你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
如何创建自定义 NER 项目
本文介绍如何进行设置以满足开始使用自定义 NER 的要求,以及如何创建项目。
先决条件
开始使用自定义 NER 之前,你需要:
创建“语言”资源
开始使用自定义 NER 之前,需要具备 Azure AI 语言资源。 建议在 Azure 门户中创建语言资源,并将存储帐户连接到该资源。 通过在 Azure 门户中创建资源,可同时创建 Azure 存储帐户,其中预配了所有必需的权限。 你还可进一步阅读本文,了解如何使用预先存在的资源,并对其进行配置以使用自定义命名实体识别。
另外,还需要 Azure 存储帐户,你将在其中上传 .txt 文档,这些文档将用于训练模型以提取实体。
注意
- 你需要分配有资源组的“所有者”角色才能创建语言资源。
- 如果要连接预先存在的存储帐户,则应为其分配“所有者”角色。
创建语言资源并连接存储帐户
可以通过下列方式创建资源:
- Azure 门户
- Language Studio
- PowerShell
注意
在存储帐户与语言资源链接后,不应将它移动到其他资源组或订阅。
从 Azure 门户创建新资源
若要创建新的 Azure AI 语言资源,请登录 Azure 门户。
在出现的窗口中,从自定义功能中选择“自定义文本分类和自定义命名实体识别”。 单击屏幕底部的“继续创建资源”。

创建包含以下详细信息的语言资源。
| 名称 |
说明 |
| 订阅 |
Azure 订阅。 |
| 资源组 |
将包含资源的资源组。 可以使用现有资源组,也可以新建一个。 |
| 区域 |
语言资源的区域。 例如,“美国西部 2”。 |
| 名称 |
资源的名称。 |
| 定价层 |
语言资源的定价层。 可以使用免费 (F0) 定价层试用该服务。 |
注意
如果收到一条消息“登录帐户不是所选存储帐户资源组的所有者”,则帐户需要在资源组上分配一个所有者角色,然后才能创建语言资源。 请联系 Azure 订阅所有者寻求帮助。
在“自定义文本分类和自定义命名实体识别”部分,选择现有存储帐户或选择“新建存储帐户”。 这些值用于帮助你快速入门,不一定是你希望在生产环境中使用的存储帐户值。 为避免在生成项目时出现延迟,请连接到与语言资源位于同一区域的存储帐户。
| 存储帐户值 |
建议的值 |
| 存储帐户名称 |
任何名称 |
| 存储帐户类型 |
标准 LRS |
确保选中“负责任的 AI 通知”。 在页面底部选择“查看 + 创建”,然后选择“创建”。
通过 Language Studio 创建新语言资源
如果是首次登录,你将在 Language Studio 中看到一个窗口,在该窗口中可以选择现有语言资源或创建新的语言资源。 也可单击右上角的“设置”图标,选择“资源”,然后单击“创建新资源”,从而创建资源 。
创建包含以下详细信息的语言资源。
| 实例详细信息 |
所需的值 |
| Azure 订阅 |
你的 Azure 订阅 |
| Azure 资源组 |
你的 Azure 资源组 |
| Azure 资源名称 |
你的 Azure 资源名称 |
| 位置 |
语言资源的区域。 |
