Arkitekturguide för frågebearbetning
gäller för:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
SQL Server Database Engine bearbetar frågor om olika datalagringsarkitekturer, till exempel lokala tabeller, partitionerade tabeller och tabeller som distribueras över flera servrar. Följande avsnitt beskriver hur SQL Server bearbetar frågor och optimerar återanvändning av frågor via cachelagring av körningsplan.
Körningslägen
SQL Server Database Engine kan bearbeta Transact-SQL-instruktioner med två olika bearbetningslägen:
- Radsvis körning
- Körning av batchläge
Utförande i radläge
körning av radläge är en frågebearbetningsmetod som används med traditionella RDBMS-tabeller, där data lagras i radformat. När en fråga körs och kommer åt data i radlagringstabeller läser körningsträdsoperatorerna och underordnade operatorerna varje obligatorisk rad i alla kolumner som anges i tabellschemat. Från varje rad som läss hämtar SQL Server sedan de kolumner som krävs för resultatuppsättningen, enligt en SELECT-instruktion, JOIN-predikat eller filterpredikat.
Not
Körning av radläge är mycket effektivt för OLTP-scenarier, men kan vara mindre effektivt vid genomsökning av stora mängder data, till exempel i datalagerscenarier.
Körning av batchläge
Batch-lägeskörning är en frågebearbetningsmetod som används för att bearbeta flera rader tillsammans (därav termen batch). Varje kolumn i en batch lagras som en vektor i ett separat minnesområde, så bearbetning i batchläge är vektorbaserad. Bearbetning i batchläge använder också algoritmer som är optimerade för processorer med flera kärnor och ökat minnesgenomflöde som finns på modern maskinvara.
När det först introducerades var batchläge-körning tämligen integrerad med och optimerad för kolumnlagringsformatet. Från och med SQL Server 2019 (15.x) och i Azure SQL Database kräver körning av batchläge inte längre kolumnlagringsindex. Mer information finns i Batch-läge på rowstore-.
Batchbearbetning fungerar på komprimerade data när det är möjligt och eliminerar exchange-operatorn som används vid exekvering i radläge. Resultatet är bättre parallellitet och snabbare prestanda.
När en fråga körs i batchläge och kommer åt data i kolumnlagerindex, läser operatorerna i exekveringsträdet och dess barnoperatorer flera rader samtidigt i kolumnsegment. SQL Server läser endast de kolumner som krävs för resultatet, enligt en SELECT-instruktion, JOIN-predikat eller filterpredikat. Mer information om columnstore-index finns i Columnstore Index Architecture.
Note
Körning av batchläge är mycket effektiva datalagerscenarier, där stora mängder data läs- och aggregeras.
SQL-instruktionsbearbetning
Bearbetning av en enda Transact-SQL-instruktion är det mest grundläggande sättet som SQL Server kör Transact-SQL-instruktioner. De steg som används för att bearbeta en enda SELECT-instruktion som endast refererar till lokala bastabeller (inga vyer eller fjärrtabeller) illustrerar den grundläggande processen.
Prioritet för logisk operator
När mer än en logisk operator används i en -instruktion utvärderas NOT först och sedan ANDoch slutligen OR. Aritmetiska och bitvisa operatorer hanteras före logiska operatorer. För mer information, se Operatorföreträde.
I följande exempel gäller färgvillkoret produktmodell 21 och inte produktmodell 20, eftersom AND har företräde framför OR.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
Du kan ändra frågans innebörd genom att lägga till parenteser för att framtvinga utvärdering av OR först. Följande fråga hittar endast produkter under modellerna 20 och 21 som är röda.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
Att använda parenteser, även om de inte krävs, kan förbättra läsbarheten för frågor och minska risken för att göra ett subtilt misstag på grund av operatorprioritet. Det finns ingen betydande prestanda påföljd vid användning av parenteser. Följande exempel är mer läsbart än det ursprungliga exemplet, även om de är syntaktiskt likadana.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
Optimera SELECT-instruktioner
Ett SELECT uttalande är inte procedurmässigt. Den anger inte de exakta steg som databasservern ska använda för att hämta begärda data. Det innebär att databasservern måste analysera -instruktionen för att fastställa det mest effektiva sättet att extrahera begärda data. Detta kallas för att optimera SELECT-instruktionen. Komponenten som gör detta kallas frågeoptimeraren. Indata till Frågeoptimeraren består av frågan, databasschemat (tabell- och indexdefinitioner) och databasstatistiken. Utdata från Frågeoptimeraren är en frågeexekveringsplan, ibland kallad en frågeplan eller en exekveringsplan. Innehållet i en exekveringsplan beskrivs mer i detalj senare i den här artikeln.
Indata och utdata för Frågeoptimeraren under optimering av en enda SELECT-instruktion visas i följande diagram:
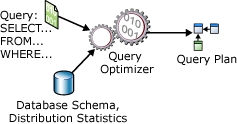
En SELECT-instruktion definierar endast följande:
- Formatet av resultatuppsättningen. Detta anges främst i urvalslistan. Andra satser som
ORDER BYochGROUP BYpåverkar dock också den slutliga formen av resultatuppsättningen. - Tabellerna som innehåller källdata. Detta anges i
FROM-satsen. - Hur tabellerna är logiskt relaterade för
SELECT-instruktionen. Detta definieras i anslutningsspecifikationerna, som kan visas iWHERE-satsen eller i enON-sats efterFROM. - De krav som raderna i källtabellerna måste uppfylla för att kvalificera sig för
SELECT-instruktionen. Dessa anges i satsernaWHEREochHAVING.
En frågekörningsplan är en beskrivning av följande:
Sekvensen där källtabellerna används.
Det finns vanligtvis många sekvenser där databasservern kan komma åt bastabellerna för att skapa resultatuppsättningen. OmSELECT-instruktionen till exempel refererar till tre tabeller kan databasservern först komma åtTableA, använda data frånTableAför att extrahera matchande rader frånTableBoch sedan använda data frånTableBför att extrahera data frånTableC. De andra sekvenserna där databasservern kan komma åt tabellerna är:
TableC,TableB,TableAeller
TableB,TableA,TableC, eller
TableB,TableC,TableAeller
TableC,TableA,TableBDe metoder som används för att extrahera data från varje tabell.
I allmänhet finns det olika metoder för att komma åt data i varje tabell. Om det bara krävs några rader med specifika nyckelvärden kan databasservern använda ett index. Om alla rader i tabellen krävs kan databasservern ignorera indexen och utföra en tabellgenomsökning. Om alla rader i en tabell krävs, men det finns ett index vars nyckelkolumner finns i enORDER BY, kan en indexgenomsökning i stället för en tabellgenomsökning spara en separat typ av resultatuppsättning. Om en tabell är mycket liten kan tabellgenomsökningar vara den mest effektiva metoden för nästan all åtkomst till tabellen.De metoder som används för att beräkna beräkningar och hur du filtrerar, aggregerar och sorterar data från varje tabell.
När data nås från tabeller finns det olika metoder för att utföra beräkningar över data, till exempel beräkning av skalära värden, och för att aggregera och sortera data enligt definitionen i frågetexten, till exempel när du använder enGROUP BY- ellerORDER BY-sats och hur du filtrerar data, till exempel när du använder enWHERE- ellerHAVING-sats.
Processen att välja en körningsplan från potentiellt många möjliga planer kallas optimering. Frågeoptimeraren är en av de viktigaste komponenterna i databasmotorn. Även om viss overhead används av frågeoptimeraren för att analysera frågan och välja en plan, sparas denna overhead vanligtvis flera gånger om när frågeoptimeraren väljer en effektiv exekveringsplan. Till exempel kan två byggföretag få identiska skisser för ett hus. Om ett företag tillbringar några dagar i början för att planera hur de ska bygga huset, och det andra företaget börjar bygga utan planering, kommer företaget som tar sig tid att planera sitt projekt förmodligen att slutföras först.
SQL Server Query Optimizer är en kostnadsbaserad optimerare. Varje möjlig exekveringsplan har en kostnad när det gäller mängden beräkningsresurser som används. Frågeoptimeraren måste analysera möjliga planer och välja den med den lägsta uppskattade kostnaden. Vissa komplexa SELECT-instruktioner har tusentals möjliga utförandeplaner. I dessa fall analyserar frågeoptimeraren inte alla möjliga kombinationer. I stället använder den komplexa algoritmer för att hitta en körningsplan som har en kostnad som är rimligen nära den minsta möjliga kostnaden.
SQL Server Query Optimizer väljer inte bara körningsplanen med den lägsta resurskostnaden. den väljer den plan som returnerar resultat till användaren med en rimlig kostnad i resurser och som returnerar resultatet snabbast. Om du till exempel bearbetar en fråga parallellt används vanligtvis fler resurser än att bearbeta den seriellt, men frågan slutförs snabbare. SQL Server Query Optimizer använder en parallell körningsplan för att returnera resultat om belastningen på servern inte påverkas negativt.
SQL Server Query Optimizer förlitar sig på distributionsstatistik när den beräknar resurskostnaderna för olika metoder för att extrahera information från en tabell eller ett index. Distributionsstatistik sparas för kolumner och index och innehåller information om densiteten1 av underliggande data. Detta används för att ange värdenas selektivitet i ett visst index eller en viss kolumn. I en tabell som till exempel representerar bilar har många bilar samma tillverkare, men varje bil har ett unikt fordonsidentifieringsnummer (VIN). Ett index på VIN är mer selektivt än ett index på tillverkaren, eftersom VIN har lägre densitet än tillverkaren. Om indexstatistiken inte är aktuell kanske frågeoptimeraren inte gör det bästa valet för tabellens aktuella tillstånd. Mer information om tätheter finns i Statistics.
1 Density definierar fördelningen av unika värden som finns i data, eller det genomsnittliga antalet duplicerade värden för en viss kolumn. När densiteten minskar ökar ett värdes selektivitet.
SQL Server Query Optimizer är viktigt eftersom det gör det möjligt för databasservern att dynamiskt justera till ändrade villkor i databasen utan att kräva indata från en programmerare eller databasadministratör. På så sätt kan programmerare fokusera på att beskriva det slutliga resultatet av frågan. De kan lita på att SQL Server Query Optimizer skapar en effektiv körningsplan för databasens tillstånd varje gång instruktionen körs.
Anteckning
SQL Server Management Studio har tre alternativ att visa exekveringsplaner:
- Den beräknade körningsplanen, som är den kompilerade planen, som skapats av frågeoptimeraren.
- Den Faktiska Körningsplanen, vilket är samma som den kompilerade planen plus dess körningskontext. Detta inkluderar körningsinformation som är tillgänglig när körningen har slutförts, till exempel körningsvarningar eller i nyare versioner av databasmotorn, den förflutna tiden och cpu-tiden som användes under körningen.
- Live Query Statistics, som är samma som den kompilerade planen plus dess körningskontext. Detta inkluderar körningsinformation under körningsförloppet och uppdateras varje sekund. Körningsinformation innehåller till exempel det faktiska antalet rader som flödar genom operatorerna.
Bearbeta en SELECT-instruktion
De grundläggande stegen som SQL Server använder för att bearbeta en enskild SELECT-instruktion är följande:
- Parsern söker igenom
SELECT-instruktionen och delar upp den i logiska enheter som nyckelord, uttryck, operatorer och identifierare. - Ett frågeträd, som ibland kallas för ett sekvensträd, skapas som beskriver de logiska steg som krävs för att omvandla källdata till det format som krävs av resultatuppsättningen.
- Frågeoptimeraren analyserar olika sätt som källtabellerna kan nås på. Den väljer sedan den serie steg som returnerar resultatet snabbast när du använder färre resurser. Frågeträdet uppdateras för att registrera den här exakta serien med steg. Den slutliga, optimerade versionen av frågeträdet kallas för körningsplanen.
- Relationsmotorn börjar verkställa verkställandeplanen. När stegen som kräver data från bastabellerna bearbetas begär relationsmotorn att lagringsmotorn skickar data från de rader som begärs från relationsmotorn.
- Relationsmotorn bearbetar de data som returneras från lagringsmotorn till det format som definierats för resultatuppsättningen och returnerar resultatuppsättningen till klienten.
Konstantvikning och utvärdering av uttryck
SQL Server utvärderar vissa konstanta uttryck tidigt för att förbättra frågeprestandan. Detta kallas konstant vikning. En konstant är en Transact-SQL literal, till exempel 3, 'ABC', '2005-12-31', 1.0e3eller 0x12345678.
Vikbara uttryck
SQL Server använder konstant vikning med följande typer av uttryck:
- Aritmetiska uttryck, till exempel
1 + 1och5 / 3 * 2, som endast innehåller konstanter. - Logiska uttryck, till exempel
1 = 1och1 > 2 AND 3 > 4, som endast innehåller konstanter. - Inbyggda funktioner som anses vikbara av SQL Server, inklusive
CASTochCONVERT. I allmänhet är en inbyggd funktion vikbar om den bara är en funktion av dess indata och inte annan kontextuell information, till exempel ALTERNATIV FÖR UPPSÄTTNING, språkinställningar, databasalternativ och krypteringsnycklar. Nondeterministiska funktioner är inte sammanställbara. Deterministiska inbyggda funktioner är vikbara, med vissa undantag. - Deterministiska metoder för CLR-användardefinierade typer och deterministiska skalära clr-användardefinierade funktioner (från och med SQL Server 2012 (11.x)). Mer information finns i konstantvikning för CLR User-Defined funktioner och metoder.
Notera
Ett undantag görs för stora objekttyper. Om utdatatypen för vikningsprocessen är en stor objekttyp (text, ntext, bild, nvarchar(max), varchar(max), varbinary(max) eller XML), viker inte SQL Server uttrycket.
Icke-mappbara uttryck
Alla andra uttryckstyper är inte vikbara. I synnerhet är följande typer av uttryck inte vikbara:
- Icke-stantiska uttryck, till exempel ett uttryck vars resultat beror på värdet för en kolumn.
- Uttryck vars resultat är beroende av en lokal variabel eller parameter, till exempel @x.
- Nondeterministiska funktioner.
- Användardefinierade Transact-SQL funktioner1.
- Uttryck vars resultat är beroende av språkinställningar.
- Uttryck vars resultat är beroende av SET-alternativ.
