บทช่วยสอน: ค้นหาความสัมพันธ์ในแบบจําลองความหมายโดยใช้ลิงก์ความหมาย
บทช่วยสอนนี้แสดงวิธีการโต้ตอบกับ Power BI จากสมุดบันทึก Jupyter และตรวจหาความสัมพันธ์ระหว่างตารางด้วยความช่วยเหลือของไลบรารี SemPy
ในบทช่วยสอนนี้ คุณจะได้เรียนรู้วิธีการ:
- ค้นหาความสัมพันธ์ในแบบจําลองความหมาย (ชุดข้อมูล Power BI) โดยใช้ไลบรารี Python ของลิงก์เชิงความหมาย (SemPy)
- ใช้ส่วนประกอบของ SemPy ที่รองรับการผสานรวมกับ Power BI และช่วยในการวิเคราะห์คุณภาพข้อมูลโดยอัตโนมัติ คอมโพเนนต์เหล่านี้ประกอบด้วย:
- FabricDataFrame - โครงสร้างที่คล้ายกับ pandas เพิ่มขึ้นด้วยข้อมูลความหมายเพิ่มเติม
- ฟังก์ชันสําหรับการดึงแบบจําลองความหมายจากพื้นที่ทํางาน Fabric ลงในสมุดบันทึกของคุณ
- ฟังก์ชันที่ทําให้การประเมินสมมติฐานเกี่ยวกับการขึ้นต่อกันของการทํางานเป็นแบบอัตโนมัติและระบุการละเมิดความสัมพันธ์ในแบบจําลองความหมายของคุณ
ข้อกําหนดเบื้องต้น
รับ การสมัครใช้งาน Microsoft Fabric หรือลงทะเบียนสําหรับ Microsoft Fabric รุ่นทดลองใช้ฟรี
ลงชื่อเข้าใช้ Microsoft Fabric
ใช้ตัวสลับประสบการณ์การใช้งานที่ด้านล่างซ้ายของหน้าหลักของคุณเพื่อเปลี่ยนเป็น Fabric

เลือก พื้นที่ทํางาน จากบานหน้าต่างนําทางด้านซ้ายเพื่อค้นหาและเลือกพื้นที่ทํางานของคุณ พื้นที่ทํางานนี้จะกลายเป็นพื้นที่ทํางานปัจจุบันของคุณ
ดาวน์โหลด ตัวอย่างความสามารถในการทํากําไรลูกค้า.pbix และตัวอย่างความสามารถในการทํากําไรลูกค้า (อัตโนมัติ).pbix แบบจําลองเชิงความหมายจากที่เก็บ GitHub ตัวอย่างผ้า และอัปโหลดไปยังพื้นที่ทํางานของคุณ
ติดตามในสมุดบันทึก
powerbi_relationships_tutorial.ipynb สมุดบันทึกจะมาพร้อมกับบทช่วยสอนนี้
เมื่อต้องการเปิดสมุดบันทึกที่มาพร้อมกับบทช่วยสอนนี้ ให้ทําตามคําแนะนําใน เตรียมระบบของคุณสําหรับบทช่วยสอนวิทยาศาสตร์ข้อมูล การนําเข้าสมุดบันทึกไปยังพื้นที่ทํางานของคุณ
ถ้าคุณต้องการคัดลอกและวางโค้ดจากหน้านี้ สร้างสมุดบันทึกใหม่
ตรวจสอบให้แน่ใจว่า แนบ lakehouse เข้ากับ สมุดบันทึกก่อนที่คุณจะเริ่มเรียกใช้โค้ด
ตั้งค่าสมุดบันทึก
ในส่วนนี้ คุณตั้งค่าสภาพแวดล้อมของสมุดบันทึกด้วยโมดูลและข้อมูลที่จําเป็น
ติดตั้ง
SemPyจาก PyPI โดยใช้ความสามารถในการติดตั้ง%pipในบรรทัดภายในสมุดบันทึก:%pip install semantic-linkทําการนําเข้าโมดูล SemPy ที่จําเป็นต่อมา:
import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violationsนําเข้า pandas สําหรับการบังคับใช้ตัวเลือกการกําหนดค่าที่ช่วยในการจัดรูปแบบผลลัพธ์:
