用于推理的 RAG 链
本文介绍了用户在线上向 RAG 应用程序提交请求时发生的流程。 数据经过数据管道处理后,便适合在 RAG 应用程序中使用。 在推理时调用的一系列步骤或步骤链通常称为 RAG 链。
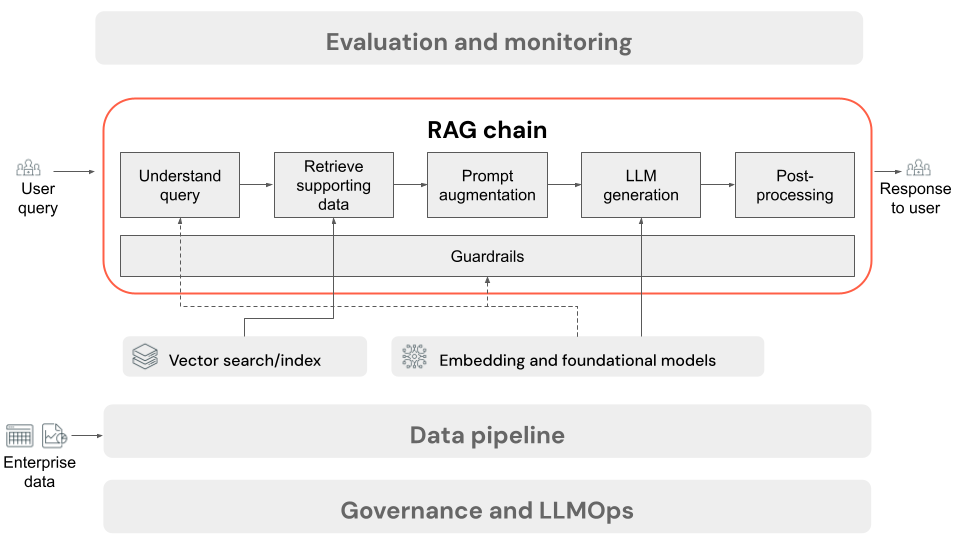
- (可选)用户查询预处理:在某些情况下,需要对用户的查询进行预处理,以使其更适合查询矢量数据库。 这可能涉及在模板内为查询设置格式、使用另一个模型重写请求或提取关键字以帮助检索。 此步骤的输出是将在后续检索步骤中使用的检索查询。
- 检索:若要从向量数据库中检索支持信息,系统会使用与数据准备期间嵌入文档块相同的嵌入模型将检索查询转换为嵌入。 这些嵌入可以使用余弦相似度等度量来比较检索查询和非结构化文本块之间的语义相似度。 接下来,从向量数据库中检索块,并根据这些块与嵌入请求的相似程度进行排序。 返回顶部(最相似的)结果。
- 提示增强:系统会使用检索到的上下文增强用户的查询,从而形成发送给 LLM 的提示,在一个模板中,该模板指导模型如何使用每个组件,通常还附带用于控制响应格式的额外指令。 对要使用的正确提示模板进行迭代的过程称为提示工程。
- LLM 生成:LLM 将增强提示(包括用户的查询和检索到的支持数据)作为输入。 然后,它会生成一个基于其他上下文的响应。
- (可选)后处理 - 可以进一步处理 LLM 的响应以应用额外的业务逻辑、添加引用或以其他方式根据预定义的规则或约束细化生成的文本。
与 RAG 应用程序数据管道一样,许多后续的工程决策都会影响 RAG 链的质量。 例如,确定在步骤 2 中检索多少个块以及如何在步骤 3 中将它们与用户的查询相结合,可以显著影响模型生成优质响应的能力。
在此过程中,可以应用各种防护措施以确保符合企业政策。 这可能涉及筛选适当的请求、在访问数据源之前检查用户权限以及对生成的响应应用内容审核技术。