查看要求之后,您可以开始创建文档处理模型了。
登录到 AI Builder
登录到 Power Apps 或 Power Automate。
在左侧窗格中,选择 ... 更多>AI 中心。
在发现 AI 能力下,选择 AI 模型。
(可选)要将 AI 模型永久保留在菜单上以便于访问,请选择大头针图标。
选择从文档中提取自定义信息。
选择创建自定义模型。
分步向导将要求您列出要从文档中提取的所有数据,从而引导您完成该过程。 如果希望使用自己的文档创建模型,请确保至少有五个使用相同布局的示例。 否则,可以使用示例数据来创建模型。
选择训练。
通过选择快速测试来测试模型。
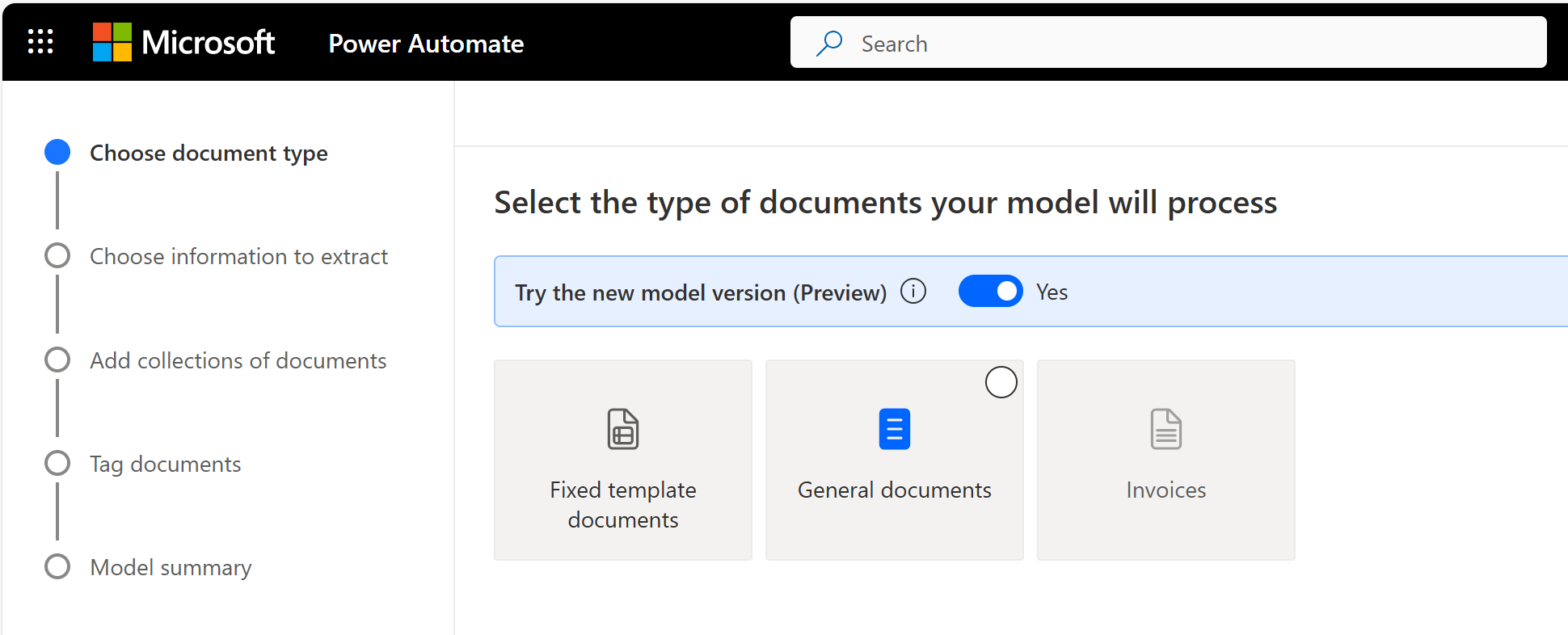
选择文档的类型
在选择文档类型步骤中,选择要构建 AI 模型以自动提取数据的文档类型。 有三个选项:
- 固定模板文档:以前称为结构化文档,对于给定的布局,当字段、表格、复选框、签名和其他项目可以在相似的位置找到时,此选项是非常理想的选择。 您可以教该模型从具有不同布局的结构化文档中提取数据。 该模型的训练时间很快。