- Uttryck vars resultat är beroende av serverkonfigurationsalternativ.
1 Före SQL Server 2012 (11.x) var deterministiska skalvärdesbaserade CLR-användardefinierade funktioner och metoder för CLR-användardefinierade typer inte vikbara.
Exempel på vikbara och icke-hopfällbara konstanta uttryck
Överväg följande fråga:
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
Om alternativet PARAMETERIZATION databas inte är inställt på FORCED för den här frågan utvärderas uttrycket 117.00 + 1000.00 och ersätts av resultatet 1117.00innan frågan kompileras. Fördelarna med den här konstanta vikningen är följande:
- Uttrycket behöver inte utvärderas upprepade gånger under körningstid.
- Värdet för uttrycket när det har utvärderats används av Frågeoptimeraren för att uppskatta storleken på resultatuppsättningen för den del av frågan som
TotalDue > 117.00 + 1000.00.
Om dbo.f å andra sidan är en skalär användardefinierad funktion viks inte uttrycket dbo.f(100) eftersom SQL Server inte viker uttryck som omfattar användardefinierade funktioner, även om de är deterministiska. Mer information om parameterisering finns i Tvingad parameterisering senare i den här artikeln.
Utvärdering av uttryck
Dessutom utvärderas vissa uttryck som inte är konstantfaldna men vars argument är kända under kompilering, oavsett om argumenten är parametrar eller konstanter, av kardinalitetsestimatorn som är en del av optimeraren.
Mer specifikt utvärderas följande inbyggda funktioner och särskilda operatorer vid kompileringstiden om alla deras indata är kända: UPPER, LOWER, RTRIM, DATEPART( YY only ), GETDATE, CASToch CONVERT. Följande operatorer utvärderas också vid kompileringstillfället om alla deras indata är kända:
- Aritmetiska operatorer: +, -, *, /, unary -
- Logiska operatorer:
AND,OR,NOT - Jämförelseoperatorer: <, >, <=, >=, <>,
LIKE,IS NULL,IS NOT NULL
Inga andra funktioner eller operatorer utvärderas av frågeoptimeraren vid kardinalitetsuppskattning.
Exempel på utvärdering av kompileringstiduttryck
Tänk på den här lagrade proceduren:
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
Under optimeringen av SELECT-instruktionen i proceduren försöker frågeoptimeraren utvärdera den förväntade kardinaliteten för resultatuppsättningen för villkoret OrderDate > @d+1. Uttrycket @d+1 är inte konstant vikt eftersom @d är en parameter. Men vid optimeringstid är värdet för parametern känt. På så sätt kan frågeoptimeraren beräkna storleken på resultatuppsättningen korrekt, vilket hjälper den att välja en bra frågeplan.
Överväg nu ett exempel som liknar det föregående, förutom att en lokal variabel @d2 ersätter @d+1 i frågan och uttrycket utvärderas i en SET-instruktion i stället för i frågan.
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
När SELECT-instruktionen i MyProc2 är optimerad i SQL Server är värdet för @d2 inte känt. Därför använder Frågeoptimeraren en standarduppskattning för selektiviteten för OrderDate > @d2, (i det här fallet 30 procent).
Bearbeta andra uttalanden
De grundläggande stegen som beskrivs för bearbetning av en SELECT-instruktion gäller för andra Transact-SQL-instruktioner som INSERT, UPDATEoch DELETE.
UPDATE- och DELETE-instruktioner måste båda riktas mot den uppsättning rader som ska ändras eller tas bort. Processen att identifiera dessa rader är samma process som används för att identifiera de källrader som bidrar till resultatuppsättningen för en SELECT-instruktion. Satserna UPDATE och INSERT kan båda innehålla inbäddade SELECT-instruktioner som tillhandahåller de datavärden som ska uppdateras eller infogas.
Även DDL-instruktioner (Data Definition Language), till exempel CREATE PROCEDURE eller ALTER TABLE, översätts slutligen till en serie av relationella operationer på systemkatalogtabellerna och ibland (till exempel ALTER TABLE ADD COLUMN) mot datatabellerna.
Arbetstabeller
Relationsmotorn kan behöva skapa en arbetstabell för att utföra en logisk åtgärd som anges i en Transact-SQL-instruktion. Arbetstabeller är interna tabeller som används för att lagra mellanliggande resultat. Arbetstabeller genereras för vissa GROUP BY, ORDER BYeller UNION frågor. Om en ORDER BY-sats till exempel refererar till kolumner som inte omfattas av några index, kan relationsmotorn behöva generera en arbetstabell för att sortera resultatuppsättningen i den begärda ordningen. Arbetsbord används också ibland som spolar som tillfälligt innehåller resultatet från att köra en del av en frågeplan. Arbetstabeller är inbyggda i tempdb och tas bort automatiskt när de inte längre behövs.
Visa upplösning
SQL Server-frågeprocessorn behandlar indexerade och icke-indexerade vyer på olika sätt:
- Raderna i en indexerad vy lagras i databasen i samma format som en tabell. Om frågeoptimeraren bestämmer sig för att använda en indexerad vy i en frågeplan behandlas denna på samma sätt som en bastabell.
- Endast definitionen av en icke-indexerad vy lagras, inte raderna i vyn. Frågeoptimeraren införlivar logiken från vydefinitionen i den körningsplan som den skapar för Transact-SQL-instruktionen som refererar till den icke-indexerade vyn.
Logiken som används av SQL Server Query Optimizer för att bestämma när en indexerad vy ska användas liknar den logik som används för att bestämma när ett index ska användas i en tabell. Om data i den indexerade vyn täcker hela eller delar av Transact-SQL-instruktionen, och Frågeoptimeraren fastställer att ett index i vyn är den billiga åtkomstsökvägen, väljer Frågeoptimeraren indexet oavsett om vyn refereras efter namn i frågan.
När en Transact-SQL-instruktion refererar till en icke-indexerad vy analyserar parsern och Frågeoptimeraren källan för både Transact-SQL-instruktionen och vyn och löser dem sedan till en enda körningsplan. Det är ingen plan för Transact-SQL-deklarationen och en separat plan för vyn.
Tänk till exempel på följande vy:
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
Baserat på den här vyn utför båda dessa Transact-SQL-instruktioner samma åtgärder på bastabellerna och ger samma resultat:
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
Funktionen SQL Server Management Studio Showplan visar att relationsmotorn skapar samma körningsplan för båda dessa SELECT-instruktioner.
Använd tips med vyer
Tips som placeras på vyer i en fråga kan vara i konflikt med andra tips som identifieras när vyn expanderas för att få åtkomst till dess bastabeller. När detta inträffar returnerar frågan ett fel. Tänk dig till exempel följande vy som innehåller ett tabelltips i definitionen:
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
Anta nu att du anger den här frågan:
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
Frågan misslyckas eftersom tipset SERIALIZABLE som tillämpas på vyn Person.AddrState i frågan sprids till båda tabellerna Person.Address och Person.StateProvince i vyn när den expanderas. Emellertid, om du expanderar vyn avslöjas även ledtråden NOLOCK om Person.Address. Eftersom SERIALIZABLE och NOLOCK ledtrådar står i konflikt är den resulterande sökfrågan felaktig.
Tabelltipsen PAGLOCK, NOLOCK, ROWLOCK, TABLOCKeller TABLOCKX står i konflikt med varandra, liksom tabelltipsen HOLDLOCK, NOLOCK, READCOMMITTED, REPEATABLEREAD, SERIALIZABLE.
Tips kan spridas genom nivåer av kapslade vyer. Till exempel, anta att en fråga tillämpar HOLDLOCK ledtråd på en vy v1. När v1 expanderas ser vi att vyn v2 är en del av dess definition.
v2:s definition innehåller ett NOLOCK-tips om en av bastabellerna. Men den här tabellen ärver också HOLDLOCK anvisning från frågan i vyn v1. Eftersom indikationerna NOLOCK och HOLDLOCK konflikterar, misslyckas frågan.
När det FORCE ORDER tipset används i en fråga som innehåller en vy bestäms kopplingsordningen för tabellerna i vyn av vyns position i den ordnade konstruktionen. Följande fråga väljer till exempel från tre tabeller och en vy:
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
Och View1 definieras enligt följande:
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
Kopplingsordningen i frågeplanen är Table1, Table2, TableA, TableB, Table3.
Lösa index för vyer
Precis som med alla index väljer SQL Server att använda en indexerad vy i sin frågeplan endast om frågeoptimeraren anser att det är fördelaktigt att göra det.
Indexerade vyer kan skapas i valfri utgåva av SQL Server. I vissa utgåvor av vissa äldre versioner av SQL Server tar Frågeoptimeraren automatiskt hänsyn till den indexerade vyn. I vissa utgåvor av vissa äldre versioner av SQL Server måste du använda NOEXPAND tabelltips för att kunna använda en indexerad vy. Automatisk användning av en indexerad vy av frågeoptimeraren stöds endast i specifika utgåvor av SQL Server. Azure SQL Database och Azure SQL Managed Instance stöder även automatisk användning av indexerade vyer utan att ange NOEXPAND tips.
SQL Server Query Optimizer använder en indexerad vy när följande villkor uppfylls:
- Dessa sessionsalternativ är inställda på
ON:ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
- Alternativet
NUMERIC_ROUNDABORTsession är inställt på AV. - Frågeoptimeraren hittar en matchning mellan vyindexkolumnerna och elementen i frågan, till exempel följande:
- Sökvillkor predikat i WHERE-satsen
- Sammanfogningsoperationer
- Mängdfunktioner
-
GROUP BY-satser - Tabellreferenser
- Den uppskattade kostnaden för att använda indexet har den lägsta kostnaden för alla åtkomstmekanismer som beaktas av Frågeoptimeraren.
- Varje tabell som refereras i frågan (antingen direkt eller genom att expandera en vy för att komma åt dess underliggande tabeller) som motsvarar en tabellreferens i den indexerade vyn måste ha samma uppsättning tips som tillämpas på den i frågan.
Notera
Tipsen READCOMMITTED och READCOMMITTEDLOCK betraktas alltid som olika tips i den här kontexten, oavsett aktuell transaktionsisoleringsnivå.
Förutom kraven för SET alternativ och tabelltips är dessa samma regler som Frågeoptimeraren använder för att avgöra om ett tabellindex omfattar en fråga. Inget annat behöver anges i frågan för att en indexerad vy ska användas.
En fråga behöver inte uttryckligen referera till en indexerad vy i FROM-satsen för att Frågeoptimeraren ska använda den indexerade vyn. Om frågan innehåller referenser till kolumner i bastabellerna som också finns i den indexerade vyn, och Frågeoptimeraren uppskattar att användning av den indexerade vyn ger den lägsta kostnadsåtkomstmekanismen, väljer Frågeoptimeraren den indexerade vyn, på samma sätt som den väljer bastabellindex när de inte refereras direkt i en fråga. Frågeoptimeraren kan välja vyn när den innehåller kolumner som inte refereras av frågan, så länge vyn erbjuder det lägsta kostnadsalternativet för att täcka en eller flera av de kolumner som anges i frågan.
Frågeoptimeraren behandlar en indexerad vy som refereras i FROM-satsen som en standardvy. Frågeoptimeraren expanderar definitionen av vyn till frågan i början av optimeringsprocessen. Sedan utförs matchning av indexerade vyer. Den indexerade vyn kan användas i den slutliga utförandeplanen som valts av Query Optimizer, eller så kan planen istället materialisera nödvändiga data från vyn genom att komma åt de bastabeller som refereras av vyn. Frågeoptimeraren väljer det billigaste alternativet.
Använda ledtrådar med indexerade vyer
Du kan förhindra att visningsindex används för en fråga med hjälp av EXPAND VIEWS frågetips, eller så kan du använda NOEXPAND tabelltipset för att framtvinga användningen av ett index för en indexerad vy som anges i FROM-satsen i en fråga. Du bör dock låta Frågeoptimeraren dynamiskt fastställa de bästa åtkomstmetoderna som ska användas för varje fråga. Begränsa din användning av EXPAND och NOEXPAND till specifika fall där testningen har visat att de förbättrar prestanda avsevärt.
Alternativet
EXPAND VIEWSanger att Frågeoptimeraren inte använder några visningsindex för hela frågan.När
NOEXPANDanges för en vy överväger frågeoptimeraren att använda index som definierats i vyn.NOEXPANDsom anges med den valfriaINDEX()-satsen tvingar Frågeoptimeraren att använda de angivna indexen.NOEXPANDkan endast anges för en indexerad vy och kan inte anges för en vy som inte är indexerad. Automatisk användning av en indexerad vy av frågeoptimeraren stöds endast i specifika utgåvor av SQL Server. Azure SQL Database och Azure SQL Managed Instance stöder även automatisk användning av indexerade vyer utan att angeNOEXPANDtips.
När varken NOEXPAND eller EXPAND VIEWS anges i en fråga som innehåller en vy, expanderas vyn för att komma åt underliggande tabeller. Om frågan som utgör vyn innehåller några tabelltips sprids dessa tips till de underliggande tabellerna. (Den här processen förklaras mer detaljerat i Visningslösning.) Så länge uppsättningen ledtrådar som finns i de underliggande tabellerna i vyn är identiska kan sökningen matchas med en indexerad vy. För det mesta matchar dessa tips varandra eftersom de ärvs direkt från vyn. Men om frågan refererar till tabeller i stället för vyer och tipsen som tillämpas direkt på dessa tabeller inte är identiska, är en sådan fråga inte berättigad till matchning med en indexerad vy. Om tipsen INDEX, PAGLOCK, ROWLOCK, TABLOCKX, UPDLOCKeller XLOCK gäller för tabellerna som refereras i frågan efter visningsexpansionen är frågan inte berättigad till matchning av indexerad vy.
Om ett tabelltips i form av INDEX (index_val[ ,...n] ) refererar till en vy i en fråga och du inte också anger NOEXPAND tips ignoreras indextipset. Om du vill ange användning av ett visst index använder du NOEXPAND.
