你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
教程:使用 Azure Cache for Redis 对 Azure OpenAI 嵌入内容执行矢量相似性搜索
在本教程中,你将演练一个基本的矢量相似性搜索用例。 你将使用 Azure OpenAI 服务生成的嵌入内容和 Azure Cache for Redis 企业层的内置矢量搜索功能来查询电影数据集,以查找最相关的匹配项。
本教程使用 Wikipedia 电影情节数据集,该数据集包含 Wikipedia 1901 至 2017 年间超过 35,000 部电影的情节描述。 该数据集包括每部电影的情节摘要,以及电影上映年份、导演、主演和类型等元数据。 你将按照本教程中的步骤根据情节摘要生成嵌入内容,并使用其他元数据运行混合查询。
本教程介绍如何执行下列操作:
- 创建为矢量搜索配置的 Azure Cache for Redis 实例
- 安装 Azure OpenAI 和其他必要的 Python 库。
- 下载电影数据集并将其准备就绪进行分析。
- 使用 text-embedding-ada-002(版本 2)模型生成嵌入内容。
- 在 Azure Cache for Redis 中创建矢量索引
- 使用余弦相似性对搜索结果进行排名。
- 通过 RediSearch 使用混合查询功能来预筛选数据,使矢量搜索更加强大。
重要
本教程将指导你构建 Jupyter Notebook。 可以使用 Python 代码文件 (.py) 按本教程操作并获取相似结果,但需要将本教程中的所有代码块添加到 .py 文件中并执行一次以查看结果。 换句话说,Jupyter Notebook 在执行单元时会提供中间结果,但这不是在 Python 代码文件中操作时应产生的行为。
重要
如果想要改用已完成的 Jupyter 笔记本,请下载名为 tutorial.ipynb 的 Jupyter 笔记本文件,并将其保存到新的 redis-vector 文件夹中。
先决条件
- Azure 订阅 - 免费创建订阅
- 已在所需的 Azure 订阅中授予对 Azure OpenAI 的访问权限。 目前,你必须进行申请才能访问 Azure OpenAI。 可以通过在 https://aka.ms/oai/access 上填写表单来申请对 Azure OpenAI 的访问权限。
- Python 3.8 或更高版本
- Jupyter 笔记本(可选)
- 部署了 text-embedding-ada-002(版本 2) 模型的 Azure OpenAI 资源。 此模型当前仅在特定区域中可用。 有关如何部署模型的说明,请参阅资源部署指南。
创建 Azure Cache for Redis 实例
按照快速入门:创建 Redis Enterprise 缓存指南进行操作。 在“高级”页上,确保已添加 RediSearch 模块并选择了企业群集策略。 其他所有设置都可以与快速入门中所述的默认值匹配。
