你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
添加专业语音训练数据集
准备好为应用程序创建自定义文本转语音的语音后,第一步是收集音频录制内容和关联的脚本,以开始训练语音模型。 有关录制语音样本的详细信息,请参阅教程。 语音服务会使用此数据创建与录制内容中的语音相匹配的、经过优化的独特声音。 训练该语音后,可以开始合成应用程序中的语音。
上传的所有数据都必须符合所选数据类型的要求。 在上传数据之正确设置数据格式非常重要,这可确保数据将由语音服务准确处理。 若要确认已正确设置数据格式,请参阅训练数据类型。
注意
- 标准订阅 (S0) 用户可以同时上传五个数据文件。 如果达到限制,请先等待,直至至少其中一个数据文件导入完毕。 然后重试。
- 每个订阅允许导入的数据文件的最大数目对于标准订阅 (S0) 用户而言为 500 个 .zip 文件。 有关详细信息,请参阅语音服务配额和限制。
上传数据
准备好上传数据后,请转到“准备训练数据”选项卡,添加第一个训练集并上传数据。 训练集是一组音频语句及其匹配脚本,用于训练声音模型。 可以使用训练集来整理训练数据。 该服务检查每个训练集的数据就绪情况。 可将多个数据导入一个训练集。
若要上传训练数据,请执行以下步骤:
- 登录 Speech Studio。
- 选择“自定义语音”>“你的项目名称”>“准备训练数据”>“上传数据”。
- 在“上传数据”向导中,选择数据类型,然后选择“下一步”。
- 从计算机中选择本地文件或输入 Azure Blob 存储 URL 以上传数据。
- 在“指定目标训练集”下,选择现有训练集或新建训练集。 如果创建了一个新的训练集,请确保在下拉列表中选择该训练集,然后再继续操作。
- 选择“下一步” 。
- 为自己的数据输入名称和说明,然后选择“下一步”。
- 查看上传详细信息,然后选择“提交”。
注意
不能使用重复的 ID。 具有相同 ID 的语句将被删除。
在训练中将会删除重复的音频名称。 确保所选数据在该 .zip 文件或多个 .zip 文件中未包含相同的音频名称。 如果语句 ID(在音频或脚本文件中)重复,就会遭到拒绝。
选择“提交”时,会自动验证数据文件。 数据验证包括针对音频文件执行一系列检查以验证文件格式、大小和采样率。 如果有任何错误,请修复它们并再次提交。
上传数据后,可以在训练集详细信息视图中检查详细信息。 在详细信息页上,可以进一步检查每个数据的发音问题和噪音级别。 句子级别的发音分数范围为 0-100。 评分低于 70 通常表示语音错误或脚本不匹配。 总分数低于 70 的语句将被拒绝。 口音重可能会降低发音分数,影响生成的数字语音。
联机解决数据问题
上传后,可以检查训练集的数据详细信息。 在继续训练语音模型之前,应尝试解决所有数据问题。
可以在 Speech Studio 中确定和解决每个语句的数据问题。
在详细信息页上,转到“接受的数据”或“拒绝的数据”页。 选择要更改的各个语句,然后选择“编辑”。
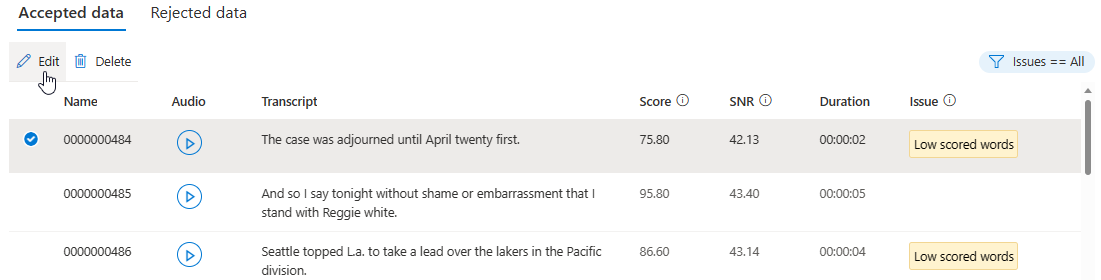
可以根据条件选择要显示的数据问题。
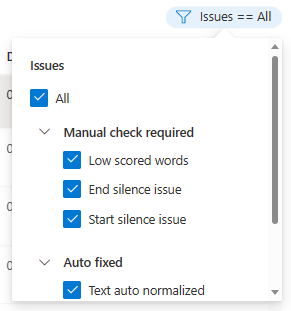
此时将显示“编辑”窗口。
