ค่าคลัสเตอร์
ค่าคลัสเตอร์จะสร้างกลุ่มที่มีค่าคล้ายกันโดยอัตโนมัติโดยใช้อัลกอริทึมการจับคู่ที่ไม่น่าเบื่อ แล้วแมปค่าของแต่ละคอลัมน์ไปยังกลุ่มที่ตรงกันที่สุด การแปลงนี้มีประโยชน์เมื่อคุณกําลังทํางานกับข้อมูลที่มีความแตกต่างมากมายเกี่ยวกับค่าเดียวกัน และคุณจําเป็นต้องรวมค่าต่างๆ ลงในกลุ่มที่สอดคล้องกัน
พิจารณาตารางตัวอย่างที่มี คอลัมน์ id ที่มีชุดของ ID และ คอลัมน์บุคคล ที่มีชุดชื่อชื่อ Miguel, Mike, William และ Bill ซึ่งสะกดคําต่างกันและเป็นตัวพิมพ์ใหญ่
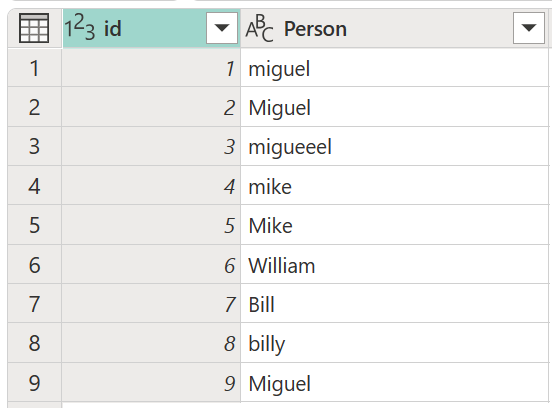
ในตัวอย่างนี้ ผลลัพธ์ที่คุณกําลังค้นหาคือตารางที่มีคอลัมน์ใหม่ที่แสดงกลุ่มค่าที่ถูกต้องจาก คอลัมน์ บุคคล และไม่ใช่การเปลี่ยนแปลงที่แตกต่างกันทั้งหมดของคําเดียวกัน
หมายเหตุ
คุณลักษณะค่าคลัสเตอร์จะพร้อมใช้งานสําหรับ Power Query Online เท่านั้น
สร้างคอลัมน์คลัสเตอร์
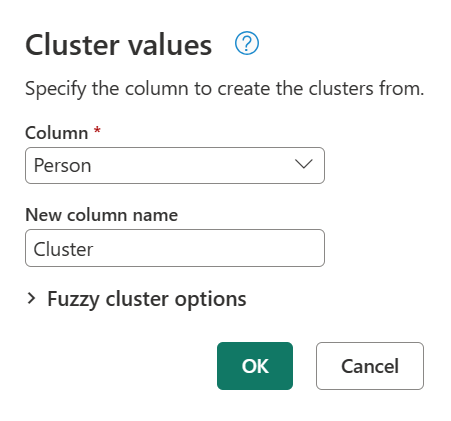
หากต้องการรวมค่าคลัสเตอร์ ก่อนอื่นให้เลือก คอลัมน์ Person ไปที่ แท็บ เพิ่มคอลัมน์ ใน ribbon จากนั้น เลือกตัวเลือกค่า คลัสเตอร์
![]()
ในกล่องโต้ตอบค่าคลัสเตอร์ ยืนยันคอลัมน์ที่คุณต้องการใช้เพื่อสร้างคลัสเตอร์จาก และป้อนชื่อใหม่ของคอลัมน์ สําหรับกรณีนี้ ตั้งชื่อคอลัมน์ คลัสเตอร์ใหม่นี้
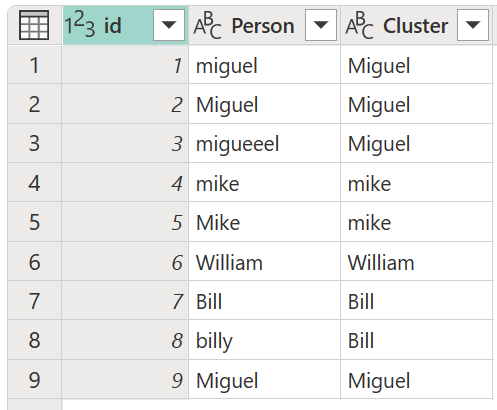
ผลลัพธ์ของการดําเนินการดังกล่าวจะแสดงในรูปภาพต่อไปนี้
หมายเหตุ
สําหรับแต่ละคลัสเตอร์ของค่า Power Query จะเลือกอินสแตนซ์ที่ใช้บ่อยที่สุดจากคอลัมน์ที่เลือกเป็นอินสแตนซ์ "มาตรฐาน" ถ้าหลายอินสแตนซ์เกิดขึ้นด้วยความถี่เดียวกัน Power Query จะเลือกอินสแตนซ์แรก
การใช้ตัวเลือกคลัสเตอร์ fuzzy
ตัวเลือกต่อไปนี้จะพร้อมใช้งานสําหรับการคลัสเตอร์ค่าในคอลัมน์ใหม่:
- ค่าเกณฑ์ความคล้ายคลึงกัน (ไม่บังคับ): ตัวเลือกนี้แสดงให้เห็นว่าค่าสองค่าที่คล้ายกันจะต้องถูกจัดกลุ่มเข้าด้วยกันอย่างไร การตั้งค่าต่ําสุดของศูนย์ (0) ทําให้ค่าทั้งหมดถูกจัดกลุ่มเข้าด้วยกัน การตั้งค่าสูงสุดของ 1 อนุญาตให้รวมค่าที่ตรงกับการจัดกลุ่มเข้าด้วยกันเท่านั้น ค่าเริ่มต้นคือ 0.8
