Felsöka långsamma frågor som påverkas av tidsgränsen för frågeoptimeraren
Gäller för: SQL Server
Den här artikeln beskriver Timeout för Optimerare, hur det kan påverka frågeprestanda och hur du optimerar prestandan.
Vad är Timeout för Optimizer?
SQL Server använder en kostnadsbaserad frågeoptimerare (QO). Mer information om QO finns i Arkitekturguide för frågebearbetning. En kostnadsbaserad frågeoptimerare väljer en frågekörningsplan med den lägsta kostnaden när den har skapat och utvärderat flera frågeplaner. Ett av målen med SQL Server Query Optimizer är att ägna en rimlig tid åt frågeoptimering jämfört med frågekörning. Det bör gå mycket snabbare att optimera en fråga än att köra den. För att uppnå det här målet har QO ett inbyggt tröskelvärde för uppgifter att överväga innan optimeringsprocessen stoppas. När tröskelvärdet nås innan QO har övervägt alla möjliga planer når det tidsgränsen för optimeraren. En Optimizer Timeout-händelse rapporteras i frågeplanen som TimeOut under Orsak till tidig avslutning av instruktionsoptimering. Det är viktigt att förstå att det här tröskelvärdet inte baseras på klocktid utan på antalet möjligheter som optimeraren tar hänsyn till. I aktuella QO-versioner för SQL Server övervägs över en halv miljon aktiviteter innan en tidsgräns nås.
Timeouten optimizer är utformad för SQL Server, och i många fall är det inte en faktor som påverkar frågeprestanda. I vissa fall kan dock valet av SQL-frågeplan påverkas negativt av tidsgränsen för optimeraren och långsammare frågeprestanda kan resultera. När du stöter på sådana problem kan det hjälpa dig att felsöka och förbättra frågehastigheten genom att förstå mekanismen för timeout för Optimerare och hur komplexa frågor kan påverkas.
Resultatet av att uppnå tröskelvärdet för optimerarens tidsgräns är att SQL Server inte har övervägt hela uppsättningen optimeringsmöjligheter. Det kan alltså ha missat planer som kan ge kortare körningstider. QO stannar vid tröskelvärdet och överväger den lägsta kostnadsfrågeplanen vid den tidpunkten, även om det kan finnas bättre, outforskade alternativ. Tänk på att den plan som valts efter att tidsgränsen för optimeraren har uppnåtts kan ge en rimlig körningstid för frågan. I vissa fall kan den valda planen dock resultera i en frågekörning som är suboptimal.
Så här identifierar du en timeout för optimeraren?
Här är symtom som indikerar en timeout för optimizer:
Komplex fråga
Du har en komplex fråga som omfattar många anslutna tabeller (till exempel är åtta eller fler tabeller anslutna).
Långsam fråga
Frågan kan köras långsamt eller långsammare än den körs på en annan SQL Server-version eller ett annat system.