import pandas as pd pd.set_option('display.max_colwidth', None)
สํารวจแบบจําลองความหมาย
บทช่วยสอนนี้ใช้แบบจําลองความหมายตัวอย่างมาตรฐาน ตัวอย่างความสามารถในการทํากําไรลูกค้า.pbix สําหรับคําอธิบายของแบบจําลองความหมาย ให้ดู ตัวอย่างความสามารถในการทํากําไรลูกค้าสําหรับ Power BI
ใช้ฟังก์ชัน
list_datasetsของ SemPy เพื่อสํารวจแบบจําลองความหมายในพื้นที่ทํางานปัจจุบันของคุณ:fabric.list_datasets()
สําหรับส่วนที่เหลือของสมุดบันทึกนี้ คุณใช้แบบจําลองความหมายตัวอย่างความสามารถในการทํากําไรลูกค้าสองเวอร์ชัน:
- ตัวอย่างความสามารถในการทํากําไรลูกค้า : แบบจําลองความหมายตามมาจากตัวอย่าง Power BI ที่มีความสัมพันธ์ของตารางที่กําหนดไว้ล่วงหน้า
- ตัวอย่างความสามารถในการทํากําไรสําหรับลูกค้า (อัตโนมัติ): ข้อมูลเดียวกัน แต่ความสัมพันธ์จะถูกจํากัดไว้เฉพาะความสัมพันธ์ที่ Power BI จะตรวจหาโดยอัตโนมัติ
แยกแบบจําลองความหมายตัวอย่างด้วยแบบจําลองความหมายที่กําหนดไว้ล่วงหน้า
โหลดความสัมพันธ์ที่กําหนดไว้ล่วงหน้าและจัดเก็บไว้ภายในตัวอย่างความสามารถในการทํากําไรลูกค้า แบบจําลองความหมายโดยใช้ฟังก์ชัน
list_relationshipsของ SemPy ฟังก์ชันนี้แสดงรายการจากแบบจําลองออบเจ็กต์ Tabular:dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsแสดงภาพ
relationshipsDataFrame เป็นกราฟ โดยใช้ฟังก์ชันplot_relationship_metadataของ SemPy:plot_relationship_metadata(relationships)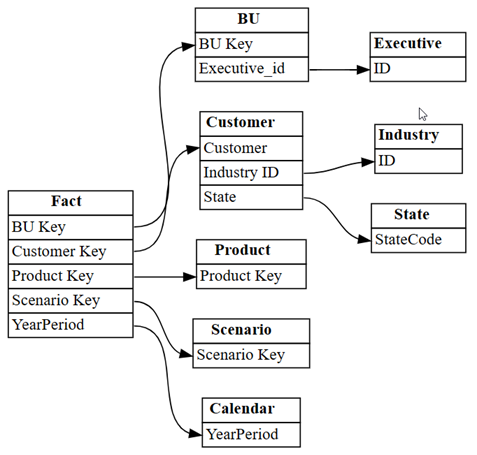

กราฟนี้แสดง "ความจริงพื้นฐาน" สําหรับความสัมพันธ์ระหว่างตารางในแบบจําลองความหมายนี้ เนื่องจากแสดงถึงวิธีการกําหนดใน Power BI โดยผู้เชี่ยวชาญเฉพาะเรื่อง
การค้นพบความสัมพันธ์เพิ่มเติม
ถ้าคุณเริ่มต้นด้วยความสัมพันธ์ที่ Power BI ตรวจพบโดยอัตโนมัติ คุณจะมีชุดขนาดเล็กกว่า
แสดงภาพความสัมพันธ์ที่ Power BI ตรวจพบโดยอัตโนมัติในแบบจําลองความหมาย:
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)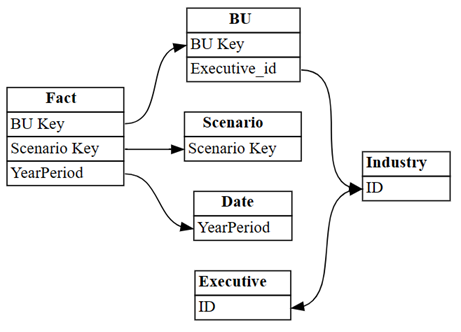
การตรวจหาอัตโนมัติของ Power BI ขาดความสัมพันธ์มากมาย ยิ่งไปกว่านั้น ความสัมพันธ์ที่ตรวจพบโดยอัตโนมัติสองความสัมพันธ์ไม่ถูกต้องในเชิงความหมาย:
-
Executive[ID]->Industry[ID] -
BU[Executive_id]->Industry[ID]
-
พิมพ์ความสัมพันธ์เป็นตาราง:
autodetectedความสัมพันธ์ที่ไม่ถูกต้องกับตาราง
Industryปรากฏในแถวที่มีดัชนี 3 และ 4 ใช้ข้อมูลนี้เพื่อเอาแถวเหล่านี้ออกละทิ้งความสัมพันธ์ที่ระบุอย่างไม่ถูกต้อง