需要花费几分钟时间来创建缓存。 在此期间,可以继续执行下一步。
设置开发环境
在本地计算机上,在通常保存项目的位置创建名为 redis-vector 的文件夹。
在文件夹中创建新的 python 文件 (tutorial.py) 或 Jupyter 笔记本 (tutorial.ipynb)。
安装所需的 Python 包:
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
下载数据集
在网页浏览器中,导航到 https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots。
使用 Kaggle 登录或注册。 下载文件需要注册。
选择 Kaggle 上的“下载”链接以下载 archive.zip 文件。
提取 archive.zip 文件,并将 wiki_movie_plots_deduped.csv 移动到 redis-vector 文件夹中。
导入库并设置连接信息
若要成功对 Azure OpenAI 发出调用,需要一个终结点和一个密钥。 还需要一个终结点和一个密钥才能连接到 Azure Cache for Redis。
转到 Azure 门户中的 Azure OpenAI 资源。
可以在“资源管理”部分找到“终结点和密钥”。 复制终结点和访问密钥,因为在对 API 调用进行身份验证时需要这两项。 示例终结点为:
https://docs-test-001.openai.azure.com。 可以使用KEY1或KEY2。转到 Azure 门户中 Azure Cache for Redis 资源的“概述”页。 复制终结点。
找到“设置”部分中的“访问密钥”。 复制访问密钥。 可以使用
Primary或Secondary。将以下代码添加到新的代码单元:
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"使用 Azure OpenAI 部署中的密钥和终结点值更新
API_KEY和RESOURCE_ENDPOINT的值。DEPLOYMENT_NAME应设置为使用text-embedding-ada-002 (Version 2)嵌入内容模型的部署的名称,并且MODEL_NAME应设置为使用的特定嵌入内容模型。使用 Azure Cache for Redis 实例中的终结点和密钥值更新
REDIS_ENDPOINT和REDIS_PASSWORD。重要
强烈建议使用环境变量或机密管理器(如 Azure 密钥保管库)来传入 API 密钥、终结点和部署名称信息。 为了简便,此处以纯文本形式设置这些变量。
执行代码单元 2。
将数据集导入 pandas 并处理数据
接下来,将 csv 文件读取到 pandas 数据帧中。
将以下代码添加到新的代码单元:
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) df执行代码单元 3。 应会看到以下输出:

接下来,通过添加
id索引来处理数据,移除列标题中的空格,并筛选电影以仅显示 1970 年之后制作的且来自英语国家或地区的电影。 此筛选步骤可减少数据集中的电影数量,从而降低生成嵌入内容所需的成本和时间。 可以根据自己的偏好随意更改或删除筛选参数。若要筛选数据,请将以下代码添加到新的代码单元:
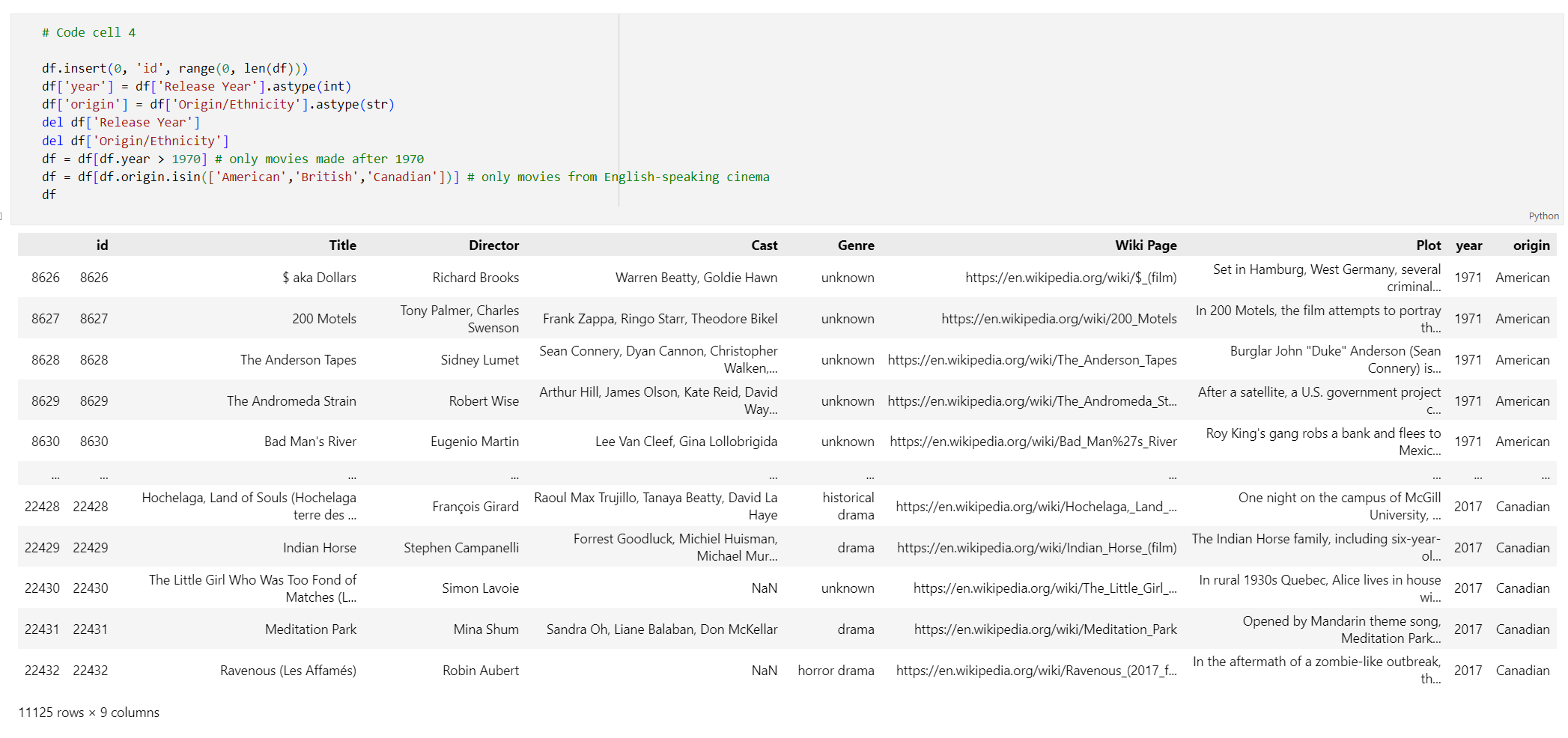
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema df执行代码单元 4。 应该看到以下结果:
创建一个函数,以通过删除空格和标点符号来清理数据,然后针对包含情节的数据帧使用该函数。
将以下代码添加到新的代码单元并执行:
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))最后,删除包含对于嵌入内容模型来说太长的情节描述的任何条目。 (换句话说,它们需要比 8192 令牌限制更多的令牌。)然后计算生成嵌入内容所需的令牌数。 这也会影响对嵌入内容生成的定价。
将以下代码添加到新的代码单元:
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))执行代码单元 6。 你应该会看到以下输出:
Number of movies: 11125 Number of tokens required:7044844重要
请参阅 Azure OpenAI 服务定价,根据所需的令牌数来计算生成嵌入内容的成本。


将数据帧加载到 LangChain
使用 DataFrameLoader 类将数据帧加载到 LangChain 中。 数据进入 LangChain 文档后,使用 LangChain 库生成嵌入内容并执行相似性搜索要容易得多。 将 Plot 设置为 page_content_column,以便在此列上生成嵌入内容。
将以下代码添加到新的代码单元并执行:
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
生成嵌入内容并将其加载到 Redis 中
现在,数据已筛选并加载到 LangChain 中,你将创建嵌入内容,以便可以查询每部电影的情节。 以下代码配置 Azure OpenAI、生成嵌入内容,并将嵌入内容矢量加载到 Azure Cache for Redis。
将以下代码添加到新的代码单元:
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")执行代码单元 8。 此步骤可能需要 30 分钟以上的时间才能完成。 还会生成
redis_schema.yaml文件。 如果要在不重新生成嵌入内容的情况下连接到 Azure Cache for Redis 实例中的索引,则此文件非常有用。
