你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
录制用于神经网络定制声音的声音示例
本文提供有关准备高质量语音示例的说明,以便使用自定义神经网络语音 Pro 项目创建专业语音模型。
从头开始创建高质量的生产级神经网络定制声音并非一件轻松的事情。 神经网络定制声音的核心部分是人类语音的大量音频样本。 这些录音是否精良至关重要。 挑选精通这类录制的发音人,让录音工程师使用专业设备进行录制。
不过,在制作这些录音之前需要脚本:由发音人说出的单词,以创建音频示例。
要创建专业的语音录制,需要很多细微而重要的细节。 本指南是一个流程线路图,可帮助你获得良好、一致的结果。
有关准备数据以获得高质量语音的提示
高度自然的自定义神经网络语音取决于多个因素,例如训练数据的质量和大小。
训练数据的质量是主要因素。 例如,在同一训练集中,一致的音量、语速、说话音调和说话风格对于创建高质量的神经网络定制声音至关重要。 在录制中还应避免背景噪音,并确保脚本和录制内容匹配。 若要确保数据的质量,需要遵循脚本选择标准和录制要求。
关于训练数据的大小,在大多数情况下,可以使用 500 条语句构建合理的神经网络定制声音。 我们的测试表明,在大多数语言中添加更多训练数据并不一定能提高语音本身的自然性(使用 MOS 分数测试的),但包含更多单词实例的训练数据越多,就越有可能减少语音的不满意部分(如噪音)的比率。 若要听听语音中令人不满意的部分,请参阅 GitHub 示例。
在某些情况下,可能需要具有独特特征的语音角色。 例如,卡通角色需要具有特殊说话风格的语音,或语调动态的语音。 对于这种情况,建议至少准备 1000 条(最好是 2000 条)语句,并在专业录音室录制。 要详细了解如何提高声音模型的质量,请参阅使用神经网络定制声音的特征和限制。
语音录制角色
神经网络定制声音录制项目有 4 个基本角色:
| 角色 | 目的 |
|---|---|
| 发音人 | 其语音将构成自定义神经网络语音的基础。 |
| 录音工程师 | 监督录音的技术方面并操作录音设备。 |
| 导演 | 撰写脚本并指导发音人的表演。 |
| 编辑器 | 完成音频文件并润色上传到 Speech Studio |
一个人可以担任多个角色。 本指南假设由你担任导演角色并聘请发音人和录音工程师。 如果想自己制作录音,请参阅本文中有关录音工程师角色的信息。 在录制会话之后才需要编辑师角色。 同时,导演或录音工程师可以担任这一职务。
选择发音人
具有旁白、配音工作、播音或新闻阅读经验的演员可成为优秀的发音人。 挑选你喜欢其原声的发音人。 可创建独特的“角色”语音,但对大多数配音员而言,要保证角色声音一致非常困难,力求一致会导致声音绷紧。 挑选发音人时只有一个最重要的因素,就是一致性。 相同语音风格的录音应该听起来像都是同一天、同一个房间录制的。 要实现这一理想,可通过良好的录音练习和工程操作。
发音人必须能以一致的语速、音量、音高和音调说话,并具有良好的听写能力。 发音人还需要能够控制其音高变化、情感影响和语音习惯。 录制语音示例可能比其他类型的语音工作更累,因此大多数发音人通常一天只能录制两三个小时。 将过程限制为每周三到四天,如果可能的话,中间休息一天。
与配音员合作,制作一个角色来定义自定义神经语音的整体声音和情感基调。 定义角色的说话风格,并要求配音员朗读脚本的方式与你想要的风格相符。 确保在一组训练数据的录音中,说话风格保持一致。
例如,如果一个角色具有天生乐观的个性,则他们的语音将带有乐观的情绪。 不过,这种个性应该在一组训练数据的所有记录中得到一致的表达。 倾听现有的声音,了解你的目标。
提示
通常,你录制的语音要归你所有。 发音人应该按照项目的承揽合同行事。
创建脚本
所有神经网络定制声音录制阶段的起点都是脚本,其中包含发音人要朗读的语句。 术语“语句”包括完整的句子和较短的短语。 生成神经网络定制声音至少需要使用 300 个录制语句作为训练数据。