| 定价层 |
语言资源的定价层。 |
重要
- 请确保在创建语言资源时启用“托管标识”。
- 阅读并确认“负责任的 AI”声明
若要使用自定义命名实体识别,需创建 Azure 存储帐户(如果还没有该帐户)。
使用 PowerShell 创建新的语言资源
可使用以下 CLI 模板和参数文件(托管在 GitHub 上)创建新资源和存储帐户。
在参数文件中编辑以下值:
| 参数名称 |
值说明 |
name |
语言资源的名称 |
location |
托管资源的区域。 有关详细信息,请参阅服务限制。 |
sku |
资源的定价层。 |
storageResourceName |
存储帐户的名称 |
storageLocation |
托管存储帐户的区域。 |
storageSkuType |
存储帐户的 SKU。 |
storageResourceGroupName |
存储帐户的资源组 |
使用以下 PowerShell 命令,部署 Azure 资源管理器 (ARM) 模板和编辑的文件。
New-AzResourceGroupDeployment -Name ExampleDeployment -ResourceGroupName ExampleResourceGroup `
-TemplateFile <path-to-arm-template> `
-TemplateParameterFile <path-to-parameters-file>
要了解如何部署模板和参数文件,请参阅 ARM 模板文档。
注意
- 将存储帐户连接到语言资源的过程是不可逆的,以后无法断开其连接。
- 只能将你的语言资源连接到一个存储帐户。
使用预先存在的语言资源
可使用现有的语言资源来开始使用自定义 NER,只要该资源满足以下要求即可:
| 要求 |
说明 |
| 区域 |
请确保现有资源是在某一个受支持的区域预配的。 如果不是,则需要在某一个受支持的区域创建新资源。 |
| 定价层 |
了解有关支持的定价层的详细信息。 |
| 托管标识 |
请确保已启用资源的托管标识设置。 否则,请阅读下一部分。 |
若要使用自定义命名实体识别,需创建 Azure 存储帐户(如果还没有该帐户)。
为资源启用标识管理
语言资源必须具有标识管理,若要使用 Azure 门户启用它,请执行以下操作:
- 转到你的语言资源
- 在左侧菜单中的“资源管理”部分下,选择“标识”
- 在“系统分配”选项卡中,确保将“状态”设置为“启用”
语言资源必须具有标识管理,若要使用 Language Studio 启用它,请执行以下操作:
- 选择屏幕右上角的“设置”图标
- 选择“资源”
- 选中你的 Azure AI 语言资源对应的“托管标识”复选框。
启用自定义命名实体识别功能
请确保从 Azure 门户启用“自定义文本分类/自定义命名实体识别”功能。
- 转到 Azure 门户中的语言资源。
- 在左侧菜单中的“资源管理”部分下,选择“功能”。
- 启用“自定义文本分类/自定义命名实体识别”功能。
- 连接你的存储帐户。
- 选择应用。
重要
- 确保你的语言资源在要连接的存储帐户上分配有“存储 Blob 数据参与者”角色。
添加所需的角色
