Serverfri databehandling
Under molnets första år fokuserade molntjänstleverantörer som Amazon och Microsoft på att erbjuda en stor mängd IaaS-tjänster till sina kunder. Det här ledde till stor tillväxt av de offentliga molnen eftersom kunderna ganska enkelt kunde flytta arbetsbelastningar som kördes lokalt på fysiska servrar eller i virtuella datorer till virtuella datorer i molnet. IaaS medför dock även ansvar. En organisation som startar en virtuell dator i molnet tar även på sig ansvar för att underhålla det som finns i den virtuella datorn, som operativsystemet, de körningsmiljöer som behövs och programmen som körs i miljöerna.
Med PaaS skiftar en del av det här ansvaret till molntjänstleverantören, och det har lett till fortsatt stora investeringar i molnet. Med tjänster som AWS Elastic Beanstalk och Azure App Service kan kunderna etablera virtuella webbservrar med populära körningsmiljöer som Java, Node.js och Microsoft.NET, och köra programvara på dem på bara några minuter. Även om det är virtuella datorer som gör grovjobbet så abstraheras de bort och märks knappt. Med PaaS kan kunderna fokusera på programmen de skriver för att lösa affärsproblem i stället för att ägna hela cykler åt att hantera virtuella datorer och hålla plattformarna uppdaterade.
Serverlös databehandling är en relativt ny innovation inom den molnbaserade databehandlingen där den här abstraktionen tas ytterligare ett steg. Anta att din organisation skriver och underhåller kod som kör säkerhetskopiering av verksamhetskritiska data varje natt, faktureringar varje vecka eller som utför en elektronisk betalning varje gång en faktura laddas upp till molnlagringen. I det här fallet är huvudmålet att köra den här koden vid rätt tidpunkt. Allt annat är sekundärt, även var koden lagras samt hur och var den körs.
Du kan använda en IaaS-strategi där du skapar en eller flera virtuella datorer som kör koden och installerar de plattformar och bibliotek som krävs. Du skulle kunna etablera en instans av Elastic Beanstalk eller App Service och köra koden där. Eller så kan du använda en funktionsmiljö som AWS Lambda eller Azure Functions till att köra koden när du vill, utan att bry dig om var eller hur den körs. AWS Lambda och Azure Functions är båda exempel på serverlös databehandling (mer specifikt på serverlösa funktioner). Ett annat exempel är Google Cloud Functions. Alla tre representerar nästa steg i den naturliga utvecklingen av molnbaserad databehandling från IaaS, där du själv har ansvar för allting, till serverlös databehandling där du fokuserar på de åtgärder du vill utföra (den kod du vill köra) i molnet och låter molntjänstleverantören hantera allting annat.
Serverlösa funktioner som körs i funktionsmiljöer i molnet är den vanligaste formen av serverlös databehandling, men det finns fler. Amazon, Microsoft och Google erbjuder serverlösa versioner av en del andra PaaS-tjänster som serverlösa databaser. En del leverantörer har stöd för serverlösa arbetsflöden. De gör att du kan definiera affärsarbetsflöden i molnet och köra dem som svar på externa händelser, till exempel att fakturor laddas upp till molnlagringen, timers som utlöses med angivna intervall eller e-postmeddelanden som anländer till inkorgen, och ofta behöver du inte skriva en enda kodrad. Slutligen är många av de containertjänster som molntjänstleverantörerna erbjuder, som Azure Container Instances och AWS Elastic Container Service, också exempel på serverlös databehandling eftersom du kan köra containers i molnet samtidigt som du abstraherar bort den underliggande infrastrukturen.
Fördelar med serverlös databehandling
Serverlös databehandling har tre viktiga fördelar för organisationer som använder molnbaserad databehandling:
Lägre beräkningskostnader: Kunder betalar vanligtvis månatliga avgifter för virtuella IaaS-datorer och PaaS-tjänster som Elastic Beanstalk och Azure App Service. Faktureringen fortsätter även om tjänsterna är inaktiva. De flesta tjänster för serverlös databehandling har dock stöd för prissättning per förbrukning där du bara faktureras för tiden som din kod körs. Tänk dig att du använder en virtuell dator som kostar 100 dollar i månaden till att köra kod som säkerhetskopierar verksamhetskritiska data varje natt och att koden körs i 30 minuter varje natt. Du betalar alltså 100 dollar per månad för att köra kod 1/48 av tiden varje månad, eller mindre än en dag. Om du distribuerar samma kod som en serverlös funktion skulle den kunna kosta så lite som några dollar per månad. Med prissättning per förbrukning betalar du inte för inaktiv tid.