脚本中的语句可以来自任何地方:小说、纪实、演讲稿件、新闻报道以及其他任何印刷形式中的内容。 有关的潜在法律问题的简要说明,请参阅法律部分。 也可自行编写文本。
语句的来源不一定要相同或属于同一类型,彼此也不一定要有任何联系。 但是,如果在语音应用程序中使用固定短语(例如“你已成功登录”),请确保将其包含在脚本中。 这样,自定义神经网络语音可更好地读出这些短语。
建议在录制脚本中包含常规句子和特定于域的句子。 例如,如果你打算录制 2,000 个句子,其中 1,000 个句子可以是常规句子,另 1,000 个句子可能是来自应用程序的目标域或用例的句子。
我们在每种语言的“常规”、“聊天”和“客户服务”域中提供了示例脚本,以帮助你准备录制脚本。 可以直接将这些 Microsoft 共享脚本用于录制,也可以将其用作参考来创建自己的录制内容。
脚本选择条件
可以遵循以下通用准则创建适当的语料库(录制的音频样本)用于进行神经网络定制声音训练。
平衡脚本以涵盖域中的不同句子类型,包括陈述、疑问、感叹、长句和短句。
每个句子应包含四到 30 个单词,并且脚本中不应包含重复的句子。
有关如何平衡不同句子类型的说明,请参阅下表:句子类型 覆盖范围 声明语句 陈述句应占脚本的 70-80%。 疑问句 疑问句大约应占域脚本的 10%-20%,其中包括 5%-10% 的升调和 5%-10% 的降调。 感叹句 感叹句大约应占脚本的 10%-20%。 短字/短语 短字/短语脚本应占语句总数的 10% 部分,每个例子包含 5 到 7 个单词。 注意
短字/短语应以逗号分隔。 它们有助于提醒你发音人在阅读时稍作停顿。
最佳做法包括:
- 均匀覆盖词性,例如动词、名词、形容词等。
- 均匀覆盖发音。 包含从 A 到 Z 的所有字母,使文本转语音引擎能够学习如何以你的风格进行每个字母的发音。
- 易于阅读、易于理解且符合日常地脚本,使讲话人能够读出。
- 避免过多类似的单词/短语模式,例如“easy”和“easier”。
- 在所有句子类型中包含不同的数字格式:地址、单位、电话号码、数量、日期等。
- 包括拼写句子,如果这是自定义神经网络语音会读到的内容。 例如,“Apple 拼写为 A P P L E”。
不要将多个句子放入一行/一段语句中。 按语句分隔每行。
确保句子简洁。 一般而言,请不要包含过多的非标准字词,例如数字或缩写,因为它们难以阅读。 某些应用程序可能需要阅读许多数字或首字母缩略词。 在这些情况下,可以包含这些字词,但要将其规范化为口语形式。
下面是一些最佳做法示例:
- 对于包含缩写“BTW”的行,不要输入该缩写,而是输入“by the way”。
- 对于包含数字“911”的行,不要输入该数字,而是输入“nine one one”。
- 对于包含首字母缩略词“ABC”的行,不要输入该缩略词,而是输入“A B C”。
这样可以确保发音人按预期方式发音。 在训练过程中,使脚本和录制内容持续保持匹配。
脚本要包含许多不同的字词和句子,句子长度、结构和情绪也要各式各样。
仔细检查脚本是否有错误。 如果可能,请其他人检查一下。 与发音人一起浏览脚本时,你可能会发现更多的错误。
发音人脚本与训练脚本之间的差异
训练脚本可能与发音人脚本不同,尤其是对于包含数字、符号、缩写、日期和时间的脚本而言。 为发音人准备的脚本必须遵循本机阅读约定,例如输入 50% 和 $45。 用于训练的脚本需要规范化,以与音频录制内容匹配,例如输入 fifty percent 和 forty-five dollars。
注意
我们在 GitHub 上为发音人提供了一些示例脚本。 若要使用示例脚本进行培训,必须在上传文件之前根据发音人的录制内容对脚本进行规范化。
下表显示了用于发音人的脚本与用于训练的规范化脚本之间的差异。
| 类别 | 发音人脚本示例 | 训练脚本示例(规范化) |
|---|---|---|
| 数字 | 123 | one hundred and twenty-three |
| 符号 | 50% | fifty percent |
| 缩写 | ASAP | as soon as possible |
| 日期和时间 | March 3rd at 5:00 PM | March third at five PM |
脚本的典型缺陷
脚本质量不佳可能会对训练结果造成负面影响。 若要获得高质量的训练结果,必须避免缺陷。
脚本缺陷通常分为以下几种类别:
| 类别 | 示例 |
|---|---|
| 毫无意义的内容。 | “Colorless green ideas sleep furiously.” |
| 不完整的句子。 | - "This was my last eve"(没有主语,没有具体的含义) -“他们已经很有趣了(末尾没有引号,不是完整的句子) |
| 句子中存在键入错误。 | - 以小写开头 - 未包含所需的结尾标点 - 拼写错误 - 缺少标点:末尾没有句号(新闻标题除外) - 以除逗号、问号、感叹号以外的符号结尾 - 错误的格式,例如: - 45$(应是 $45) - 字词/标点之间没有空格或者有多余的空格 |
| 重复类似的格式,为每种模式提供一种格式就已足够。 | - "Now is 1pm in New York" - "Now is 2pm in New York" - "Now is 3pm in New York" - "Now is 1pm in Seattle" - "Now is 1pm in Washington D.C." |
| 不常见的外来字词:脚本仅接受常见外来字词。 | 在英语中,人们可能会在日常讲话中使用法语单词“faux”,但像“coincer la bulle”这样的语法表达并不常见。 |
| 表情符号或其他任何不常见符号 |
脚本格式
脚本在录制阶段中使用,因此可以任何易于使用的方式进行编制。 单独创建 Speech Studio 所需的文本文件。
基本脚本格式包含三列:
- 语句的编号,从 1 开始。 编号可让工作室中的每个人都能轻松找到特定语句(“让我们再试一次编号 356”)。 可使用 Microsoft Word 的段落编号功能自动为表行编号。
- 可在空白列中写下每个语句的录制号或时间码,以便在完成的录音中找到它。
- 语句自身的文本。
注意
大多数工作室都要录制简短的片段,称为“试录”。 每次试录通常包含 10 到 24 条语句。 记下试录号就足以让你在之后找到某条语句。 如果录制的工作室喜欢制作更长时间的录音,则需要记下时间码。 工作室将有一个醒目的时间显示。
在每行后留出足够的空间来写注释。 确保页面之间没有分隔的语句。 对页面进行编号并在纸张的一面打印脚本。
将脚本一式三份打印:一份给发音人、一份给录音工程师、一份给导演(你)。 使用回形针而非订书钉:经验丰富的配音员不会将页面重叠在一起,避免在翻页时产生噪音。
发音人声明
若要训练神经网络声音,必须使用发音人录制的音频文件创建发音人资料(前提是发音人同意授权使用其语音数据来训练定制声音模型)。 准备录制脚本时,请确保包含声明语句。
合法性
根据版权法,参与者朗读受版权保护的文本也可能算作表演,作品的作者应该为此得到补偿。 在最终产品(即神经网络定制声音)中无法识别此表演。 即便如此,为此目的而使用受版权保护作品的合法性尚未确定。 Microsoft 无法就此问题提供法律建议;请咨询你自己的法律顾问。
幸运的是,可完全避免这些问题。 有很多文本源无需许可或权限即可使用。
| 文本源 | 说明 |
|---|---|
| CMU Arctic corpus | 约 1100 个句子,选自专用于语音合成项目的无版权作品。 首先使用这类句子是很可取的。 |
| 作品不再 受版权保护 |
通常是 1923 年之前出版的作品。 在英语方面,Project Gutenberg(古腾堡计划)提供了数以万计的此类作品。 你可能想要关注较新的作品,因为语言会更接近现代英语。 |
| 政府作品 | 美国政府创作的作品在美国不受版权保护,但政府可以在其他国家/地区声明版权所有。 |