使用以下步骤为语言资源和存储帐户设置所需的角色。
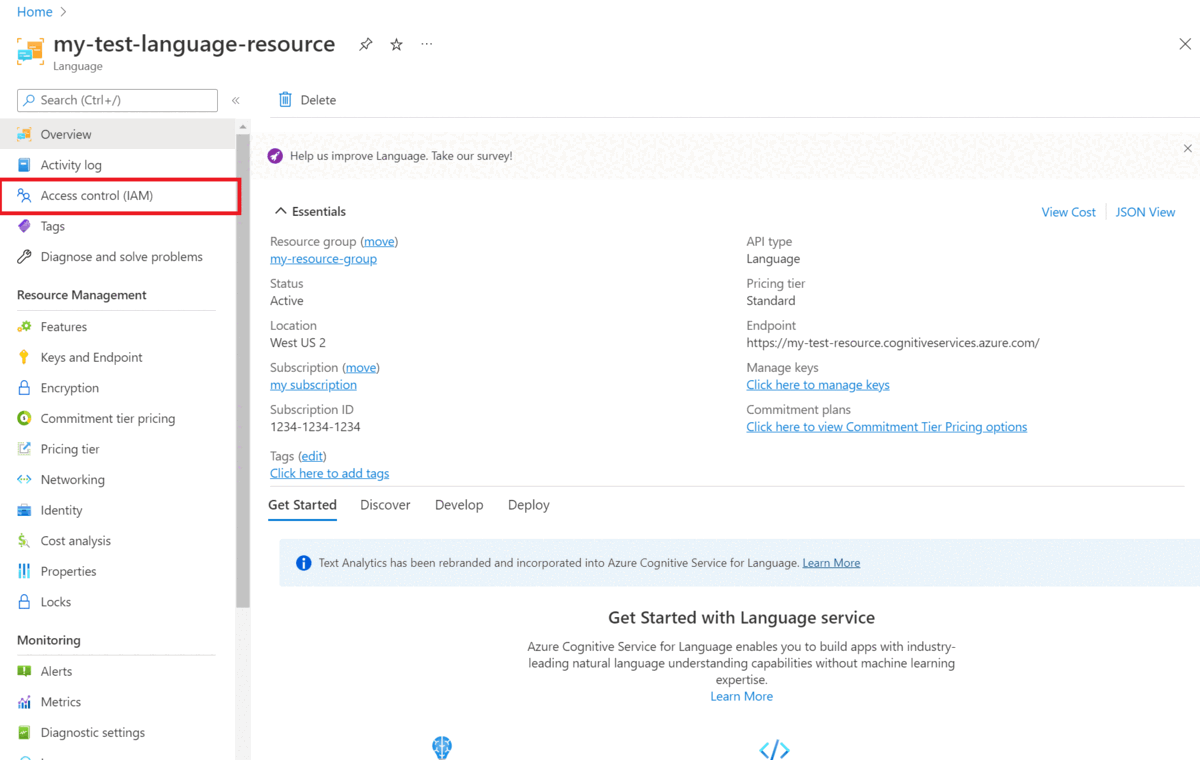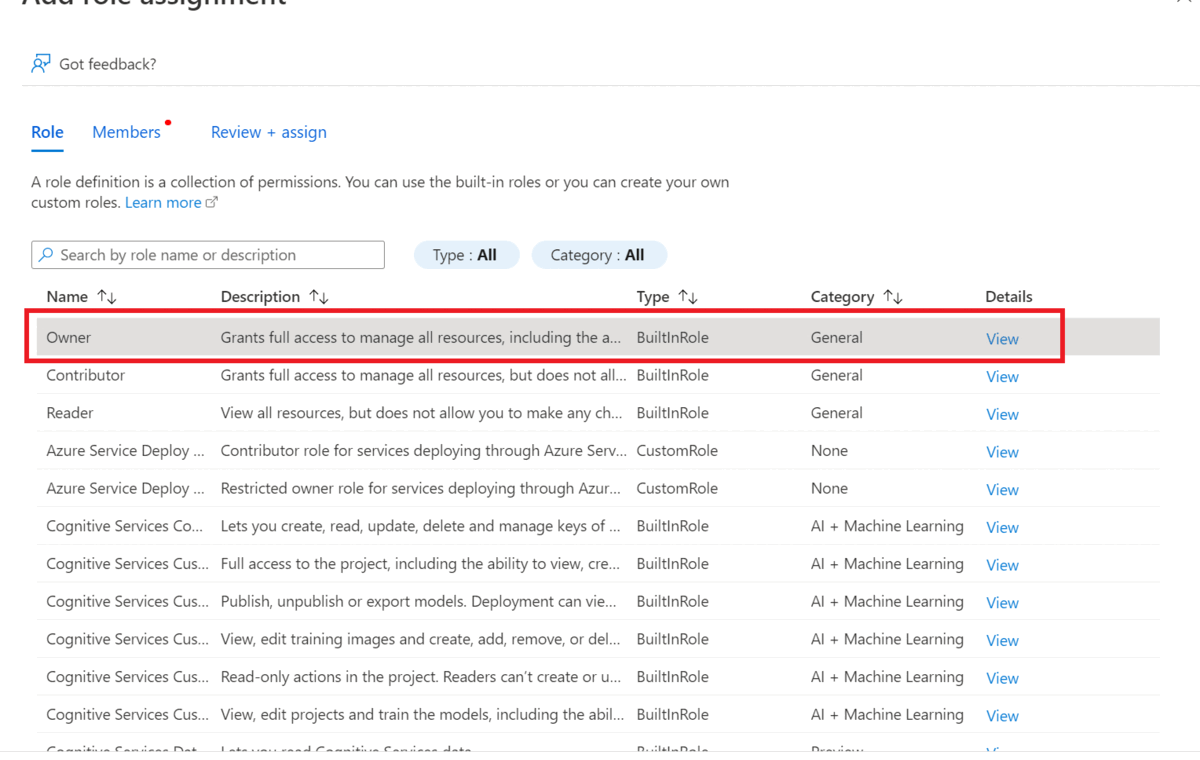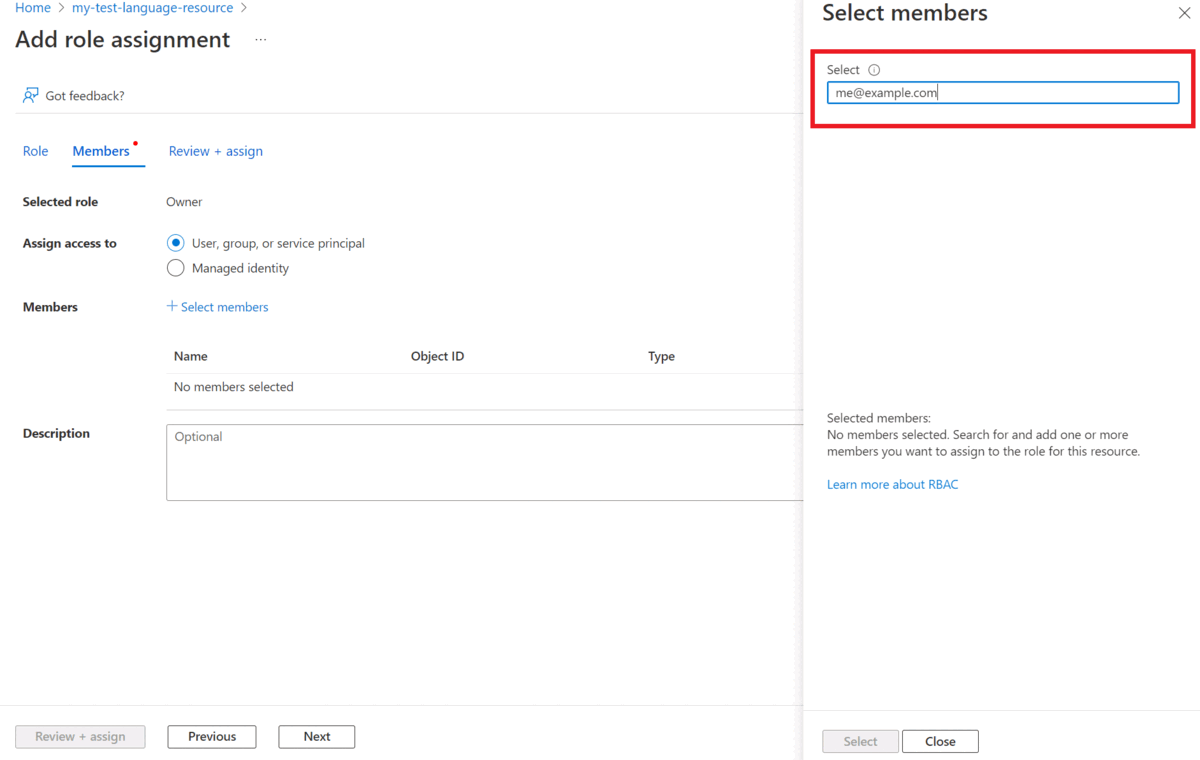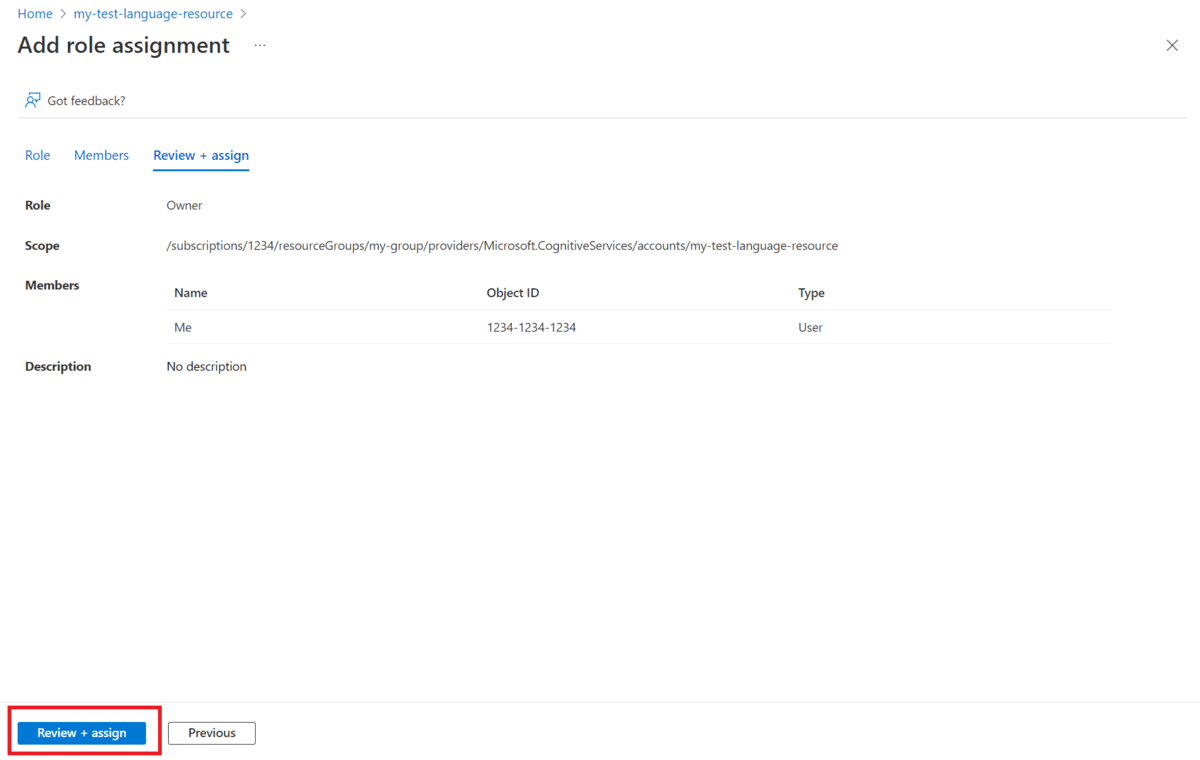
Azure AI 语言资源的角色
在 Azure 门户中转到你的存储帐户或语言资源。
在左侧导航菜单中,选择“访问控制(IAM)”。
选择“添加”以添加角色分配,然后为帐户选择适当的角色。
你应在你的语言资源上分配有“所有者”或“参与者”角色。
在“将访问权限分配给”中,选择“用户、组或服务主体”
选择“选择成员”
选择用户名。 可在“选择”字段中搜索用户名。 对所有角色重复此操作。
对需要访问此资源的所有用户帐户重复这些步骤。
存储帐户的角色
- 在 Azure 门户中转到自己的存储帐户页面。
- 在左侧导航菜单中,选择“访问控制(IAM)”。
- 选择“添加”以添加角色分配,然后选择存储帐户上的“存储 Blob 数据参与者”角色。
- 在“将访问权限分配给”中,选择“托管标识”。
- 选择“选择成员”
- 选择你的订阅,然后选择“Language”作为托管标识。 可在“选择”字段中搜索用户名。
用户的角色
重要
如果跳过此步骤,则在尝试连接到自定义项目时会出现 403 错误。 重要的是,即使你是存储帐户的所有者,当前用户也必须具有此角色才能访问存储帐户 blob 数据。
- 在 Azure 门户中转到自己的存储帐户页面。
- 在左侧导航菜单中,选择“访问控制(IAM)”。
- 选择“添加”以添加角色分配,然后选择存储帐户上的“存储 Blob 数据参与者”角色。
- 在“将访问权限分配给”中,选择“用户、组或服务主体”。
- 选择“选择成员”
- 选择你的用户。 可在“选择”字段中搜索用户名。
重要
如果有虚拟网络或专用终结点,请务必在 Azure 门户中选择“允许受信任服务列表中的 Azure 服务访问此存储帐户”。
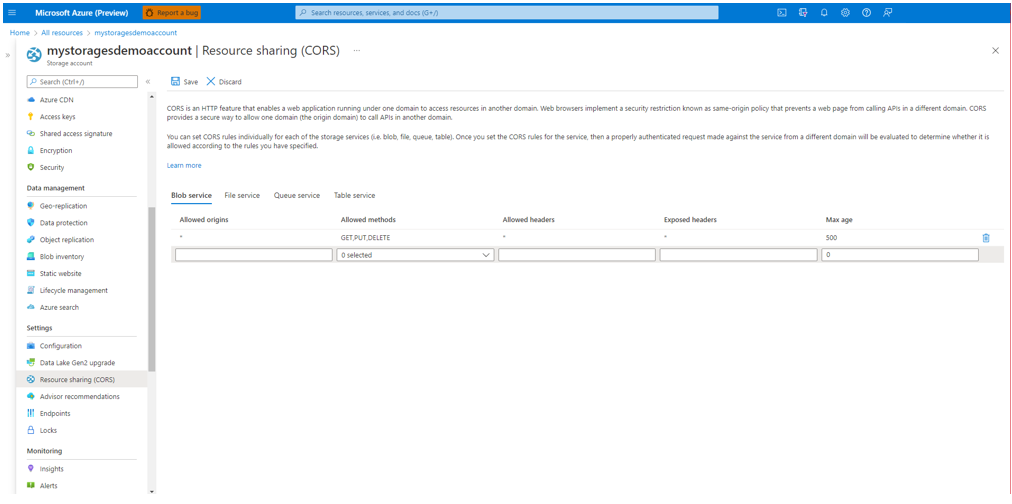
为你的存储帐户启用 CORS
当启用跨源资源共享 (CORS) 时,请确保允许(GET、PUT、DELETE)方法。
将“允许的来源”字段设置为 https://language.cognitive.azure.com。 通过将 * 添加到允许的标头值来允许所有标头,并将最长期限设置为 500。
创建自定义命名实体识别项目
配置资源和存储容器后,需要创建新的自定义 NER 项目。 项目是一个工作区,用于根据数据生成自定义 AI 模型。 只有你和对所使用的 Azure 资源具有访问权限的其他人才能访问你的项目。 如果已标记了数据,则可以通过导入项目来使用它入手。
登录到 Language Studio。 随即将出现一个窗口,供你选择订阅和语言资源。 选择在上一步中创建的语言资源。
在 Language Studio 的“提取信息”部分下,选择“自定义命名实体识别”。

从项目页的顶部菜单中选择“创建新项目”。 通过创建项目,可以标记数据、训练、评估、改进和部署模型。

