你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
教程:将 Azure Cache for Redis 用作语义缓存
在本教程中,你将使用 Azure Cache for Redis 作为基于 AI 的大型语言模型 (LLM) 的语义缓存。 使用 Azure OpenAI 服务生成对查询的 LLM 响应,并使用 Azure Cache for Redis 来缓存这些响应,从而更快地提供响应并降低成本。
由于 Azure Cache for Redis 提供内置矢量搜索功能,因此还可以执行语义缓存。 可以为相同的查询返回缓存响应,也可以为含义相似的查询返回缓存响应,即使文本并不相同。
本教程介绍如何执行下列操作:
- 创建为语义缓存配置的 Azure Cache for Redis 实例
- 使用 LangChain 其他常用的 Python 库。
- 使用 Azure OpenAI 服务从 AI 模型生成文本并缓存结果。
- 了解通过使用 LLM 缓存带来的性能提升。
重要
本教程将指导你构建 Jupyter Notebook。 可以使用 Python 代码文件 (.py) 按本教程操作并获取相似结果,但需要将本教程中的所有代码块添加到 .py 文件中并执行一次以查看结果。 换句话说,Jupyter Notebook 在执行单元时会提供中间结果,但这不是在 Python 代码文件中操作时应产生的行为。
重要
如果想要改用已完成的 Jupyter 笔记本,请下载名为 semanticcache.ipynb 的 Jupyter 笔记本文件,并将其保存到新的 semanticcache 文件夹中。
先决条件
Azure 订阅 - 免费创建订阅
在所需的 Azure 订阅中授予对 Azure OpenAI 的访问权限。目前,必须申请 Azure OpenAI 的访问权限。 可以通过在 https://aka.ms/oai/access 上填写表单来申请对 Azure OpenAI 的访问权限。
Jupyter 笔记本(可选)
一个 Azure OpenAI 资源,已部署 text-embedding-ada-002(版本 2)和 gpt-35-turbo-instruct 模型。 这些模型当前仅在特定区域中可用。 有关如何部署模型的说明,请参阅资源部署指南。
创建用于 Redis 的 Azure 缓存实例
按照快速入门:创建 Redis Enterprise 缓存指南进行操作。 在“高级”页上,确保已添加 RediSearch 模块并选择了“企业”群集策略。 其他所有设置都可以与快速入门中所述的默认值匹配。
需要花费几分钟时间来创建缓存。 在此期间,可以继续执行下一步。
设置开发环境
在本地计算机上,在通常保存项目的位置创建名为 semanticcache 的文件夹。
在文件夹中创建新的 python 文件 (tutorial.py) 或 Jupyter 笔记本 (tutorial.ipynb)。
安装所需的 Python 包:
pip install openai langchain redis tiktoken
创建 Azure OpenAI 模型
请确保已将两个模型部署到 Azure OpenAI 资源:
提供文本响应的 LLM。 本教程使用 GPT-3.5-turbo-instruct 模型。
一个嵌入模型,将查询转换为矢量,以将其与过去的查询进行比较。 本教程使用 text-embedding-ada-002(版本 2)模型。
如需更多详细的说明,请参阅部署模型。 记录为每个模型部署选择的名称。
导入库并设置连接信息
若要成功对 Azure OpenAI 发出调用,需要一个终结点和一个密钥。 还需要一个终结点和一个密钥才能连接到 Azure Cache for Redis。
转到 Azure 门户中的 Azure OpenAI 资源。
在 Azure OpenAI 资源的“资源管理”部分找到“终结点和密钥”。 复制终结点和访问密钥,因为在对 API 调用进行身份验证时需要这两项。 示例终结点为:
https://docs-test-001.openai.azure.com。 可以使用KEY1或KEY2。转到 Azure 门户中 Azure Cache for Redis 资源的“概述”页。 复制终结点。
找到“设置”部分中的“访问密钥”。 复制访问密钥。 可以使用
Primary或Secondary。将以下代码添加到新的代码单元:
# Code cell 2 import openai import redis import os import langchain from langchain.llms import AzureOpenAI from langchain.embeddings import AzureOpenAIEmbeddings from langchain.globals import set_llm_cache from langchain.cache import RedisSemanticCache import time AZURE_ENDPOINT=<your-openai-endpoint> API_KEY=<your-openai-key> API_VERSION="2023-05-15" LLM_DEPLOYMENT_NAME=<your-llm-model-name> LLM_MODEL_NAME="gpt-35-turbo-instruct" EMBEDDINGS_DEPLOYMENT_NAME=<your-embeddings-model-name> EMBEDDINGS_MODEL_NAME="text-embedding-ada-002" REDIS_ENDPOINT = <your-redis-endpoint> REDIS_PASSWORD = <your-redis-password>使用 Azure OpenAI 部署中的密钥和终结点值更新
API_KEY和RESOURCE_ENDPOINT的值。将
LLM_DEPLOYMENT_NAME和EMBEDDINGS_DEPLOYMENT_NAME设置为 Azure OpenAI 服务中部署的两个模型的名称。使用 Azure Cache for Redis 实例中的终结点和密钥值更新
REDIS_ENDPOINT和REDIS_PASSWORD。重要