- ละเว้นตัวพิมพ์: เมื่อมีการเปรียบเทียบสตริงข้อความ ตัวพิมพ์เล็กจะถูกละเว้น ตัวเลือกนี้จะถูกเปิดใช้งานโดยค่าเริ่มต้น
- จัดกลุ่มตามการรวมส่วนของข้อความ: อัลกอริทึมจะพยายามรวมส่วนของข้อความ (เช่น การรวม Micro และ soft ลงใน Microsoft) เพื่อจัดกลุ่มค่าต่างๆ
- แสดงคะแนนความคล้ายคลึงกัน: แสดงคะแนนความคล้ายคลึงกันระหว่างค่าอินพุตและค่าตัวแทนที่คํานวณหลังจากการคลัสเตอร์แบบไม่ชัดเจน
- ตารางการแปลง (ไม่บังคับ): คุณสามารถเลือกตารางการแปลงที่แมปค่า (เช่น การแมป MSFT ไปยัง Microsoft) เพื่อจัดกลุ่มเข้าด้วยกัน
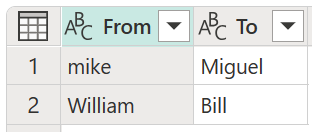
สําหรับตัวอย่างนี้ ตารางการแปลงใหม่ที่มีชื่อ ตาราง การแปลงของฉัน ถูกใช้เพื่อแสดงให้เห็นว่าสามารถแมปค่าได้อย่างไร ตารางการแปลงนี้มีสองคอลัมน์:
- จาก: สตริงข้อความที่จะค้นหาในตารางของคุณ
- ไปยัง: สตริงข้อความที่จะใช้เพื่อแทนที่สตริงข้อความในคอลัมน์ From
สำคัญ
สิ่งสําคัญคือตารางการแปลงมีคอลัมน์และชื่อคอลัมน์เดียวกันตามที่แสดงในรูปภาพก่อนหน้า (ต้องมีชื่อว่า "จาก" และ "ถึง") มิฉะนั้น Power Query จะไม่รู้จักตารางนี้เป็นตารางการแปลง และจะไม่มีการแปลงเกิดขึ้น
ใช้คิวรีที่สร้างขึ้นก่อนหน้านี้ ดับเบิลคลิกที่ ขั้นตอน ค่า กลุ่ม จากนั้นในกล่องโต้ตอบ ค่า คลัสเตอร์ ขยาย ตัวเลือกคลัสเตอร์ Fuzzy ภายใต้ ตัวเลือกคลัสเตอร์ Fuzzy เปิดใช้งาน ตัวเลือกแสดงคะแนน ความคล้ายคลึงกัน สําหรับ ตารางการแปลง (ไม่บังคับ) ให้เลือกคิวรีที่มีตารางการแปลง
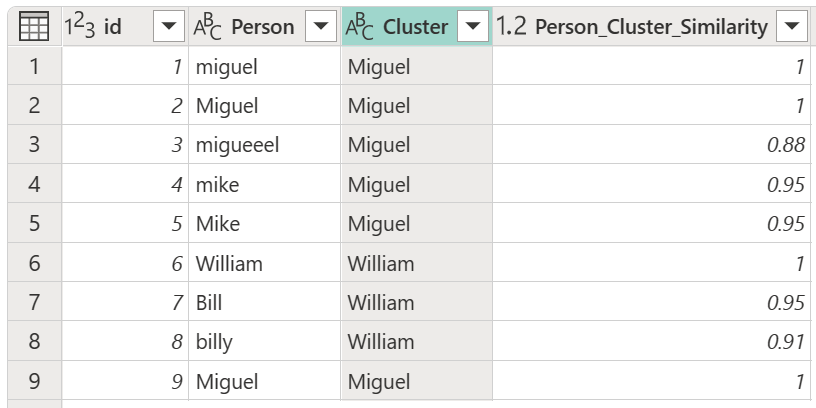
หลังจากเลือกตัวเลือก แสดงคะแนนความคล้ายคลึงกัน หลังจากเลือกตารางการแปลงของคุณและเปิดใช้งานตัวเลือก แสดงคะแนนความคล้ายคลึงกัน เลือก ตกลง ผลลัพธ์ของการดําเนินการนั้นทําให้คุณมีตารางที่มี id เดียวกันและคอลัมน์บุคคลเป็นตารางต้นฉบับ แต่ยังมีสองคอลัมน์ใหม่ที่เรียกว่าคลัสเตอร์และ Person_Cluster_Similarity