Utforska och bearbeta data med Microsoft Fabric
Data är hörnstenen i datavetenskap, särskilt när det gäller att träna en maskininlärningsmodell för att uppnå artificiell intelligens. Vanligtvis uppvisar modeller förbättrade prestanda när storleken på träningsdatauppsättningen ökar. Förutom mängden data är datakvaliteten lika viktig.
För att garantera både kvaliteten och kvantiteten av dina data är det värt att använda Microsoft Fabrics robusta datainmatnings- och bearbetningsmotorer. Du har flexibiliteten att välja en metod med låg kod eller kod först när du upprättar viktiga pipelines för datainmatning, utforskning och transformering.
Mata in dina data i Microsoft Fabric
Om du vill arbeta med data i Microsoft Fabric måste du först mata in data. Du kan mata in data från flera källor, både lokala datakällor och molndatakällor. Du kan till exempel mata in data från en CSV-fil som lagras på din lokala dator eller i en Azure Data Lake Storage (Gen2).
Dricks
Läs mer om hur du matar in och samordnar data från olika källor med Microsoft Fabric.
När du har anslutit till en datakälla kan du spara data i ett Microsoft Fabric Lakehouse. Du kan använda lakehouse som en central plats för att lagra alla strukturerade, halvstrukturerade och ostrukturerade filer. Du kan sedan enkelt ansluta till lakehouse när du vill komma åt dina data för utforskning eller omvandling.
Utforska och transformera dina data
Som dataexpert kanske du är mest bekant med att skriva och köra kod i notebook-filer. Microsoft Fabric erbjuder en välbekant notebook-upplevelse som drivs av Spark-beräkning.
Apache Spark är ett öppen källkod ramverk för parallell bearbetning för storskalig databearbetning och analys.
Notebook-filer kopplas automatiskt till Spark-beräkning. När du kör en cell i en notebook-fil för första gången startar en ny Spark-session. Sessionen bevaras när du kör efterföljande celler. Spark-sessionen stoppas automatiskt efter en viss tid av inaktivitet för att spara kostnader. Du kan också stoppa sessionen manuellt.
När du arbetar i en notebook-fil kan du välja det språk som du vill använda. För datavetenskapsarbetsbelastningar kommer du förmodligen att arbeta med PySpark (Python) eller SparkR (R).
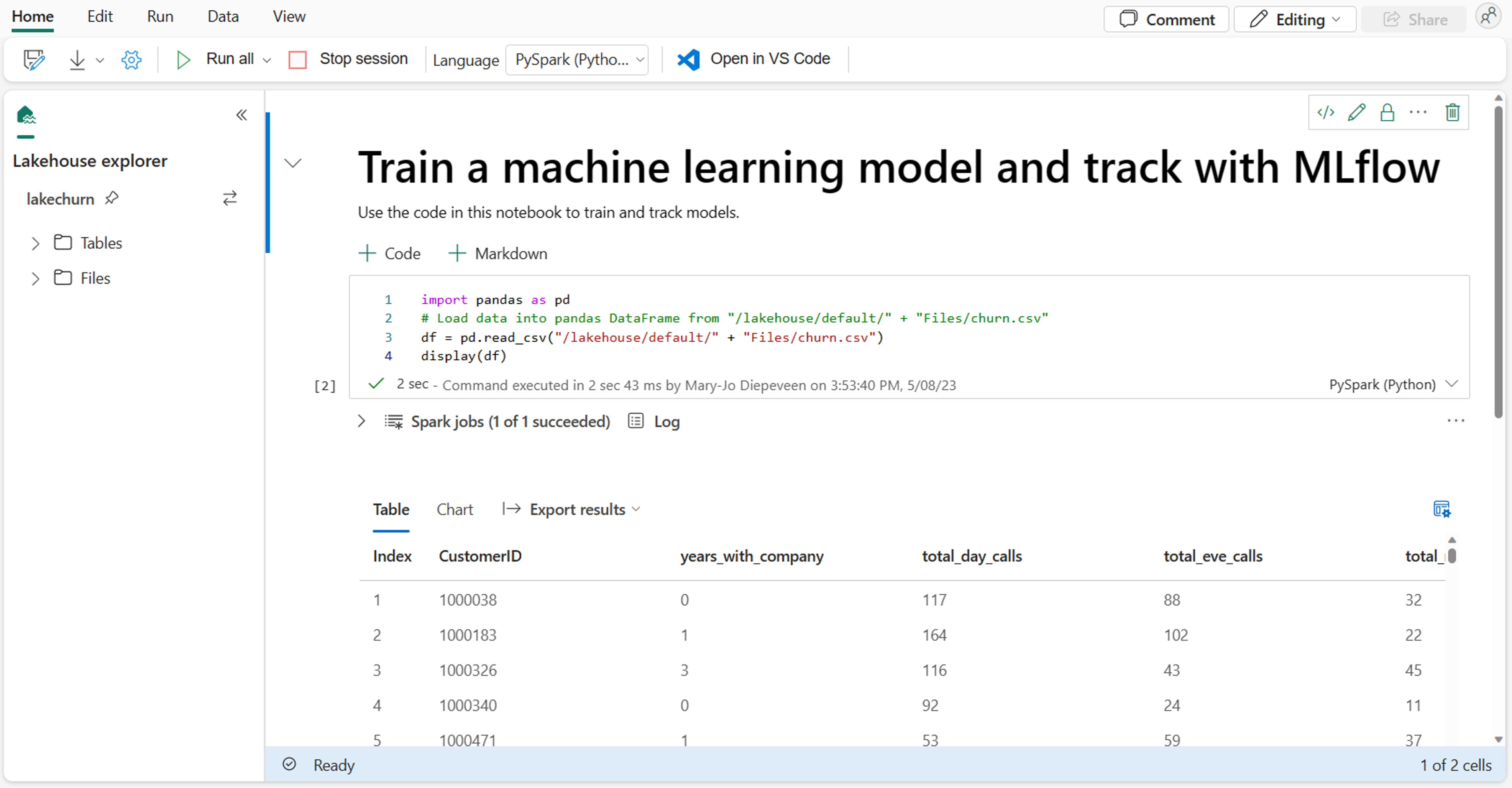
I notebook-filen kan du utforska dina data med hjälp av önskat bibliotek eller med något av de inbyggda visualiseringsalternativen. Om det behövs kan du transformera dina data och spara bearbetade data genom att skriva tillbaka dem till lakehouse.
Förbereda dina data med Data Wrangler
För att hjälpa dig att utforska och transformera dina data snabbare erbjuder Microsoft Fabric den lättanvända Data Wrangler.
När du har startat Data Wrangler får du en beskrivande översikt över de data som du arbetar med. Du kan visa sammanfattningsstatistiken för dina data för att hitta eventuella problem som saknade värden.
Om du vill rensa dina data kan du välja någon av de inbyggda datarensningsåtgärderna. När du väljer en åtgärd genereras en förhandsgranskning av resultatet och den associerade koden automatiskt åt dig. När du har valt alla nödvändiga åtgärder kan du exportera transformeringarna för att koda och köra dem på dina data.