强烈建议使用环境变量或机密管理器(如 Azure 密钥保管库)来传入 API 密钥、终结点和部署名称信息。 为了简便,此处以纯文本形式设置这些变量。
执行代码单元 2。
初始化 AI 模型
接下来,初始化 LLM 和嵌入模型
将以下代码添加到新的代码单元:
# Code cell 3 llm = AzureOpenAI( deployment_name=LLM_DEPLOYMENT_NAME, model_name="gpt-35-turbo-instruct", openai_api_key=API_KEY, azure_endpoint=AZURE_ENDPOINT, openai_api_version=API_VERSION, ) embeddings = AzureOpenAIEmbeddings( azure_deployment=EMBEDDINGS_DEPLOYMENT_NAME, model="text-embedding-ada-002", openai_api_key=API_KEY, azure_endpoint=AZURE_ENDPOINT, openai_api_version=API_VERSION )执行代码单元 3。
将 Redis 设置为语义缓存
接下来,将 Redis 指定为 LLM 的语义缓存。
将以下代码添加到新的代码单元:
# Code cell 4 redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT set_llm_cache(RedisSemanticCache(redis_url = redis_url, embedding=embeddings, score_threshold=0.05))重要
score_threshold参数的值决定两个查询需要有多相似才能返回缓存结果。 数字越小,查询的相似度越高。 可以对这个值进行调整,使其适合你的应用。执行代码单元 4。
查询并从 LLM 获取响应
最后,查询 LLM 以获取 AI 生成的响应。 如果使用 Jupyter 笔记本,则可以在单元格顶部添加 %%time,以输出执行代码所需的时间。
将以下代码添加到新的代码单元并执行:
# Code cell 5 %%time response = llm("Please write a poem about cute kittens.") print(response)应会看到一个输出,输出如下所示:
Fluffy balls of fur, With eyes so bright and pure, Kittens are a true delight, Bringing joy into our sight. With tiny paws and playful hearts, They chase and pounce, a work of art, Their innocence and curiosity, Fills our hearts with such serenity. Their soft meows and gentle purrs, Are like music to our ears, They curl up in our laps, And take the stress away in a snap. Their whiskers twitch, they're always ready, To explore and be adventurous and steady, With their tails held high, They're a sight to make us sigh. Their tiny faces, oh so sweet, With button noses and paw-sized feet, They're the epitome of cuteness, ... Cute kittens, a true blessing, In our hearts, they'll always be reigning. CPU times: total: 0 ns Wall time: 2.67 sWall time显示值 2.67 秒。 这是查询 LLM 和 LLM 生成响应所需的实际时间。再次执行单元格 5。 你应该会看到完全相同的输出,但操作时间更短:
Fluffy balls of fur, With eyes so bright and pure, Kittens are a true delight, Bringing joy into our sight. With tiny paws and playful hearts, They chase and pounce, a work of art, Their innocence and curiosity, Fills our hearts with such serenity. Their soft meows and gentle purrs, Are like music to our ears, They curl up in our laps, And take the stress away in a snap. Their whiskers twitch, they're always ready, To explore and be adventurous and steady, With their tails held high, They're a sight to make us sigh. Their tiny faces, oh so sweet, With button noses and paw-sized feet, They're the epitome of cuteness, ... Cute kittens, a true blessing, In our hearts, they'll always be reigning. CPU times: total: 0 ns Wall time: 575 ms操作时间似乎缩短了 5 倍 - 一直缩短到 575 毫秒。
将查询从
Please write a poem about cute kittens更改为Write a poem about cute kittens,然后再次运行单元格 5。 应会看到完全相同的输出和比原始查询短的操作时间。 尽管查询已更改,但查询的语义意义保持不变,因此返回了相同的缓存输出。 这是语义缓存的优势!