重要
生成嵌入项的速度取决于 Azure OpenAI 模型可用的配额。 每分钟配额为 24 万个令牌,处理数据集中的 700 万个令牌大约需要 30 分钟。
运行矢量搜索查询
设置数据集、Azure OpenAI 服务 API 和 Redis 实例后,可以使用矢量进行搜索。 在此示例中,返回给定查询的前 10 个结果。
将以下代码添加到 Python 代码文件:
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')执行代码单元 9。 应会看到以下输出:
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)将返回相似性分数,以及按照相似性划分的电影顺序分级。 请注意,更具体的查询的相似性分数在列表中下降得更快。
混合搜索
由于 RediSearch 在矢量搜索的基础上还具有丰富的搜索功能,因此可以按数据集中的元数据(例如电影类型、演员、上映年份或导演)筛选结果。 在这种情况下,请根据类型
comedy进行筛选。将以下代码添加到新的代码单元:
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')执行代码单元 10。 应会看到以下输出:
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
借助 Azure Cache for Redis 和 Azure OpenAI 服务,可以使用嵌入内容和矢量搜索向应用程序添加强大的搜索功能。
清理资源
要继续使用在本文中创建的资源,请保留资源组。
否则,如果已完成资源,可以删除创建的 Azure 资源组以避免产生费用。
重要
删除资源组的操作不可逆。 删除资源组时,包含在其中的所有资源会被永久删除。 请确保不会意外删除错误的资源组或资源。 如果在现有资源组(其中包含要保留的资源)内创建了此资源,可以逐个删除这些资源,而不是删除资源组。
删除资源组的步骤
登录到 Azure 门户,然后选择“资源组”。
选择要删除的资源组。
如果有多个资源组,请使用“筛选任何字段...”框,键入为本文创建的资源组的名称。 在结果列表中选择资源组。
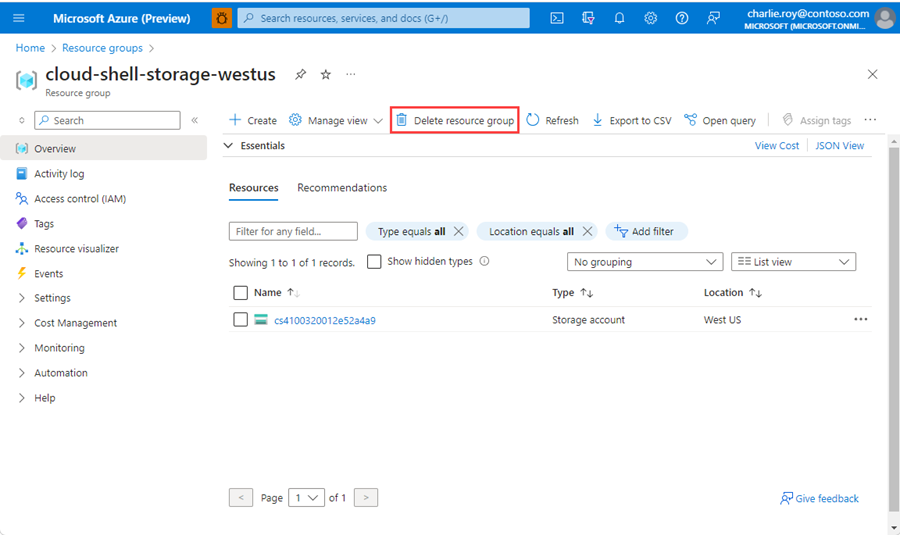
选择“删除资源组”。
系统会要求确认是否删除资源组。 键入资源组的名称进行确认,然后选择“删除”。
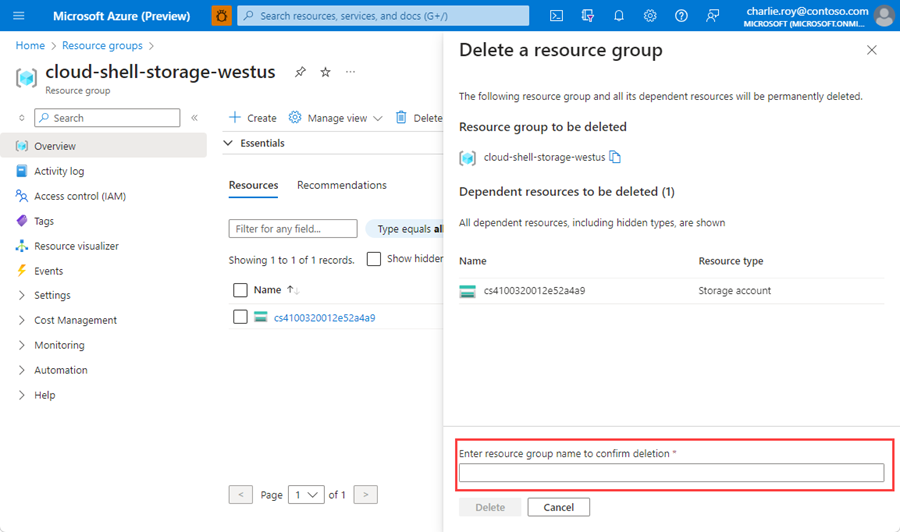
片刻之后,将会删除该资源组及其所有资源。
相关内容
- 详细了解 Azure Cache for Redis
- 详细了解 Azure Cache for Redis 矢量搜索功能
- 详细了解 Azure OpenAI 服务生成的嵌入内容
- 详细了解余弦相似性
- 了解如何使用 OpenAI 和 Redis 生成 AI 支持的应用
- 生成具有语义答案的问答应用