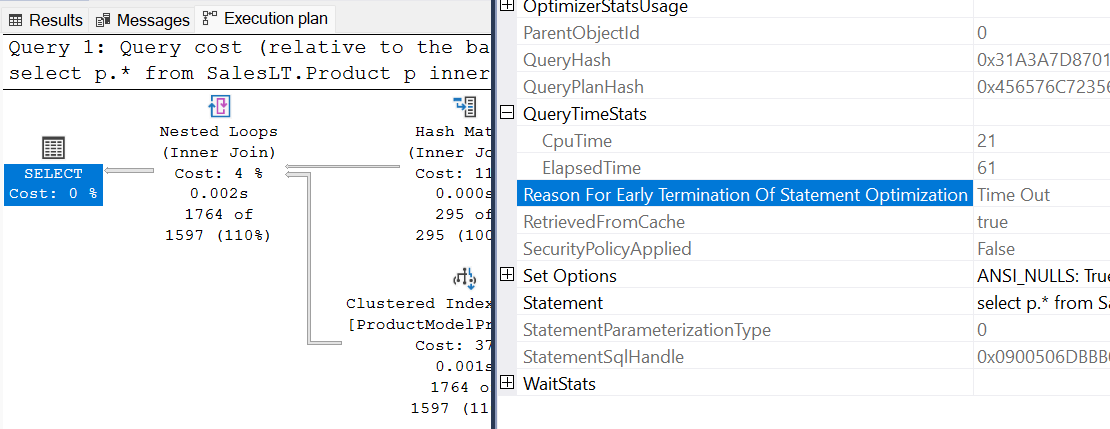
Frågeplan visar StatementOptmEarlyAbortReason=Timeout
Frågeplanen visas
StatementOptmEarlyAbortReason="TimeOut"i XML-frågeplanen.<?xml version="1.0" encoding="utf-16"?> <ShowPlanXML xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" Version="1.518" Build="13.0.5201.2" xmlns="http://schemas.microsoft.com/sqlserver/2004/07/showplan"> <BatchSequence> <Batch> <Statements> <StmtSimple ..." StatementOptmLevel="FULL" StatementOptmEarlyAbortReason="TimeOut" ......> ... <Statements> <Batch> <BatchSequence>Kontrollera egenskaperna för den vänstra abonnemangsoperatorn i Microsoft SQL Server Management Studio. Du kan se värdet för Orsak för tidig avslutning av instruktionsoptimering är TimeOut.
Vad orsakar en timeout för optimizer?
Det finns inget enkelt sätt att avgöra vilka villkor som skulle leda till att tröskelvärdet för optimeraren nås eller överskrids. Följande avsnitt är några faktorer som påverkar hur många planer som utforskas av QO när du letar efter den bästa planen.
I vilken ordning ska tabeller kopplas?
Här är ett exempel på körningsalternativen för tretabellskopplingar (
Table1, ,Table2Table3):- Anslut med
Table1Table2och resultatet medTable3 - Anslut med
Table1Table3och resultatet medTable2 - Anslut med
Table2Table3och resultatet medTable1
Obs! Ju större antalet tabeller är, desto större är möjligheterna.
- Anslut med
Vilken heap- eller binär trädåtkomststruktur (HoBT) som ska användas för att hämta raderna från en tabell?
- Grupperat index
- Icke-grupperat index1
- Icke-grupperat index2
- Tabellhög
Vilken fysisk åtkomstmetod ska användas?
- Indexsökning
- Indexgenomsökning
- Tabellgenomsökning
Vilken fysisk kopplingsoperator ska använda?
- Kapslad loopkoppling (NJ)
- Hash-anslutning (HJ)
- Sammanfoga koppling (MJ)
- Anpassningsbar koppling (från och med SQL Server 2017 (14.x))
Mer information finns i Kopplingar.
Kör du delar av frågan parallellt eller seriellt?
Mer information finns i Parallell frågebearbetning.
Medan följande faktorer kommer att minska antalet metoder för åtkomst som beaktas och därmed de möjligheter som beaktas:
- Frågepredikat (filter i
WHERE-satsen) - Förekomster av begränsningar
- Kombinationer av väldesignad och uppdaterad statistik
Obs! Det faktum att QO når tröskelvärdet innebär inte att det kommer att få en långsammare fråga. I de flesta fall fungerar frågan bra, men i vissa fall kan du se en långsammare frågekörning.
Exempel på hur faktorerna beaktas
För att illustrera ska vi ta ett exempel på en koppling mellan tre tabeller (t1, t2, och t3) och varje tabell har ett grupperat index och ett icke-grupperat index.
Överväg först de fysiska kopplingstyperna. Det finns två kopplingar här. Och eftersom det finns tre fysiska kopplingsmöjligheter (NJ, HJ och MJ) kan frågan utföras på 32 = 9 sätt.