更改相似性阈值
尝试运行具有其他含义的类似查询,如
Please write a poem about cute puppies。 请注意,缓存的结果也在此处返回。puppies一词的语义含义非常接近于kittens一词,因此会返回缓存结果。可以修改相似性阈值,以决定语义缓存何时应返回缓存结果,何时应返回来自 LLM 的新输出。 在代码单元格 4 中,将
score_threshold从0.05更改为0.01:# Code cell 4 redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT set_llm_cache(RedisSemanticCache(redis_url = redis_url, embedding=embeddings, score_threshold=0.01))再次尝试查询
Please write a poem about cute puppies。 应会收到特定于小狗的新输出:Oh, little balls of fluff and fur With wagging tails and tiny paws Puppies, oh puppies, so pure The epitome of cuteness, no flaws With big round eyes that melt our hearts And floppy ears that bounce with glee Their playful antics, like works of art They bring joy to all they see Their soft, warm bodies, so cuddly As they curl up in our laps Their gentle kisses, so lovingly Like tiny, wet, puppy taps Their clumsy steps and wobbly walks As they explore the world anew Their curiosity, like a ticking clock Always eager to learn and pursue Their little barks and yips so sweet Fill our days with endless delight Their unconditional love, so complete ... For they bring us love and laughter, year after year Our cute little pups, in every way. CPU times: total: 15.6 ms Wall time: 4.3 s可能需要根据你的应用微调相似性阈值,以确保在确定要缓存的查询时使用正确的敏感度。
清理资源
要继续使用在本文中创建的资源,请保留资源组。
否则,如果已完成资源,可以删除创建的 Azure 资源组以避免产生费用。
重要
删除资源组的操作不可逆。 删除资源组时,包含在其中的所有资源会被永久删除。 请确保不会意外删除错误的资源组或资源。 如果在现有资源组(其中包含要保留的资源)内创建了此资源,可以逐个删除这些资源,而不是删除资源组。
删除资源组的步骤
登录到 Azure 门户,然后选择“资源组”。
选择要删除的资源组。
如果有多个资源组,请使用“筛选任何字段...”框,键入为本文创建的资源组的名称。 在结果列表中选择资源组。
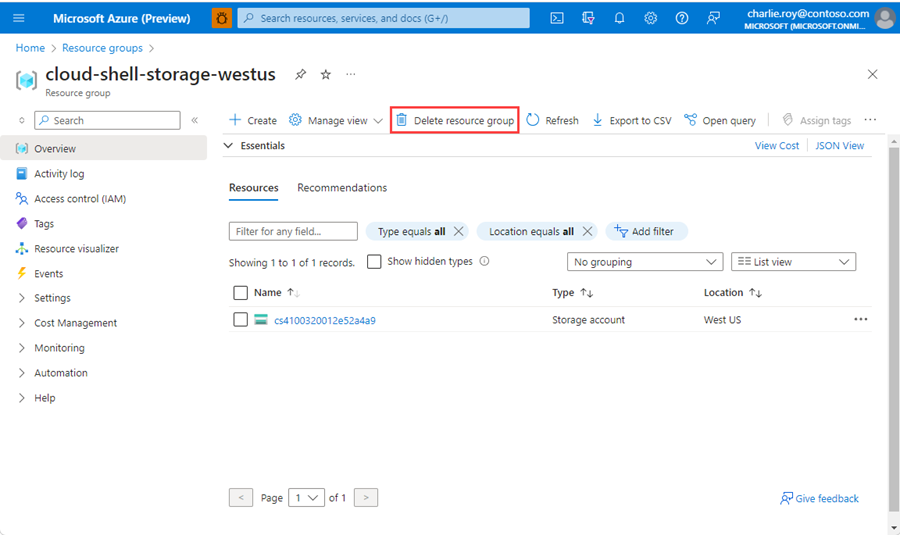
选择“删除资源组”。
系统会要求确认是否删除资源组。 键入资源组的名称进行确认,然后选择“删除”。
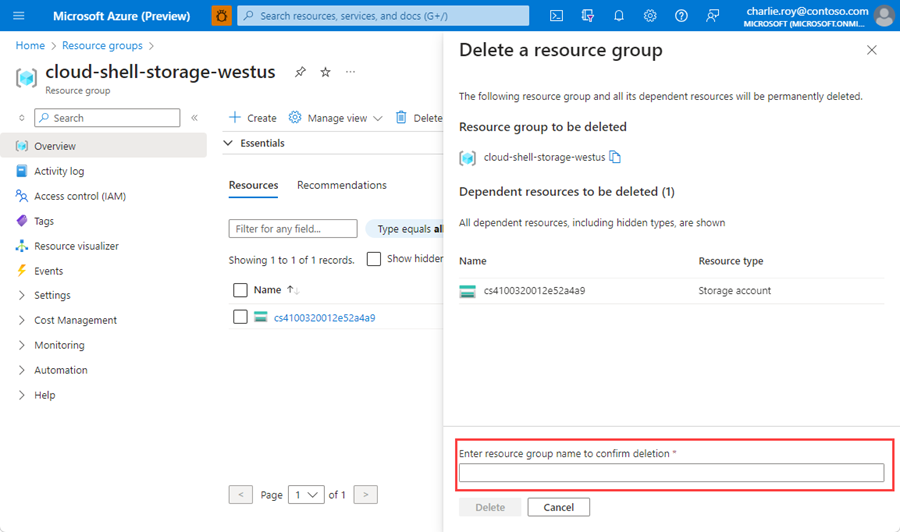
片刻之后,将会删除该资源组及其所有资源。
相关内容
- 详细了解 Azure Cache for Redis
- 详细了解 Azure Cache for Redis 矢量搜索功能
- 教程:在 Azure Cache for Redis 中使用矢量相似性搜索
- 了解如何使用 OpenAI 和 Redis 生成 AI 支持的应用
- 生成具有语义答案的问答应用