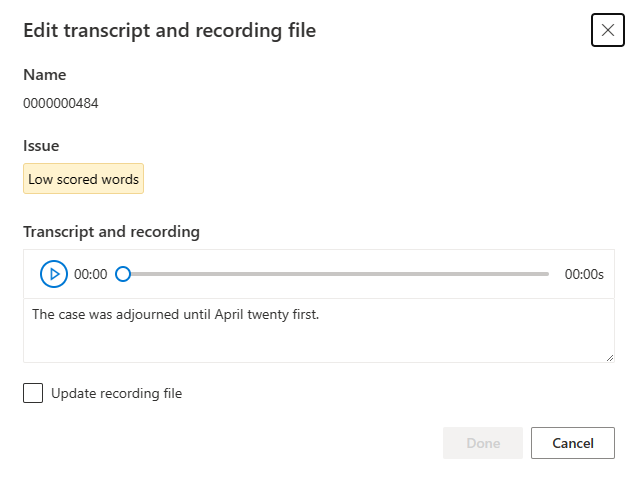
根据编辑窗口中的问题说明更新脚本或录制文件。
你可以在文本框中编辑脚本,然后单击“完成”
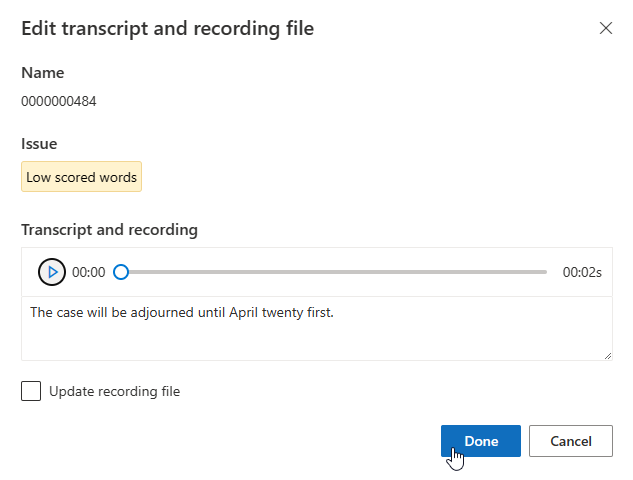
如果需要更新录制文件,请选择“更新录制文件”,然后上传已修复的录制文件 (.wav)。
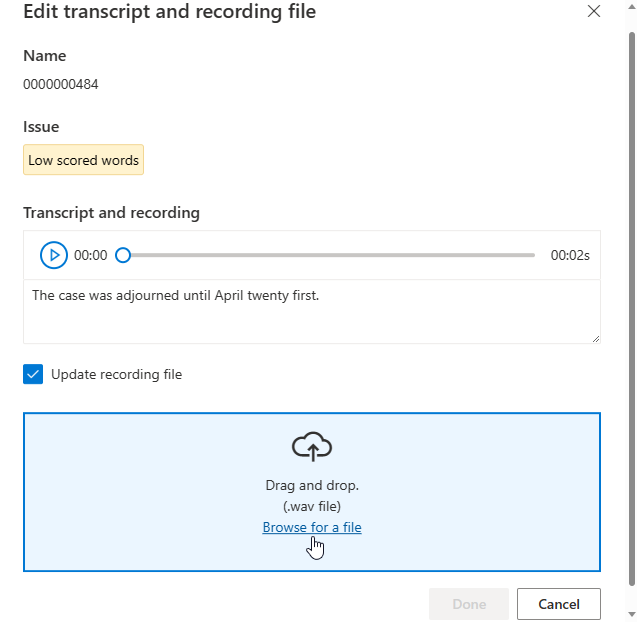
在对数据进行更改后,在使用此数据集进行训练之前,需要单击“分析数据”来检查数据质量。
在分析完成之前,无法为训练模型选择此训练集。
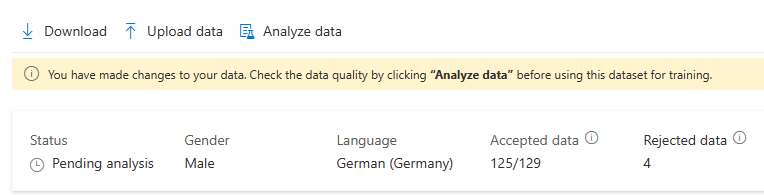
还可以通过选择有问题的语句并单击“删除”来删除它们。
典型的数据问题
问题分为三种类型。 请参考下面的表来检查相应类型的错误。
自动拒绝
出现这些错误的数据不会用于训练。 出现错误的导入数据会被忽略,因此无需删除它们。 可以联机修复这些数据错误,也可以再次上传更正后的数据进行训练。
| 类别 | 名称 | 说明 |
|---|---|---|
| 脚本 | 分隔符无效 | 必须使用制表符分隔语句 ID 和脚本内容。 |
| 脚本 | 脚本 ID 无效 | 脚本行 ID 必须是数字。 |
| 脚本 | 重复的脚本 | 脚本内容的每一行必须唯一。 该行与 {} 重复。 |
| 脚本 | 脚本太长 | 脚本长度必须小于 1,000 个字符。 |
| 脚本 | 没有匹配的音频 | 每条语句(脚本文件的每一行)的 ID 必须与音频 ID 匹配。 |
| 脚本 | 没有有效的脚本 | 此数据集中找不到有效的脚本。 修复详细问题列表中显示的脚本行。 |
| 音频 | 没有匹配的脚本 | 没有任何音频文件与脚本 ID 匹配。 .wav 文件的名称必须与脚本文件中的 ID 匹配。 |
| 音频 | 音频格式无效 | .wav 文件的音频格式无效。 使用 SoX 之类的音频工具检查 .wav 文件格式。 |
| 音频 | 采样率过低 | .wav 文件的采样率不能低于 16 KHz。 |
| 音频 | 音频太长 | 音频时长超过 30 秒。 将长音频拆分为多个文件。 最好让语句的长度短于 15 秒。 |
| 音频 | 无有效音频 | 在此数据集中找不到有效的音频。 检查音频数据,然后重新上传。 |
| 不匹配 | 低评分语句 | 句子级别发音评分低于 70。 查看脚本和音频内容,以确保它们匹配。 |
自动修复
以下错误会自动修复,但你应检查并确认修复是正确的。
| 类别 | 名称 | 说明 |
|---|---|---|
| 不匹配 | 静音已自动修复 | 检测到起始静音持续时间短于 100 毫秒,并已自动将其延长为 100 毫秒。 下载规范化数据集并进行查看。 |
| 不匹配 | 静音已自动修复 | 检测到末尾静音持续时间短于 100 毫秒,并已自动将其延长为 100 毫秒。 下载规范化数据集并进行查看。 |
| 脚本 | 文本自动规范化 | 对于数字、符号和缩写,文本会自动规范化。 查看脚本和音频,以确保它们匹配。 |
需要手动检查
下表中列出的未解决的错误会影响训练质量,但在训练期间不会排除带有这些错误的数据。 如需较高质量的训练,建议手动修复这些错误。
| 类别 | 名称 | 说明 |
|---|---|---|