| 公共域 | 明确否认版权或专用于公共领域的作品。 在某些司法管辖区可能无法完全放弃版权。 |
| 许可作品 | 根据 Creative Commons 或 GNU 自由文档许可证 (GFDL) 等许可分发的作品。 维基百科使用 GFDL。 但是,某些许可证可能会对影响自定义神经网络语音模型创建的许可内容的表演施加约束,因此请仔细阅读许可证。 |
录制脚本
在专门从事语音工作的专业录音室内录制脚本。 他们有录音棚,以及进行操作的合适设备和合适人员。 不建议节省录音费用。
与工作室的录音工程师讨论项目并听取其建议。 录音只应有很少或没有动态范围压缩(最大为 4:1)。 音频具有一致的音量和高信噪比,同时没有不必要的声音,这一点至关重要。
录音要求
为了获得高质量的训练结果,请在录音或准备数据期间遵循以下要求:
发音清晰且准确
自然语速:不同音频文件的语速不会过慢或过快。
适当的音量、韵律和断句:在同一句子中或不同句子之间保持稳定,标点断句正确。
录音期间无噪音
适合角色设计
没有错误的重音:适合目标设计
没有错误的发音
作为最佳做法,请参考以下规范来准备音频样本。
| 属性 | 值 |
|---|---|
| 文件格式 | *.wav,单声道 |
| 采样率 | 24 KHz |
| 示例格式 | 16 位,PCM |
| 峰值音量级别 | -3 dB 到 -6 dB |
| 信噪比 | > 35 dB |
| 静音 | - 开头和结尾应包含一段时间的静音(建议 100 毫秒,但不超过 200 毫秒) - 字词或短语之间的静音 < -30 dB - 讲出的最后一个字词后面的波形中的静音 < -60 dB |
| 环境噪声或回声 | - 讲话之前的波形中开头部分的噪音级 < -70 dB |
注意
可以采用更高的采样率和位深度进行录音,例如,使用 48 KHz 24 位 PCM 格式。 在神经网络定制声音训练期间,我们会自动将采样率降低至 24 KHz 16 位 PCM。
信噪比 (SNR) 高表明音频中的噪音少。 通过专业录音棚录音通常可以达到 35+ 的 SNR。 音频的 SNR 低于 20 可能导致生成的语音中出现明显的噪音。
考虑重新录制发音分数低或信噪比不佳的语句。 如果无法重新录制,请考虑从数据中排除这些语句。
典型音频错误
要获得高质量的训练结果,我们强烈建议避免音频错误。 音频错误通常属于以下类别:
音频文件名与脚本 ID 不匹配。
WAR 文件格式无效,无法读取。
音频采样率低于 16 KHz。 为获得高质量的神经网络声音,建议使 .wav 文件采样率等于或高于 24 KHz。
音量峰值不在 -3 dB(最大音量的 70%)到 -6 dB (50%) 的范围内。
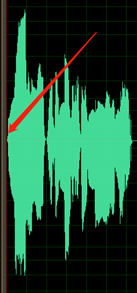
波形在峰值处被切断,因此不完整。
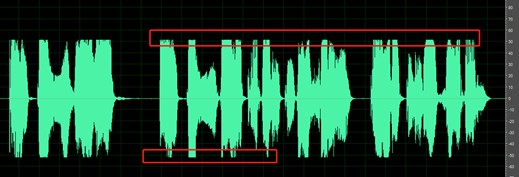
录制的静音部分不完全静音;可以听到环境噪音、嘴发出的噪音和回音等声音。
例如,以下音频在语音之间包含环境噪音。
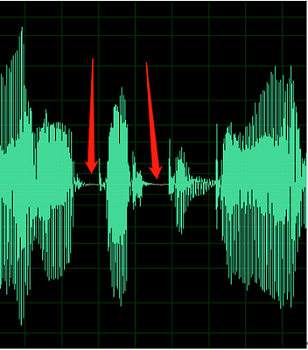
以下示例包含 DC 偏移噪音或回音的信号。
总音量太低。 如果音量低于 -18 dB(最大音量的 10%),则数据会标记为有问题。 确保所有音频文件持续保持相同的音量级别。
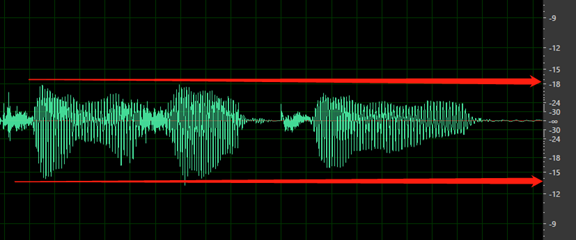
第一个字词之前或最后一个字词之后无静音。 此外,开头或结尾的静音不应长于 200 毫秒或短于 100 毫秒。
自制
如果想自己录制,而不去录音棚录制,这里有一个简短的入门。 由于家庭录音和播客的兴起,在网上找到好的录音建议和资源比以往任何时候都更容易。
“录音棚”应该是一个没有明显回音或“空间声”的小房间。应尽可能安静和隔音。 墙上的窗帘可用于减少回声、中和或“消除”房间的声音。