单击“创建新项目”后,将显示一个窗口,供你连接存储帐户。 如果已连接了存储帐户,将看到该存储帐户已连接。 如果未显示,请从显示的下拉列表中选择你的存储帐户,然后选择“连接存储帐户”;这将为你的存储帐户设置所需的角色。 如果你没有被指定为存储帐户的“所有者”,此步骤可能会返回错误。
注意
- 只需为使用的每个新资源执行一次此步骤。
- 此过程是不可逆的,如果将一个存储帐户连接到你的语言资源,以后将无法断开其连接。
- 只能将你的语言资源连接到一个存储帐户。

输入项目信息,包括名称、说明和项目中文件的语言。 如果使用示例数据集,请选择“英语”。 以后将无法更改项目名称。 选择“下一步”
提示
你的数据集无须完全使用同一语言。 你可以有多个文档,每个文档都支持不同的语言。 如果数据集包含不同语言的文档,或者你在运行时需要不同语言的文本,请在输入项目基本信息时选择“启用多语言数据集”选项。 稍后可以从“项目设置”页面启用此选项。
选择你上传数据集的容器。
如果已标记了数据,请确保它遵循支持的格式,并且选择“是,我的文件已标记,并且我已设置 JSON 标签文件的格式”,然后从下拉菜单中选择标签文件。 选择“下一步”。
查看输入的数据,并选择“创建项目”。
若要开始创建自定义命名实体识别模型,需要创建项目。 通过创建项目,可以标记数据、训练、评估、改进和部署模型。
使用以下 URL、标头和 JSON 正文创建 PATCH 请求,以创建项目。
请求 URL
使用以下 URL 创建项目。 请将以下占位符值替换为你自己的值。
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| 占位符 |
值 |
示例 |
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 |
https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 |
myProject |
{API-VERSION} |
要调用的 API 版本。 此处引用的值适用于最新发布的版本。 请参阅模型生命周期,了解有关其他可用 API 版本的详细信息。 |
2022-05-01 |
使用以下标头对请求进行身份验证。
| 键 |
值 |
Ocp-Apim-Subscription-Key |
资源密钥。 用于对 API 请求进行身份验证。 |
Body
在请求中使用以下 JSON。 请将以下占位符值替换为你自己的值。
{
"projectName": "{PROJECT-NAME}",
"language": "{LANGUAGE-CODE}",
"projectKind": "CustomEntityRecognition",
"description": "Project description",
"multilingual": "True",
"storageInputContainerName": "{CONTAINER-NAME}"
}
| 密钥 |
占位符 |
值 |
示例 |
| projectName |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 |