När frågeoptimeraren i allmänhet matchar en indexerad vy med en fråga tillämpas alla tips som anges i tabellerna eller vyerna i frågan direkt på den indexerade vyn. Om frågeoptimeraren väljer att inte använda en indexerad vy sprids eventuella tips direkt till tabellerna som refereras i vyn. Mer information finns i Visa upplösning. Den här spridningen gäller inte för kopplingstips. De tillämpas endast i sin ursprungliga position i frågan. Kopplingstips beaktas inte av frågeoptimeraren när frågor matchas med indexerade vyer. Om en frågeplan använder en indexerad vy som matchar en del av en fråga som innehåller ett kopplingstips används inte kopplingstipset i planen.
Ledtrådar tillåts inte i definitionerna av indexerade vyer. I kompatibilitetsläge 80 och senare ignorerar SQL Server ledtrådar i indexerade vydefinitioner när de underhålls eller vid körning av frågor som använder indexerade vyer. Även om tips i indexerade vydefinitioner inte ger upphov till ett syntaxfel i 80-kompatibilitetsläge ignoreras de.
Mer information finns i Tabelltips (Transact-SQL).
Hantera distribuerade partitionerade vyer
SQL Server-frågeprocessorn optimerar prestanda för distribuerade partitionerade vyer. Den viktigaste aspekten av distribuerad partitionerad vyprestanda är att minimera mängden data som överförs mellan medlemsservrar.
SQL Server skapar intelligenta, dynamiska planer som effektivt använder distribuerade frågor för att komma åt data från fjärrmedlemstabeller:
- Frågeprocessorn använder först OLE DB för att hämta kontrollvillkorsdefinitionerna från varje medlemstabell. På så sätt kan frågeprocessorn mappa fördelningen av nyckelvärden mellan medlemstabellerna.
- Frågeprocessorn jämför de nyckelintervall som anges i en Transact-SQL-instruktion
WHERE-sats med kartan som visar hur raderna distribueras i medlemstabellerna. Frågeprocessorn skapar sedan en frågekörningsplan som använder distribuerade frågor för att endast hämta de fjärrrader som krävs för att slutföra Transact-SQL-instruktionen. Körningsplanen är också utformad på ett sådant sätt att all åtkomst till fjärrmedlemmars tabeller, för antingen data eller metadata, fördröjs tills informationen krävs.
Tänk dig till exempel ett system där en Customers tabell är partitionerad mellan Server1 (CustomerID från 1 till 3299999), Server2 (CustomerID från 3300000 till 6599999) och Server3 (CustomerID från 6600000 till 9999999).
Överväg körningsplanen som skapats för den här frågan som körs på Server1:
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
Körningsplanen för den här frågan extraherar raderna med CustomerID nyckelvärden från 3200000 till 3299999 från den lokala medlemstabellen och utfärdar en distribuerad fråga för att hämta raderna med nyckelvärden från 3300000 till 3400000 från Server2.
SQL Server-frågeprocessorn kan också skapa dynamisk logik i frågekörningsplaner för Transact-SQL-instruktioner där nyckelvärdena inte är kända när planen måste skapas. Tänk till exempel på den här lagrade proceduren:
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
SQL Server kan inte förutsäga vilket nyckelvärde som ska anges av parametern @CustomerIDParameter varje gång proceduren körs. Eftersom nyckelvärdet inte kan förutsägas kan frågeprocessorn inte heller förutsäga vilken medlemstabell som måste nås. För att hantera det här fallet skapar SQL Server en körningsplan som har villkorsstyrd logik, som kallas dynamiska filter, för att styra vilken medlemstabell som används baserat på indataparametervärdet. Förutsatt att den GetCustomer lagrade proceduren kördes på Server1 kan körningsplanens logik representeras enligt följande:
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
SQL Server skapar ibland dessa typer av dynamiska körningsplaner även för frågor som inte är parametriserade. Frågeoptimeraren kan parameterisera en fråga så att körningsplanen kan återanvändas. Om Frågeoptimeraren parameteriserar en fråga som refererar till en partitionerad vy kan frågeoptimeraren inte längre anta att de obligatoriska raderna kommer från en angiven bastabell. Sedan måste den använda dynamiska filter i utförandeplanen.
Körning av lagrade procedurer och triggers
SQL Server lagrar endast källan för lagrade procedurer och utlösare. När en lagrad procedur eller utlösare först körs kompileras källkoden till en körningsplan. Om den lagrade proceduren eller utlösaren körs igen innan körningsplanen har raderas från minnet identifierar den relationella motorn den befintliga planen och återanvänder den. Om planen har gått ur minnet skapas en ny plan. Den här processen liknar den process som SQL Server följer för alla Transact-SQL-instruktioner. Den största prestandafördelen som lagrade procedurer och utlösare har i SQL Server jämfört med batchar med dynamiska Transact-SQL är att deras Transact-SQL-instruktioner alltid är desamma. Därför matchar relationsdatabasens motor dem enkelt med alla befintliga exekveringsplaner. Lagrade procedurer och utlösarplaner återanvänds enkelt.
Körningsplanen för lagrade procedurer och utlösare körs separat från körningsplanen för batchen som anropar den lagrade proceduren eller utlöser utlösaren. Detta möjliggör större återanvändning av de lagrade procedurernas och triggerplanernas körning.
Cachelagring och återanvändning av körningsplan
SQL Server har en pool med minne som används för att lagra både körningsplaner och databuffertar. Procentandelen av poolen som allokeras till antingen körningsplaner eller databuffertar varierar dynamiskt, beroende på systemets tillstånd. Den del av minnespoolen som används för att lagra körningsplaner kallas för plancachen.
Plancachen har två lager för alla kompilerade planer:
- -objektplaner cachelagring (OBJCP) som används för planer relaterade till bevarade objekt (lagrade procedurer, funktioner och utlösare).
- Det SQL-planer cachelagret (SQLCP) används för planer relaterade till autoparametriserade, dynamiska eller förberedda frågor.
Frågan nedan innehåller information om minnesanvändning för dessa två cachelager:
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
Notera
Plancachen har ytterligare två lagringar som inte används för att lagra planer:
- Bound Trees cacheminne (PHDR) används för datastrukturer vid kompilering av planer för vyer, begränsningar och standardvärden. Dessa strukturer kallas Förbundna träd eller Algebrizer-träd.
- Den extended stored procedures cache store (XPROC) som används för fördefinierade systemprocedurer, till exempel
sp_executeSqlellerxp_cmdshell, som definieras med hjälp av en DLL, inte med hjälp av Transact-SQL-instruktioner. Den cachelagrade strukturen innehåller bara funktionsnamnet och DLL-namnet där proceduren implementeras.
SQL Server-körningsplaner har följande huvudkomponenter:
Kompilerad plan (eller frågeplan)
Frågeplanen som skapas av kompileringsprocessen är mestadels en återinträdesbar, skrivskyddad datastruktur som kan användas av många användare. Den lagrar information om:Fysiska operatorer som implementerar åtgärden som beskrivs av logiska operatorer.
Ordningen på dessa operatorer, som avgör i vilken ordning data används, filtreras och aggregeras.
Antalet uppskattade rader som passerar genom operatorerna.
Not
I nyare versioner av databasmotorn lagras även information om de statistikobjekt som användes för kardinalitetsuppskattning.
Vilka stödobjekt måste skapas, till exempel arbetstabeller eller arbetsfiler i
tempdb. Ingen användarkontext eller körningsinformation lagras i frågeplanen. Det finns aldrig mer än en eller två kopior av frågeplanen i minnet: en kopia för alla seriella körningar och en annan för alla parallella körningar. Den parallella kopian omfattar alla parallella körningar, oavsett graden av parallellitet.
exekveringskontext
Varje användare som för närvarande kör frågan har en datastruktur som innehåller data som är specifika för deras körning, till exempel parametervärden. Den här datastrukturen kallas för körningskontexten. Datastrukturerna för körningskontext återanvänds, men deras innehåll återanvänds inte. Om en annan användare kör samma fråga initieras datastrukturerna på nytt med kontexten för den nya användaren.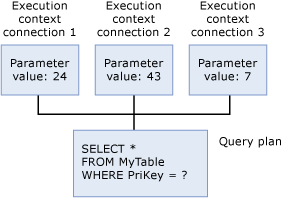
När någon Transact-SQL-instruktion körs i SQL Server söker databasmotorn först igenom plancachen för att verifiera att det finns en befintlig körningsplan för samma Transact-SQL-instruktion. Transact-SQL-instruktionen kvalificerar sig som befintlig om den bokstavligen matchar en tidigare utförd Transact-SQL-instruktion med en cachelagrad plan, tecken för tecken. SQL Server återanvänder alla befintliga planer som hittas, vilket sparar kostnaderna för att omkompilera Transact-SQL-instruktionen. Om det inte finns någon körningsplan genererar SQL Server en ny körningsplan för frågan.
Obs
Körningsplanerna för vissa Transact-SQL-instruktioner sparas inte i plancachen, till exempel massåtgärdsinstruktioner som körs på rowstore eller instruktioner som innehåller strängliteraler som är större än 8 KB. Dessa planer finns bara medan sökfrågan körs.
SQL Server har en effektiv algoritm för att hitta befintliga körningsplaner för en specifik Transact-SQL-instruktion. I de flesta system är de minimala resurser som används av den här genomsökningen mindre än de resurser som sparas genom att kunna återanvända befintliga planer i stället för att kompilera varje Transact-SQL-instruktion.
Algoritmerna för att matcha nya Transact-SQL-instruktioner med befintliga, oanvända körningsplaner i plancachen kräver att alla objektreferenser är fullständigt kvalificerade. Anta till exempel att Person är standardschemat för användaren som kör nedanstående SELECT-instruktioner. Även om det i det här exemplet inte krävs att tabellen Person är fullständigt kvalificerad att genomföras, innebär det att den andra instruktionen inte matchas med en befintlig plan, men den tredje matchas:
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
Om du ändrar något av följande SET-alternativ för en viss körning påverkas möjligheten att återanvända planer, eftersom databasmotorn utför konstant vikning och dessa alternativ påverkar resultatet av sådana uttryck:
ANSI_NULL_DFLT_OFF
FORCEPLAN
ARITHABORT
DATEFIRST
ANSI_PADDING
NUMERIC_ROUNDABORT
ANSI_NULL_DFLT_ON
SPRÅK
CONCAT_NULL_YIELDS_NULL
DATUMFORMAT
ANSI_WARNINGS
QUOTED_IDENTIFIER
ANSI_NULLS
NO_BROWSETABLE
ANSI_DEFAULTS
Cachelagrar flera planer för samma fråga
Frågeställningar och exekveringsplaner är unikt identifierbara i databasmotorn, ungefär som ett fingeravtryck:
- -frågeplanens hash- är ett binärt hash-värde som beräknas på körningsplanen för en viss fråga och används för att unikt identifiera liknande körningsplaner.
- Den frågans hash- är ett binärt hashvärde som beräknas på Transact-SQL text i en fråga och används för att unikt identifiera frågor.
En kompilerad plan kan hämtas från plancachen med hjälp av en Plan Handle, som är en tillfällig identifierare som endast förblir konstant när planen finns kvar i cacheminnet. Planhanteraren är ett hash-värde som härleds från den kompilerade planen för hela batchen. Planhandtaget för en kompilerad plan förblir detsamma även om en eller flera satser i batchen kompileras om.
Note
Om en plan kompilerades för en sats i stället för en enda sats kan planen för enskilda satser i satsen hämtas med hjälp av planhandtaget och satsförskjutningarna.
Den sys.dm_exec_requests DMV innehåller kolumnerna statement_start_offset och statement_end_offset för varje post, som refererar till instruktionen som för närvarande körs för en batch som körs eller beständigt objekt. Mer information finns i sys.dm_exec_requests (Transact-SQL).
sys.dm_exec_query_stats DMV innehåller också dessa kolumner för varje post som refererar till positionen för en instruktion i batchen eller ett beständigt objekt. Mer information finns i sys.dm_exec_query_stats (Transact-SQL).
Den faktiska Transact-SQL texten i en batch lagras i ett separat minnesutrymme från plancachen, som kallas SQL Manager cache (SQLMGR). Den Transact-SQL texten för en kompilerad plan kan hämtas från SQL Manager-cachen med hjälp av en SQL Handle, som är en tillfällig identifierare som endast förblir konstant medan minst en plan som refererar till den finns kvar i plancachen. SQL-referensen är ett hash-värde som härleds från hela batchtexten och är garanterat unikt för varje batch.
Note
Precis som en kompilerad plan lagras Transact-SQL-texten för varje batch, inklusive kommentarerna. SQL-handtaget innehåller MD5-hashen för hela batchtexten och är garanterat unik för varje batch.
Frågan nedan innehåller information om minnesanvändning för SQL Manager-cachen:
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
Det finns en 1:N-relation mellan ett SQL-hanteringsobjekt och planhanteringsobjekt. Ett sådant villkor inträffar när cachenyckeln för de kompilerade planerna skiljer sig. Detta kan inträffa på grund av ändringar i SET-alternativen mellan två körningar av samma batch.
Överväg följande lagrade procedur:
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
Kontrollera vad som finns i plancachen med hjälp av frågan nedan:
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
Här är resultatet.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Kör nu den lagrade proceduren med en annan parameter, men inga andra ändringar i körningskontexten:
EXEC usp_SalesByCustomer 8
GO
Kontrollera igen vad som finns i plancachen. Här är resultatet.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Observera att usecounts har ökat till 2, vilket innebär att samma cachelagrade plan återanvänddes as-iseftersom datastrukturerna för körningskontexten återanvänddes. Ändra nu alternativet SET ANSI_DEFAULTS och kör den lagrade proceduren med samma parameter.
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
Kontrollera igen vad som finns i plancachen. Här är resultatet.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Observera att det nu finns två poster i sys.dm_exec_cached_plans DMV-utdata:
- Kolumnen
usecountsvisar värdet1i den första posten, vilken är planen som utförs en gång medSET ANSI_DEFAULTS OFF. - Kolumnen
usecountsvisar värdet2i den andra posten, som är planen som kördes medSET ANSI_DEFAULTS ON, eftersom den har körts två gånger. - De olika
memory_object_addressrefererar till en annan post i körningsplanen i plancachen. Detsql_handlevärdet är dock detsamma för båda posterna eftersom de refererar till samma batch.- Körningen med
ANSI_DEFAULTSinställd på OFF har en nyplan_handleoch är tillgänglig för återanvändning för anrop som har samma uppsättning SET-alternativ. Det nya planhandtaget är nödvändigt eftersom körningskontexten initierades på nytt på grund av ändrade SET-alternativ. Men det utlöser ingen omkompilering: båda posterna refererar till samma plan och fråga, vilket framgår av sammaquery_plan_hashochquery_hashvärden.