使用专用于录制语音的高品质的录音室电容麦克风(简称“麦克风”)。 Sennheiser、AKG,甚至较新的 Zoom 麦克风可以产生很棒的效果。 可购买麦克风,也可从当地的视听设备租赁公司租用一个。 寻找带 USB 接口的麦克风。 这种类型的麦克风可方便地将麦克风元件、前置放大器和模数转换器组合到一个封装中,简化了连接。
也可以使用模拟麦克风。 许多出租店提供以语音特征而闻名的“复古”麦克风。 专业模拟装置使用均衡的 XLR 连接器,而不是消费类设备中使用的 1/4 英寸插头。 如果要模拟,还需要一个前置放大器和一个带这些连接器的计算机音频接口。
将麦克风安装在支架或吊杆上,并在麦克风前安装一个噗声滤除器,以消除“爆破”音(如“p”和“b”)所产生的噪音。有些麦克风配有悬挂机架,它能消除支架产生的振动,这很有帮助。
发音人必须与麦克风保持一致的距离。 在地板上用胶带标记其应该站立的位置。 如果发音人更喜欢坐着,请特别注意监控麦克风距离并避免椅子产生噪音。
使用支架来放置脚本。 避免支架倾斜,它会造成声音传播到麦克风上。
操作录音设备的人员(即录音工程师)不能和发音人在同一个房间,而且要使用某种方式(对讲电路)与录音棚中的发音人交谈。
录音应包含尽可能少的噪音,目标是 -80 dB。
仔细听“录音棚”中没人发声时的录音,找出噪音来自哪里,并消除原因。 常见的噪声源是通风口、日光灯镇流器、附近道路上的交通以及设备风扇(甚至笔记本电脑也可能有风扇)。 麦克风和电缆可以从附近的交流电线接收电噪声,通常是呼呼声或嗡嗡声。 接地回路也可能导致嗡嗡声,这是因为设备插入了多个电路。
提示
在某些情况下,可能能够使用均衡器或降噪软件插件来帮助消除录音中的噪音,但最好在源头阻止噪音。
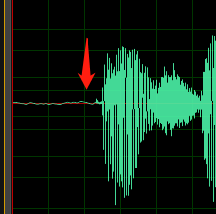
设置级别,以便在不过载的情况下使用大多数可用的数字录音动态范围。 这意味着声音大,但不至于大到音频失真。 下图显示了精良录音波形的示例:
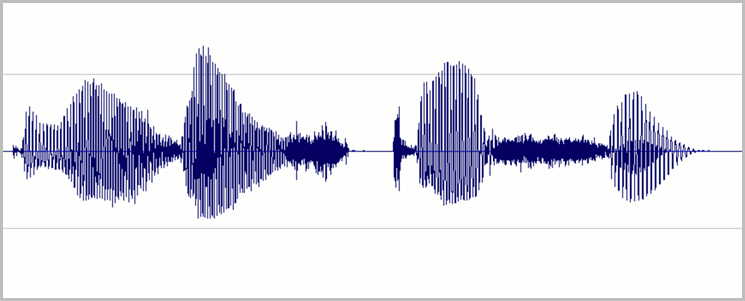
这里使用了大部分范围(高度),但信号的最高峰未到达窗口的顶部或底部。 还可看到录制中的无声状态近似于细的水平线,它表示低噪声基底。 该录音具有可接受的动态范围和信噪比。
根据使用的麦克风,使用高品质的音频接口或 USB 端口直接录制到计算机中。 对于模拟,要保持音频链简单:麦克风、前置放大器、音频接口和计算机。 每月支付合理的价格即可获得 Avid Pro Tools 和 Adobe Audition 许可证。 如果预算非常紧张,请试用免费的 Audacity。
以 44.1 KHz 16 位单声道(CD 质量)或更高标准进行录制。 如果设备支持,目前最先进的是 48 KHz 24 位。 在将音频提交到 Speech Studio 之前,请将音频的采样率降至 24 KHz 16 位。 尽管如此,如果需要编辑,拥有高质量的原始录音还是值得的。
理想情况下,让不同的人担任导演、工程师和发音人的角色。 不要自己独揽所有角色。 在紧要关头,导演可兼任工程师。
录音前
为避免浪费工作室时间,请在录音阶段前与发音人一起查看脚本。 当发音人熟悉文本时,他们能够理清任何不熟悉的字词的发音。
注意
大多数录音室在录音棚中提供脚本的电子显示屏。 在这种情况下,直接在脚本文档中键入你的浏览注释。 但是,仍然需要在录制期间使用纸质打印件进行记录。 大多数工程师也需要打印件。 你仍然需要再打印一份,在计算机出现故障的情况下供发音人备用。
发音人可能会询问你要强调一个语句中的哪个词(“关键词”)。 告诉他们你想要一个没有特别强调的自然朗读。 合成语音时可以增加强调部分;但原始录音时不需要。
指导发音人清楚地发音。 脚本的每个字词都要按书面形式发音。 不能像随意交谈中常见的那样省略某些音或将几个音混在一起,除非是在脚本中以这种方式编写。
| 书面文本 | 不必要的随意发音 |
|---|---|
| never going to give you up | never gonna give you up |
| there are four lights | there're four lights |