Automatisk skalbarhet: Molnleverantörer erbjuder mekanismer för skalning av IaaS-tjänster i produkter som automatisk skalning av AWS och vm-skalningsuppsättningar i Azure. Det finns även manuella och automatiska skalningsalternativ för PaaS-tjänster. Men även om skalningen utförs automatiskt så måste en molnadministratör aktivera autoskalningen och konfigurera den så att molnleverantören vet hur och när skalningen ska ske. Eftersom du betalar för enskilda instanser av IaaS- och PaaS-tjänster så är ett av de underliggande överväganden som administratörer måste ta hänsyn till att du vill konfigurera tjänsten så att den skalar om tillräckligt utan att skala om för mycket. Med serverlös databehandling kan du skala ut transparent och automatiskt vid ökade behov och skala in när behovet minskar. Molnadministratörer behöver normalt inte utföra någon konfiguration förutom att aktivera det här alternativet i tjänsten. Om du får 100 förfrågningar om att köra en serverlös funktion samtidigt så ser molntjänstleverantören till att förfrågningarna kan köras parallellt (eller nästan parallellt). Kostnaden påverkas inte, för med förbrukningsbaserad prissättning kostar det lika mycket att köra en funktion 100 gånger oavsett om körningen är seriell eller parallell.
Minskade administrativa kostnader: Med Serverless kan du fokusera på att köra kod och arbetsflöden samtidigt som du överför ansvaret för allt annat, inklusive att underhålla den underliggande plattformen, till molntjänstleverantören.
Det finns även nackdelar med serverlös databehandling. Här är några av begränsningarna du bör överväga:
En del funktionsmiljöer har begräsningar för tiden en funktion får köras.
En del funktionsmiljöer garanterar inte att en funktion körs direkt om du inte är beredd att betala mer för det. När du använder förbrukningsbaserad prissättning i Azure Functions kanske en funktion till exempel inte körs förrän 10 minuter efter det att den anropas. Det här kanske inte är ett problem för en nattlig säkerhetskopiering. Du bryr dig förmodligen inte om säkerhetskopieringen körs 01:00 eller 01:10. Men det kan vara en deal-breaker för funktioner som är tidskritiska – funktioner som måste köras i realtid (eller nästan i realtid).
Serverlösa funktioner är i allmänhet tillståndslösa, det vill säga att de inte kan lagra data internt och att de är beständiga mellan olika funktionsanrop. De kan använda externa molnlagringstjänster som Amazon S3 och Azure Storage till att lagra mellan anrop, men det gör funktionskoden mer komplex.
En del molntjänstleverantörer har stöd för tillståndskänsliga funktioner (Azure kallar dem ”varaktiga funktioner”), men funktioner som bevarar ett tillstånd är ett relativt nytt tillägg i den serverlösa databehandlingen och de stöds inte överallt.
Serverlösa funktioner
Det vanligaste exemplet på serverlös databehandling är serverlösa funktioner. Du laddar upp kod till molnet och anger när den ska köras. Koden kan skrivas på en mängd olika språk, inklusive Java och C#.
I bild 11 ser du vilka programmeringsspråk som stöddes för serverlösa funktioner i Azure, AWS och GCP när artikeln skrevs:
| Språk | Azure Functions | AWS Lambda | Google Cloud Functions |
|---|---|---|---|
| C# | x | x | |
| F# | x | ||
| Go | x | x | |
| Java | x | x | |
| JavaScript (Node.js) | x | x | x |
| PowerShell | x | x | |
| Python | x | x | x |
| Ruby | x | ||
| TypeScript | x |
Bild 11: Programmeringsspråk som stöds av populära serverlösa funktionskörningar.
