ใช้โมเดลของ Azure Machine Learning
ข้อมูลที่รวมเข้าด้วยกันใน Dynamics 365 Customer Insights- Data เป็นแหล่งที่มาสำหรับการสร้างโมเดลการเรียนรู้เกี่ยวกับเครื่องที่สามารถสร้างข้อมูลเชิงลึกทางธุรกิจเพิ่มเติม Customer Insights - Data ผสานรวมกับ Azure Machine Learning เพื่อใช้โมเดลที่คุณกำหนดเอง
ข้อกำหนดเบื้องต้น
- การเข้าถึง Customer Insights - Data
- การสมัครใช้งาน Azure Enterprise ที่ใช้งานอยู่
- โปรไฟล์ลูกค้าแบบรวม
- ตารางที่ส่งออกเอนทิตีไปยังที่เก็บข้อมูล Azure Blob ที่กำหนดค่า
ตั้งค่าพื้นที่ทำงานของ Azure Machine Learning
ดู สร้างพื้นที่ทำงานของ Azure Machine Learning สำหรับตัวเลือกต่างๆ ในการสร้างพื้นที่ทำงาน เพื่อประสิทธิภาพที่ดีที่สุด ให้สร้างพื้นที่ทำงานในภูมิภาค Azure ที่ตั้งอยู่ใกล้เคียงกับสภาพแวดล้อม Customer Insights ของคุณมากที่สุด
เข้าถึงพื้นที่ทำงานของคุณผ่าน Azure Machine Learning Studio วิธีการทำงาน กับพื้นที่ทำงานของคุณมีหลายวิธี
ทำงานกับตัวออกแบบ Azure Machine Learning
ตัวออกแบบ Azure Machine Learning มีพื้นที่ทำงานการแสดงผลด้วยภาพที่คุณสามารถลากและวางชุดข้อมูลและโมดูลต่างๆ ไปป์ไลน์ชุดงานที่สร้างจากตัวออกแบบสามารถรวมเข้ากับ Customer Insights - Data ได้หากมีการกำหนดค่าตามนั้น
การทำงานกับ Azure Machine Learning SDK
นักวิทยาศาสตร์ข้อมูลและนักพัฒนา AI ใช้ Azure Machine Learning SDK เพื่อสร้างเวิร์กโฟลว์การเรียนรู้เกี่ยวกับเครื่อง ขณะนี้ โมเดลที่ฝึกโดยใช้ SDK ไม่สามารถรวมเข้าได้โดยตรง ไปป์ไลน์การอนุมานแบบชุดงานที่ใช้โมเดลนั้นจำเป็นสำหรับการผสานรวมกับ Customer Insights - Data
ข้อกำหนดไปป์ไลน์แบบชุดงานที่จะรวมเข้ากับ Customer Insights - Data
การกำหนดค่าชุดข้อมูล
สร้างชุดข้อมูลเพื่อใช้ข้อมูลตารางจาก Customer Insights สำหรับไปป์ไลน์การอนุมานแบบชุดงานของคุณ ลงทะเบียนชุดข้อมูลเหล่านี้ในพื้นที่ทำงาน ขณะนี้เรารองรับ ชุดข้อมูลแบบตาราง ในรูปแบบ .csv เท่านั้น กำหนดพารามิเตอร์ชุดข้อมูลที่สอดคล้องกับข้อมูลตารางเป็นพารามิเตอร์ไปป์ไลน์
ชุดข้อมูลพารามิเตอร์ในตัวออกแบบ
ในตัวออกแบบ ให้เปิด เลือกคอลัมน์ในชุดข้อมูล และเลือก ตั้งเป็นพารามิเตอร์ไปป์ไลน์ ที่คุณระบุชื่อสำหรับพารามิเตอร์
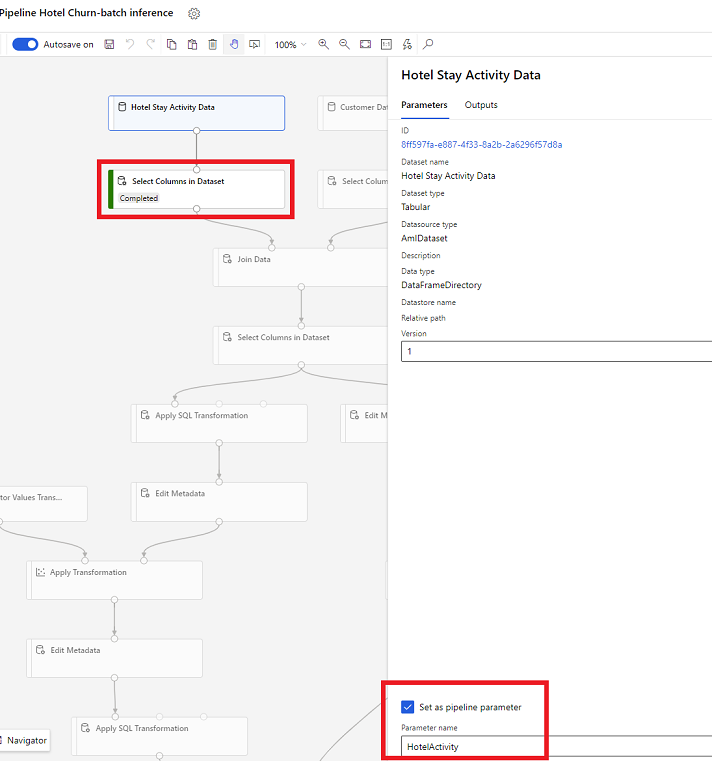
พารามิเตอร์ชุดข้อมูลใน SDK (Python)
HotelStayActivity_dataset = Dataset.get_by_name(ws, name='Hotel Stay Activity Data') HotelStayActivity_pipeline_param = PipelineParameter(name="HotelStayActivity_pipeline_param", default_value=HotelStayActivity_dataset) HotelStayActivity_ds_consumption = DatasetConsumptionConfig("HotelStayActivity_dataset", HotelStayActivity_pipeline_param)
