บทช่วยสอน: วิเคราะห์การขึ้นต่อกันของฟังก์ชันในแบบจําลองความหมาย
ในบทช่วยสอนนี้ คุณสร้างงานที่ทําก่อนหน้านี้โดยนักวิเคราะห์ Power BI และจัดเก็บในรูปแบบของแบบจําลองความหมาย (ชุดข้อมูล Power BI) โดยใช้ SemPy (ตัวอย่าง) ในประสบการณ์วิทยาศาสตร์ข้อมูล Synapse ภายใน Microsoft Fabric คุณสามารถวิเคราะห์การขึ้นต่อกันของฟังก์ชันการทํางานที่มีอยู่ในคอลัมน์ของ DataFrame ได้ การวิเคราะห์นี้ช่วยในการค้นหาปัญหาคุณภาพของข้อมูลที่ไม่เป็นทางการเพื่อให้ได้ข้อมูลเชิงลึกที่ถูกต้องยิ่งขึ้น
ในบทช่วยสอนนี้ คุณจะได้เรียนรู้วิธีการ:
- นําความรู้โดเมนไปใช้เพื่อกําหนดสมมติฐานเกี่ยวกับการขึ้นต่อกันของฟังก์ชันการทํางานในแบบจําลองความหมาย
- ทําความคุ้นเคยกับคอมโพเนนต์ของไลบรารี Python ของลิงก์ความหมาย (SemPy) ที่สนับสนุนการผสานรวมกับ Power BI และช่วยในการวิเคราะห์คุณภาพข้อมูลโดยอัตโนมัติ คอมโพเนนต์เหล่านี้ประกอบด้วย:
- FabricDataFrame - โครงสร้างที่คล้ายกับ pandas เพิ่มขึ้นด้วยข้อมูลความหมายเพิ่มเติม
- ฟังก์ชันที่มีประโยชน์สําหรับการดึงแบบจําลองความหมายจากพื้นที่ทํางาน Fabric ลงในสมุดบันทึกของคุณ
- ฟังก์ชันที่มีประโยชน์ที่ทําให้การประเมินสมมติฐานเกี่ยวกับการขึ้นต่อกันของการทํางานเป็นแบบอัตโนมัติและระบุการละเมิดความสัมพันธ์ในแบบจําลองความหมายของคุณ
ข้อกําหนดเบื้องต้น
รับ การสมัครใช้งาน Microsoft Fabric หรือลงทะเบียนสําหรับ Microsoft Fabric รุ่นทดลองใช้ฟรี
ลงชื่อเข้าใช้ Microsoft Fabric
ใช้ตัวสลับประสบการณ์การใช้งานที่ด้านล่างซ้ายของหน้าหลักของคุณเพื่อเปลี่ยนเป็น Fabric

เลือก พื้นที่ทํางาน จากบานหน้าต่างนําทางด้านซ้ายเพื่อค้นหาและเลือกพื้นที่ทํางานของคุณ พื้นที่ทํางานนี้จะกลายเป็นพื้นที่ทํางานปัจจุบันของคุณ
ดาวน์โหลด
ตัวอย่างความสามารถในการทํากําไรลูกค้า.pbix ในพื้นที่ทํางานของคุณ ให้เลือก นําเข้ารายงาน>หรือ>รายงานที่มีการแบ่งหน้า จากคอมพิวเตอร์เครื่องนี้ อัปโหลดไฟล์ Customer Profitability Sample.pbix ไปยังพื้นที่ทํางานของคุณ
ติดตามในสมุดบันทึก
powerbi_dependencies_tutorial.ipynb สมุดบันทึกมาพร้อมกับบทช่วยสอนนี้
เมื่อต้องการเปิดสมุดบันทึกที่มาพร้อมกับบทช่วยสอนนี้ ให้ทําตามคําแนะนําใน เตรียมระบบของคุณสําหรับบทช่วยสอนวิทยาศาสตร์ข้อมูล การนําเข้าสมุดบันทึกไปยังพื้นที่ทํางานของคุณ
