RAG 数据管道说明和处理步骤
本文将介绍如何准备非结构化数据,以在 RAG 应用程序中使用。 非结构化数据是指没有特定结构或组织的数据,例如可能包含文本和图像的 PDF 文档,或者音频或视频等多媒体内容。
非结构化数据缺少预定义的数据模型或架构,因此无法仅根据结构和元数据进行查询。 因此,非结构化数据需要能够理解和提取原始文本、图像、音频或其他内容的语义含义的技术。
在数据准备过程中,RAG 应用程序数据管道获取原始非结构化数据,并将其转换为离散区块,这些区块可以根据其与用户查询的相关性进行查询。 下面概述了数据预处理中的关键步骤。 每个步骤都有各种可调的旋钮 - 有关这些旋钮的更深入的讨论,请参阅提升 RAG 应用程序质量。
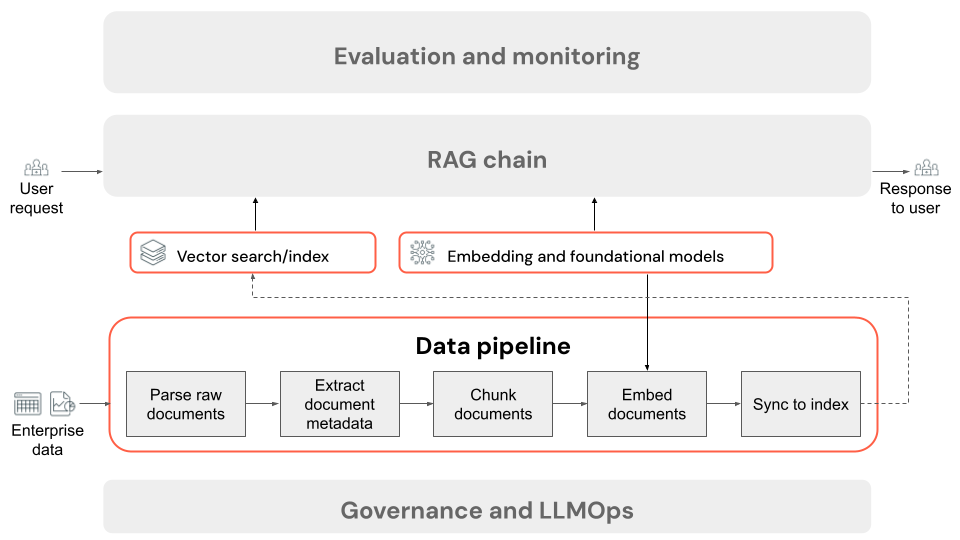
准备非结构化数据以供检索
在本部分的其余部分中,我们将介绍使用语义搜索准备非结构化数据以进行检索的过程。 语义搜索可以理解用户查询的上下文含义和意图,从而提供更相关的搜索结果。
对非结构化数据实现 RAG 应用程序的检索组件时,语义搜索是可以采用的几种方法之一。 这些文档在检索旋钮部分中介绍了备用检索策略。
RAG 应用程序数据管道的步骤
以下是 RAG 应用程序中使用非结构化数据的数据管道的典型步骤:
- 分析原始文档:初始步骤涉及将原始数据转换为可用格式。 包括从 PDF 集合中提取文本、表格和图像,或使用光学字符识别 (OCR) 技术从图像中提取文本。
- 提取文档元数据(可选):在某些情况下,提取和使用文档元数据(如文档标题、页码、URL 或其他信息)可以帮助检索步骤更准确地查询正确的数据。
- 区块文档:为了确保已分析的文档适合嵌入模型和 LLM 的上下文窗口,我们会将已分析的文档分解为较小的离散区块。 检索这些重点区块(而不是整个文档)可为 LLM 提供更有针对性的内容来生成响应。
- 嵌入区块:在使用语义搜索的 RAG 应用程序中,一种称为嵌入模型的特殊语言模型会将上一步中的每个区块转换为数字矢量或数字列表,以封装每个内容片段的含义。 最重要的是,这些矢量表示文本的语义含义,而不仅仅是表面级关键字。 这样就可以基于含义而不是字面文本匹配进行搜索。
- 在矢量数据库中索引区块:最后一步是将区块的矢量表示形式以及区块的文本加载到矢量数据库中。 矢量数据库是一种专用型数据库,旨在有效地存储和搜索嵌入等矢量数据。 为了保持大量区块的性能,矢量数据库通常包括一个矢量索引,该索引使用各种算法以优化搜索效率的方式组织和映射矢量嵌入。 在查询时,用户的请求嵌入到矢量中,数据库利用矢量索引查找最相似的区块矢量,返回相应的原始文本区块。
计算相似性的过程可能会耗费大量计算资源。 矢量索引(如 Databricks 矢量搜索)提供一种有效组织和导航嵌入的机制,通常通过复杂的近似方法,加快了这一过程。 这样就可以快速对最相关的结果进行排名,而无需将每个嵌入与用户的查询单独进行比较。
数据管道中的每个步骤都涉及影响 RAG 应用程序质量的工程决策。 例如,在步骤 3 中选择合适的区块大小可确保 LLM 收到具体但有上下文的信息,而在步骤 4 中选择合适的嵌入模型则可确定检索期间返回的区块的准确性。
此数据准备过程称为脱机数据准备,因为它发生在系统应答查询之前,这与用户提交查询时触发的联机步骤不同。