myProject |
| 语言 |
{LANGUAGE-CODE} |
一个字符串,用于指定项目中使用的文档的语言代码。 如果项目是多语言项目,请选择大多数文档的语言代码。 请参阅语言支持了解有关支持的语言代码的详细信息。 |
en-us |
| projectKind |
CustomEntityRecognition |
项目类型。 |
CustomEntityRecognition |
| 多语言 |
true |
一个布尔值,它让你可以在你的数据集内拥有多种语言的文档,并且在部署模型后可以使用任何支持的语言(不一定包含在训练文档中)查询该模型。 请参阅语言支持,了解有关多语言支持的详细信息。 |
true |
| storageInputContainerName |
{CONTAINER-NAME |
上传文档的 Azure 存储容器的名称。 |
myContainer |
此请求将返回 201 响应,表示项目已创建。
此请求在以下情况下将返回错误:
导入项目
如果已标记了数据,则可以使用它来开始使用该服务。 请确保已标记的数据遵循接受的数据格式。
登录到 Language Studio。 随即将出现一个窗口,供你选择订阅和语言资源。 选择语言资源。
在 Language Studio 的“提取信息”部分下,选择“自定义命名实体识别”。
从项目页的顶部菜单中选择“创建新项目”。 通过创建项目,可以标记数据、训练、评估、改进和部署模型。
选择“创建新项目”后,将显示一个屏幕,供你连接存储帐户。 如果找不到存储帐户,请确保已使用建议的步骤创建了资源。 如果已将存储帐户连接到语言资源,将会看到你的存储帐户已连接。
注意
- 只需为使用的每个新语言资源执行一次此步骤。
- 此过程是不可逆的,如果将一个存储帐户连接到你的语言资源,以后将无法断开其连接。
- 只能将你的语言资源连接到一个存储帐户。
输入项目信息,包括名称、说明和项目中文件的语言。 以后将无法更改项目名称。 选择“下一页”。
提示
你的数据集无须完全使用同一语言。 你可以有多个文档,每个文档都支持不同的语言。 如果数据集包含不同语言的文档,或者你在运行时需要不同语言的文本,请在输入项目基本信息时选择“启用多语言数据集”选项。 稍后可以从“项目设置”页面启用此选项。
选择你上传数据集的容器。
选择“是,我的文件已标记,并且我已设置 JSON 标签文件的格式”,然后从下面的下拉菜单中选择标签文件以导入 JSON 标签文件。 请确保它遵循支持的格式。
选择下一步。
查看输入的数据,并选择“创建项目”。
使用以下 URL、标头和 JSON 正文提交 POST 请求,以导入标签文件。 请确保标签文件遵循接受的格式。
如果已存在同名的项目,则替换该项目的数据。
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| 占位符 |
值 |
示例 |
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 |
https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 |