ถ้าคุณต้องการคัดลอกและวางโค้ดจากหน้านี้ สร้างสมุดบันทึกใหม่
ตรวจสอบให้แน่ใจว่า แนบ lakehouse เข้ากับ สมุดบันทึกก่อนที่คุณจะเริ่มเรียกใช้โค้ด
ตั้งค่าสมุดบันทึก
ในส่วนนี้ คุณตั้งค่าสภาพแวดล้อมของสมุดบันทึกด้วยโมดูลและข้อมูลที่จําเป็น
ติดตั้ง
SemPyจาก PyPI โดยใช้ความสามารถในการติดตั้ง%pipในบรรทัดภายในสมุดบันทึก:%pip install semantic-linkทําการนําเข้าโมดูลที่จําเป็นซึ่งคุณจะต้องใช้ในภายหลัง:
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
โหลดและประมวลผลข้อมูลล่วงหน้า
บทช่วยสอนนี้ใช้แบบจําลองความหมายตัวอย่างมาตรฐาน ตัวอย่างความสามารถในการทํากําไรลูกค้า.pbix สําหรับคําอธิบายของแบบจําลองความหมาย ให้ดู ตัวอย่างความสามารถในการทํากําไรลูกค้าสําหรับ Power BI
โหลดข้อมูล Power BI ลงใน FabricDataFrames โดยใช้ฟังก์ชัน
read_tableของ SemPy:dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()โหลดตาราง
Stateลงใน FabricDataFrame:state = fabric.read_table(dataset, "State") state.head()ในขณะที่ผลลัพธ์ของโค้ดนี้ดูเหมือน DataFrame ของ pandas คุณได้เริ่มต้นโครงสร้างข้อมูลที่เรียกว่า
FabricDataFrameที่สนับสนุนการดําเนินการที่มีประโยชน์บางอย่างที่ด้านบนของ pandasตรวจสอบชนิดข้อมูล ของ
customer:type(customer)เอาต์พุตยืนยันว่า
customerเป็นชนิดsempy.fabric._dataframe._fabric_dataframe.FabricDataFrame.'เข้าร่วม
customerและstateDataFrames:customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
ระบุการขึ้นต่อกันของฟังก์ชันการทํางาน
การแสดงการขึ้นต่อกันของฟังก์ชันการทํางานเป็นความสัมพันธ์แบบหนึ่งต่อกลุ่มระหว่างค่าในคอลัมน์สองคอลัมน์ (หรือมากกว่า) ภายใน DataFrame ความสัมพันธ์เหล่านี้สามารถใช้เพื่อตรวจหาปัญหาคุณภาพของข้อมูลโดยอัตโนมัติ
เรียกใช้ฟังก์ชัน
find_dependenciesของ SemPy บน DataFrame ที่ผสานเพื่อระบุการขึ้นต่อกันของฟังก์ชันที่มีอยู่ระหว่างค่าในคอลัมน์:dependencies = customer_state_df.find_dependencies() dependenciesแสดงภาพการขึ้นต่อกันที่ระบุโดยใช้ฟังก์ชัน
plot_dependency_metadataของ SemPy:plot_dependency_metadata(dependencies)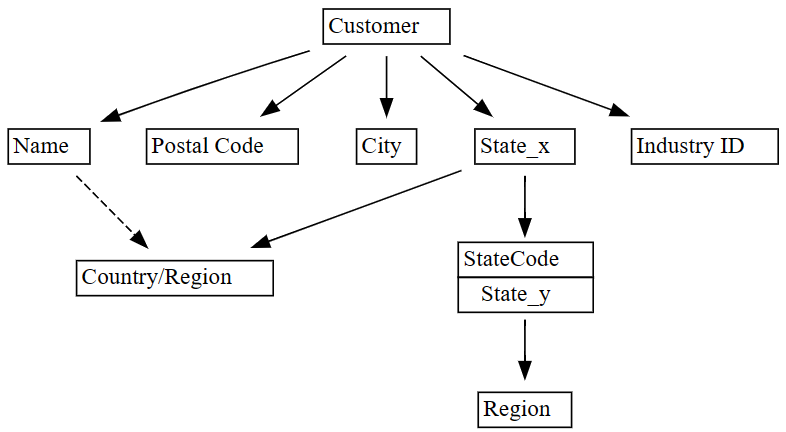