| 脚本 | 非规范化文本 | 此脚本包含符号。 规范化这些符号,使之与音频匹配。 例如,规范化 / 为斜杠。 |
| 脚本 | 疑问语句不足 | 在所有语句中,至少应有 10% 的语句是疑问句。 这有助于声音模型正确表达疑问语调。 |
| 脚本 | 感叹语句不足 | 在所有语句中,至少应有 10% 的语句是感叹句。 这有助于声音模型正确表达惊叹语调。 |
| 脚本 | 没有有效的结束标点符号 | 在行尾添加以下标点符号之一:句号(半角“.”或全角“。”)、感叹号(半角“!”或全角“!”)或问号(半角“?”或全角“?”)。 |
| 音频 | 神经网络声音采样率低 | 建议将 .wav 文件的采样率设置为 24 KHz 或更高,以创建神经网络声音。 如果采样率较低,它将自动提升到 24 KHz。 |
| 数据量(Volume) | 总体音量过小 | 音量不应低于 -18 dB(最大音量的 10%)。 在录制示例或准备数据期间,将音量平均水平控制在适当范围内。 |
| 数据量(Volume) | 音量溢出 | 在第 {} 秒检测到音量溢出。 调整录制设备,以避免音量在达到峰值时溢出。 |
| 数据量(Volume) | 起始静音问题 | 前 100 毫秒的静音不纯。 降低录制噪音最低水平,并将前 100 毫秒保留为起始静音。 |
| 数据量(Volume) | 末尾静音问题 | 最后 100 毫秒的静音不纯。 降低录制噪音最低水平,并将最后 100 毫秒保留为末尾静音。 |
| 不匹配 | 字词评分低 | 查看脚本和音频内容以确保它们匹配,并控制噪音最低水平。 缩短长时间静音的时长,或将过长的音频拆分为多个语句。 |
| 不匹配 | 起始静音问题 | 在第一个字词前面听到了额外的音频。 查看脚本和音频内容以确保它们匹配,控制噪音最低水平,并使前 100 毫秒保持静音。 |
| 不匹配 | 末尾静音问题 | 在最后一个字词后面听到了额外的音频。 查看脚本和音频内容以确保它们匹配,控制噪音最低水平,并使最后 100 毫秒保持静音。 |
| 不匹配 | 信噪比低 | 音频 SNR 水平低于 20 dB。 建议至少为 35 dB。 |
| 不匹配 | 无可用评分 | 无法识别此音频中的语音内容。 检查音频和脚本内容,确保音频有效并与脚本匹配。 |
后续步骤
你需要一个训练数据集来创建专业语音。 训练数据集包括音频和脚本文件。 音频文件是语音配音员朗读脚本文件的录音。 脚本文件是音频文件的文本。
在本文中,你将创建一个训练集并获取其资源 ID。 然后,使用资源 ID,可以上传一组音频和脚本文件。
创建训练集
要创建训练集,请使用自定义语音 API 的 TrainingSets_Create 操作。 根据以下说明构造请求正文:
- 设置所需的
projectId属性。 请参阅创建项目。 - 将所需的
voiceKind属性设置为Male或Female。 以后将无法更改类型。 - 设置所需的
locale属性。 这应该是训练集数据的区域设置。 训练集的区域设置应与同意声明的区域设置相同。 以后无法更改此区域设置。 可在此处查找文本到语音区域设置列表。 - (可选)设置训练集说明的
description属性。 稍后可以更改训练集说明。
使用 URI 发出 HTTP PUT 请求,如以下 TrainingSets_Create 示例所示。