- Körningen med
Det innebär i praktiken att vi har två planposter i cacheminnet som motsvarar samma batch, och det understryker vikten av att se till att plancachen som påverkar SET-alternativen är densamma, när samma frågor körs upprepade gånger, för att optimera för återanvändning av planen och hålla planens cachestorlek till det minimum som krävs.
Tips
En vanlig fallgrop är att olika klienter kan ha olika standardvärden för SET-alternativen. En anslutning som görs via SQL Server Management Studio ställer till exempel automatiskt in QUOTED_IDENTIFIER till PÅ, medan SQLCMD anger QUOTED_IDENTIFIER till AV. Att köra samma frågor från dessa två klienter resulterar i flera planer (enligt beskrivningen i exemplet ovan).
Ta bort utförandeplaner från plancachen
Körningsplaner finns kvar i plancachen så länge det finns tillräckligt med minne för att lagra dem. När det finns minnesbelastning använder SQL Server Database Engine en kostnadsbaserad metod för att avgöra vilka körningsplaner som ska tas bort från plancachen. För att fatta ett kostnadsbaserat beslut ökar och minskar SQL Server Database Engine en aktuell kostnadsvariabel för varje körningsplan enligt följande faktorer.
När en användarprocess infogar en körningsplan i cacheminnet anger användarprocessen den aktuella kostnaden som motsvarar den ursprungliga frågekompileringskostnaden. för ad hoc-körningsplaner anger användarprocessen den aktuella kostnaden till noll. Därefter återställs den aktuella kostnaden till den ursprungliga kompileringskostnaden varje gång en användarprocess refererar till en körningsplan. för ad hoc-körningsplaner ökar användarprocessen den aktuella kostnaden. För alla planer är det maximala värdet för den aktuella kostnaden den ursprungliga kompileringskostnaden.
När det finns minnesbelastning reagerar SQL Server-databasmotorn genom att ta bort exekveringsplaner från plancachen. För att avgöra vilka planer som ska tas bort undersöker SQL Server Database Engine upprepade gånger tillståndet för varje körningsplan och tar bort planer när den aktuella kostnaden är noll. En körningsplan med noll aktuell kostnad tas inte bort automatiskt när minnesbelastning förekommer; den avlägsnas bara när SQL Server-databasmotorn undersöker planen och den aktuella kostnaden är noll. När du undersöker en exekveringsplan skickar SQL Server Database Engine den aktuella kostnaden mot noll genom att minska den aktuella kostnaden för en fråga för närvarande inte använder planen.
SQL Server Database Engine granskar exekveringsplanerna upprepade gånger tills tillräckligt många har tagits bort för att uppfylla minneskraven. Även om minnesbelastningen finns kan en körningsplan få sina kostnader ökade och minskade mer än en gång. När minnesbelastningen inte längre finns slutar SQL Server Database Engine att minska den aktuella kostnaden för oanvända körningsplaner och alla körningsplaner finns kvar i plancachen, även om kostnaden är noll.
SQL Server Database Engine använder resursövervakaren och användararbetstrådarna för att frigöra minne från plancachen som svar på minnesbelastningen. Resursövervakaren och arbetstrådarna för användare kan undersöka planer som körs parallellt för att sänka den nuvarande kostnaden för varje oanvänd exekveringsplan. Resursövervakaren tar bort körningsplaner från plancachen när det finns ett globalt minnestryck. Det frigör minne för att tillämpa principer för systemminne, processminne, resurspoolminne och maximal storlek för alla cacheminnen.
Den maximala storleken för alla cacheminnen är en funktion av buffertpoolens storlek och får inte överskrida det maximala serverminnet. Mer information om hur du konfigurerar maximalt serverminne finns i inställningen max server memory i sp_configure.
Användararbetstrådarna tar bort körplaner från plancachen när det finns tryck på minnet från en enskild cache. De tillämpar principer för maximal storlek på en enda cache och högsta enskilda cacheposter.
Följande exempel visar vilka exekveringsplaner som tas bort från plancachen:
- En körningsplan refereras ofta för att kostnaden aldrig ska gå till noll. Planen finns kvar i plancachen och tas inte bort om det inte finns minnesbelastning och den aktuella kostnaden är noll.
- En ad hoc-körningsplan infogas och refereras inte igen innan minnesbelastningen finns. Eftersom ad hoc-planer initieras med en aktuell kostnad på noll, kommer SQL Server Database Engine att se den aktuella kostnaden som noll och ta bort planen från plancachen när den undersöker exekveringsplanen. Ad hoc-körningsplanen finns kvar i plancachen med noll aktuell kostnad när det inte finns någon minnesbelastning.
Om du vill ta bort en enda plan eller alla planer från cacheminnet manuellt använder du DBCC FREEPROCCACHE.
DBCC FREESYSTEMCACHE kan också användas för att rensa alla cacheminnen, inklusive plan-cache. Från och med SQL Server 2016 (13.x), använd ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE för att rensa procedurcachen för den aktuella databasen.
En ändring av vissa konfigurationsinställningar via sp_configure och omkonfigurera gör också att planer tas bort från plancachen. Du hittar listan över dessa konfigurationsinställningar i avsnittet Anmärkningar i artikeln DBCC FREEPROCCACHE. En konfigurationsändring som den här loggar följande informationsmeddelande i felloggen:
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
Kompilera om körningsplaner
Vissa ändringar i en databas kan orsaka att en körningsplan antingen är ineffektiv eller ogiltig, baserat på databasens nya tillstånd. SQL Server identifierar de ändringar som ogiltigförklarar en körningsplan och markerar planen som ogiltig. En ny plan måste sedan omkompileras för nästa anslutning som kör databasfrågan. Villkoren som ogiltigförklarar en plan omfattar följande:
- Ändringar som gjorts i en tabell eller vy som refereras av frågan (
ALTER TABLEochALTER VIEW). - Ändringar som görs i en specifik procedur, vilket medför att alla planerna för den proceduren tas bort från cacheminnet (
ALTER PROCEDURE). - Ändringar i alla index som används av körningsplanen.
- Uppdateringar av statistik som används av körningsplanen genereras antingen explicit från ett uttalande, som
UPDATE STATISTICS, eller genereras automatiskt. - Ta bort ett index som används av exekveringsplanen.
- Ett explicit anrop till
sp_recompile. - Ett stort antal ändringar av nycklar (som genereras av
INSERTellerDELETE-instruktioner från andra användare som ändrar en tabell som refereras av frågan). - Om antalet rader i de infogade eller borttagna tabellerna ökar avsevärt för tabeller med utlösare.
- Köra en lagrad procedur med hjälp av alternativet
WITH RECOMPILE.
De flesta omkompileringar krävs antingen för korrekthet i uttalanden eller för att erhålla potentialt snabbare frågekörningsplaner.
I SQL Server-versioner före 2005, när en instruktion i en batch orsakar omkompilering, kompilerades hela batchen, oavsett om den skickades via en lagrad procedur, utlösare, ad hoc-batch eller förberedd instruktion. Från och med SQL Server 2005 (9.x) kompileras endast instruktionen i batchen som utlöser omkompilering. Dessutom finns det ytterligare typer av omkompileringar i SQL Server 2005 (9.x) och senare på grund av dess utökade funktionsuppsättning.
Omkompilering på statement-nivå gynnar prestanda eftersom ett litet antal instruktioner i de flesta fall orsakar omkompileringar och tillhörande påföljder när det gäller CPU-tid och lås. Dessa påföljder undviks därför för de andra satserna i batchen som inte behöver omkompileras.
Den sql_statement_recompile utökade händelsen (XEvent) rapporterar omkompileringar på instruktionsnivå. Denna XEvent inträffar när en omkompilering på instruktionsnivå krävs av någon typ av batch. Detta omfattar lagrade procedurer, utlösare, ad hoc-batchar och frågor. Batchar kan skickas via flera gränssnitt, inklusive sp_executesql, dynamisk SQL, Förbereda metoder eller Kör metoder.
Kolumnen recompile_cause i sql_statement_recompile XEvent innehåller en heltalskod som anger orsaken till omkompileringen. Följande tabell innehåller möjliga orsaker:
Schemat har ändrats
Statistik har ändrats
Uppskjuten kompilering
SET-alternativet har ändrats
Temporär tabell har ändrats
Fjärrraduppsättningen har ändrats
FOR BROWSE behörigheten har ändrats
Frågemeddelandemiljön har ändrats
Partitionerad vy har ändrats
Marköralternativen har ändrats
OPTION (RECOMPILE) begärd
Parametriserad plan utrensad
Plan som påverkar databasversionen har ändrats
Policy för tvingande av Query Store-planer har ändrats
Det gick inte att tvinga fram query Store-planen
Query Store saknar en plan
Not
I SQL Server-versioner där XEvents inte är tillgängliga kan SQL Server Profiler SP:Recompile spårningshändelse användas för samma syfte med rapportering av omkompileringar på instruktionsnivå.
Spårningshändelsen SQL:StmtRecompile rapporterar även omkompileringar på instruktionsnivå, och den här spårningshändelsen kan också användas för att spåra och felsöka omkompileringar.
Medan SP:Recompile endast genererar för lagrade procedurer och utlösare genererar SQL:StmtRecompile för lagrade procedurer, utlösare, ad hoc-batchar, batchar som körs med hjälp av sp_executesql, förberedda frågor och dynamisk SQL.
Kolumnen EventSubClass i SP:Recompile och SQL:StmtRecompile innehåller en heltalskod som anger orsaken till omkompileringen. Koderna beskrivs här.
Not
När databasalternativet AUTO_UPDATE_STATISTICS är inställt på ON, omkompileras frågorna när de riktar sig mot tabeller eller indexerade vyer vars statistik har uppdaterats, eller vars kardinaliteter har ändrats betydligt sedan den senaste körningen.
Det här beteendet gäller för användardefinierade standardtabeller, temporära tabeller och de infogade och borttagna tabeller som skapats av DML-utlösare. Om frågeprestanda påverkas av överdriven omkompilering kan du överväga att ändra den här inställningen till OFF. När AUTO_UPDATE_STATISTICS databasalternativet är inställt på OFFsker inga omkompileringar baserat på statistik- eller kardinalitetsändringar, med undantag för de infogade och borttagna tabellerna som skapas av DML INSTEAD OF utlösare. Eftersom dessa tabeller skapas i tempdbberor omkompileringen av frågor som har åtkomst till dem på inställningen för AUTO_UPDATE_STATISTICS i tempdb.
I SQL Server före 2005 fortsätter frågor att kompileras om baserat på kardinalitetsändringar i DML-utlösarens infogade och borttagna tabeller, även när den här inställningen är OFF.
Parametrar och exekveringsplaners återanvändning
Användningen av parametrar, inklusive parametermarkörer i ADO-, OLE DB- och ODBC-program, kan öka återanvändningen av körningsplaner.
Varning
Att använda parametrar eller parametermarkörer för att lagra värden som skrivs av slutanvändare är säkrare än att sammanfoga värdena till en sträng som sedan körs med hjälp av antingen en API-metod för dataåtkomst, EXECUTE-instruktionen eller sp_executesql lagrad procedur.
Den enda skillnaden mellan följande två SELECT-instruktioner är de värden som jämförs i WHERE-satsen:
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Den enda skillnaden mellan körningsplanerna för dessa frågor är värdet som lagras för jämförelsen med kolumnen ProductSubcategoryID. Målet är att SQL Server alltid ska känna igen att uttrycken genererar i stort sett samma plan och återanvänder planerna, men SQL Server identifierar ibland inte detta i komplexa Transact-SQL-instruktioner.
Genom att separera konstanter från Transact-SQL-instruktionen med hjälp av parametrar kan relationsmotorn identifiera duplicerade planer. Du kan använda parametrar på följande sätt:
I Transact-SQL använder du
sp_executesql:DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParmDen här metoden rekommenderas för Transact-SQL skript, lagrade procedurer eller utlösare som genererar SQL-instruktioner dynamiskt.
ADO, OLE DB och ODBC använder parametermarkörer. Parametermarkörer är frågetecken (?) som ersätter en konstant i en SQL-instruktion och är bundna till en programvariabel. Du skulle till exempel göra följande i ett ODBC-program:
Använd
SQLBindParameterför att binda en heltalsvariabel till den första parametermarkören i en SQL-instruktion.Placera heltalsvärdet i variabeln.
Utför uttrycket och ange parametermarkören (?):
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
SQL Server Native Client OLE DB-providern och SQL Server Native Client ODBC-drivrutinen som ingår i SQL Server använder
sp_executesqlför att skicka instruktioner till SQL Server när parametermarkörer används i program.För att utforma lagrade procedurer, som använder parametrar efter design.
Om du inte uttryckligen skapar parametrar i utformningen av dina program kan du också förlita dig på SQL Server Query Optimizer för att automatiskt parametrisera vissa frågor med hjälp av standardbeteendet för enkel parameterisering. Du kan också tvinga frågeoptimeraren att överväga att parameterisera alla frågor i databasen genom att ange alternativet PARAMETERIZATION för ALTER DATABASE-instruktionen till FORCED.
När tvingad parameterisering är aktiverad kan enkel parameterisering fortfarande ske. Följande fråga kan till exempel inte parametriseras enligt reglerna för tvingad parameterisering:
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
Den kan dock parametriseras enligt enkla parameteriseringsregler. När framtvingad parameterisering provas men misslyckas provas fortfarande enkel parameterisering.
Enkel parameterisering
I SQL Server ökar användningen av parametrar eller parametermarkörer i Transact-SQL-instruktioner relationsmotorns möjlighet att matcha nya Transact-SQL-instruktioner med befintliga, tidigare kompilerade körningsplaner.
Varning
Att använda parametrar eller parametermarkörer för att lagra värden som skrivs av slutanvändare är säkrare än att sammanfoga värdena till en sträng som sedan körs med antingen en API-metod för dataåtkomst, EXECUTE-instruktionen eller den sp_executesql lagrade proceduren.