ตามที่คาดไว้ กราฟการขึ้นต่อกันของฟังก์ชันการทํางานแสดงให้เห็นว่าคอลัมน์
Customerจะกําหนดบางคอลัมน์เช่นCity,Postal Code, และNameน่าแปลกใจที่กราฟไม่แสดงการขึ้นต่อกันของฟังก์ชันการทํางานระหว่าง
CityและPostal Codeอาจเนื่องมาจากมีการละเมิดมากมายในความสัมพันธ์ระหว่างคอลัมน์ คุณสามารถใช้ฟังก์ชันplot_dependency_violationsของ SemPy เพื่อแสดงภาพการละเมิดการขึ้นต่อกันระหว่างคอลัมน์ที่ระบุ

สํารวจข้อมูลสําหรับปัญหาด้านคุณภาพ
วาดกราฟด้วยฟังก์ชันการแสดงภาพ
plot_dependency_violationsของ SemPycustomer_state_df.plot_dependency_violations('Postal Code', 'City')
พล็อตของการละเมิดการขึ้นต่อกันแสดงค่าสําหรับ
Postal Codeทางด้านซ้าย มือ และค่าสําหรับCityทางด้านขวา ขอบเชื่อมต่อPostal Codeทางด้านซ้ายมือกับCityทางด้านขวาหากมีแถวที่มีสองค่าเหล่านี้ ขอบจะถูกใส่คําอธิบายประกอบไว้ด้วยการนับจํานวนแถวดังกล่าว ตัวอย่างเช่น มีสองแถวที่มีรหัสไปรษณีย์ 20004 แถวหนึ่งมีเมือง "North Tower" และอีกแถวที่มีเมือง "Washington"นอกจากนี้ แผนภูมิยังแสดงการละเมิดบางอย่างและค่าว่างมากมาย
ยืนยันจํานวนค่าว่างสําหรับ
Postal Code:customer_state_df['Postal Code'].isna().sum()50 แถวมี NA สําหรับรหัสไปรษณีย์
ทิ้งแถวพร้อมค่าว่าง จากนั้น ค้นหาการขึ้นต่อกันโดยใช้ฟังก์ชัน
find_dependenciesโปรดสังเกตverbose=1พารามิเตอร์พิเศษที่ดูการทํางานภายในของ SemPy:customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)Entropy แบบมีเงื่อนไขสําหรับ
Postal CodeและCityคือ 0.049 ค่านี้ระบุว่ามีการละเมิดการขึ้นต่อกันของการทํางาน ก่อนที่คุณจะแก้ไขการละเมิด ให้เพิ่มเกณฑ์บน entropy แบบมีเงื่อนไขจากค่าเริ่มต้นของ0.01ถึง0.05เพียงดูการขึ้นต่อกัน ค่าเกณฑ์ต่ํากว่าส่งผลให้เกิดการขึ้นต่อกันน้อยลง (หรือตัวเลือกที่สูงขึ้น)เพิ่มค่าเกณฑ์ใน entropy แบบมีเงื่อนไขจากค่าเริ่มต้นของ
0.01เป็น0.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))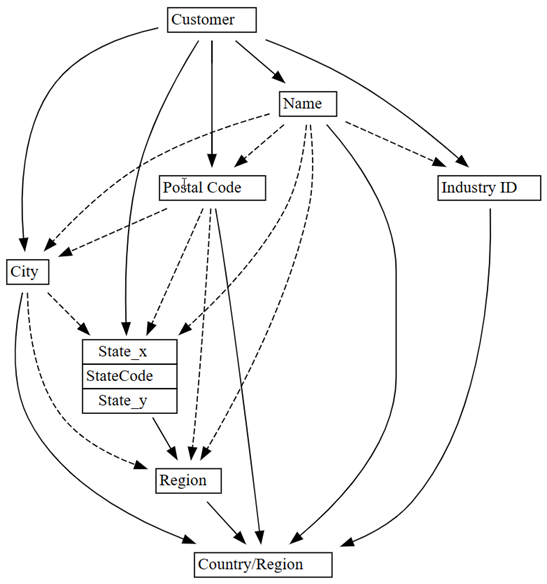
ถ้าคุณนําความรู้โดเมนที่เอนทิตีกําหนดค่าของเอนทิตีอื่น กราฟการขึ้นต่อกันนี้ดูเหมือนถูกต้อง
สํารวจปัญหาคุณภาพของข้อมูลที่ถูกตรวจพบเพิ่มเติม ตัวอย่างเช่น ลูกศรประจะรวม
CityและRegionซึ่งแสดงว่าการขึ้นต่อกันเป็นเพียงการประมาณเท่านั้น ความสัมพันธ์โดยประมาณนี้อาจหมายความว่ามีการขึ้นต่อกันของฟังก์ชันบางส่วนcustomer_state_df.list_dependency_violations('City', 'Region')ดูแต่ละกรณีที่ค่าอคติ
Regionอย่างใกล้ชิดทําให้เกิดการละเมิด:customer_state_df[customer_state_df.City=='Downers Grove']ผลแสดงเมือง Downers Grove ที่เกิดขึ้นในรัฐอิลลินอยส์และเนแบรสกา อย่างไรก็ตาม Grove ของ Downer เป็นเมือง ในอิลลินอยส์ไม่ใช่ Nebraska
ลองดูเมือง เฟรมอนต์:
customer_state_df[customer_state_df.City=='Fremont']มีเมืองที่เรียกว่า เฟรมอนต์ ในแคลิฟอร์เนีย อย่างไรก็ตาม สําหรับ Texas โปรแกรมค้นหาส่งกลับ Premontไม่ใช่ Fremont
นอกจากนี้ยังน่าสงสัยว่าเห็นการละเมิดการขึ้นต่อกันระหว่าง
NameและCountry/Regionตามที่ระบุโดยเส้นประในกราฟต้นฉบับของการละเมิดการขึ้นต่อกัน (ก่อนที่จะทิ้งแถวที่มีค่าว่าง)customer_state_df.list_dependency_violations('Name', 'Country/Region')ซึ่งปรากฏว่าลูกค้ารายหนึ่ง ออกแบบ SDI มีอยู่ในสองภูมิภาค - สหรัฐอเมริกาและแคนาดา การเกิดขึ้นนี้อาจไม่ใช่การละเมิดความหมาย แต่อาจเป็นกรณีที่ไม่ธรรมดา ถึงกระนั้นก็คุ้มค่าที่จะมองอย่างใกล้ชิด:
ดูลูกค้า SDI Designอย่างใกล้ชิด :
customer_state_df[customer_state_df.Name=='SDI Design']การตรวจสอบเพิ่มเติมแสดงให้เห็นว่าเป็นลูกค้าสองรายที่แตกต่างกันจริง ๆ (จากอุตสาหกรรมที่แตกต่างกัน) ที่มีชื่อเดียวกัน

การวิเคราะห์ข้อมูลการสํารวจเป็นกระบวนการที่น่าตื่นเต้นและเป็นการทําความสะอาดข้อมูล มีบางสิ่งที่ข้อมูลกําลังซ่อนอยู่เสมอ โดยขึ้นอยู่กับลักษณะที่คุณดู สิ่งที่คุณต้องการถาม และอื่นๆ ลิงก์เชิงความหมายนําเสนอเครื่องมือใหม่ที่คุณสามารถใช้เพื่อให้บรรลุผลมากขึ้นด้วยข้อมูลของคุณ
เนื้อหาที่เกี่ยวข้อง
ดูบทช่วยสอนอื่น ๆ สําหรับลิงก์ความหมาย / SemPy:
- บทช่วยสอน : ล้างข้อมูลด้วยการขึ้นต่อกัน การทํางาน
- บทช่วยสอน : แยกและคํานวณหน่วยวัด Power BI จากสมุดบันทึก Jupyter
- บทช่วยสอน : ค้นหาความสัมพันธ์ในแบบจําลองความหมายโดยใช้ลิงก์เชิงความหมาย
- บทช่วยสอน
: ค้นหาความสัมพันธ์ในชุดข้อมูล Synthea โดยใช้ลิงก์ความหมาย - บทช่วยสอน : ตรวจสอบข้อมูลโดยใช้ SemPy และความคาดหวังที่ยิ่งใหญ่ (GX)