| how's the weather today | how's th' weather today |
| say hello to my little friend | say hello to my lil' friend |
发音人不应在字词之间有明显的暂停。 句子仍然要自然流畅,即使听起来有点正式。 这种精细的区分可能需要练习才能做到正确。
录制阶段
在录制开始时,创建典型语句的参考录音或匹配文件。 要求发音人差不多每一页都重复这一行。 每次都将新录音与参考录音进行比较。 这种练习有助于发音人在音量、节奏、音调和语调方面保持一致。 同时,工程师可以使用匹配文件作为声音级别和整体一致性的参考。
在休息后或另一天继续录制时,匹配文件尤为重要。 为发音人多播放几次,每次都要他们复述一遍,直到匹配良好。
若要记录具有特定风格的语料库,请仔细选择展示所需风格的脚本。 在录音过程中,确保发音人在音量、节奏、音高和语气上保持一致,以实现体现预期风格的录音。
指导发音人深呼吸,并在每条语句之前暂停片刻。 在语句之间录制几秒钟的无声状态。 字词每次出现时都要以相同的方式发音并考虑上下文。 例如,作为动词的“record”与作为名词的“record”的发音不同。
在第一次录音之前录制大约五秒钟的无声状态以捕捉“空间声”。 这种做法有助于 Speech Studio 补偿录音中的噪音。
提示
你只需要捕捉发音人的声音,因此可以只进行其台词的单声道录制。 但是,如果以立体声录制,可使用第二个声道在控制室中录制闲谈,以捕获特定台词或试录的讨论。 从上传到 Speech Studio 的版本中删除此音轨。
使用耳机仔细听发音人的表现。 需要的是优美且自然的用词、正确的发音,还不能有不必要的声音。 要立即要求发音人重新录制不符合这些标准的语句。
提示
如果使用大量的语句,单个语句可能不会对生成的神经网络定制声音产生明显的影响。 更好的方式是简单记下所有有问题的语句,将它们从数据集中排除,再看看神经网络定制声音的结果如何。稍后可随时返回工作室并录制漏掉的示例。
对于每条语句,都要在脚本上记下试录号或时间码。 还要要求工程师在录音的元数据或提示表中标记每条语句。
定期休息并提供饮料,帮助发音人保持声音的良好状态。
录制后
现代录音棚在计算机上进行后期。 录制结束时,将收到一个或多个音频文件,而不是磁带。 这些文件可能是 CD 质量(44.1 KHz 16 位)的 WAV 或 AIFF 格式或更高格式。 24 KHz 16 位很常见,也是理想选择。 神经网络定制声音的默认采样率为 24 KHz。 建议对训练数据使用 24 KHz 及更高的采样率。 通常不需要更高的采样率,例如 96 KHz。
Speech Studio 要求所提供的每条语句都在各自的文件中。 工作室提供的每个音频文件都包含多条语句。 因此,主要的后期制作任务是拆分录音并准备提交。 录音工程师可能已在文件中放置标记(或提供单独的提示表),用于指示每条语句的开始位置。
使用注释找到想要的确切试录,然后使用声音编辑实用工具(如 Avid Pro Tools、Adobe Audition 或免费的 Audacity)将每条语句复制到新的文件中。
仔细听每个文件。 在此阶段,可剔除录音过程中漏掉的不必要的微小声音,比如在一句台词前的轻微咂嘴声,但请注意不要删除任何实际的语音。 如果无法修复文件,请将其从数据集中删除,并记录你已将其删除。
保存前要将每个文件转换成 16 位和 24 KHz 及更高的采样率,如果录制了工作室闲谈,则移除第二个声道。 以 WAV 格式保存每个文件,使用脚本中的语句编号命名文件。
最后,创建记录,它将每个 WAV 文件与相应语句的文本版本进行关联。 训练声音模型包括所需格式的详细信息。 可直接从脚本中复制文本。 然后创建 WAV 文件和 文本记录的 Zip 文件。
将原始录音存档在安全的地方,以备日后需要时使用。 同时也要保留脚本和注释。
后续步骤
已准备好上传录音和创建神经网络定制声音。