- NJ – NJ
- NJ – HJ
- NJ – MJ
- HJ – NJ
- HJ – HJ
- HJ – MJ
- MJ – NJ
- MJ – HJ
- MJ – MJ
Tänk sedan på kopplingsordningen, som beräknas med hjälp av permutationer: P (n, r). Ordningen på de två första tabellerna spelar ingen roll, så det kan finnas P(3,1) = 3 möjligheter:
- Anslut med
t1t2och sedan medt3 - Anslut med
t1t3och sedan medt2 - Anslut med
t2t3och sedan medt1
Tänk sedan på de klustrade och icke-grupperade index som kan användas för datahämtning. För varje index har vi dessutom två åtkomstmetoder, sök eller genomsöka. Det innebär att för varje tabell finns det 22 = 4 alternativ. Vi har tre tabeller, så det kan finnas 43 = 64 alternativ.
Slutligen, med tanke på alla dessa villkor, kan det finnas 9 * 3 * 64 = 1728 möjliga planer.
Anta nu att det finns n tabeller som är kopplade till frågan och att varje tabell har ett grupperat index och ett icke-grupperat index. Överväg följande faktorer:
- Kopplingsbeställningar: P(n,n-2) = n!/2
- Kopplingstyper: 3n-1
- Olika indextyper med sök- och genomsökningsmetoder: 4n
Multiplicera alla dessa ovan så kan vi få antalet möjliga planer: 2*n!*12n-1. När n = 4 är talet 82 944. När n = 6 är talet 358 318 080. Så med ökningen av antalet tabeller som ingår i en fråga ökar antalet möjliga planer geometriskt. Om du inkluderar möjligheten till parallellitet och andra faktorer kan du dessutom föreställa dig hur många möjliga planer som kommer att övervägas. Därför är det mer troligt att en fråga med många kopplingar når tröskelvärdet för optimeringstimeout än en med färre kopplingar.
Observera att ovanstående beräkningar illustrerar det värsta scenariot. Som vi har påpekat finns det faktorer som minskar antalet möjligheter, till exempel filterpredikat, statistik och begränsningar. Till exempel minskar ett filterpredikat och uppdaterad statistik antalet fysiska åtkomstmetoder eftersom det kan vara effektivare att använda en indexsökning än en genomsökning. Detta leder också till ett mindre urval av kopplingar och så vidare.
Varför visas en timeout för optimeraren med en enkel fråga?
Ingenting med Query Optimizer är enkelt. Det finns många möjliga scenarier och graden av komplexitet är så hög att det är svårt att förstå alla möjligheter. Frågeoptimeraren kan dynamiskt ange tröskelvärdet för tidsgränsen baserat på kostnaden för planen som hittades i ett visst skede. Om till exempel en plan som verkar relativt effektiv hittas kan uppgiftsgränsen för att söka efter en bättre plan minskas. Därför kan underskattad kardinalitetsuppskattning (CE) vara ett scenario för att få en optimizer-timeout tidigt. I det här fallet är fokus för undersökningen CE. Det är ett ovanligare fall jämfört med scenariot om att köra en komplex fråga som beskrivs i föregående avsnitt, men det är möjligt.
Lösningar
En timeout för optimerare som visas i en frågeplan betyder inte nödvändigtvis att det är orsaken till den dåliga frågeprestandan. I de flesta fall kanske du inte behöver göra något åt den här situationen. Frågeplanen som SQL Server slutar med kan vara rimlig och frågan du kör kan fungera bra. Du kanske aldrig vet att du har stött på en timeout för Optimizer.
Prova följande steg om du upptäcker behovet av att finjustera och optimera.
Steg 1: Upprätta en baslinje
Kontrollera om du kan köra samma fråga med samma datauppsättning på en annan version av SQL Server, med en annan CE-konfiguration eller på ett annat system (maskinvaruspecifikationer). En vägledande princip i prestandajustering är "det finns inga prestandaproblem utan baslinje". Därför är det viktigt att upprätta en baslinje för samma fråga.