คอลัมน์ คลัสเตอร์ ประกอบด้วยชื่อ Miguel เวอร์ชันที่สะกดและเป็นตัวพิมพ์ใหญ่อย่างถูกต้องสําหรับเวอร์ชันของ Miguel และ Mike และ William สําหรับเวอร์ชันของ Bill, Billy และ William คอลัมน์ Person_Cluster_Similarity ประกอบด้วยคะแนนความคล้ายคลึงกันสําหรับแต่ละชื่อ
ยอมรับตารางการแปลง
คุณอาจสังเกตเห็นว่าตารางการแปลงในส่วนก่อนหน้านี้ปรากฏขึ้นเพื่อระบุว่าอินสแตนซ์ของ Mike มีการเปลี่ยนแปลงเป็น Miguel และอินสแตนซ์ของ William จะเปลี่ยนเป็น Bill อย่างไรก็ตาม ในตารางผลลัพธ์ อินสแตนซ์ของ Bill และ "billy" จะเปลี่ยนเป็น William แทน ในตารางการแปลง แทนที่จะเป็นเส้นทางจาก จาก ถึง ถึง ตารางการแปลงจะสมมาตรในระหว่างการคลัสเตอร์ ซึ่งหมายความว่า "mike" เทียบเท่ากับ "Miguel" และในทางกลับกัน ผลลัพธ์ของค่าที่เทียบเท่าที่กําหนดในตารางการแปลงจะขึ้นอยู่กับกฎต่อไปนี้:
- หากมีค่าที่เหมือนกันเป็นส่วนใหญ่ ค่าเหล่านี้จะมีความสําคัญเหนือค่าที่ไม่ใช่ค่าเฉพาะ
- ถ้าไม่มีค่าส่วนใหญ่ ค่าที่ปรากฏก่อนจะมีความสําคัญก่อน
ตัวอย่างเช่น ในตารางต้นฉบับที่ใช้ในบทความนี้ Miguel เวอร์ชัน (ทั้ง "miguel" และ Miguel) ใน คอลัมน์ Person จะสร้างอินสแตนซ์ส่วนใหญ่ของชื่อ Miguel และ Mike นอกจากนี้ชื่อ Miguel ที่มีตัวพิมพ์ใหญ่เริ่มต้นส่วนใหญ่ของชื่อ Miguel ดังนั้นการเชื่อมโยง Miguel กับดัดแปลงและ Mike และผลที่ได้จากการแปลงผลลัพธ์ของตารางในชื่อ Miguel ที่ใช้ในคอลัมน์คลัสเตอร์
อย่างไรก็ตาม สําหรับชื่อ William, Bill และ "billy" ไม่มีค่าส่วนใหญ่เนื่องจากทั้งสามค่าไม่ซ้ํากัน เนื่องจาก William ปรากฏก่อน William จะถูกใช้ในคอลัมน์คลัสเตอร์ หาก "billy" ปรากฏตัวแรกในตาราง ดังนั้น "billy" จะถูกใช้ในคอลัมน์คลัสเตอร์ นอกจากนี้ เนื่องจากไม่มีค่าส่วนใหญ่ จึงมีการใช้กรณีของชื่อแต่ละชื่อ นั่นคือถ้า William เป็นอันดับแรก William ที่มีตัวพิมพ์ใหญ่ "W" จะถูกใช้เป็นค่าผลลัพธ์ ถ้า "billy" เป็นอันดับแรก "billy" ด้วยตัวพิมพ์เล็ก "b" จะถูกใช้