- 将
YourResourceKey替换为语音资源密钥。 - 将
YourResourceRegion替换为语音资源区域。 - 将
JessicaTrainingSetId替换为所选的训练集 ID。 训练集的 URI 中将使用区分大小写的 ID,并且以后无法更改。
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2024-02-01-preview"
你应该会收到以下格式的响应正文:
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
上传训练集数据
要上传音频和脚本训练集,请使用自定义语音 API 的 TrainingSets_UploadData 操作。
在调用此 API 之前,请将录制文件和脚本文件存储在 Azure Blob 中。 在下面的示例中,录制文件为 https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.wav 文件,脚本文件为 https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.txt 文件。
根据以下说明构造请求正文:
- 将所需的
kind属性设置为AudioAndScript。 类型确定了训练集的类型。 - 设置所需的
audios属性。 在audios属性中,设置以下属性:- 将所需的
containerUrl属性设置为包含音频文件的 Azure Blob 存储容器的 URL。 对具有读取权限和列表权限的容器使用共享访问签名 (SAS)。 - 将所需
extensions属性设置为音频文件的扩展名。 - (可选)设置属性
prefix以设置 Blob 名称的前缀。
- 将所需的
- 设置所需的
scripts属性。 在scripts属性中,设置以下属性:- 将所需
containerUrl属性设置为包含脚本文件的 Azure Blob 存储容器的 URL。 对具有读取权限和列表权限的容器使用共享访问签名 (SAS)。 - 将所需
extensions属性设置为脚本文件的扩展名。 - (可选)设置属性
prefix以设置 Blob 名称的前缀。
- 将所需
使用 URI 发出 HTTP PUT 请求,如以下 TrainingSets_Create 示例所示。
- 将
YourResourceKey替换为语音资源密钥。 - 将
YourResourceRegion替换为语音资源区域。 - 如果在上一步中指定了其他训练集 ID,请替换
JessicaTrainingSetId。
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2024-02-01-preview"
响应头包含 Operation-Location 属性。 使用此 URI 获取有关 TrainingSets_UploadData 操作的详细信息。 以下是响应头示例:
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2024-02-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345