你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
快速入门:将 Azure Cosmos DB for Table 与用于 Python 的 Azure SDK 配合使用
在本快速入门中,你将使用用于 Python 的 Azure SDK 部署一个基本的 Azure Cosmos DB for Table 应用程序。 Azure Cosmos DB for Table 是一种无架构数据存储,允许应用程序在云中存储结构化表数据。 你将了解如何使用 Azure SDK for Python 在 Azure Cosmos DB 资源中创建表、行并执行基本任务。
API 参考文档 | 库源代码 | 包 (PyPI) | Azure Developer CLI
先决条件
- Azure 开发人员 CLI
- Docker Desktop
- Python 3.12
如果没有 Azure 帐户,请在开始前创建一个免费帐户。
初始化项目
使用 Azure Developer CLI (azd) 创建 Azure Cosmos DB for Table 帐户并部署容器化示例应用程序。 示例应用程序使用客户端库来管理、创建、读取和查询示例数据。
在空目录中打开终端。
如果尚未经过身份验证,请使用
azd auth login向 Azure Developer CLI 进行身份验证。 按照该工具指定的步骤,使用首选 Azure 凭据向 CLI 进行身份验证。azd auth login使用
azd init来初始化项目。azd init --template cosmos-db-table-python-quickstart在初始化期间,配置唯一的环境名称。
使用
azd up部署 Azure Cosmos DB 帐户。 Bicep 模板还部署示例 Web 应用程序。azd up在预配过程中,选择订阅、所需位置和目标资源组。 等待预配过程完成。 此过程可能需要大约 5 分钟。
预配 Azure 资源后,输出中将包含指向正在运行的 Web 应用程序的 URL。
Deploying services (azd deploy) (✓) Done: Deploying service web - Endpoint: <https://[container-app-sub-domain].azurecontainerapps.io> SUCCESS: Your application was provisioned and deployed to Azure in 5 minutes 0 seconds.使用控制台中的 URL 在浏览器中导航到 Web 应用程序。 观察正在运行的应用的输出。
安装客户端库
客户端库可通过 PyPi 作为 azure-data-tables 包使用。
打开终端并导航到
/src文件夹。cd ./src使用
pip install安装azure-data-tables包(如果尚未安装)。pip install azure-data-tables打开并查看 src/requirements.txt 文件以验证
azure-data-tables项是否存在。
对象模型
| 名称 | 描述 |
|---|---|
TableServiceClient |
此类型是主要客户端类型,用于管理帐户范围的元数据或数据库。 |
TableClient |
此类型表示帐户中表的客户端。 |
代码示例
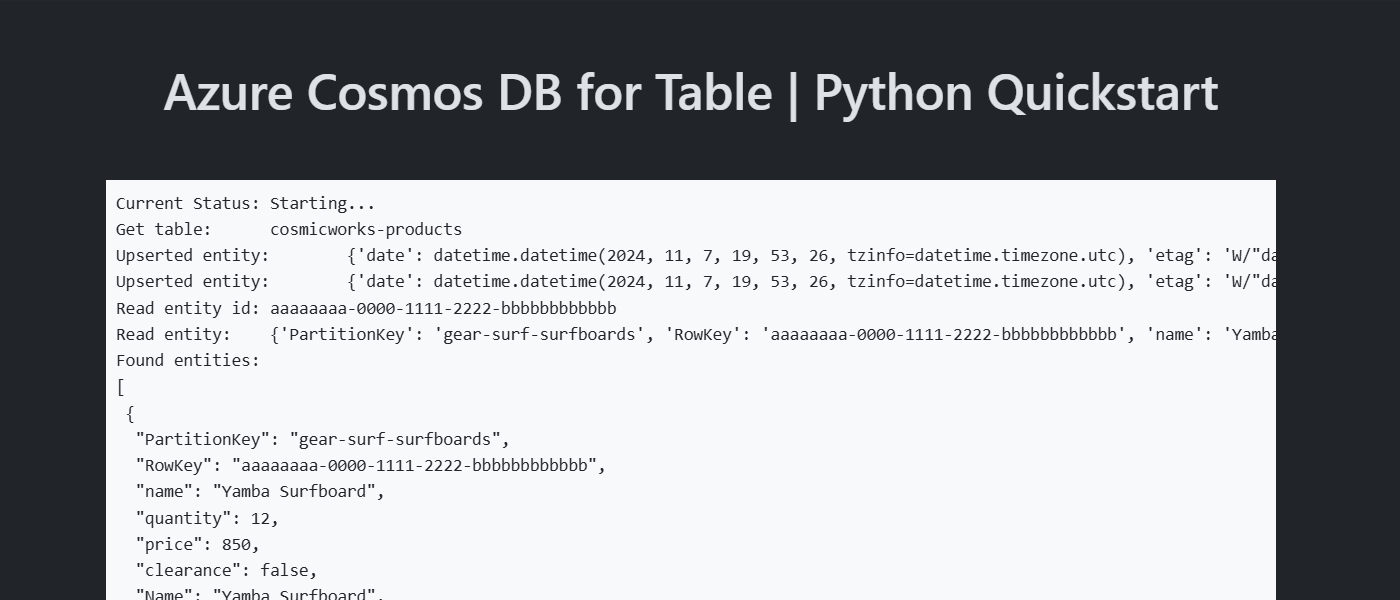
模板中的示例代码使用名为 cosmicworks-products 的表。 cosmicworks-products 表包含每个产品的详细信息,例如名称、类别、数量、价格、唯一标识符和销售标志。 容器使用唯一标识符作为行键,使用类别作为分区键。
验证客户端
此示例创建 TableServiceClient 类型的新实例。
credential = DefaultAzureCredential()
client = TableServiceClient(endpoint="<azure-cosmos-db-table-account-endpoint>", credential=credential)
获取表
此示例使用 TableServiceClient 类型的 GetTableClient 函数创建 TableClient 类型的实例。
table = client.get_table_client("<azure-cosmos-db-table-name>")
创建实体
在表中创建新实体的最简单方法是,创建新对象并确保指定必需的 RowKey 和 PartitionKey 属性。
new_entity = {
"RowKey": "aaaaaaaa-0000-1111-2222-bbbbbbbbbbbb",
"PartitionKey": "gear-surf-surfboards",
"Name": "Yamba Surfboard",
"Quantity": 12,
"Sale": False,
}
使用 upsert_entity 在表中创建实体。
created_entity = table.upsert_entity(new_entity)
获取实体
可使用 get_entity 从表中检索特定实体。
existing_entity = table.get_entity(
row_key="aaaaaaaa-0000-1111-2222-bbbbbbbbbbbb",
partition_key="gear-surf-surfboards",
)
查询实体
插入实体后,还可使用 query_entities 和字符串 OData 筛选器运行查询以获取与特定筛选器匹配的所有实体。
category = "gear-surf-surfboards"
# Ensure the value is OData-compliant by escaping single quotes
safe_category = category.replace("'", "''")
filter = f"PartitionKey eq '{safe_category}'"
entities = table.query_entities(query_filter=filter)
使用 for 循环分析查询的分页结果。
for entity in entities:
# Do something
清理资源
不再需要示例应用程序或资源时,请删除相应的部署和所有资源。
azd down