myProject |
{API-VERSION} |
要调用的 API 版本。 此处引用的值适用于最新发布的版本。 请参阅模型生命周期,了解有关其他可用 API 版本的详细信息。 |
2022-05-01 |
使用以下标头对请求进行身份验证。
| 键 |
值 |
Ocp-Apim-Subscription-Key |
资源密钥。 用于对 API 请求进行身份验证。 |
Body
在请求中使用以下 JSON。 请将以下占位符值替换为你自己的值。
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"projectKind": "CustomEntityRecognition",
"description": "Trying out custom NER",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"storageInputContainerName": "{CONTAINER-NAME}",
"settings": {}
},
"assets": {
"projectKind": "CustomEntityRecognition",
"entities": [
{
"category": "Entity1"
},
{
"category": "Entity2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 500,
"labels": [
{
"category": "Entity1",
"offset": 25,
"length": 10
},
{
"category": "Entity2",
"offset": 120,
"length": 8
}
]
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 100,
"labels": [
{
"category": "Entity2",
"offset": 20,
"length": 5
}
]
}
]
}
]
}
}
| 密钥 |
占位符 |
值 |
示例 |
api-version |
{API-VERSION} |
要调用的 API 版本。 此处使用的版本必须与 URL 中的 API 版本相同。 详细了解其他可用的 API 版本 |
2022-03-01-preview |
projectName |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 |
myProject |
projectKind |
CustomEntityRecognition |
项目类型。 |
CustomEntityRecognition |
language |
{LANGUAGE-CODE} |
一个字符串,用于指定项目中使用的文档的语言代码。 如果项目是多语言项目,请选择大多数文档的语言代码。 |
en-us |
multilingual |
true |
一个布尔值,它让你可以在你的数据集内拥有多种语言的文档,并且在部署模型后可以使用任何支持的语言(不一定包含在训练文档中)查询该模型。 如需了解多语言支持,请参阅语言支持。 |