När du skapar en funktion och anger koden som ska köras så identifierar du även den externa händelse som ska utlösa körningen. De populära molnplattformarna har stöd för olika utlösare som timers, händelser som inträffar i andra molntjänster (som att ett dokument laddas upp till molnlagringen) och HTTP-anrop. Det är enkelt att ladda upp kod för fakturering till en funktionsmiljö och konfigurera den så att den körs en gång om dagen, en gång i veckan eller en gång i månaden. Det är lika enkelt att aktivera en funktion varje gång en faktura laddas upp till molnlagringen (till exempel Amazon S3 eller Azure Storage), eller när ett anrop skickas till en REST-slutpunkt som är kopplad till funktionen.
Serverlösa funktioner används ofta till att utföra fristående uppgifter som säkerhetskopiering på natten och fakturering. De används också till att koppla samman olika molntjänster och skapa omfattande lösningar med molntjänsterna som byggstenar. I bild 12 ser du en sådan lösning som används till att kombinera flera Azure-tjänster som övervakar aktiviteten hos isbjörnar i Arktis. En Azure-funktion har en nyckelroll i arkitekturen genom att den tar utdata från Azure Stream Analytics (utlöses via ett HTTP-anrop), hämtar ett foto från Azure Blob Storage och skickar fotot till en modell som har tränats upp med Azure Custom Vision Service, där AI används till att fastställa om fotot innehåller en isbjörn. Funktionen är limmet som binder samman Stream Analytics, Blob Storage och Custom Vision Service.
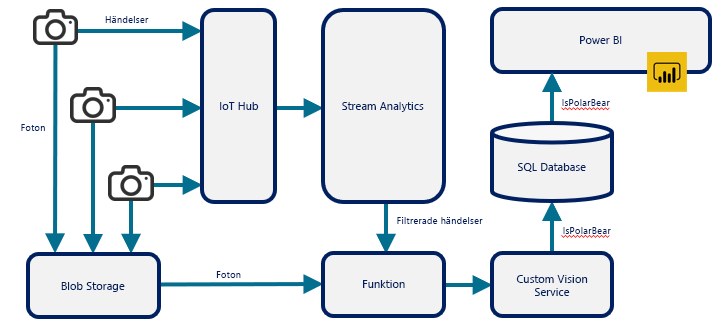
Bild 12: Använda en Azure-funktion för att ansluta andra Azure-tjänster.
Serverlösa arbetsflöden
En del tjänster inom serverlös databehandling gör att kunderna kan automatisera affärsarbetsflöden utan att behöva skriva någon kod. Azure Logic Apps tillhandahåller till exempel mer än 100 inbyggda anslutningsappar för interaktion med datakällor som sträcker sig från Oracle-databaser till sociala medietjänster som X. De tillhandahåller utlösare för att definiera när arbetsflöden ska köras , till exempel när en fil laddas upp till Box.com eller något tweetas med en angiven hashtagg. De har även hundratals fördefinierade åtgärder som definierar vad som ska hända när en utlösare aktiveras, och de kan kopplas samman för att bilda komplexa arbetsflöden. Dessutom har de villkor som gör att åtgärder kan utföras villkorligt. De kan även utökas i all oändlighet eftersom en av åtgärderna som Azure Logic Apps har stöd för är att anropa en Azure-funktion. Om ett arbetsflöde innehåller anpassad logik som inte är kapslad i en åtgärd kan du ange koden som implementerar logiken och ta med den i arbetsflödet som om den vore en fördefinierad åtgärd.
I bild 13 ser du ett sådant arbetsflöde i Azure Logic Apps-designern1. När det kommer in ett e-postmeddelande aktiveras logikappen vars uppgift det är att söka efter nyckelfras i ämnesraden och kontrollera om det finns någon bifogad fil. Om båda villkoren är uppfyllda anropar logikappen en Azure-funktion som tar bort all HTML-kod från meddelandets brödtext. Det rensade meddelandet och eventuella bilagor skickas till Azure Blob Storage, och sedan skickas ett e-postmeddelande med länkar till relevanta dokument i Blob Storage samt information till berörda parter om att informationen är tillgänglig och väntar på granskning. Det här exemplet kombinerar två serverlösa paradigm – en logikapp som kör åtgärder utan kod (åtminstone inte kod som du eller någon annan i din organisation skrev) och en Azure-funktion som innehåller kod som du angav för att anpassa arbetsflödet – och som är representativ för det skift som sker inom molnbaserad databehandling från virtuella do-it-yourself-datorer till abstraktioner på högre nivå som gör att organisationer kan fokusera sin energi på att lösa affärsproblem i stället för att hantera virtuella datorer och installera och underhålla körningsmiljöer.
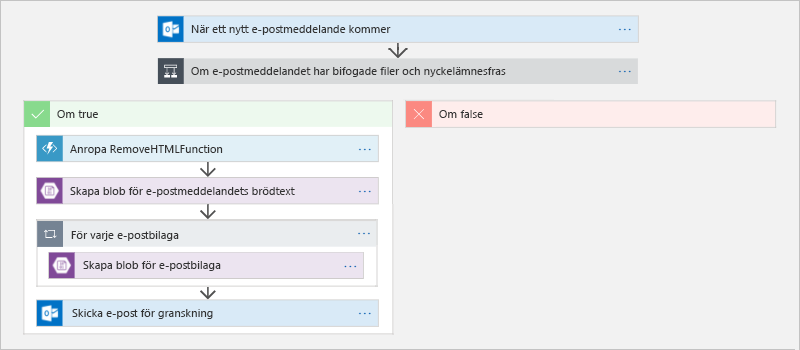
Bild 13: Definiera ett arbetsflöde i Azure Logic Apps.
Amazon har en liknande tjänst, AWS Step Functions. Med Step Functions kan du skapa visuella arbetsflöden där du kombinerar andra tjänster som AWS Lambda och AWS ECS. Arbetsflödena består av en serie steg, där utdata från ett steg används som indata till nästa. Precis som Azure Logic Apps så har AWS Step Functions primitiva typer för förgreningar och parallell körning så att du inte behöver skriva någon kod för detta. I praktiken blir ett företagsarbetsflöde ett tillståndsdiagram som är enkelt att förstå, enkelt att förklara för andra och enkelt att ändra.
Serverlösa databaser
Under molnets första år så behövde du etablera en virtuell dator och installera en databasprodukt som MySQL, PostgreSQL eller SQL Server när du ville köra en databas i molnet. När PaaS kom så kunde databaser erbjudas som en tjänst. Med Azure SQL Database eller Amazon Relational Database Service (RDS) etablerar du till exempel bara en instans och får en molndatabas redo att betjäna klienter på bara några minuter. Molntjänstleverantören håller dessutom databasplattformen aktuell genom att köra uppdateringar och korrigeringar.
En ännu nyare innovation inom molnbaserad databehandling är serverlösa databaser, där prismodellen är optimerad för enstaka databaser med oregelbunden användning. Azure erbjuder till exempel en serverlös version av Azure SQL Database. Med den vanliga versionen av Azure SQL Database väljer du en prisnivå som baseras på den maximala belastning du förväntar dig att databasen ska kunna hantera. Om belastningen är ”hackig” eller oregelbunden får du ofta betala som om belastningen på databasen var hög konstant.
Den serverlösa versionen av Azure SQL Database hanterar det här problemet genom att skala om databasen vid behov så att den kan hantera belastningen för stunden, och kostnaden baseras på summan av kostnaderna för beräkningar och lagring. Precis som vid förbrukningsbaserad prissättning för serverlösa funktioner så betalar du bara för det du använder. Amazon har en liknande tjänst som heter AWS Aurora Serverless, som är en serverlös version av Amazons databastjänst Aurora, och Google erbjuder sina kunder en serverlös NoSQL-databastjänst som heter Google Cloud Firestore.
Referenser
- Microsoft (2019). Automatisera hanteringen av e-postmeddelanden och bifogade filer med Azure Logic Apps. https://learn.microsoft.com/azure/logic-apps/tutorial-process-email-attachments-workflow.