Om en Transact-SQL-instruktion körs utan parametrar parameteriserar SQL Server instruktionen internt för att öka möjligheten att matcha den mot en befintlig körningsplan. Den här processen kallas enkel parameterisering. I SQL Server-versioner före 2005 kallades processen automatisk parameterisering.
Tänk på det här påståendet:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
Värdet 1 i slutet av -instruktionen kan anges som en parameter. Relationsmotorn skapar körningsplanen för den här batchen som om en parameter hade angetts i stället för värdet 1. På grund av den här enkla parameteriseringen identifierar SQL Server att följande två instruktioner genererar i stort sett samma körningsplan och återanvänder den första planen för den andra instruktionen:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Vid bearbetning av komplexa Transact-SQL-instruktioner kan relationsmotorn ha svårt att avgöra vilka uttryck som kan parametriseras. Om du vill öka relationsmotorns förmåga att matcha komplexa Transact-SQL-instruktioner med befintliga, oanvända körningsplaner anger du uttryckligen parametrarna med hjälp av antingen sp_executesql- eller parametermarkörer.
Notis
När +, -, *, /eller % aritmetiska operatorer används för att utföra implicit eller explicit konvertering av int-, smallint-, tinyint- eller bigint-konstantvärden till flödes-, real-, decimal- eller numeriska datatyper, tillämpar SQL Server specifika regler för att beräkna typ och precision för uttrycksresultatet. Dessa regler skiljer sig dock åt beroende på om frågan är parametriserad eller inte. Därför kan liknande uttryck i frågor i vissa fall ge olika resultat.
Under standardbeteendet för enkel parameterisering parameteriserar SQL Server en relativt liten typ av frågor. Du kan dock ange att alla frågor i en databas ska parametriseras, med vissa begränsningar, genom att ange alternativet PARAMETERIZATION för kommandot ALTER DATABASE till FORCED. Detta kan förbättra prestandan för databaser som har stora mängder samtidiga frågor genom att minska frekvensen för frågekompileringar.
Du kan också ange att en enskild fråga, och andra som är syntaktiskt likvärdiga men bara skiljer sig åt i deras parametervärden, ska parametriseras.
Tips
När du använder en ORM-lösning (t.ex. Object-Relational Mapping), såsom Entity Framework (EF), kanske frågor från applikationen som manuella LINQ-frågeträd eller vissa råa SQL-frågor inte parametriseras, vilket påverkar planens återanvändning och möjligheten att spåra frågor i Query Store. Mer information finns i Cachelagring och parameterisering av EF-frågor och råa SQL-frågor.
Tvingad parameterisering
Du kan åsidosätta standardbeteendet för enkel parameterisering för SQL Server genom att ange att alla SELECT, INSERT, UPDATEoch DELETE-instruktioner i en databas ska parametriseras, med vissa begränsningar. Framtvingad parameterisering aktiveras genom att alternativet PARAMETERIZATION ställs in till FORCED i ALTER DATABASE-instruktionen. Tvingad parameterisering kan förbättra prestandan för vissa databaser genom att minska frekvensen för frågekompileringar och omkompileringar. Databaser som kan dra nytta av tvingad parameterisering är vanligtvis de som har stora mängder samtidiga frågor från källor som till exempel program för försäljningsställen.
När alternativet PARAMETERIZATION är inställt på FORCEDkonverteras alla literalvärden som visas i en SELECT, INSERT, UPDATEeller DELETE-instruktion som skickas i valfritt formulär till en parameter under frågekompilering. Undantagen är literaler som visas i följande frågekonstruktioner:
-
INSERT...EXECUTE-uttalanden. - Instruktioner i organen för lagrade procedurer, utlösare eller användardefinierade funktioner. SQL Server återanvänder redan frågeplaner för dessa rutiner.
- Förberedda instruktioner som redan har parametriserats i programmet på klientsidan.
- Instruktioner som innehåller XQuery-metodanrop, där metoden visas i en kontext där dess argument vanligtvis parametriseras, till exempel en
WHERE-sats. Om en metod instansieras i ett sammanhang där dess argument inte är parametriserade, parametriseras resten av uttrycket. - Utsagor inuti en Transact-SQL-kursor. (
SELECT-instruktioner inuti API-markörer parametriseras.) - Inaktuella frågekonstruktioner.
- Alla instruktioner som körs i kontexten för
ANSI_PADDINGellerANSI_NULLSanges tillOFF. - Uttryck som innehåller fler än 2 097 literaler som kan parameteriseras.
- Satser som refererar till variabler, till exempel
WHERE T.col2 >= @bb. - Instruktioner som innehåller
RECOMPILEfrågetips. - Uttalanden som innehåller en
COMPUTE-sats. - Utsagor som innehåller en
WHERE CURRENT OF-sats.
Dessutom parametriseras inte följande frågesatser. I dessa fall är det bara satserna som inte parametriseras. Andra satser i samma fråga kan vara berättigade till tvingad parameterisering.
-
<select_list> av en
SELECT-instruktion. Detta omfattarSELECTlistor över underfrågor ochSELECTlistor iINSERT-satser. - Sats för underfråga
SELECTsom förekommer i enIF-sats. - Satserna
TOP,TABLESAMPLE,HAVING,GROUP BY,ORDER BY,OUTPUT...INTOellerFOR XMLi en fråga. - Argument, antingen direkt eller som underuttryck, till
OPENROWSET,OPENQUERY,OPENDATASOURCE,OPENXMLeller någonFULLTEXT-operatör. - Mönstret och escape_character-argumenten i en
LIKE-sats. - Stilargumentet för en
CONVERT-sats. - Heltalskonstanter i en
IDENTITY-sats. - Konstanter som anges med hjälp av ODBC-tilläggssyntax.
- Konstant vikbara uttryck som är argument för operatorerna
+,-,*,/och%. När du överväger berättigande till tvingad parameterisering anser SQL Server att ett uttryck är konstant vikbart när något av följande villkor är sant:- Inga kolumner, variabler eller underfrågor visas i uttrycket.
- Uttrycket innehåller en
CASE-sats.
- Argument för frågetipsklausuler. Dessa inkluderar argumentet number_of_rows för frågehint
FAST, argumentet number_of_processors för frågehintMAXDOPoch argumentet number för frågehintMAXRECURSION.
Parameterisering sker på nivån för enskilda Transact-SQL-instruktioner. Med andra ord parametriseras enskilda instruktioner i en batch. Efter kompileringen körs en parametriserad fråga i kontexten för batchen där den ursprungligen skickades. Om en körplan för en fråga är cachelagrad kan du avgöra om frågan har parameteriserats genom att hänvisa till sql-kolumnen i den dynamiska hanteringsvyn sys.syscacheobjects. Om en fråga parametriseras kommer namnen och datatyperna för parametrar före texten i den skickade batchen i den här kolumnen, till exempel (@1 tinyint).
Obs
Parameternamn är godtyckliga. Användare eller program bör inte förlita sig på en viss namngivningsordning. Dessutom kan följande ändras mellan versioner av SQL Server- och Service Pack-uppgraderingar: Parameternamn, val av literaler som parametriseras och avståndet i den parametriserade texten.
Datatyper av parametrar
När SQL Server parameteriserar literaler konverteras parametrarna till följande datatyper:
- Heltalsliteraler som passar i int-datatypen parameteriseras till int. Större heltalsliteraler som ingår i predikat som omfattar någon jämförelseoperator (inklusive
<,<=,=,!=,>,>=,!<,!>,<>,ALL,ANY,SOME,BETWEENochIN) parameteriseras till numerisk(38,0). Större literaler som inte är delar av predikat som involverar jämförelseoperatorer parameteriseras till ett numeriskt värde vars precision är precis tillräckligt stor för att stödja sin storlek och vars skala är 0. - Numeriska literaler med fast decimalpunkt som ingår i predikat som omfattar jämförelseoperatorer parametriseras som numeriska med en precision på 38 och vars skala är precis tillräckligt stor för att hantera dess storlek. Numeriska literaler med fast punkt som inte är delar av predikat med jämförelseoperatorer omvandlas till numeriska typer vars precision och skala är precis tillräckligt stora för att rymma deras storlek.
- Flyttalsnumeriska literaler parametriseras till float(53).
- Icke-Unicode-strängliteraler parameteriserar till varchar(8000) om literalen passar inom 8 000 tecken och till varchar(max) om den är större än 8 000 tecken.
- Unicode-strängliteraler parameteriserar till nvarchar(4000) om literalen passar inom 4 000 Unicode-tecken och till nvarchar(max) om literalen är större än 4 000 tecken.
- Binära literaler parametriserar till varbinary(8000) om literalen passar inom 8 000 byte. Om den är större än 8 000 byte konverteras den till varbinary(max).
- Literalvärden av pengatyp parameteriseras till penningtypen.
Riktlinjer för användning av tvingad parameterisering
Tänk på följande när du anger alternativet PARAMETERIZATION till TVINGAD:
- Tvingad parameterisering ändrar i själva verket literalkonstanterna i en fråga till parametrar när en fråga kompileras. Därför kan Frågeoptimeraren välja suboptimala planer för frågor. I synnerhet är det mindre troligt att frågeoptimeraren matchar frågan med en indexerad vy eller ett index i en beräknad kolumn. Den kan också välja suboptimala planer för frågor som ställs i partitionerade tabeller och distribuerade partitionerade vyer. Tvingad parameterisering bör inte användas för miljöer som är starkt beroende av indexerade vyer och index på beräknade kolumner. I allmänhet bör det
PARAMETERIZATION FORCEDalternativet endast användas av erfarna databasadministratörer när du har fastställt att detta inte påverkar prestanda negativt. - Distribuerade frågor som refererar till mer än en databas är berättigade till tvingad parameterisering så länge som alternativet
PARAMETERIZATIONär inställt påFORCEDi databasen vars kontext frågan körs. - Om du anger alternativet
PARAMETERIZATIONtillFORCEDrensas alla frågeplaner från plancachen för en databas, förutom de som för närvarande kompilerar, omkompilerar eller kör. Planer för frågor som kompileras eller körs under inställningsändringen parametriseras nästa gång frågan körs. - Att ange alternativet
PARAMETERIZATIONär en onlineåtgärd som inte kräver några exklusiva lås på databasnivå. - Den aktuella inställningen för alternativet
PARAMETERIZATIONbevaras när du kopplar om eller återställer en databas.
Du kan åsidosätta beteendet för tvingad parameterisering genom att ange att enkel parameterisering ska utföras på en enda fråga och andra som är syntaktiskt likvärdiga men bara skiljer sig åt i sina parametervärden. Däremot kan du ange att tvingad parameterisering endast ska utföras på en uppsättning syntaktiskt likvärdiga frågor, även om tvingad parameterisering är inaktiverad i databasen. Planeringsguider används för detta ändamål.
Notera
När alternativet PARAMETERIZATION är inställt på FORCEDkan rapporteringen av felmeddelanden skilja sig från när alternativet PARAMETERIZATION är inställt på SIMPLE: flera felmeddelanden kan rapporteras under tvingad parameterisering, där färre meddelanden rapporteras under enkel parameterisering och radnumren där fel inträffar kan rapporteras felaktigt.
Förbereda SQL-instruktioner
SQL Server-relationsmotorn ger fullständigt stöd för att förbereda Transact-SQL-instruktioner innan de körs. Om ett program måste köra en Transact-SQL-instruktion flera gånger kan det använda databas-API:et för att göra följande:
- Förbered uttalandet en gång. Detta kompilerar Transact-SQL-instruktionen till en exekveringsplan.
- Kör den förkompilerade planen varje gång den måste utföra instruktionen. Detta förhindrar att du behöver kompilera om Transact-SQL-instruktionen för varje körning efter första gången. Förberedelse och körning av instruktioner styrs av API-funktioner och -metoder. Det är inte en del av språket Transact-SQL. Modellen för att förbereda/utföra Transact-SQL-instruktioner stöds av SQL Server Native Client OLE DB Provider och SQL Server Native Client ODBC-drivrutinen. På en förberedelsebegäran skickar antingen providern eller drivrutinen uttalandet till SQL Server med en begäran om att förbereda det. SQL Server kompilerar en körningsplan och returnerar ett handtag för planen till providern eller drivrutinen. Vid en körningsbegäran skickar antingen providern eller drivrutinen en begäran till servern om att köra planen som är associerad med handtaget.
Förberedda instruktioner kan inte användas för att skapa temporära objekt på SQL Server. Förberedda instruktioner kan inte referera till system lagrade procedurer som skapar temporära objekt, till exempel temporära tabeller. Dessa procedurer måste köras direkt.
Överdriven användning av modellen prepare/execute kan försämra prestandan. Om en instruktion endast körs en gång kräver en direkt körning endast en tur-och-retur-resa till servern. Att förbereda och köra en Transact-SQL-instruktion som exekveras endast en gång kräver en extra nätverksresa: en resa för att förbereda instruktionen och en för att exekvera den.
Det är effektivare att förbereda en instruktion om parametermarkörer används. Anta till exempel att ett program ibland uppmanas att hämta produktinformation från AdventureWorks exempeldatabas. Det finns två sätt för programmet att göra detta.
Med det första sättet kan programmet köra en separat fråga för varje begärd produkt:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
Med det andra sättet gör programmet följande:
Förbereder en instruktion som innehåller en parametermarkör (?):
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;Binder en programvariabel till parametermarkören.
Varje gång produktinformation behövs, fylls den bundna variabeln med nyckelvärdet och instruktionen körs.
Det andra sättet är effektivare när uttalandet utförs fler än tre gånger.
I SQL Server har modellen prepare/execute ingen betydande prestandafördel jämfört med direkt körning på grund av hur SQL Server återanvänder körningsplaner. SQL Server har effektiva algoritmer för matchning av aktuella Transact-SQL-instruktioner med körningsplaner som genereras för tidigare körningar av samma Transact-SQL-instruktion. Om ett program kör en Transact-SQL-instruktion med parametermarkörer flera gånger återanvänder SQL Server körningsplanen från den första körningen för den andra och efterföljande körningen (såvida inte planen åldras från plancachen). Modellen prepare/execute har fortfarande följande fördelar:
- Det är effektivare att hitta en körningsplan med en identifierande referens än de algoritmer som används för att matcha en Transact-SQL-instruktion med befintliga körningsplaner.
- Programmet kan styra när körningsplanen skapas och när den återanvänds.
- Modellen prepare/execute är portabel för andra databaser, inklusive tidigare versioner av SQL Server.
Parameterkänslighet
Parameterkänslighet, även kallat "parametersniffning", refererar till en process där SQL Server "sniffar" de aktuella parametervärdena under kompilering eller omkompilering och skickar dem till Frågeoptimeraren så att de kan användas för att generera potentiellt effektivare frågekörningsplaner.
Parametervärden sniffas under kompilering eller omkompilering för följande typer av batchar:
- Lagrade procedurer
- Frågor som skickas via
sp_executesql - Förberedda frågor
Mer information om felsökning av problem med felaktig parametersniffning finns i:
- Undersöka och lösa parameterkänsliga problem
- Parametrar och återanvändning av körningsplan
- optimering av parameterkänslig plan
- Felsöka frågor med problem med parameterkänslig frågekörningsplan i Azure SQL Database
- Felsöka frågor med problem i exekveringsplaner för parameterkänsliga frågor i Azure SQL Managed Instance
Not
För frågor som använder RECOMPILE-ledtråd, analyseras både parametervärden och aktuella värden för lokala variabler. De värden som sniffas (av parametrar och lokala variabler) är de som finns i batchen på platsen precis före instruktionen med RECOMPILE ledtråd. I synnerhet för parametrar sniffas inte de värden som medföljer batchanropet.
Parallell frågebearbetning
SQL Server tillhandahåller parallella frågor för att optimera frågekörnings- och indexåtgärder för datorer som har mer än en mikroprocessor (CPU). Eftersom SQL Server kan utföra en fråge- eller indexåtgärd parallellt med hjälp av flera operativsystemsarbetstrådar kan åtgärden slutföras snabbt och effektivt.
Under frågeoptimering letar SQL Server efter frågor eller indexåtgärder som kan dra nytta av parallell körning. För dessa frågor infogar SQL Server exchange-operatorer i frågekörningsplanen för att förbereda frågan för parallell körning. En utbytesoperator är en operator i en frågeexekveringsplan som tillhandahåller processhantering, omfördelning av data och flödeskontroll. Exchange-operatorn innehåller Distribute Streams, Repartition Streamsoch Gather Streams logiska operatorer som undertyper, varav en eller flera kan visas i Showplan-utdata från en frågeplan för en parallell fråga.
Viktig
Vissa konstruktioner hindrar SQL Server från att använda parallellitet i hela verkställandeplanen eller delar av verkställandeplanen.
Konstruktioner som hämmar parallellitet är:
skalära UDF:er
Mer information om skalära användardefinierade funktioner finns i Skapa användardefinierade funktioner. Från och med SQL Server 2019 (15.x) har SQL Server Database Engine möjlighet att infoga dessa funktioner och låsa upp användningen av parallellitet under frågebearbetningen. Mer information om skalbar UDF-inlining finns i Intelligent frågebearbetning i SQL-databaser.Fjärrfråga
Mer information om Remote Query finns i Showplan Referens för logiska och fysiska operatorer.dynamiska markörer
Mer information om markörer finns i DECLARE CURSOR.Rekursiva frågor
Mer information om rekursion finns i Riktlinjer för att definiera och använda rekursiva gemensamma tabelluttryck och Rekursion i T-SQL.Flervärdeskodfunktioner (mstvf)
Mer information om MSTVFs finns i Create User-defined Functions (Database Engine).TOP-nyckelordet
Mer information finns i TOP (Transact-SQL).
En frågekörningsplan kan innehålla attributet NonParallelPlanReason i elementet QueryPlan, som beskriver varför parallellitet inte användes. Värden för det här attributet är:
| NonParallelPlanReason-värde | Beskrivning |
|---|---|
| MaxDOPSetToOne | Maximal grad av parallellitet inställd på 1. |
| Beräknad DOP är ett | Uppskattad grad av parallellitet är 1. |
| Ingen parallell med fjärrfråga | Parallellitet stöds inte för fjärrfrågor. |
| NoParallelDynamicCursor | Parallella planer stöds inte för dynamiska markörer. |
| NoParallelFastForwardCursor | Parallella planer stöds inte för snabbåtkomstmarkörer. |
| Ingen Parallell Markörhämtning Med Bokmärke | Parallella planer stöds inte för markörer som hämtar efter bokmärke. |
| IngenParallelSkapaIndexINonEnterpriseEdition | Parallell indexskapande stöds inte för icke-Enterprise-utgåva. |
| IngaParallellaPlanerIDesktopEllerExpressEdition | Parallella planer stöds inte för Desktop och Express Edition. |
| Icke-parallelliserbarInneboendeFunktion | Frågan refererar till en inbyggda funktion som inte kan parallelliseras. |
| CLRAnvändardefinieradFunktionKräverDataÅtkomst | Parallellitet stöds inte för en CLR UDF som kräver dataåtkomst. |
| TSQLAnvändardefinieradeFunktionerInteParallelliserbara | Frågan refererar till en användardefinierad T-SQL-funktion som inte kunde parallelliseras. |
| Tabellvariabeltransaktioner stöder inte parallella nästlade transaktioner | Tabellvariabeltransaktioner stöder inte parallella kapslade transaktioner. |
| DMLQueryReturnsOutputToClient | DML-frågan returnerar utdata till klienten och kan inte parallelliseras. |
| BlandadSeriellOchParallellOnlinIndexByggnadEjStödd | En blandning av serie- och parallella planer för en enda onlineindexuppbyggnad stöds inte. |
| KundeInteGenereraGiltigParallellPlan | Det gick inte att verifiera den parallella planen och gick inte tillbaka till seriellt. |
| Ingen parallellisering för minnesoptimerade tabeller | Parallellitet stöds inte för refererade In-Memory OLTP-tabeller. |
| NoParallelForDmlPåMinnesoptimeradTabell | Parallellitet stöds inte för DML i en In-Memory OLTP-tabell. |
| NoParallelForNativelyCompiledModule | Parallellitet stöds inte för refererade nativt kompilerade moduler. |
| NoRangesÅterupptagbarSkapa | Intervallgenereringen misslyckades för en återupptagbar skapandeoperation. |
När exchange-operatorerna har infogats är resultatet en exekveringsplan för parallella frågor. En körningsplan för parallella frågor kan använda mer än en arbetstråd. En seriell körningsplan som används av en icke-parallell fråga (seriell) använder endast en arbetstråd för körningen. Det faktiska antalet arbetstrådar som används av en parallell fråga bestäms vid initiering av frågeplankörning och bestäms av planens komplexitet och graden av parallellitet.
Grad av parallellitet (DOP) avgör det maximala antalet processorer som används. Det betyder inte antalet arbetstrådar som används. DOP-gränsen anges för uppgift. Det är inte ett gräns per begäran eller per förfrågan. Det innebär att under en parallell frågekörning kan en enskild begäran skapa flera uppgifter som har tilldelats till en schemaläggaren. Fler processorer än vad som anges av MAXDOP kan användas samtidigt vid en viss tidpunkt för frågekörning, när olika uppgifter körs samtidigt. Mer information finns i tråd- och aktivitetsarkitekturguiden.
SQL Server Query Optimizer använder inte en parallell körningsplan för en fråga om något av följande villkor är sant:
- Den seriella körningsplanen är trivial eller överskrider inte kostnadströskelvärdet för parallellitetsinställningen.
- Den seriella körningsplanen har en lägre total uppskattad delträdskostnad än någon parallell körningsplan som utforskas av optimeraren.
- Frågan innehåller skalär- eller relationsoperatorer som inte kan köras parallellt. Vissa operatorer kan orsaka att ett avsnitt i frågeplanen körs i serieläge eller att hela planen körs i serieläge.
Obs
Den totala uppskattade kostnaden för underträd för en parallell plan kan vara lägre än kostnadströskelvärdet för parallellitetsinställning. Detta indikerar att den totala uppskattade underträdskostnaden för serieplanen överskred den och att frågeplanen med den lägre totala uppskattade underträdskostnaden valdes.
Grad av parallellitet (DOP)
SQL Server identifierar automatiskt den bästa graden av parallellitet för varje instans av en parallell frågekörning eller en DDL-åtgärd (Index Data Definition Language). Den gör detta baserat på följande kriterier:
Om SQL Server körs på en dator som har mer än en mikroprocessor eller processor, till exempel en symmetrisk multiprocessdator (SMP). Endast datorer som har mer än en PROCESSOR kan använda parallella frågor.
Om tillräckligt med arbetstrådar är tillgängliga. Varje fråga eller indexåtgärd kräver ett visst antal arbetstrådar för att köras. Att köra en parallell plan kräver fler arbetstrådar än en seriell plan, och antalet obligatoriska arbetstrådar ökar med graden av parallellitet. När kravet på arbetstråd i den parallella planen för en viss grad av parallellitet inte kan uppfyllas, minskar SQL Server Database Engine graden av parallellitet automatiskt eller helt överger den parallella planen i den angivna arbetsbelastningskontexten. Sedan kör den det seriella programmet (en arbetstråd).
Den typen av fråge- eller indexåtgärd som körs. Indexåtgärder som skapar eller återskapar ett index eller släpper ett klustrat index och frågor som använder CPU-cykler är de bästa kandidaterna för en parallell plan. Till exempel är kopplingar till stora tabeller, stora aggregeringar och sortering av stora resultatuppsättningar bra kandidater. I enkla frågor, som ofta förekommer i transaktionsbearbetningsprogram, överstiger den ytterligare samordning som krävs för att köra en fråga parallellt den potentiella prestandaökningen. För att skilja mellan frågor som drar nytta av parallellitet och de som inte gynnas jämför SQL Server Database Engine den uppskattade kostnaden för att köra fråge- eller indexåtgärden med kostnadströskel för parallellitet värde. Användare kan ändra standardvärdet 5 med hjälp av sp_configure om rätt testning visar att ett annat värde passar bättre för den arbetsbelastning som körs.
Om det finns tillräckligt många rader för att bearbeta. Om frågeoptimeraren bedömer att antalet rader är för lågt introducerar det inte exchange-operatorer för att distribuera raderna. Därför körs operatorerna seriellt. Att köra operatorerna i en serieplan undviker scenarier när start-, distributions- och samordningskostnaderna överskrider de vinster som uppnås vid parallell operatörskörning.
Om aktuell distributionsstatistik är tillgänglig. Om den högsta graden av parallellitet inte är möjlig beaktas lägre grader innan den parallella planen överges. När du till exempel skapar ett grupperat index i en vy kan distributionsstatistik inte utvärderas eftersom det klustrade indexet ännu inte finns. I det här fallet kan SQL Server Database Engine inte tillhandahålla den högsta graden av parallellitet för indexåtgärden. Vissa operatorer, till exempel sortering och genomsökning, kan dock fortfarande dra nytta av parallell körning.
Note
Parallella indexåtgärder är endast tillgängliga i SQL Server Enterprise-, Utvecklar- och utvärderingsversioner.
Vid körningen avgör SQL Server Database Engine om den aktuella systemarbetsbelastningen och konfigurationsinformationen som beskrevs tidigare tillåter parallell körning. Om parallell körning är berättigad avgör SQL Server Database Engine det optimala antalet arbetstrådar och sprider körningen av den parallella planen över dessa arbetstrådar. När en fråge- eller indexåtgärd börjar köras på flera arbetstrådar för parallell körning används samma antal arbetstrådar tills åtgärden har slutförts. SQL Server Database Engine omvärderar det optimala antalet arbetstrådar varje gång en körningsplan hämtas från plancachen. Till exempel kan en körning av en fråga resultera i användning av en serieplan, en senare körning av samma fråga kan resultera i en parallell plan med tre arbetstrådar, och en tredje körning kan resultera i en parallell plan med fyra arbetstrådar.
Uppdaterings- och borttagningsoperatorerna i en parallell frågekörningsplan körs seriellt, men WHERE-satsen i en UPDATE- eller DELETE-instruktion kan köras parallellt. De faktiska dataändringarna tillämpas sedan seriellt på databasen.
Fram till SQL Server 2012 (11.x) körs även infogningsoperatorn seriellt. Select-delen av en INSERT-instruktion kan dock köras parallellt. De faktiska dataändringarna tillämpas sedan seriellt på databasen.
Från och med SQL Server 2014 (12.x) och databaskompatibilitetsnivå 110 kan SELECT ... INTO-instruktionen köras parallellt. Andra former av infogningsoperatorer fungerar på samma sätt som beskrivs för SQL Server 2012 (11.x).
Från och med SQL Server 2016 (13.x) och databaskompatibilitetsnivå 130 kan INSERT ... SELECT-instruktionen köras parallellt när du infogar i heaps eller klustrade kolumnlagringsindex (CCI) och använder TABLOCK-tipset. Infogningar i lokala temporära tabeller (identifieras av #-prefixet) och globala temporära tabeller (identifieras av ##-prefix) aktiveras också för parallellitet med hjälp av TABLOCK-tipset. Mer information finns i INSERT (Transact-SQL).
Statiska och keyset-drivna markörer kan fyllas i med parallella exekveringsplaner. Beteendet för dynamiska markörer kan dock endast uppnås genom sekventiell exekvering. Frågeoptimeraren genererar alltid en seriell exekveringsplan för en fråga som ingår i en dynamisk pekare.
Åsidosätt parallellitetsgrader
Graden av parallellitet anger antalet processorer som ska användas vid parallell plankörning. Den här konfigurationen kan ställas in på olika nivåer:
Servernivå med hjälp av max grad av parallellitet (MAXDOP)serverkonfigurationsalternativet.
gäller för: SQL ServerNote
SQL Server 2019 (15.x) introducerar automatiska rekommendationer för att ange konfigurationsalternativet MAXDOP-server under installationsprocessen. Med installationsanvändargränssnittet kan du antingen acceptera de rekommenderade inställningarna eller ange ditt eget värde. Mer information finns i Database Engine Configuration – MaxDOP-sidan.
Arbetsbelastningsnivå med hjälp av konfigurationsalternativet MAX_DOPResource Governor-arbetsbelastningsgrupp.
gäller för: SQL ServerDatabasnivå med hjälp av konfigurationen MAXDOPdatabasomfattning.
gäller för: SQL Server och Azure SQL DatabaseFråge- eller indexuttrycksnivå med hjälp av MAXDOP-frågehint eller MAXDOP indexalternativ. Du kan till exempel använda alternativet MAXDOP för att kontrollera, genom att öka eller minska, antalet processorer som är dedikerade till en online-indexåtgärd. På så sätt kan du balansera de resurser som används av en indexåtgärd med de samtidiga användarnas.
gäller för: SQL Server och Azure SQL Database
Om du anger alternativet för maximal parallellitet till 0 (standard) kan SQL Server använda alla tillgängliga processorer upp till högst 64 processorer i en parallell plankörning. Även om SQL Server anger ett körningsmål på 64 logiska processorer när MAXDOP-alternativet är inställt på 0, kan ett annat värde anges manuellt om det behövs. Genom att ange MAXDOP till 0 för frågor och index kan SQL Server använda alla tillgängliga processorer upp till högst 64 processorer för de aktuella frågorna eller indexen i en parallell plankörning. MAXDOP är inte ett framtvingat värde för alla parallella frågor, utan snarare ett preliminärt mål för alla frågor som är berättigade till parallellitet. Det innebär att om det inte finns tillräckligt med arbetstrådar tillgängliga vid körning kan en fråga köras med en lägre grad av parallellitet än konfigurationsalternativet FÖR MAXDOP-servern.
Tips
Mer information finns i MAXDOP-rekommendationer för riktlinjer för att konfigurera MAXDOP på server-, databas-, fråge- eller tipsnivå.
Exempel på parallell fråga
Följande fråga räknar antalet beställningar som gjorts under ett visst kvartal, med början den 1 april 2000, och där minst en rad i ordern togs emot av kunden senare än det bekräftade datumet. Den här frågan visar antalet sådana beställningar grupperade efter varje orderprioritet och sorterade i stigande prioritetsordning.
I det här exemplet används teoretiska tabell- och kolumnnamn.
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
Anta att följande index har definierats i tabellerna lineitem och orders:
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
Här är en möjlig parallell plan som genererats för frågan som visades tidigare:
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
Bilden nedan visar en frågeplan som körs med en parallellitet på 4 och som involverar en koppling mellan två tabeller.
Den parallella planen innehåller tre parallellitetsoperatorer. Både indexsökningsoperatorn för o_datkey_ptr-indexet och indexgenomsökningsoperatorn för l_order_dates_idx index utförs parallellt. Detta ger flera exklusiva strömmar. Detta kan fastställas från närmaste parallellitetsoperatorer ovanför operatorerna Indexsökning respektive Indexsökning. Båda partitionerar om typen av utbyte. Det vill sa att de bara omdelar data mellan strömmarna och producerar samma antal strömmar på sina utdata som de har på sina indata. Det här antalet strömmar är lika med graden av parallellitet.
Parallellitetsoperatorn ovanför operatorn l_order_dates_idx Index Scan partitionerar om sina indataströmmar med värdet L_ORDERKEY som en nyckel. På så sätt hamnar samma värden för L_ORDERKEY i samma utdataström. Samtidigt bibehåller utdataströmmar ordningen på kolumnen L_ORDERKEY för att säkerställa att indatakravet för operatorn Merge Join uppfylls.
Parallellitetsoperatorn ovanför indexsökningsoperatorn partitionerar om sina indataströmmar med hjälp av värdet för O_ORDERKEY. Eftersom dess indata inte är sorterade efter kolumnvärdena O_ORDERKEY, och detta är kopplingskolumnen i sammanfogningsoperatorn Merge Join, säkerställer Sorteringsoperatorn mellan parallellitet och Merge Join att indata sorteras korrekt för Merge Join-operatorn på kopplingskolumnerna. Operatorn Sort, till exempel merge join-operatorn, utförs parallellt.
Den översta parallellitetsoperatorn samlar in resultat från flera strömmar till en enda ström. Partiella aggregeringar som utförs av Stream Aggregate-operatorn under parallellitetsoperatorn ackumuleras sedan till ett enda SUM värde för varje värde för O_ORDERPRIORITY i Stream Aggregate-operatorn ovanför parallellismoperatorn. Eftersom den här planen har två bytesegment, med grad av parallellitet lika med 4, använder den åtta arbetstrådar.
Mer information om operatorerna som används i det här exemplet finns i referensen Showplan Logiska och fysiska operatorer.
Parallella indexåtgärder
Frågeplanerna som skapats för indexåtgärder som skapar eller återskapar ett index, eller släpper ett klustrat index, möjliggör parallella, trådade åtgärder för flera arbetare på datorer som har flera mikroprocessorer.
Anteckning
Parallella indexåtgärder är endast tillgängliga i Enterprise Edition, från och med SQL Server 2008 (10.0.x).
SQL Server använder samma algoritmer för att fastställa graden av parallellitet (det totala antalet separata arbetstrådar som ska köras) för indexåtgärder som för andra frågor. Den maximala graden av parallellitet för en indexåtgärd omfattas av alternativet maximal grad av parallellitet serverkonfiguration. Du kan åsidosätta den maximala graden av parallellitetsvärde för enskilda indexåtgärder genom att ange alternativet MAXDOP-index i satserna CREATE INDEX, ALTER INDEX, DROP INDEX och ALTER TABLE.
När SQL Server Database Engine skapar en indexkörningsplan anges antalet parallella åtgärder till det lägsta värdet bland följande:
- Antalet mikroprocessorer eller processorer i datorn.
- Talet som anges i konfigurationsalternativet för den maximala graden av parallellitetsserver.
- Antalet processorer som inte redan överskrider ett tröskelvärde för arbete som utförs för SQL Server-arbetstrådar.
Till exempel på en dator som har åtta processorer, men där maximal grad av parallellitet är inställd på 6, genereras inte mer än sex parallella arbetstrådar för en indexåtgärd. Om fem av processorerna på datorn överskrider tröskelvärdet för SQL Server-arbete när en indexkörningsplan skapas anger körningsplanen endast tre parallella arbetstrådar.
Huvudfaserna i en parallell indexåtgärd omfattar följande:
- En koordinerande arbetstråd söker snabbt och slumpmässigt igenom tabellen för att beräkna fördelningen av indexnycklarna. Den koordinerande arbetstråden upprättar de nyckelgränser som skapar ett antal nyckelintervall som är lika med graden av parallella åtgärder, där varje nyckelintervall beräknas täcka liknande antal rader. Om det till exempel finns fyra miljoner rader i tabellen och graden av parallellitet är 4, avgör den koordinerande arbetstråden de nyckelvärden som avgränsar fyra uppsättningar rader med 1 miljon rader i varje uppsättning. Om det inte går att upprätta tillräckligt många nyckelintervall för att använda alla processorer minskas graden av parallellitet i enlighet med detta.
- Den koordinerande arbetstråden skickar ett antal arbetstrådar som är lika med antalet parallella processer och väntar på att dessa arbetstrådar ska slutföra sitt arbete. Varje arbetstråd söker igenom bastabellen med ett filter som endast hämtar rader med nyckelvärden inom det intervall som tilldelats till arbetstråden. Varje arbetstråd skapar en indexstruktur för raderna i dess nyckelintervall. När det gäller ett partitionerat index skapar varje arbetstråd ett angivet antal partitioner. Partitioner är inte delade mellan arbetstrådar.
- När alla parallella arbetstrådar har slutförts ansluter den koordinerande arbetstråden indexunderenheterna till ett enda index. Den här fasen gäller endast för offlineindexåtgärder.
Enskilda CREATE TABLE- eller ALTER TABLE-instruktioner kan ha flera begränsningar som kräver att ett index skapas. Dessa åtgärder för att skapa flera index utförs i serie, även om varje enskild åtgärd för att skapa index kan vara en parallell åtgärd på en dator som har flera processorer.
Arkitektur för distribuerad frågehantering
Microsoft SQL Server stöder två metoder för att referera till heterogena OLE DB-datakällor i Transact-SQL-instruktioner:
Länkade servernamn
System lagrade procedurersp_addlinkedserverochsp_addlinkedsrvloginanvänds för att ge ett servernamn till en OLE DB-datakälla. Objekt på dessa länkade servrar kan refereras i Transact-SQL-instruktioner med hjälp av namn i fyra delar. Om till exempel ett länkat servernamn förDeptSQLSrvrdefinieras mot en annan instans av SQL Server refererar följande instruktion till en tabell på servern:SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;Det länkade servernamnet kan också anges i en
OPENQUERY-instruktion för att öppna en raduppsättning från OLE DB-datakällan. Den här raduppsättningen kan sedan refereras som en tabell i Transact-SQL-instruktioner.Namn på ad hoc-anslutningar
För ovanliga referenser till en datakälla anges funktionernaOPENROWSETellerOPENDATASOURCEmed den information som behövs för att ansluta till den länkade servern. Raduppsättningen kan sedan refereras till på samma sätt som en tabell refereras till i Transact-SQL-instruktioner:SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
SQL Server använder OLE DB för att kommunicera mellan relationsmotorn och lagringsmotorn. Relationsmotorn delar upp varje Transact-SQL-instruktion i en serie åtgärder på enkla OLE DB-raduppsättningar som lagringsmotorn öppnar från bastabellerna. Det innebär att relationsmotorn också kan öppna enkla OLE DB-raduppsättningar på valfri OLE DB-datakälla.
Relationsmotorn använder API :et (OLE DB Application Programming Interface) för att öppna raduppsättningarna på länkade servrar, hämta raderna och hantera transaktioner.
För varje OLE DB-datakälla som används som en länkad server måste en OLE DB-provider finnas på servern som kör SQL Server. Vilken uppsättning Transact-SQL åtgärder som kan användas mot en specifik OLE DB-datakälla beror på funktionerna hos OLE DB-providern.
För varje instans av SQL Server kan medlemmar i den sysadmin fasta serverrollen aktivera eller inaktivera användningen av ad hoc-anslutningsnamn för en OLE DB-provider med hjälp av egenskapen SQL Server DisallowAdhocAccess. När ad hoc-åtkomst är aktiverat kan alla användare som är inloggade på den instansen köra Transact-SQL-instruktioner som innehåller ad hoc-anslutningsnamn och referera till alla datakällor i nätverket som kan nås med hjälp av OLE DB-providern. För att styra åtkomsten till datakällor kan medlemmar i den sysadmin rollen inaktivera ad hoc-åtkomst för den OLE DB-providern, vilket begränsar användarna till endast de datakällor som refereras till av länkade servernamn som definierats av administratörerna. Som standard är ad hoc-åtkomst aktiverad för SQL Server OLE DB-providern och inaktiverad för alla andra OLE DB-leverantörer.
Distribuerade frågor kan tillåta användare att komma åt en annan datakälla (till exempel filer, icke-relationella datakällor som Active Directory och så vidare) med hjälp av säkerhetskontexten för Det Microsoft Windows-konto som SQL Server-tjänsten körs under. SQL Server personifierar inloggningen korrekt för Windows-inloggningar. Det är dock inte möjligt för SQL Server-inloggningar. Detta kan potentiellt göra det möjligt för en distribuerad frågeanvändare att komma åt en annan datakälla som de inte har behörighet för, men det konto under vilket SQL Server-tjänsten körs har behörigheter. Använd sp_addlinkedsrvlogin för att definiera de specifika inloggningar som har behörighet att komma åt motsvarande länkade server. Den här kontrollen är inte tillgänglig för ad hoc-namn, så var försiktig när du aktiverar en OLE DB-provider för ad hoc-åtkomst.
När det är möjligt, för SQL Server över relationsoperationer som sammanfogningar, begränsningar, projektioner, sorteringar och grupperingsåtgärder till OLE DB-datakällan. SQL Server söker inte som standard in bastabellen i SQL Server och utför själva relationsåtgärderna. SQL Server frågar OLE DB-providern för att fastställa vilken sql-grammatik som den stöder och skickar, baserat på den informationen, så många relationsåtgärder som möjligt till providern.
SQL Server anger en mekanism för en OLE DB-provider för att returnera statistik som anger hur nyckelvärden distribueras i OLE DB-datakällan. På så sätt kan SQL Server Query Optimizer bättre analysera datamönstret i datakällan utifrån kraven på varje Transact-SQL-instruktion, vilket ökar möjligheten att generera optimala körningsplaner.
Förbättringar av frågebearbetning i partitionerade tabeller och index
SQL Server 2008 (10.0.x) förbättrade frågebearbetningsprestanda för partitionerade tabeller för många parallella planer, ändrar hur parallella planer och serieplaner representeras och förbättrade partitioneringsinformationen i både kompilerings- och körningsplaner. Den här artikeln beskriver dessa förbättringar, ger vägledning om hur du tolkar frågekörningsplanerna för partitionerade tabeller och index och innehåller metodtips för att förbättra frågeprestanda för partitionerade objekt.
Not
Fram till SQL Server 2014 (12.x) stöds partitionerade tabeller och index endast i versionerna SQL Server Enterprise, Developer och Evaluation. Från och med SQL Server 2016 (13.x) SP1 stöds även partitionerade tabeller och index i SQL Server Standard Edition.
Ny partitionsmedveten sökåtgärd
I SQL Server ändras den interna representationen av en partitionerad tabell så att tabellen visas för frågeprocessorn som ett multikollumnindex med PartitionID som inledande kolumn.
PartitionID är en dold beräknad kolumn som används internt för att representera ID för partitionen som innehåller en viss rad. Anta till exempel att tabellen T, som definierats som T(a, b, c), är partitionerad i kolumn a och har ett grupperat index på kolumn b. I SQL Server behandlas den här partitionerade tabellen internt som en icke-partitionerad tabell med schemat T(PartitionID, a, b, c) och ett klustrat index på den sammansatta nyckeln (PartitionID, b). På så sätt kan frågeoptimeraren utföra sökåtgärder baserat på PartitionID på alla partitionerade tabeller eller index.
Partitionseliminering utförs nu i denna sökoperation.