- 常规文档:以前称为非结构化文档,此选项适用于任何类型的文档,尤其是没有固定结构或格式复杂的文档。 您可以教该模型从具有不同布局的结构化或非结构化文档中提取数据。 该模型功能强大,但训练时间长。
- 发票:通过添加在默认情况下没有提取的新字段或无法正确提取的文档示例来增强预生成发票处理模型的行为。
试用新模型版本(预览版)
通过选择试用新模型版本(预览版)切换开关,您可以尝试固定模板文档、常规文档和发票的最新预览模型版本。
重要提示
- 新模型版本是预览版。
- 预览版本不能用于生产,并且可能功能受限。 这些版本受补充使用条款的约束,在正式发布之前已经可用,以便客户可以及早使用并提供反馈。
先决条件
您的环境必须位于以下区域之一:澳大利亚、亚洲、加拿大、欧洲、法国、德国、日本、印度、挪威、南非、南美洲、韩国、瑞士、阿拉伯联合酋长国和美国。
使用预览模型的好处
- 提高准确性:期望更高的数据提取准确性。
- 最新 OCR 增强功能:预览模型包括最新的光学字符识别 (OCR) 更新。 此更新解决了许多常见的 OCR 问题,尤其是在处理条形码、QR 码和水印等复杂文本格式时。
- 表的置信度分数:您可以获取表、表行和单个表单元格的置信度分数
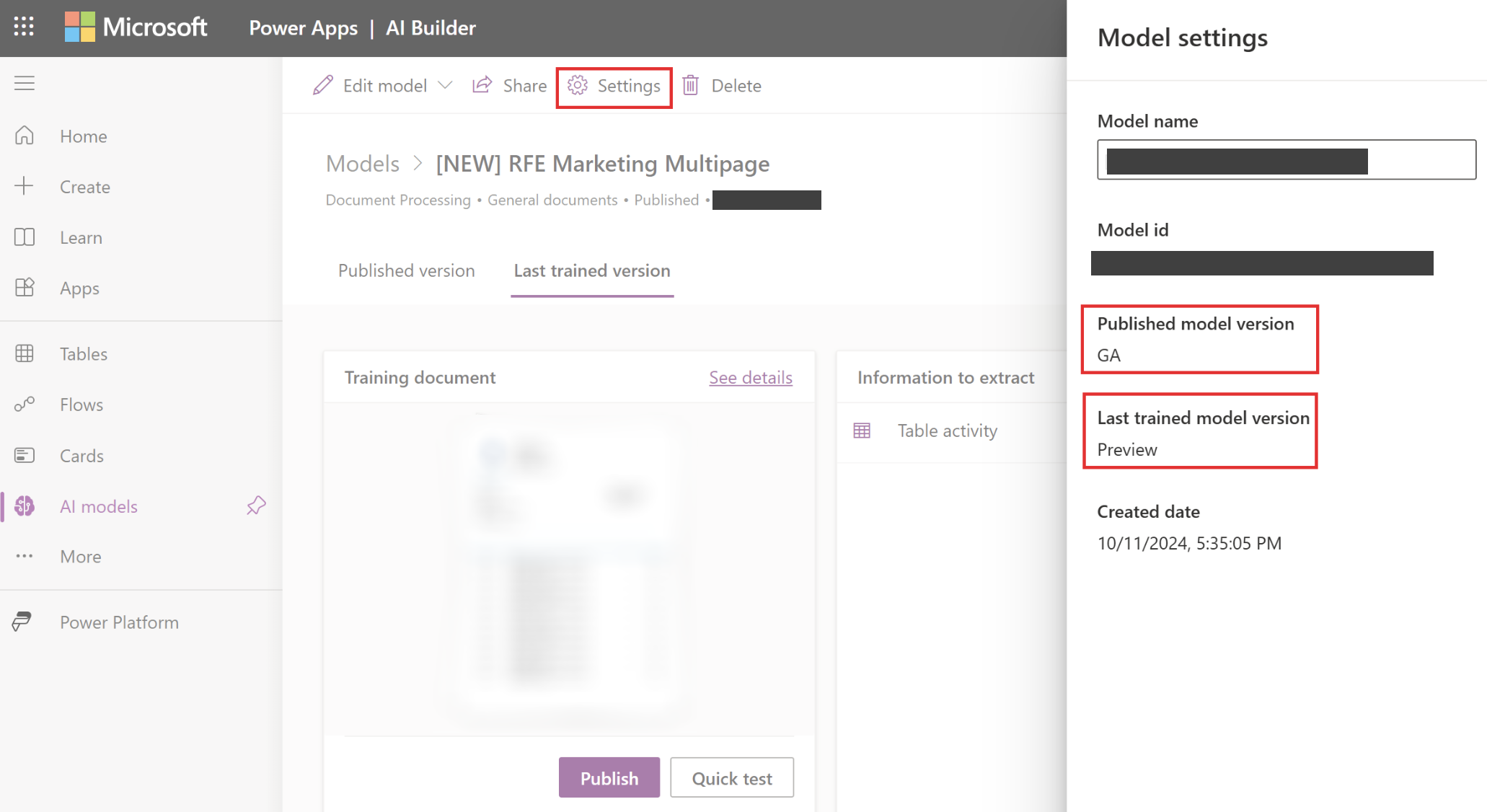
如何检查模型版本
您可以轻松验证用于训练和发布模型的版本。 选择设置>发布模型版本>上次训练模型版本。
如何更改模型版本
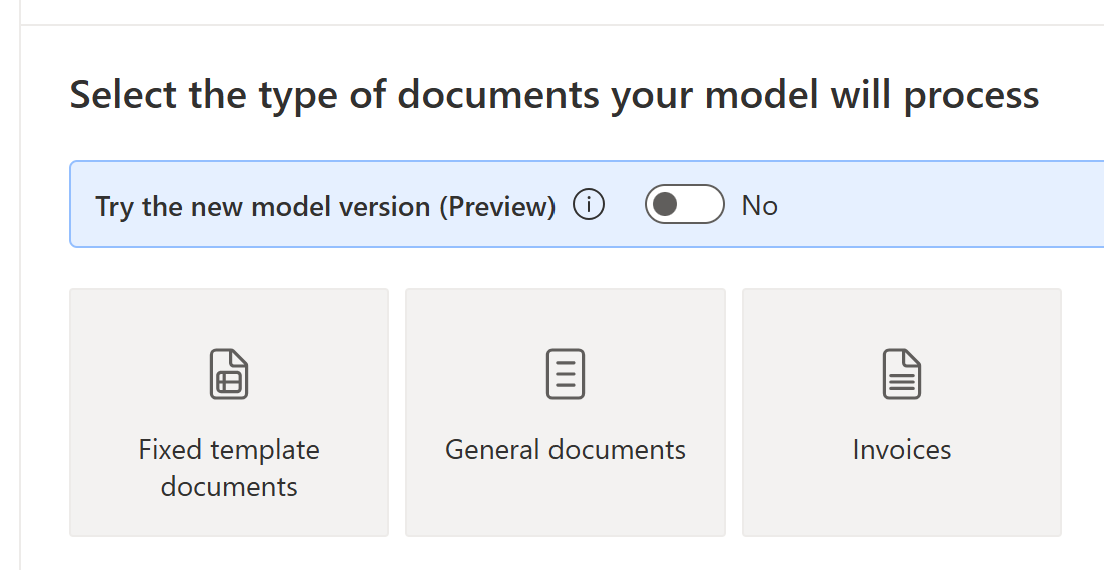
可以编辑经过训练或发布的模型版本(预览版),并使用正式发布(GA)版本对其进行训练。
- 选择编辑模型。
- 选择试用新模型版本(预览)。
- 选择否开关。
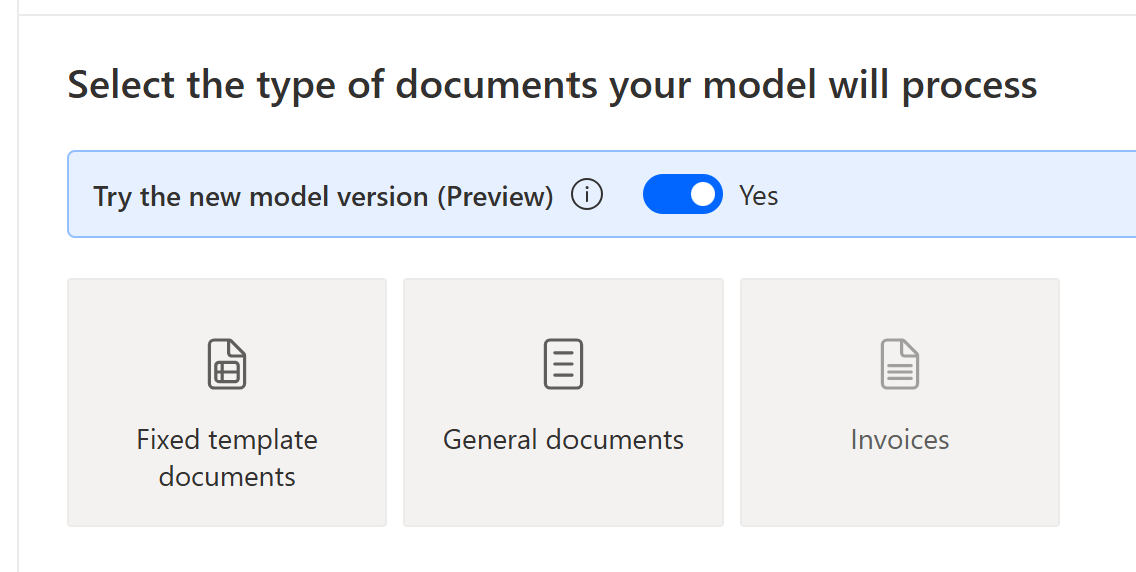
您可以编辑已训练或已发布的模型正式发布(GA)版本,并使用模型版本(预览)进行训练。
- 选择编辑模型。
- 选择试用新模型版本(预览)。
- 选择 是开关。
定义要提取的信息
在选择要提取的信息屏幕上,定义希望训练模型提取的字段、表和复选框。 选择 +添加按钮开始进行定义。

对于每个文本字段,提供要在模型中使用的字段名称。
对于每个数字字段,请提供要在模型中使用的字段名称。
此外,还可以将格式句点 (.) 或逗号 (,) 定义为小数分隔符。
对于每个日期字段,提供要在模型中使用的字段名称。
此外,还可以定义格式(年、月、日)、或(月、日、年)、或(日、月、年)。
对于每个复选框,请提供该复选框在模型中使用的名称。
为可以在文档中检查的每个项目定义单独的复选框。
对于每个表,请提供该表的名称。
另外,定义模型应提取的不同列。
备注
自定义发票模型附带有无法编辑的默认字段。
按集合对文档进行分组
集合是一组共享相同布局的文档。 应创建与您希望模型处理的文档布局同样多的集合。 例如,如果您正在构建一个 AI 模型来处理来自两个不同供应商的发票,每个供应商都有自己的发票模板,请创建两个集合。
对于创建的每个集合,您需要为每个集合至少上载五个示例文档。 当前接受 JPG、PNG 和 PDF 文件格式的文件。
备注
每个模型最多可以创建 200 个集合。