如何监视代理在生产流量上的质量
重要
此功能目前以公共预览版提供。
本文介绍如何使用 马赛克 AI 代理评估监视已部署代理在生产流量上的质量。
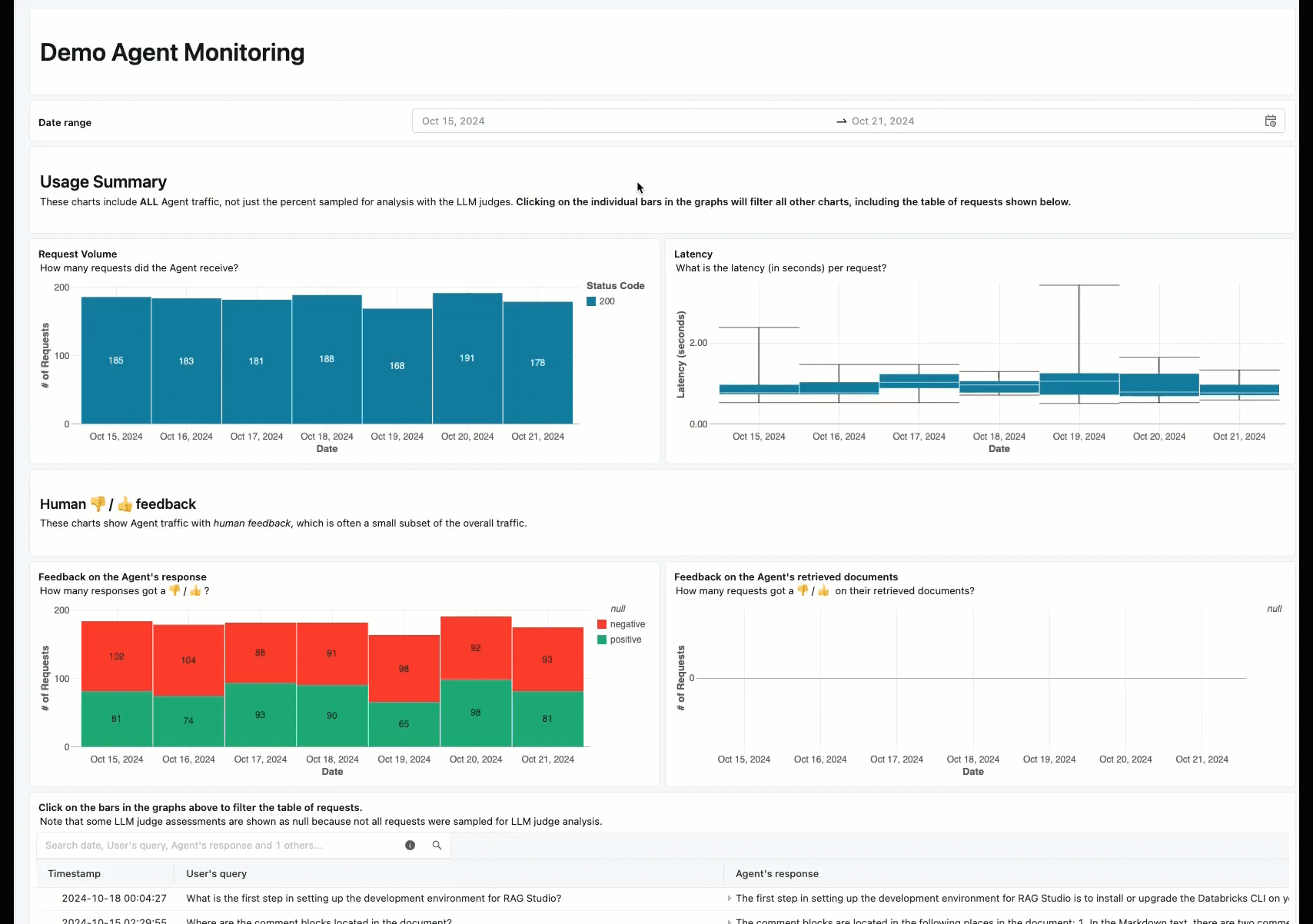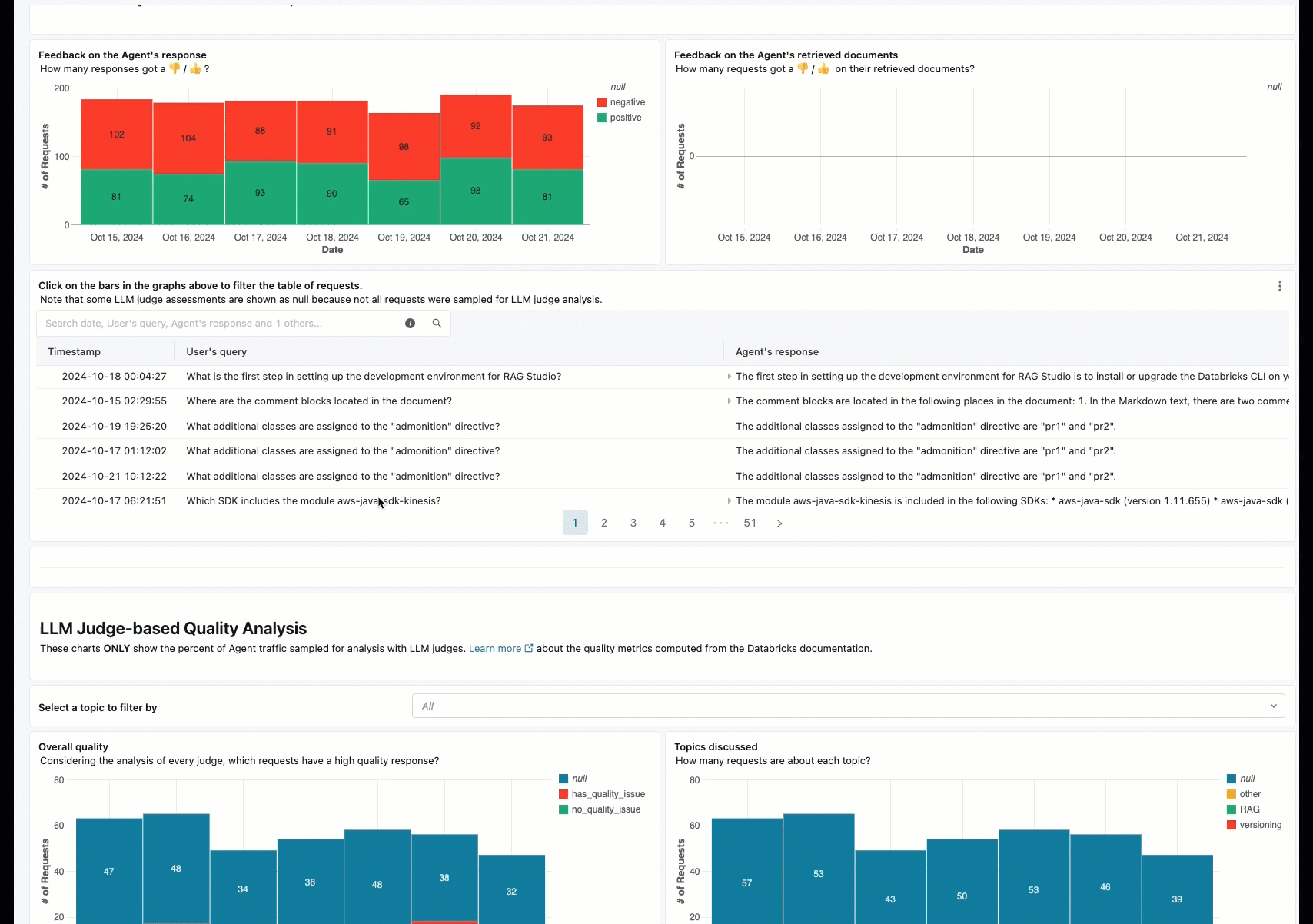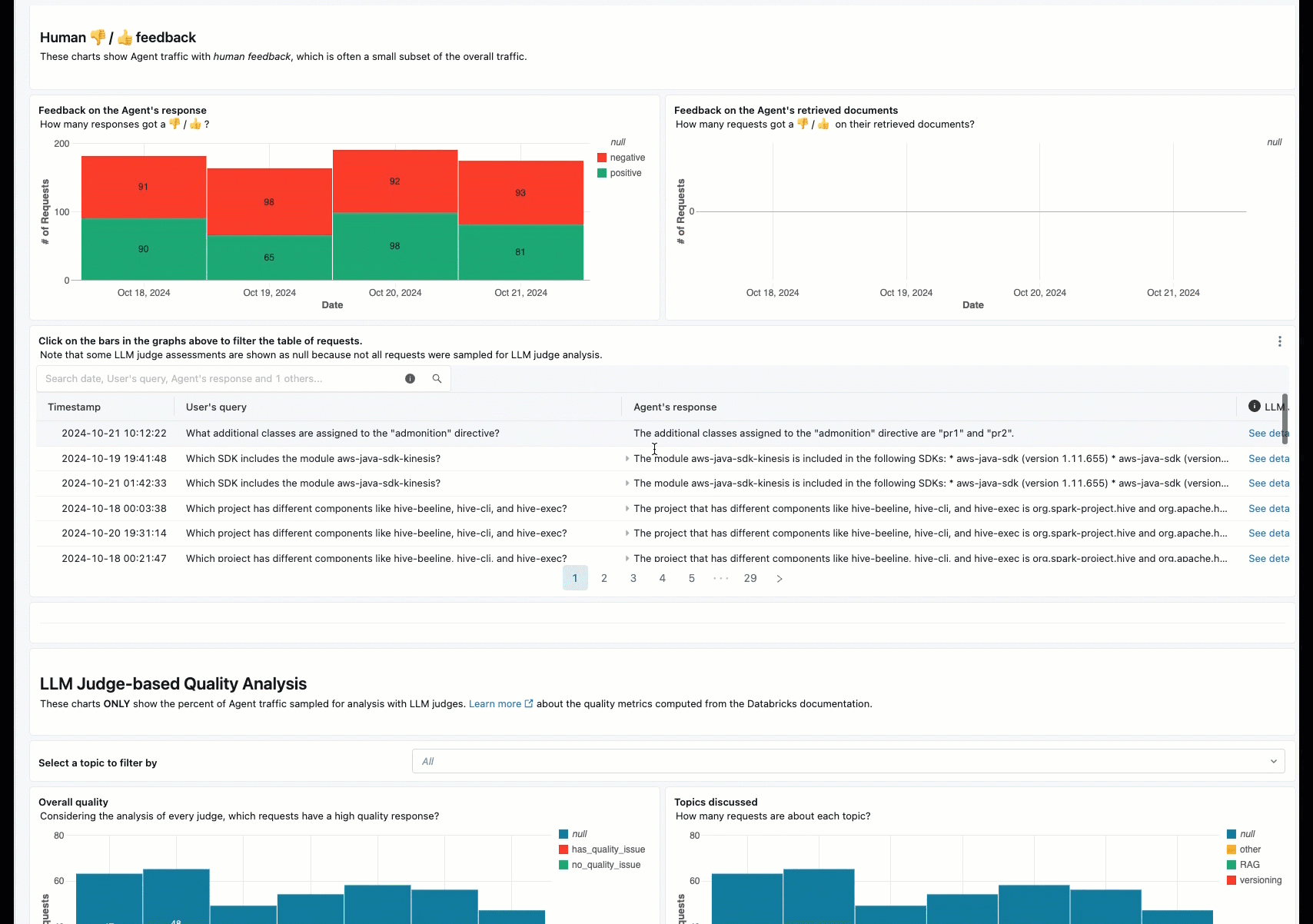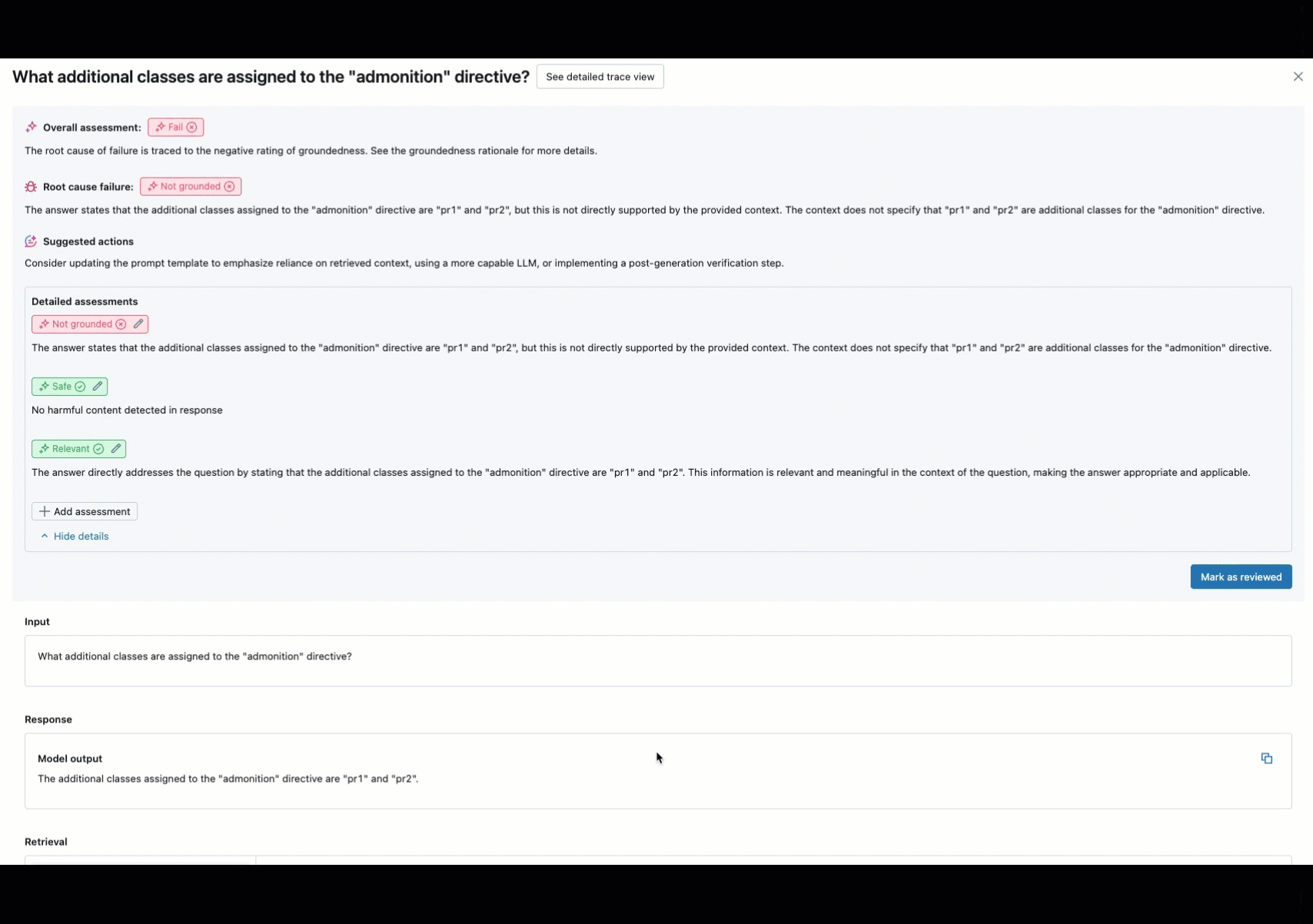
联机监视是确保代理按预期处理实际请求的关键方面。 使用下面提供的笔记本,可以对通过代理服务终结点提供的请求持续运行代理评估。 笔记本会生成一个仪表板,用于在生产请求上显示 代理输出的质量指标 以及用户反馈(竖起大拇指或大拇 👍 指 👎)。 此反馈可以通过利益干系人提供的评审应用或生产终结点上的反馈 API 到达,这些终结点允许捕获最终用户的反应。 利用仪表板,可以按不同维度对指标进行切片,包括按时间、用户反馈、传递/失败状态和输入请求的主题(例如,了解特定主题是否与质量较低的输出相关)。 此外,还可以更深入地了解具有低质量响应的单个请求,以便进一步调试这些请求。 所有项目(如仪表板)都可以完全自定义。