Steg 2: Leta efter "dolda" villkor som leder till tidsgränsen för Optimizer
Granska frågan i detalj för att fastställa dess komplexitet. Vid den inledande undersökningen kanske det inte är uppenbart att frågan är komplex och omfattar många kopplingar. Ett vanligt scenario här är att vyer eller tabellvärdesfunktioner ingår. På ytan kan frågan till exempel verka enkel eftersom den kopplar ihop två vyer. Men när du undersöker frågorna i vyerna kan det hända att varje vy ansluter till sju tabeller. När de två vyerna är anslutna får du därför en 14-tabellkoppling. Om frågan använder följande objekt kan du öka detaljnivån i varje objekt för att se hur de underliggande frågorna i den ser ut:
- Vyer
- Tabellvärdesfunktioner (TFV:er)
- Underfrågor eller härledda tabeller
- Vanliga tabelluttryck (CTE)
- UNION-operatörer
För alla dessa scenarier är den vanligaste lösningen att skriva om frågan och dela upp den i flera frågor. Mer information finns i Steg 7: Förfina frågan .
Underfrågor eller härledda tabeller
Följande fråga är ett exempel som kopplar ihop två separata uppsättningar frågor (härledda tabeller) med 4–5 kopplingar i var och en. Men efter parsning av SQL Server kompileras den till en enda fråga med åtta tabeller anslutna.
SELECT ...
FROM
( SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
) AS derived_table1
INNER JOIN
( SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
) AS derived_table2
ON derived_table1.Co1 = derived_table2.Co10
AND derived_table1.Co2 = derived_table2.Co20
Vanliga tabelluttryck (CTE)
Att använda flera vanliga tabelluttryck (CTE) är inte en lämplig lösning för att förenkla en fråga och undvika timeout för Optimizer. Flera CTE:er ökar bara frågans komplexitet. Därför är det kontraproduktivt att använda CTE:er när du löser timeouter för optimerare. CtEs ser ut att bryta en fråga logiskt, men de kombineras till en enda fråga och optimeras som en enda stor koppling av tabeller.
Här är ett exempel på en CTE som kompileras som en enda fråga med många kopplingar. Det kan verka som om frågan mot my_cte är en enkel koppling med två objekt, men det finns faktiskt sju andra tabeller som är anslutna i CTE.
WITH my_cte AS (
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
WHERE ... )
SELECT ...
FROM my_cte
JOIN t8 ON ...
Vyer
Kontrollera att du har kontrollerat vydefinitionerna och tagit med alla tabeller. På samma sätt som CTE:er och härledda tabeller kan kopplingar döljas i vyer. Till exempel kan en koppling mellan två vyer i slutändan vara en enda fråga med åtta tabeller inblandade:
CREATE VIEW V1 AS
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
GO
CREATE VIEW V2 AS
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
GO
SELECT ...
FROM V1
JOIN V2 ON ...
Tabellvärdesfunktioner (TVF:er)
Vissa kopplingar kan vara dolda i TFV:er. Följande exempel visar vad som visas som en koppling mellan två TFV:er och en tabell kan vara en niotabellskoppling.
CREATE FUNCTION tvf1() RETURNS TABLE
AS RETURN
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
GO
CREATE FUNCTION tvf2() RETURNS TABLE
AS RETURN
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
GO
SELECT ...
FROM tvf1()
JOIN tvf2() ON ...
JOIN t9 ON ...
Union
Union-operatorer kombinerar resultatet av flera frågor till en enda resultatuppsättning. De kombinerar också flera frågor i en enda fråga. Sedan kan du få en enda, komplex fråga. I följande exempel får du en enda frågeplan som omfattar 12 tabeller.
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
UNION ALL
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
UNION ALL
SELECT ...
FROM t9
JOIN t10 ON ...
JOIN t11 ON ...
JOIN t12 ON ...
Steg 3: Om du har en baslinjefråga som körs snabbare använder du dess frågeplan
Om du bedömer att en viss baslinjeplan som du får från steg 1 är bättre för din fråga via testning använder du något av följande alternativ för att tvinga QO att välja den planen:
Steg 4: Alternativ för att minska abonnemang
Om du vill minska risken för en timeout för optimerare kan du försöka minska de möjligheter som QO behöver tänka på när du väljer en plan. Den här processen omfattar testning av frågan med olika tipsalternativ. Precis som med de flesta beslut med QO är valen inte alltid deterministiska på ytan eftersom det finns en mängd olika faktorer att ta hänsyn till. Därför finns det ingen enda garanterad lyckad strategi och den valda planen kan förbättra eller minska prestandan för den valda frågan.
