How customer-managed planned failover (preview) works
Customer managed planned failover can be useful in scenarios such as disaster and recovery planning and testing, proactive remediation of anticipated large-scale disasters, and nonstorage related outages.
During the planned failover process, your storage account's primary and secondary regions are swapped. The original primary region is demoted and becomes the new secondary while the original secondary region is promoted and becomes the new primary. The storage account must be available in both the primary and secondary regions before a planned failover can be initiated.
This article describes what happens during a customer-managed planned failover and failback at every stage of the process. To understand how a failover due to an unexpected storage endpoint outage works, see How customer-managed (unplanned) failover.
Important
Customer-managed planned failover is currently in PREVIEW and limited to the following regions:
- France Central
- France South
- India Central
- India West
- East Asia
- Southeast Asia
See the Supplemental Terms of Use for Microsoft Azure Previews for legal terms that apply to Azure features that are in beta, preview, or otherwise not yet released into general availability.
To opt in to the preview, see Set up preview features in Azure subscription and specify AllowSoftFailover as the feature name. The provider name for this preview feature is Microsoft.Storage.
Important
After a planned failover, a storage account's Last Sync Time (LST) value might appear stale or be reported as NULL when Azure Files data is present.
System snapshots are periodically created in a storage account's secondary region to maintain consistent recovery points used during failover and failback. Initiating customer-managed planned failover causes the original primary region to become the new secondary. In some cases, there are no system snapshots available on the new secondary after the planned failover completes, causing the account's overall LST value to appear stale or be displayed as Null.
Because user activities such as creating, modifying, or deleting objects can trigger snapshot creation, any account on which these activities occur after planned failover will not require additional attention. However, accounts having no snapshots or user activity may continue to display a Null LST value until system snapshot creation is triggered.
If necessary, perform one of the following activities for each share within a storage account to trigger snapshot creation. Upon completion, your account should display a valid LST value within 30 minutes' time.
- Mount the share, then open any file for reading.
- Upload a test or sample file to the share.
Redundancy management during planned failover and failback
Tip
To understand the varying redundancy states during customer-managed failover and failback process in detail, see Azure Storage redundancy for definitions of each.
During the planned failover process, the primary region's storage service endpoints become read-only while remaining updates finish replicating to the secondary region. Next, all storage service endpoint's domain name service (DNS) entries are switched. Your storage account's secondary endpoints become the new primary endpoints, and the original primary endpoints become the new secondary. Data replication within each region remains unchanged even though the primary and secondary regions are switched.
The planned failback process is essentially the same as the planned failover process, but with one exception. During planned failback, Azure stores the original redundancy configuration of your storage account and restores it to its original state upon failback. For example, if your storage account was originally configured as GZRS, the storage account will be GZRS after failback.
Note
Unlike customer-managed (unplanned) failover, during planned failover, replication from the primary to secondary region must be complete before the DNS entries for the endpoints are changed to the new secondary. Because of this, data loss is not expected during planned failover or failback as long as both the primary and secondary regions are available throughout the process.
How to initiate a failover
To learn how to initiate a failover, see Initiate an account failover.
The planned failover and failback process
The following diagrams show what happens during a customer-managed planned failover and failback of a storage account.
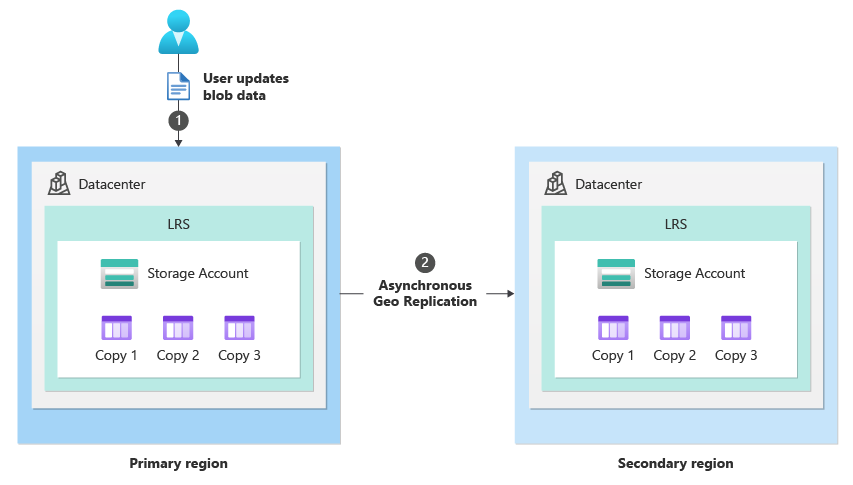
Under normal circumstances, a client writes data to a storage account in the primary region via storage service endpoints (1). The data is then copied asynchronously from the primary region to the secondary region (2). The following image shows the normal state of a storage account configured as GRS:

The planned failover process (GRS/RA-GRS)
Begin disaster recovery testing by initiating a failover of your storage account to the secondary region. The following steps describe the failover process, and the subsequent image provides illustration:
- The original primary region becomes read only.
- Replication of all data from the primary region to the secondary region completes.
- DNS entries for storage service endpoints in the secondary region are promoted and become the new primary endpoints for your storage account.
The failover typically takes about an hour.

After the failover is complete, the original primary region becomes the new secondary (1), and the original secondary region becomes the new primary (2). The URIs for the storage service endpoints for blobs, tables, queues, and files remain the same, but their DNS entries are changed to point to the new primary region (3). Users can resume writing data to the storage account in the new primary region, and the data is then copied asynchronously to the new secondary (4) as shown in the following image:

While in the failover state, perform your disaster recovery testing.
The planned failback process (GRS/RA-GRS)
After testing is complete, perform another failover to failback to the original primary region. During the failover process, as shown in the following image:
- The original primary region becomes read only.
- All data finishes replicating from the current primary region to the current secondary region.
- The DNS entries for the storage service endpoints are changed to point back to the region that was the primary before the initial failover was performed.
The failback typically takes about an hour.

After the failback is complete, the storage account is restored to its original redundancy configuration. Users can resume writing data to the storage account in the original primary region (1) while replication to the original secondary (2) continues as before the failover: