是否有成本限制?
🟡 [P1] 预期的使用模式和峰值负载是什么?
🟡 [P1] 系统应能够处理多少个并发用户或请求? Databricks 可使用模型服务进行自动扩展,以本机方式处理此类可伸缩性需求。
计算
确定如何随着时间的推移评估和改进 RAG 解决方案。
🟢 [P0] 你想要影响的业务目标/KPI 是什么? 什么是基线值以及目标是什么?
🟢 [P0] 哪些用户或利益干系人将提供初始和持续反馈?
🟢 [P0] 应使用哪些指标来评估生成的响应的质量? Mosaic AI 代理评估提供了一组建议使用的指标。
🟡 [P1] RAG 应用必须擅长解决哪组问题才能投入生产?
🟡 [P1] 是否存在[评估集]? 是否可以获得用户查询的评估集以及标准答案和(可选)应检索的正确支持文档?
🟡 [P1] 如何收集用户反馈并将其纳入系统中?
安全性
确定任何安全和隐私注意事项。
🟢 [P0] 是否存在需要谨慎处理的敏感/机密数据?
🟡 [P1] 解决方案中是否需要实施访问控制(例如,给定用户只能从一组受限制的文档中进行检索)?
部署
了解如何集成、部署和维护 RAG 解决方案。
🟡 RAG 解决方案应如何与现有系统和工作流集成?
🟡 应如何部署、缩放模型并对其进行版本控制? 本教程介绍如何使用 MLflow、Unity Catalog、Agent SDK 和模型服务在 Databricks 上处理端到端生命周期。
示例
例如,请考虑如何将这些问题应用于 Databricks 客户支持团队使用的此示例 RAG 应用程序:
| 区域 | 注意事项 | 要求 |
|---|---|---|
| 用户体验 | - 交互方式。 - 典型的用户查询示例。 - 预期的响应格式和风格。 - 处理不明确或不相关的查询。 |
- 与 Slack 集成的聊天界面。 - 示例查询:“如何缩短群集启动时间?” “我有哪种类型的支持计划?” - 提供明确的技术性响应,包括代码片段以及相关文档的链接(如果适用)。 - 提供上下文建议并根据需要上报给支持工程师。 |
| 数据 | - 数据源的数量和类型。 - 数据格式和位置。 - 数据大小和更新频率。 - 数据质量和一致性。 |
- 三个数据源。 - 公司文档(HTML、PDF)。 - 已解决的支持工单 (JSON)。 - 社区论坛帖子(Delta 表)。 - 将数据存储在 Unity Catalog 中并且每周更新一次。 - 总数据大小:5GB。 - 由专用文档和支持团队维护数据结构和质量的一致性。 |
| 性能 | - 可接受的最大延迟。 - 成本限制。 - 预期使用情况和并发。 |
- 最大延迟要求。 - 成本限制。 - 预期的峰值负载。 |
| 计算 | - 评估数据集可用性。 - 质量指标。 - 用户反馈收集。 |
- 来自每个产品领域的主题专家帮助审查输出并调整不正确的答案以创建评估数据集。 - 业务 KPI。 - 提高支持工单解决率。 - 缩短用户在每个支持工单上花费的时间。 - 质量指标。 - 通过 LLM 来判断答案的正确性和相关性。 - 通过 LLM 判断检索准确率。 - 用户投赞成票或反对票。 - 反馈收集。 - 将检测 Slack 以提供赞成/反对票。 |
| 安全性 | - 敏感数据处理。 - 访问控制要求。 |
- 检索源中不应有敏感的客户数据。 - 通过 Databricks Community SSO 进行用户身份验证。 |
| 部署 | - 与现有系统集成。 - 部署和版本控制。 |
- 与支持工单系统集成。 - 将链部署为 Databricks 模型服务终结点。 |
下一步
入门指南:步骤 1. 克隆代码存储库并创建计算。