ไปป์ไลน์การอนุมานแบบชุดงาน
ในตัวออกแบบ ใช้ไปป์ไลน์การฝึกเพื่อสร้างหรือปรับปรุงไปป์ไลน์การอนุมานได้ ขณะนี้รองรับเฉพาะไปป์ไลน์การอนุมานแบบชุดงานเท่านั้น
เมื่อใช้ SDK เผยแพร่ไปป์ไลน์ไปยังจุดสิ้นสุดได้ ปัจจุบัน Customer Insights - Data รวมเข้ากับไปป์ไลน์เริ่มต้นในจุดสิ้นสุดไปป์ไลน์แบบชุดงานในพื้นที่ทำงาน Machine Learning
published_pipeline = pipeline.publish(name="ChurnInferencePipeline", description="Published Churn Inference pipeline") pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name="ChurnPipelineEndpoint") pipeline_endpoint.add_default(pipeline=published_pipeline)
นำเข้าข้อมูลไปป์ไลน์
ผู้ออกแบบมี โมดูลส่งออกข้อมูล ที่อนุญาตให้ส่งออกผลลัพธ์ของไปป์ไลน์ไปยังที่เก็บข้อมูล Azure ปัจจุบัน โมดูลดังกล่าวต้องใช้ที่เก็บข้อมูลชนิด ที่เก็บข้อมูล Azure Blob และกำหนดพารามิเตอร์ ที่เก็บข้อมูล และ พาธ แบบสัมพันธ์ ระบบจะแทนที่พารามิเตอร์ทั้งคู่นี้ในระหว่างการดำเนินการไปป์ไลน์กับที่เก็บข้อมูลและพาธที่สามารถเข้าถึงไปยังแอปพลิเคชัน
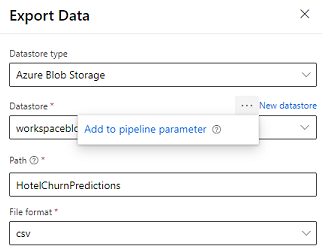
เมื่อเขียนผลลัพธ์การอนุมานโดยใช้โค้ด อัปโหลดผลลัพธ์ไปยังพาธภายใน ที่เก็บข้อมูลที่ลงทะเบียน ในพื้นที่ทำงาน หากพาธและที่เก็บข้อมูลมีการกำหนดพารามิเตอร์ในไปป์ไลน์ Customer Insights สามารถอ่านและนำเข้าเอาต์พุตการอนุมานได้ ปัจจุบันรองรับผลลัพธ์แบบตารางเดียวในรูปแบบ csv เท่านั้น พาธต้องมีไดเรกทอรีและชื่อไฟล์
# In Pipeline setup script OutputPathParameter = PipelineParameter(name="output_path", default_value="HotelChurnOutput/HotelChurnOutput.csv") OutputDatastoreParameter = PipelineParameter(name="output_datastore", default_value="workspaceblobstore") ... # In pipeline execution script run = Run.get_context() ws = run.experiment.workspace datastore = Datastore.get(ws, output_datastore) # output_datastore is parameterized directory_name = os.path.dirname(output_path) # output_path is parameterized. # Datastore.upload() or Dataset.File.upload_directory() are supported methods to uplaod the data # datastore.upload(src_dir=<<working directory>>, target_path=directory_name, overwrite=False, show_progress=True) output_dataset = Dataset.File.upload_directory(src_dir=<<working directory>>, target = (datastore, directory_name)) # Remove trailing "/" from directory_name