Upload training and testing datasets for custom speech
You need audio or text data for testing the accuracy of speech recognition or training your custom models. For information about the data types supported for testing or training your model, see Training and testing datasets.
Tip
You can also use the online transcription editor to create and refine labeled audio datasets.
Upload datasets
Sign in to the Azure AI Foundry portal.
Select Fine-tuning from the left pane.
Select AI Service fine-tuning.
Select the custom model that you want to manage from the Model name column.
Select Manage data and then select Add data.
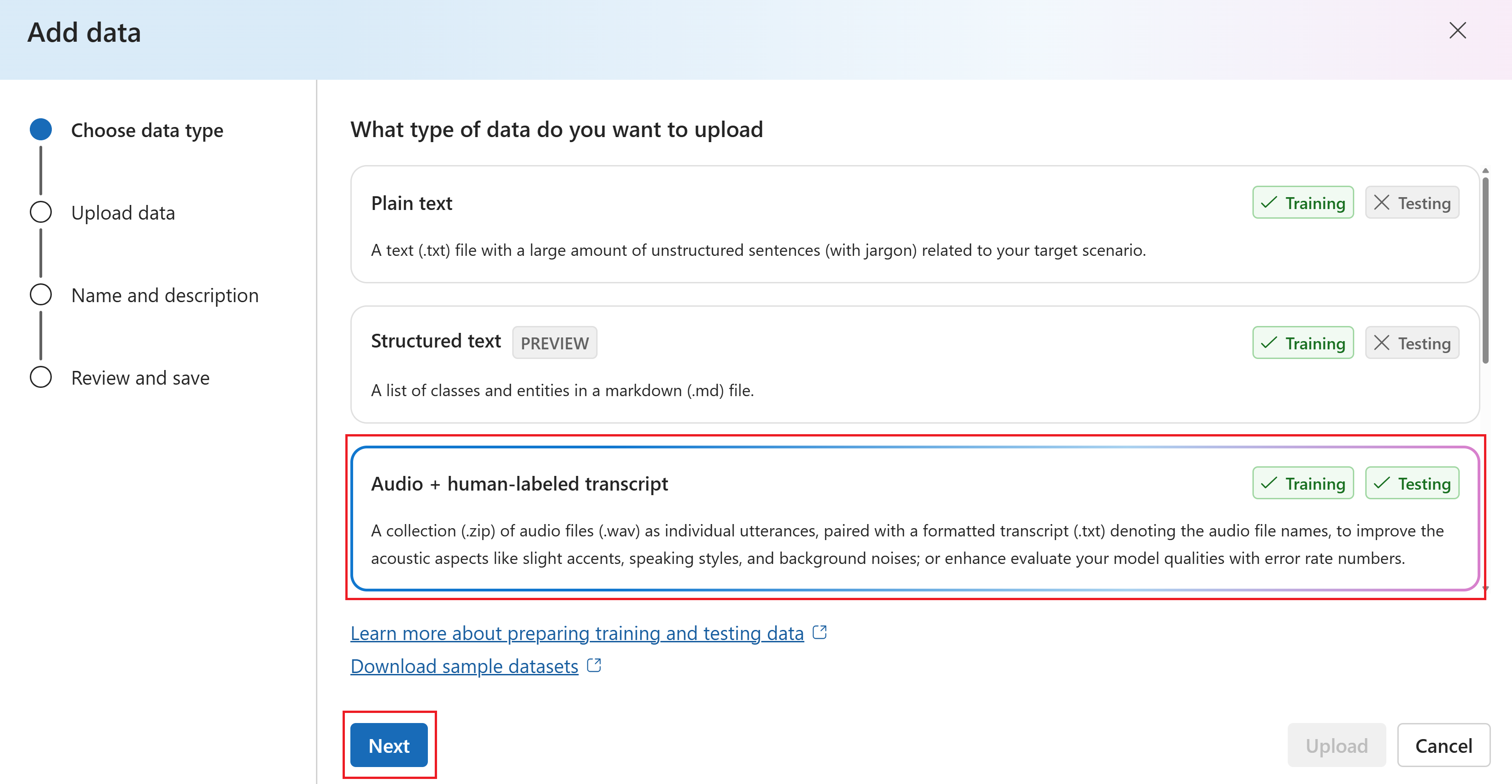
In the Add data wizard, select the type of training data you want to add. In this example, we select Audio + human-labeled transcript. Then select Next.