true |
storageInputContainerName |
{CONTAINER-NAME} |
上传文档的 Azure 存储容器的名称。 |
myContainer |
entities |
|
一个数组,其中包含项目中的所有实体类型。 这些是将从文档提取到的实体类型。 |
|
documents |
|
一个数组,其中包含项目中的所有文档和每个文档中标记的实体列表。 |
[] |
location |
{DOCUMENT-NAME} |
存储容器中文档的位置。 由于所有文档都位于容器的根目录中,因此这应为文档名称。 |
doc1.txt |
dataset |
{DATASET} |
该文件在训练前被拆分时将进入的测试集。 有关如何拆分数据的详细信息,请参阅如何训练模型。 此字段的可能值为 Train 和 Test。 |
Train |
发送 API 请求后,你将收到 202 响应,这表明作业已正确提交。 在响应头中,提取 operation-location 值。 其格式如下:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} 用于标识请求,因为此操作是异步操作。 你将使用此 URL 获取导入作业状态。
此请求可能出现的错误情况:
- 所选资源不具有该存储帐户的适当权限。
- 指定的
storageInputContainerName 不存在。
- 使用了无效的语言代码,或者语言代码类型不是字符串。
multilingual 值是一个字符串,而不是布尔值。
获取项目详细信息
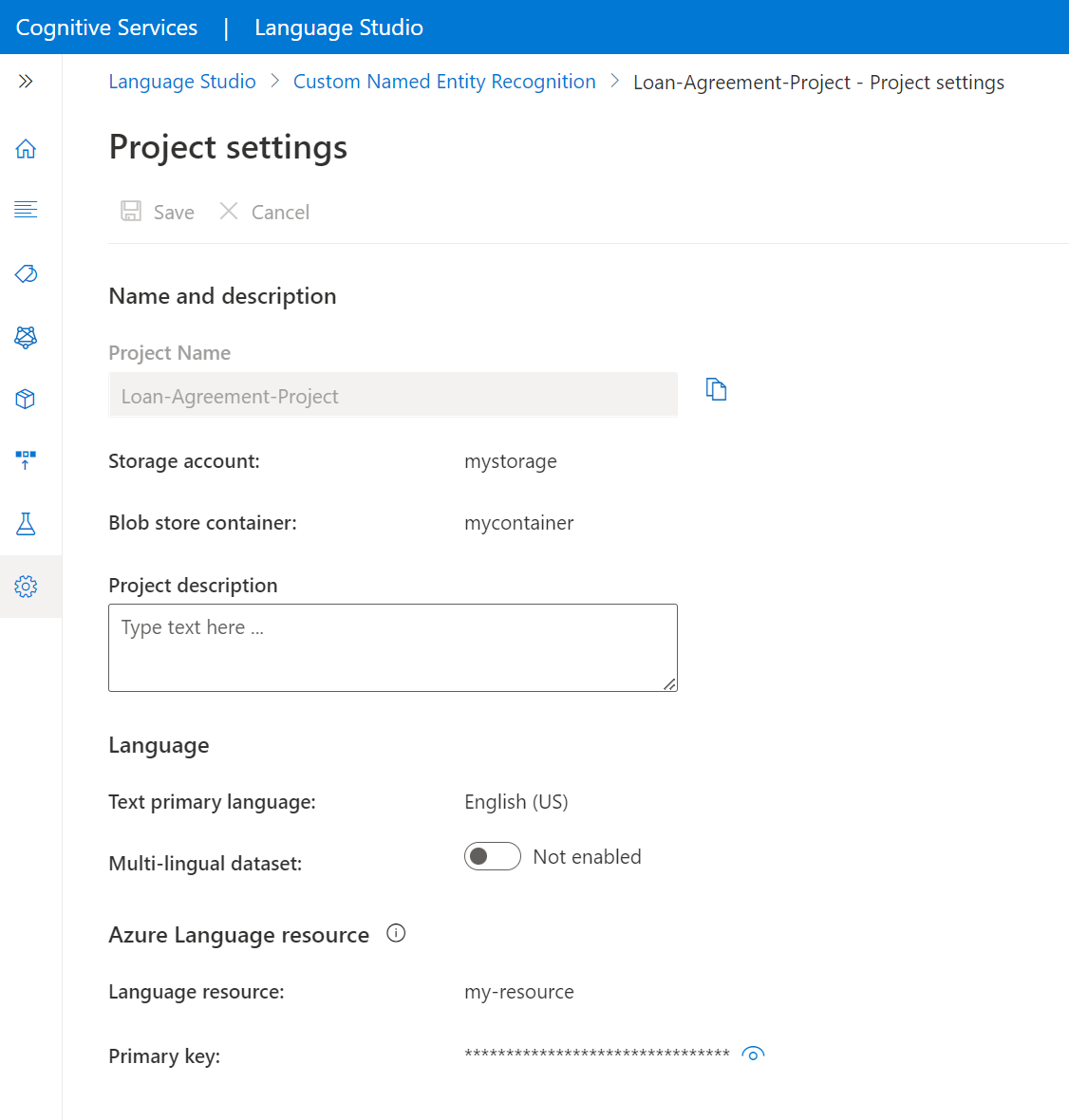
转到 Language Studio 中的“项目设置”页面。
可以看到项目详细信息。
在此页中,可以在项目设置中更新项目说明以及启用/禁用多语言数据集。
还可以查看已连接到语言资源的存储帐户和容器。
还可以从此页面检索主资源键。
使用以下 GET 请求获取项目详细信息。 请将以下占位符值替换为你自己的值。
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}?api-version={API-VERSION}
| 占位符 |
值 |
示例 |
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 |
https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 |
myProject |
{API-VERSION} |
要调用的 API 版本。 请参阅模型生命周期,了解有关其他可用 API 版本的详细信息。 |
2022-05-01 |
使用以下标头对请求进行身份验证。
| 键 |
值 |
Ocp-Apim-Subscription-Key |
资源密钥。 用于对 API 请求进行身份验证。 |
响应正文
{
"createdDateTime": "2021-10-19T23:24:41.572Z",
"lastModifiedDateTime": "2021-10-19T23:24:41.572Z",
"lastTrainedDateTime": "2021-10-19T23:24:41.572Z",
"lastDeployedDateTime": "2021-10-19T23:24:41.572Z",
"projectKind": "CustomEntityRecognition",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project description",
"language": "{LANGUAGE-CODE}"
}
| 值 |
占位符 |
说明 |
示例 |
projectKind |
CustomEntityRecognition |
项目类型。 |
CustomEntityRecognition |
storageInputContainerName |
{CONTAINER-NAME} |
上传文档的 Azure 存储容器的名称。 |
myContainer |
projectName |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 |
myProject |
multilingual |
true |
一个布尔值,它让你可以在你的数据集内拥有多种语言的文档,并且在部署模型后可以使用任何支持的语言(不一定包含在训练文档中)查询该模型。 如需详细了解多语言支持,请参阅语言支持。 |
true |
language |
{LANGUAGE-CODE} |
一个字符串,用于指定项目中使用的文档的语言代码。 如果项目是多语言项目,请选择大多数文档的语言代码。 |
en-us |
发送 API 请求后,将收到 200 响应(指示成功)和 JSON 响应正文(包含项目详细信息)。
删除项目
如果不再需要项目,可以使用 Language Studio 删除项目。 选择上方的“自定义命名实体识别 (NER)”,选择要删除的项目,然后选择顶部菜单中的“删除”。
不再需要项目时,可以使用以下 DELETE 请求将其删除。 将占位符值替换为你自己的值。
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| 占位符 |
值 |
示例 |
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 |
https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 |
myProject |
{API-VERSION} |
要调用的 API 版本。 此处引用的值适用于最新发布的版本。 请参阅模型生命周期,了解有关其他可用 API 版本的详细信息。 |
2022-05-01 |
使用以下标头对请求进行身份验证。
| 键 |
价值 |
| Ocp-Apim-Subscription-Key |
资源密钥。 用于对 API 请求进行身份验证。 |
发送 API 请求后,将收到一个指示成功的 202 响应,这意味着项目已被删除。 带有用于检查作业状态的 Operation-Location 标头的成功调用结果。
后续步骤