Dessutom utökas Frågeoptimeraren så att en sök- eller genomsökningsåtgärd med ett villkor kan utföras på PartitionID (som den logiska inledande kolumnen) och eventuellt andra indexnyckelkolumner, och sedan kan en sökning på andra nivån, med ett annat villkor, göras på en eller flera ytterligare kolumner för varje distinkt värde som uppfyller kvalificeringen för sökåtgärden på första nivån. Med den här åtgärden, som kallas för en snabbsökning, kan frågeoptimeraren utföra en sök- eller genomsökningsåtgärd baserat på ett villkor för att fastställa vilka partitioner som ska nås och en indexsökningsåtgärd på andra nivån inom operatorn för att returnera rader från dessa partitioner som uppfyller ett annat villkor. Tänk till exempel på följande fråga.
SELECT * FROM T WHERE a < 10 and b = 2;
I det här exemplet förutsätter du att tabell T, definierad som T(a, b, c), är partitionerad i kolumn a och har ett grupperat index på kolumn b. Partitionsgränserna för tabell T definieras av följande partitionsfunktion:
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
För att lösa frågan utför frågeprocessorn en sökåtgärd på första nivån för att hitta varje partition som innehåller rader som uppfyller villkoret T.a < 10. Detta identifierar de partitioner som ska nås. I varje partition som identifieras utför processorn sedan en sökning på andra nivån i det klustrade indexet på kolumn b för att hitta de rader som uppfyller villkoret T.b = 2 och T.a < 10.
Följande illustration är en logisk representation av skip scan-operationen. Den visar tabell T med data i kolumner a och b. Partitionerna numreras 1 till 4 med de partitionsgränser som visas av streckade lodräta linjer. En sökåtgärd på första nivån till partitionerna (visas inte i bilden) har fastställt att partitionerna 1, 2 och 3 uppfyller sökvillkoret som anges av partitioneringen som definierats för tabellen och predikatet för kolumnen a. Det vill säga T.a < 10. Sökvägen som korsas av sökdelen på den andra nivån i skip-genomsökningsåtgärden illustreras av den böjda linjen. Skip scan-operationen söker i varje partition efter rader som möter villkoret b = 2. Den totala kostnaden för "skip scan"-operationen är densamma som för tre separata indexsökningar.
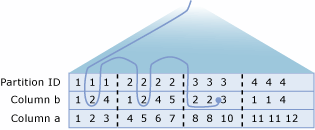
Visa partitioneringsinformation i frågekörningsplaner
Körningsplanerna för frågor i partitionerade tabeller och index kan undersökas med hjälp av Transact-SQL SET-instruktioner SET SHOWPLAN_XML eller SET STATISTICS XML, eller med hjälp av den grafiska körningsplanens utdata i SQL Server Management Studio. Du kan till exempel visa kompileringsplanen genom att välja Visa uppskattad exekveringsplan i verktygsfältet för frågeredigeraren och exekveringsplanen vid körning genom att välja Inkludera verklig exekveringsplan.
Med hjälp av dessa verktyg kan du kontrollera följande information:
- Åtgärder som
scans,seeks,inserts,updates,mergesochdeletessom har åtkomst till partitionerade tabeller eller index. - De partitioner som nås av frågan. Till exempel är det totala antalet partitioner som används och intervallen för sammanhängande partitioner som nås tillgängliga i körningsplaner.
- När åtgärden hoppa över genomsökningen används i en sök- eller genomsökningsåtgärd för att hämta data från en eller flera partitioner.
Förbättringar av partitionsinformation
SQL Server tillhandahåller förbättrad partitioneringsinformation för både kompileringstidens och körningens exekveringsplaner. Körningsplanerna innehåller nu följande information:
- Ett valfritt
Partitioned-attribut som anger att en operator, till exempel enseek,scan,insert,update,mergeellerdelete, utförs i en partitionerad tabell. - Ett nytt
SeekPredicateNew-element med ettSeekKeys-underelement som innehållerPartitionIDsom den inledande indexnyckelkolumnen och filtervillkor som specificerar intervallsökningar påPartitionID. Förekomsten av tvåSeekKeysunderelement indikerar att en snabbsökningsåtgärd påPartitionIDanvänds. - Sammanfattningsinformation som ger totalt antal partitioner som används. Den här informationen är endast tillgänglig i körningstidsplaner.
Om du vill visa hur den här informationen visas i både den grafiska körningsplanens utdata och XML Showplan-utdata bör du överväga följande fråga i den partitionerade tabellen fact_sales. Den här frågan uppdaterar data i två partitioner.
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
Följande bild visar egenskaperna för Clustered Index Seek-operatorn i körexekveringsplanen för den här frågeställningen. Information om hur du visar definitionen av tabellen fact_sales och partitionsdefinitionen finns i Exempel i den här artikeln.

Partitionerat attribut
När en operator, till exempel en indexsökning, körs i en partitionerad tabell eller ett index, visas attributet Partitioned i kompilerings- och körningsplanen och är inställt på True (1). Attributet visas inte när det är inställt på False (0).
Attributet Partitioned kan visas i följande fysiska och logiska operatorer:
- Tabellgenomsökning
- Indexgenomsökning
- Indexsökning
- Infoga
- Uppdatera
- Ta bort
- Slå ihop
Som du ser i föregående bild visas det här attributet i egenskaperna för operatorn där det definieras. I XML Showplan-utdata visas det här attributet som Partitioned="1" i den RelOp noden för operatorn där det definieras.
Nytt sökpredikat
I XML Showplan-utdata visas elementet SeekPredicateNew i operatorn där det definieras. Den kan innehålla upp till två förekomster av SeekKeys-underelementet. Det första SeekKeys objektet anger sökåtgärden på den första nivån på partitions-ID-nivån för det logiska indexet. Den här sökningen avgör alltså de partitioner som måste nås för att uppfylla villkoren för frågan. Det andra SeekKeys objektet anger sökdelen på den andra nivån i åtgärden hoppa över genomsökning som inträffar inom varje partition som identifieras i sökningen på första nivån.
Information om partitionssammanfattning
I körningsplaner ger information om partitionssammanfattning ett antal partitioner som används och identiteten för de faktiska partitioner som används. Du kan använda den här informationen för att kontrollera att rätt partitioner används i frågan och att alla andra partitioner tas bort från övervägandet.
Följande information tillhandahålls: Actual Partition Countoch Partitions Accessed.
Actual Partition Count är det totala antalet partitioner som används av frågan.
Partitions Accessedi XML Showplan-utdata är partitionssammanfattningsinformationen som visas i det nya RuntimePartitionSummary-elementet i RelOp nod för operatorn där den definieras. I följande exempel visas innehållet i elementet RuntimePartitionSummary som anger att två totala partitioner används (partitionerna 2 och 3).
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
Visa partitionsinformation med hjälp av andra Showplan-metoder
Showplan-metoderna SHOWPLAN_ALL, SHOWPLAN_TEXToch STATISTICS PROFILE rapporterar inte partitionsinformationen som beskrivs i den här artikeln, med följande undantag. Som en del av SEEK predikat identifieras de partitioner som ska nås av ett intervallpredikat på den beräknade kolumnen som representerar partitions-ID:t. I följande exempel visas ett SEEK-predikat för en Clustered Index Seek-operator. Partitionerna 2 och 3 nås och sökoperatorn filtrerar på de rader som uppfyller villkoret date_id BETWEEN 20080802 AND 20080902.
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
Tolka körningsplaner för partitionerade heaps
En partitionerad heap behandlas som ett logiskt index på partitions-ID:t. Partitionseliminering på en partitionerad heap representeras i en körningsplan, som en Table Scan-operator med ett SEEK-predikat för partitions-ID. I följande exempel visas den Showplan-information som tillhandahålls:
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
Tolka körningsplaner för samlokala kopplingar
Kollokation av koppling kan inträffa när två tabeller partitionas med samma eller motsvarande partitioneringsfunktion och partitioneringskolumnerna på båda sidor av kopplingen anges i kopplingsvillkoret i frågan. Frågeoptimeraren kan generera en plan där partitionerna i varje tabell som har samma partitions-ID är anslutna separat. Sorterade kopplingar kan vara snabbare än icke-sorterade kopplingar eftersom de kan kräva mindre minne och bearbetningstid. Frågeoptimeraren väljer en icke-samordnad plan eller en samordnad plan baserat på kostnadsuppskattningar.
I en sammanställd plan läser Nested Loops-kopplingen en eller flera anslutna tabell- eller indexpartitioner från den inre sidan. Talen i Constant Scan-operatorerna representerar partitionsnumren.
När parallella planer för sorterade kopplingar genereras för partitionerade tabeller eller index visas en parallellitetsoperator mellan operatorerna Constant Scan och Nested Loops koppling. I det här fallet läser och arbetar flera arbetstrådar på den yttre sidan av sammanfogningen på olika partitioner.
Följande illustration visar en parallell frågeplan för en samplacerad sammanfogning.
Strategi för parallell frågekörning för partitionerade objekt
Frågeprocessorn använder en parallell körningsstrategi för frågor som väljs från partitionerade objekt. Som en del av körningsstrategin avgör frågeprocessorn de tabellpartitioner som krävs för frågan och andelen arbetstrådar som ska allokeras till varje partition. I de flesta fall allokerar frågeprocessorn lika många eller nästan lika många arbetstrådar till varje partition och kör sedan frågan parallellt mellan partitionerna. Följande stycken förklarar arbetstrådsallokering i detalj.
Om antalet arbetstrådar är mindre än antalet partitioner tilldelar frågeprocessorn varje arbetstråd till en annan partition, vilket till en början lämnar en eller flera partitioner utan en tilldelad arbetstråd. När en arbetstråd har slutfört körningen på en partition tilldelar frågeprocessorn den till nästa partition tills varje partition har tilldelats en enda arbetstråd. Det här är det enda fallet där frågeprocessorn omallokerar arbetstrådar till andra partitioner.
Visar att en arbetstråd blir omtilldelad efter att den har slutfört sitt arbete. Om antalet arbetstrådar är lika med antalet partitioner tilldelar frågeprocessorn en arbetstråd till varje partition. När en arbetstråd är klar omallokeras den inte till en annan partition.

Om antalet arbetstrådar är större än antalet partitioner allokerar frågeprocessorn lika många arbetstrådar till varje partition. Om antalet arbetstrådar inte är en exakt multipel av antalet partitioner allokerar frågeprocessorn ytterligare en arbetstråd till vissa partitioner för att kunna använda alla tillgängliga arbetstrådar. Om det bara finns en partition, tilldelas alla arbetstrådar till den partitionen. I diagrammet nedan finns det fyra partitioner och 14 arbetstrådar. Varje partition har tre tilldelade arbetstrådar och två partitioner har ytterligare en arbetstråd för totalt 14 arbetstrådstilldelningar. När en arbetstråd är klar tilldelas den inte till en annan partition.

Även om ovanstående exempel tyder på ett enkelt sätt att allokera arbetstrådar är den faktiska strategin mer komplex och beaktar andra variabler som inträffar under utförande av frågor. Om tabellen till exempel är partitionerad och har ett klustrat index i kolumn A och en fråga har predikatsatsen WHERE A IN (13, 17, 25)allokerar frågeprocessorn en eller flera arbetstrådar till vart och ett av dessa tre sökvärden (A=13, A=17 och A=25) i stället för varje tabellpartition. Det är bara nödvändigt att köra frågan i de partitioner som innehåller dessa värden, och om alla dessa sökpredikat råkar finnas i samma tabellpartition tilldelas alla arbetstrådar till samma tabellpartition.
Anta att tabellen har fyra partitioner i kolumn A med gränspunkter (10, 20, 30), ett index i kolumn B och att frågan har en predikatsats WHERE B IN (50, 100, 150). Eftersom tabellpartitionerna baseras på värdena för A kan värdena för B förekomma i någon av tabellpartitionerna. Frågeprocessorn söker därför efter vart och ett av de tre värdena för B (50, 100, 150) i var och en av de fyra tabellpartitionerna. Frågeprocessorn tilldelar arbetstrådar proportionellt så att den kan köra var och en av dessa 12 frågegenomsökningar parallellt.
| Tabellpartitioner baserade på kolumn A | Söker efter kolumn B i varje tabellpartition |
|---|---|
| Tabellpartition 1: < 10 | B=50, B=100, B=150 |
| Tabellpartition 2: A >= 10 OCH A < = 20 | B=50, B=100, B=150 |
| Tabellpartition 3: A >= 20 OCH A < 30 | B=50, B=100, B=150 |
| Tabellpartition 4: En >= 30 | B=50, B=100, B=150 |
Metodtips
För att förbättra prestandan för frågor som har åtkomst till en stor mängd data från stora partitionerade tabeller och index rekommenderar vi följande metodtips:
- Randa varje partition över många diskar. Detta är särskilt relevant när du använder snurrande diskar.
- När det är möjligt kan du använda en server med tillräckligt med huvudminne för att få plats med partitioner som används ofta, eller alla partitioner i minnet, för att minska I/O-kostnaden.
- Om de data du frågar inte får plats i minnet komprimerar du tabellerna och indexen. Detta minskar I/O-kostnaden.
- Använd en server med snabba processorer och så många processorkärnor som du har råd med för att dra nytta av parallell frågebearbetning.
- Kontrollera att servern har tillräckligt med I/O-styrbandbredd.
- Skapa ett grupperat index i varje stor partitionerad tabell för att dra nytta av B-trädgenomsökningsoptimeringar.
- Följ rekommendationerna för bästa praxis i vitboken Prestandaguiden för datainläsningnär du massinläsningar av data i partitionerade tabeller.
Exempel
I följande exempel skapas en testdatabas som innehåller en enskild tabell med sju partitioner. Använd de verktyg som beskrevs tidigare när du kör frågorna i det här exemplet för att visa partitioneringsinformation för både kompilerings- och körningsplaner.
Not
Det här exemplet infogar mer än 1 miljon rader i tabellen. Det kan ta flera minuter att köra det här exemplet beroende på maskinvaran. Innan du kör det här exemplet kontrollerar du att du har mer än 1,5 GB ledigt diskutrymme.
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
Relaterat innehåll
- logisk och fysisk showplansoperatorreferens
- översikt över Extended Events
- Metodtips för övervakning av arbetsbelastningar med Query Store
- kardinalitetsuppskattning (SQL Server)
- Intelligent frågebearbetning i SQL-databaser
- operatorprioritet (Transact-SQL)
- Översikt över exekveringsplan
- Performance Center för SQL Server-databasens databas-motor och Azure SQL-databas