Framtvinga en JOIN-order
Använd OPTION (FORCE ORDER) för att eliminera ordningens permutationer:
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
OPTION (FORCE ORDER)
Minska JOIN-möjligheterna
Om andra alternativ inte har hjälpt kan du försöka minska kombinationerna av frågeplan genom att begränsa valet av fysiska kopplingsoperatorer med kopplingstips. Till exempel: OPTION (HASH JOIN, MERGE JOIN), OPTION (HASH JOIN, LOOP JOIN) eller OPTION (MERGE JOIN).
Obs! Du bör vara försiktig när du använder dessa tips.
I vissa fall kan en begränsning av optimeraren med färre kopplingsalternativ göra att det bästa kopplingsalternativet inte är tillgängligt och faktiskt kan göra frågan långsammare. I vissa fall krävs också en specifik koppling av en optimerare (till exempel radmål) och frågan kan misslyckas med att generera en plan om anslutningen inte är ett alternativ. När du har riktat in dig på kopplingstipsen för en specifik fråga kontrollerar du därför om du hittar en kombination som ger bättre prestanda och eliminerar tidsgränsen för Optimizer.
Här är två exempel på hur du använder sådana tips:
Använd
OPTION (HASH JOIN, LOOP JOIN)för att endast tillåta hash- och loopkopplingar och undvika sammanslagningskoppling i frågan:SELECT ... FROM t1 JOIN t2 ON ... JOIN t3 ON ... JOIN t4 ON ... JOIN t5 ON ... OPTION (HASH JOIN, LOOP JOIN)Framtvinga en specifik koppling mellan två tabeller:
SELECT ... FROM t1 INNER MERGE JOIN t2 ON ... JOIN t3 ON ... JOIN t4 ON ... JOIN t5 ON ...
Steg 5: Ändra CE-konfiguration
Försök att ändra CE-konfigurationen genom att växla mellan äldre CE och ny CE. Om du ändrar CE-konfigurationen kan QO välja en annan sökväg när SQL Server utvärderar och skapar frågeplaner. Så även om det uppstår ett timeout-problem för optimeraren är det möjligt att du får en plan som presterar mer optimalt än den som valts med hjälp av den alternativa CE-konfigurationen. Mer information finns i Så här aktiverar du den bästa frågeplanen (kardinalitetsuppskattning).
Steg 6: Aktivera optimizerkorrigeringar
Om du inte har aktiverat frågeoptimerarkorrigeringar kan du överväga att aktivera dem med någon av följande två metoder:
- Servernivå: använd spårningsflaggaN T4199.
- Databasnivå: Använd
ALTER DATABASE SCOPED CONFIGURATION ..QUERY_OPTIMIZER_HOTFIXES = ONeller ändra databaskompatibilitetsnivåer för SQL Server 2016 och senare versioner.
QO-korrigeringarna kan leda till att optimeraren tar en annan väg i planutforskningen. Därför kan den välja en mer optimal frågeplan. Mer information finns i SQL Server query optimizer hotfix trace flag 4199 servicing model (Sql Server query optimizer hotfix trace flag 4199 servicing model).
Steg 7: Förfina frågan
Överväg att dela upp en enskild fråga med flera tabeller i flera separata frågor med hjälp av tillfälliga tabeller. Att dela upp frågan är bara ett sätt att förenkla uppgiften för optimeraren. Se följande exempel:
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
Om du vill optimera frågan kan du försöka dela upp den enskilda frågan i två frågor genom att infoga en del av kopplingsresultatet i en tillfällig tabell:
SELECT ...
INTO #temp1
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
GO
SELECT ...
FROM #temp1
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...