On the Upload your data page, select local files, Azure Blob Storage, or other shared web locations. Then select Next.
If you select a remote location and you don't use trusted Azure services security mechanism, then the remote location should be a URL that can be retrieved with a simple anonymous GET request. For example, a SAS URL or a publicly accessible URL. URLs that require extra authorization or expect user interaction aren't supported.
Note
If you use Azure Blob URL, you can ensure maximum security of your dataset files by using trusted Azure services security mechanism. You will use the same techniques as for Batch transcription and plain Storage Account URLs for your dataset files. See details here.
Enter a name and description for the data. Then select Next.
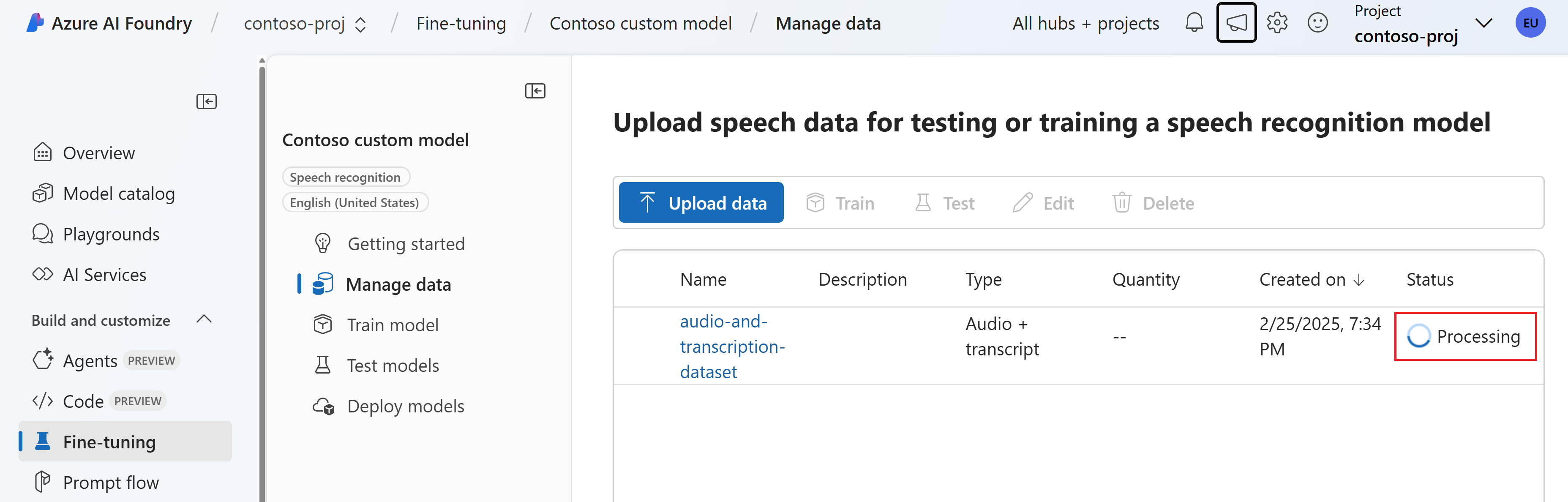
Review the data and select Upload. You're taken back to the Manage data page. The status of the data is Processing.



To upload your own datasets in Speech Studio, follow these steps:
Sign in to the Speech Studio.
Select Custom speech > Your project name > Speech datasets > Upload data.
Select the Training data or Testing data tab.
Select a dataset type, and then select Next.