autodetected.drop(index=[3,4], inplace=True) autodetectedตอนนี้คุณมีความสัมพันธ์ที่ถูกต้อง แต่ไม่สมบูรณ์
แสดงภาพความสัมพันธ์ที่ไม่สมบูรณ์เหล่านี้โดยใช้
plot_relationship_metadata:plot_relationship_metadata(autodetected)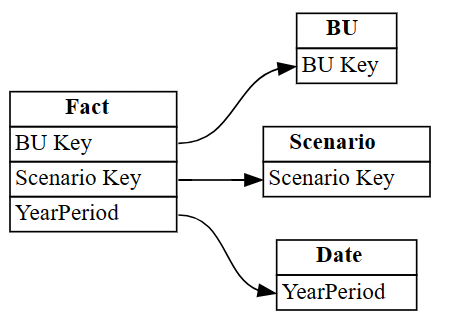
โหลดตารางทั้งหมดจากแบบจําลองความหมายโดยใช้ฟังก์ชัน
list_tablesและread_tableของ SemPy:tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()ค้นหาความสัมพันธ์ระหว่างตาราง โดยใช้
find_relationshipsและตรวจทานผลลัพธ์บันทึกเพื่อรับข้อมูลเชิงลึกบางอย่างเกี่ยวกับวิธีการทํางานของฟังก์ชันนี้:suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )แสดงความสัมพันธ์ที่ค้นพบใหม่:
plot_relationship_metadata(suggested_relationships_all)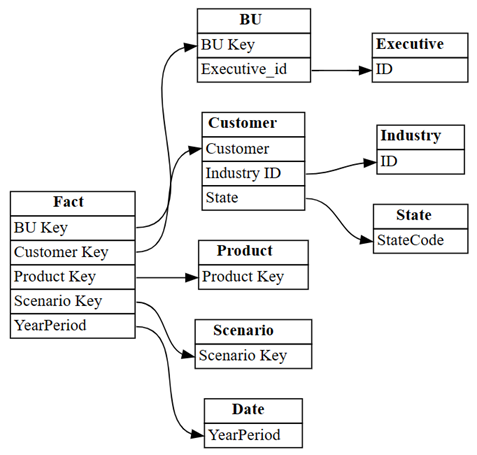
SemPy สามารถตรวจหาความสัมพันธ์ทั้งหมดได้
ใช้พารามิเตอร์
excludeเพื่อจํากัดการค้นหาสําหรับความสัมพันธ์เพิ่มเติมที่ไม่ได้ระบุไว้ก่อนหน้านี้:additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



ตรวจสอบความสัมพันธ์
ก่อนอื่น โหลดข้อมูลจากตัวอย่างความสามารถในการทํากําไรลูกค้า แบบจําลองความหมาย:
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()ตรวจสอบการทับซ้อนของค่าคีย์หลักและนอก (foreign key) โดยใช้ฟังก์ชัน
list_relationship_violationsใส่เอาต์พุตของฟังก์ชันlist_relationshipsเป็นข้อมูลป้อนเข้าไปยังlist_relationship_violations:list_relationship_violations(tables, fabric.list_relationships(dataset))การละเมิดความสัมพันธ์ให้ข้อมูลเชิงลึกที่น่าสนใจบางอย่าง ตัวอย่างเช่น ค่าหนึ่งในเจ็ดค่าใน
Fact[Product Key]ไม่มีอยู่ในProduct[Product Key]และคีย์ที่ขาดหายไปนี้คือ50
การวิเคราะห์ข้อมูลการสํารวจเป็นกระบวนการที่น่าตื่นเต้นและเป็นการทําความสะอาดข้อมูล มีบางสิ่งที่ข้อมูลกําลังซ่อนอยู่เสมอ โดยขึ้นอยู่กับลักษณะที่คุณดู สิ่งที่คุณต้องการถาม และอื่นๆ ลิงก์เชิงความหมายนําเสนอเครื่องมือใหม่ที่คุณสามารถใช้เพื่อให้บรรลุผลมากขึ้นด้วยข้อมูลของคุณ
เนื้อหาที่เกี่ยวข้อง
ดูบทช่วยสอนอื่น ๆ สําหรับลิงก์ความหมาย / SemPy:
- บทช่วยสอน : ล้างข้อมูลด้วยการขึ้นต่อกัน การทํางาน
- บทช่วยสอน : วิเคราะห์การขึ้นต่อกันของฟังก์ชันการทํางานในแบบจําลองความหมายตัวอย่าง
- บทช่วยสอน : แยกและคํานวณหน่วยวัด Power BI จากสมุดบันทึก Jupyter
- บทช่วยสอน
: ค้นหาความสัมพันธ์ในชุดข้อมูล Synthea โดยใช้ลิงก์ความหมาย - บทช่วยสอน : ตรวจสอบข้อมูลโดยใช้ SemPy และความคาดหวังที่ยิ่งใหญ่ (GX)