要求
通过代理评估持续处理生产流量
以下示例笔记本演示如何从代理服务终结点对请求日志运行代理评估。 若要运行笔记本,请执行以下步骤:
- 在工作区中导入笔记本(说明)。 可以单击下面的“导入复制链接”按钮获取导入的 URL。
- 填写导入笔记本顶部的必需参数。
- 已部署代理的服务终结点的名称。
- 采样请求的采样率介于 0.0 和 1.0 之间。 对流量量较高的终结点使用较低的速率。
- (可选)用于存储生成的项目(如仪表板)的工作区文件夹。 默认值为主文件夹。
- (可选)用于对输入请求进行分类的主题列表。 默认值是包含单个 catch-all 主题的列表。
- 在导入的笔记本中单击“ 全部 运行”。 这将在 30 天内对生产日志进行初始处理,并初始化汇总质量指标的仪表板。
- 单击“计划”以创建作业以定期运行笔记本。 该作业将以增量方式处理生产日志,并使仪表板保持最新状态。
笔记本需要无服务器计算或运行 Databricks Runtime 15.2 或更高版本的群集。 当持续监视具有大量请求的终结点上的生产流量时,我们建议设置更频繁的计划。 例如,每小时计划适用于每小时超过 10,000 个请求的终结点,采样率为 10%。
在生产流量笔记本上运行代理评估
针对评估指标创建警报
计划笔记本定期运行后,可以添加警报,以在质量指标低于预期时收到通知。 这些警报的创建和使用方式与其他 Databricks SQL 警报相同。 首先,针对示例笔记本生成的评估请求日志表创建 Databricks SQL 查询 。 以下代码演示了对评估请求表的示例查询,筛选过去一小时内的请求:
SELECT
`date`,
AVG(pass_indicator) as avg_pass_rate
FROM (
SELECT
*,
CASE
WHEN `response/overall_assessment/rating` = 'yes' THEN 1
WHEN `response/overall_assessment/rating` = 'no' THEN 0
ELSE NULL
END AS pass_indicator
-- The eval requests log table is generated by the example notebook
FROM {eval_requests_log_table_name}
WHERE `date` >= CURRENT_TIMESTAMP() - INTERVAL 1 DAY
)
GROUP BY ALL
然后,创建 Databricks SQL 警报 以所需的频率评估查询,并在触发警报时发送通知。 下图显示了在总体通过率低于 80% 时发送警报的示例配置。
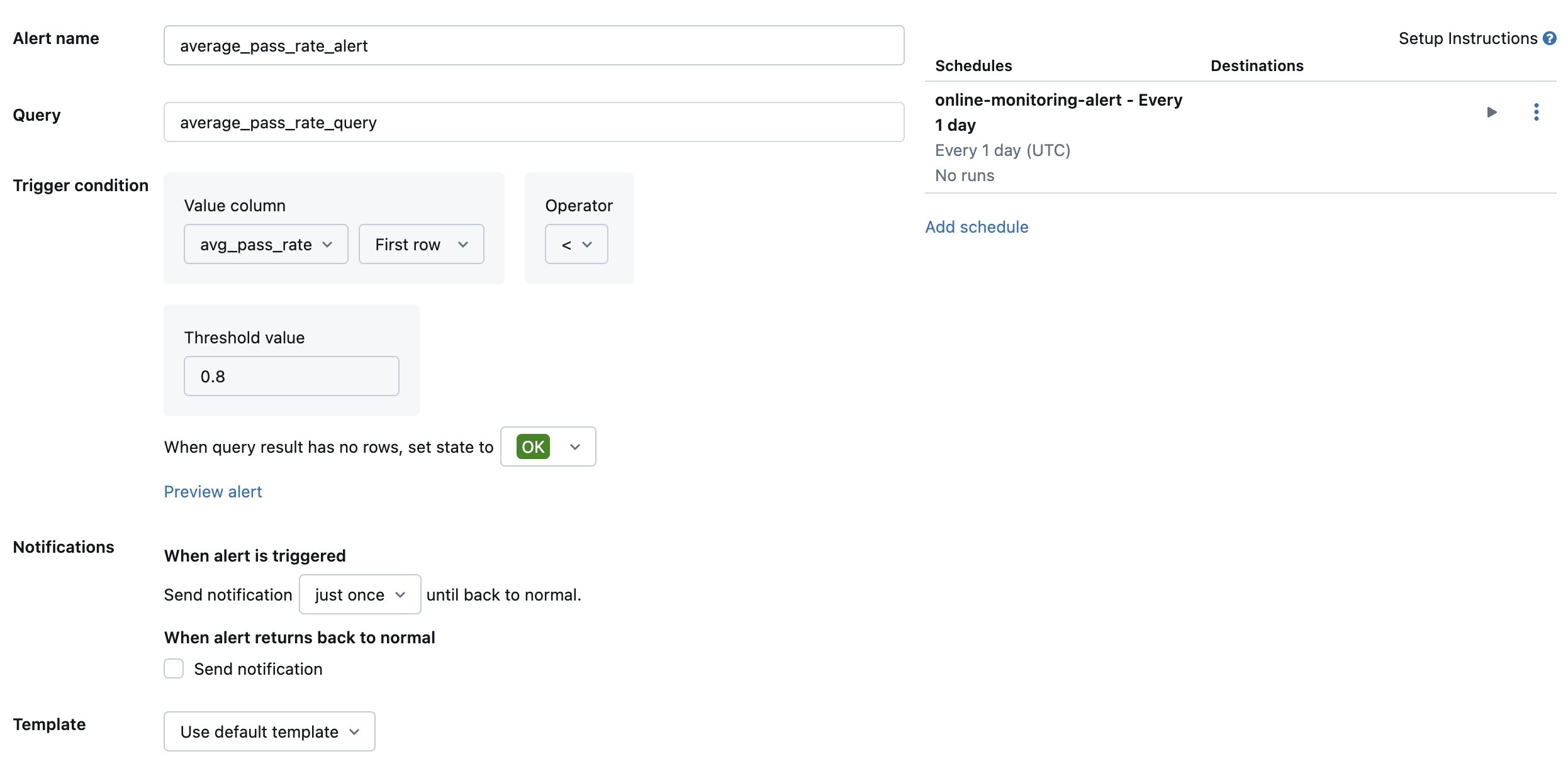
默认情况下,发送电子邮件通知。 还可以设置 Webhook 或向 Slack 或 PagerDuty 等其他应用程序发送通知。
将选定的生产日志添加到评审应用以供人工评审
当用户提供有关请求的反馈时,你可能希望请求主题专家审查带有负面反馈的请求(对响应或检索有经验的请求)。 为此,请将特定日志添加到 评审应用 ,以请求专家评审。
以下代码演示了对评估日志表的示例查询,以检索每个请求 ID 和源 ID 的最新人工评估:
with ranked_logs as (
select
`timestamp`,
request_id,
source.id as source_id,
text_assessment.ratings["answer_correct"]["value"] as text_rating,
retrieval_assessment.ratings["answer_correct"]["value"] as retrieval_rating,
retrieval_assessment.position as retrieval_position,
row_number() over (
partition by request_id, source.id, retrieval_assessment.position order by `timestamp` desc
) as rank
from {assessment_log_table_name}
)
select
request_id,
source_id,
text_rating,
retrieval_rating
from ranked_logs
where rank = 1
order by `timestamp` desc
在以下代码中,将行human_ratings_query = "..."中替换为...类似于上述查询的查询。 然后,以下代码提取带有负面反馈的请求,并将其添加到评审应用:
from databricks import agents
human_ratings_query = "..."
human_ratings_df = spark.sql(human_ratings_query).toPandas()
# Filter out the positive ratings, leaving only negative and "IDK" ratings
negative_ratings_df = human_ratings_df[
(human_ratings_df["text_rating"] != "positive") | (human_ratings_df["retrieval_rating"] != "positive")
]
negative_ratings_request_ids = negative_ratings_df["request_id"].drop_duplicates().to_list()
agents.enable_trace_reviews(
model_name=YOUR_MODEL_NAME,
request_ids=negative_ratings_request_ids,
)
有关评审应用的更多详细信息,请参阅 获取有关代理应用程序质量的反馈。