Specify the dataset location, and then select Next. You can choose a local file or enter a remote location such as Azure Blob URL. If you select a remote location and you don't use trusted Azure services security mechanism, then the remote location should be a URL that can be retrieved with a simple anonymous GET request. For example, a SAS URL or a publicly accessible URL. URLs that require extra authorization or expect user interaction aren't supported.
Note
If you use Azure Blob URL, you can ensure maximum security of your dataset files by using trusted Azure services security mechanism. You will use the same techniques as for Batch transcription and plain Storage Account URLs for your dataset files. See details here.
Enter the dataset name and description, and then select Next.
Review your settings, and then select Save and close.
After your dataset is uploaded, go to the Train custom models page to train a custom model.
With the Speech CLI and Speech to text REST API, unlike the Azure AI Foundry portal and Speech Studio, you don't choose whether a dataset is for testing or training at the time of upload. You specify how a dataset is used when you train a model or run a test.
Although you don't indicate whether the dataset is for testing or training, you must specify the dataset kind. The dataset kind is used to determine which type of dataset is created. In some cases, a dataset kind is only used for testing or training, but you shouldn't take a dependency on that. The Speech CLI and REST API kind values correspond to the options in the Azure AI Foundry portal and Speech Studio as described in the following table:
| CLI and API kind | Portal options |
|---|---|
| Acoustic | Training data: Audio + human-labeled transcript Testing data: Transcript (automatic audio synthesis) Testing data: Audio + human-labeled transcript |
| AudioFiles | Testing data: Audio |
| Language | Training data: Plain text |
| LanguageMarkdown | Training data: Structured text in markdown format |
| Pronunciation | Training data: Pronunciation |
| OutputFormatting | Training data: Output format |
Important
You don't use the Speech CLI or REST API to upload data files directly. First you store the training or testing dataset files at a URL that the Speech CLI or REST API can access. After you upload the data files, you can use the Speech CLI or REST API to create a dataset for custom speech testing or training.
To create a dataset and connect it to an existing project, use the spx csr dataset create command. Construct the request parameters according to the following instructions:
Set the
projectproperty to the ID of an existing project. This parameter is recommended so that you can also view and manage the dataset in the Azure AI Foundry portal. You can run thespx csr project listcommand to get available projects.Set the required
kindproperty. The possible set of values for a training dataset kind are: Acoustic, AudioFiles, Language, LanguageMarkdown, and Pronunciation.Set the required
contentUrlproperty. This parameter is the location of the dataset. If you don't use trusted Azure services security mechanism (see next Note), then thecontentUrlproperty should be a URL that can be retrieved with a simple anonymous GET request. For example, a SAS URL or a publicly accessible URL. URLs that require extra authorization, or expect user interaction aren't supported.Note
If you use Azure Blob URL, you can ensure maximum security of your dataset files by using trusted Azure services security mechanism. You will use the same techniques as for Batch transcription and plain Storage Account URLs for your dataset files. See details here.
Set the required
languageproperty. The dataset locale must match the locale of the project. The locale can't be changed later. The Speech CLIlanguageproperty corresponds to thelocaleproperty in the JSON request and response.Set the required
nameproperty. This parameter is the name that is displayed in the Azure AI Foundry portal. The Speech CLInameproperty corresponds to thedisplayNameproperty in the JSON request and response.
Here's an example Speech CLI command that creates a dataset and connects it to an existing project:
spx csr dataset create --api-version v3.2 --kind "Acoustic" --name "My Acoustic Dataset" --description "My Acoustic Dataset Description" --project YourProjectId --content YourContentUrl --language "en-US"
You should receive a response body in the following format:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23",
"kind": "Acoustic",
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"textNormalizationKind": "Default",
"acceptedLineCount": 2,
"rejectedLineCount": 0,
"duration": "PT59S"
},
"lastActionDateTime": "2024-07-14T17:36:30Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T17:36:14Z",
"locale": "en-US",
"displayName": "My Acoustic Dataset",
"description": "My Acoustic Dataset Description",
"customProperties": {
"PortalAPIVersion": "3"
}
}
The top-level self property in the response body is the dataset's URI. Use this URI to get details about the dataset's project and files. You also use this URI to update or delete a dataset.
For Speech CLI help with datasets, run the following command:
spx help csr dataset
With the Speech CLI and Speech to text REST API, unlike the Azure AI Foundry portal and Speech Studio, you don't choose whether a dataset is for testing or training at the time of upload. You specify how a dataset is used when you train a model or run a test.
Although you don't indicate whether the dataset is for testing or training, you must specify the dataset kind. The dataset kind is used to determine which type of dataset is created. In some cases, a dataset kind is only used for testing or training, but you shouldn't take a dependency on that. The Speech CLI and REST API kind values correspond to the options in the Azure AI Foundry portal and Speech Studio as described in the following table:
| CLI and API kind | Portal options |
|---|---|
| Acoustic | Training data: Audio + human-labeled transcript Testing data: Transcript (automatic audio synthesis) Testing data: Audio + human-labeled transcript |
| AudioFiles | Testing data: Audio |
| Language | Training data: Plain text |
| LanguageMarkdown | Training data: Structured text in markdown format |
| Pronunciation | Training data: Pronunciation |
| OutputFormatting | Training data: Output format |
Important
You don't use the Speech CLI or REST API to upload data files directly. First you store the training or testing dataset files at a URL that the Speech CLI or REST API can access. After you upload the data files, you can use the Speech CLI or REST API to create a dataset for custom speech testing or training.
To create a dataset and connect it to an existing project, use the Datasets_Create operation of the Speech to text REST API. Construct the request body according to the following instructions:
Set the
projectproperty to the URI of an existing project. This property is recommended so that you can also view and manage the dataset in the Azure AI Foundry portal. You can make a Projects_List request to get available projects.Set the required
kindproperty. The possible set of values for a training dataset kind are: Acoustic, AudioFiles, Language, LanguageMarkdown, and Pronunciation.Set the required
contentUrlproperty. This property is the location of the dataset. If you don't use trusted Azure services security mechanism (see next Note), then thecontentUrlproperty should be a URL that can be retrieved with a simple anonymous GET request. For example, a SAS URL or a publicly accessible URL. URLs that require extra authorization, or expect user interaction aren't supported.Note
If you use Azure Blob URL, you can ensure maximum security of your dataset files by using trusted Azure services security mechanism. You will use the same techniques as for Batch transcription and plain Storage Account URLs for your dataset files. See details here.
Set the required
localeproperty. The dataset locale must match the locale of the project. The locale can't be changed later.Set the required
displayNameproperty. This property is the name that is displayed in the Azure AI Foundry portal.
Make an HTTP POST request using the URI as shown in the following example. Replace YourSubscriptionKey with your Speech resource key, replace YourServiceRegion with your Speech resource region, and set the request body properties as previously described.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"kind": "Acoustic",
"displayName": "My Acoustic Dataset",
"description": "My Acoustic Dataset Description",
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"contentUrl": "https://contoso.com/mydatasetlocation",
"locale": "en-US",
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/datasets"
You should receive a response body in the following format:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23",
"kind": "Acoustic",
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"textNormalizationKind": "Default",
"acceptedLineCount": 2,
"rejectedLineCount": 0,
"duration": "PT59S"
},
"lastActionDateTime": "2024-07-14T17:36:30Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T17:36:14Z",
"locale": "en-US",
"displayName": "My Acoustic Dataset",
"description": "My Acoustic Dataset Description",
"customProperties": {
"PortalAPIVersion": "3"
}
}
The top-level self property in the response body is the dataset's URI. Use this URI to get details about the dataset's project and files. You also use this URI to update or delete the dataset.
Important
Connecting a dataset to a custom speech project isn't required to train and test a custom model using the REST API or Speech CLI. But if the dataset is not connected to any project, you can't select it for training or testing in the Azure AI Foundry portal.