Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
gäller för:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() SQL-databas i Microsoft Fabric
SQL-databas i Microsoft Fabric
Alternativ och rekommendationer för att läsa in data i ett kolumnlagringsindex med hjälp av sql-standardmetoderna för massinläsning och infogning av trickle. Att läsa in data i ett kolumnlagringsindex är en viktig del av alla datalagerprocesser eftersom de flyttar data till indexet inför analys.
Ny med kolumnlagringsindex? Se Columnstore-index – översikt och Columnstore-indexarkitektur.
Vad är massinläsning?
Massinläsning syftar på sättet som ett stort antal rader läggs till i en datalagringsplats. Det är det mest högpresterande sättet att flytta data till ett columnstore-index eftersom det fungerar på batchar med rader. Massinläsning fyller radgrupper till maximal kapacitet och komprimerar dem direkt till kolumnarkivet. Endast rader i slutet av en införsel som inte uppfyller minimikravet på 102 400 rader per radgrupp går till deltalagret.
För att utföra en massinläsning kan du använda bcp-verktyget, Integration Services eller välja rader från en mellanlagringstabell.
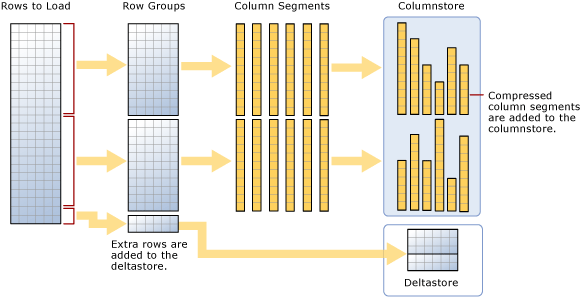
Som diagrammet antyder, en massinläsning:
- Sorterar inte data i förväg. Data infogas i radgrupper i den ordning de tas emot.
- Om batchstorleken är >= 102400 läses raderna in direkt i de komprimerade radgrupperna. Du bör välja en batchstorlek >= 102400 för en effektiv bulkimport, eftersom detta möjliggör undvikande av att flytta datarader till delta-radgrupper innan de slutligen flyttas till komprimerade radgrupper av en bakgrundstråd, Tuple Mover (TM).
- Om batchstorleken < är 102 400 eller om de återstående raderna är < 102 400 läses raderna in i deltaradgrupper.
Anmärkning
I en radlagringstabell med ett icke-klustrat kolumnbutiksindex infogar SQL Server alltid data i bastabellen. Data infogas aldrig direkt i kolumnlagringsindexet.
Massinläsning har dessa inbyggda prestandaoptimeringar:
Parallella belastningar: Du kan ha flera samtidiga masslaster (bcp eller massinfogning) som var och en laddar en separat datafil. Till skillnad från massinläsningar av radarkiv i SQL Server behöver du inte ange
TABLOCKeftersom varje massimporttråd läser in data exklusivt i separata radgrupper (komprimerade eller deltaradgrupper) med exklusivt lås på den.Minskad loggning: De data som läses in direkt i komprimerade radgrupper leder till en betydande minskning av loggens storlek. Om data till exempel komprimerades 10x är motsvarande transaktionslogg ungefär 10 gånger mindre utan att kräva
TABLOCKeller Massloggad/Enkel återställningsmodell. Alla data som går till en deltaradgrupp loggas fullständigt. Detta omfattar alla batchstorlekar som är mindre än 102 400 rader. Bästa praxis är att använda batchstorlek >= 102400. Eftersom det inteTABLOCKkrävs kan du läsa in data parallellt.Minimal loggning: Du kan få ytterligare minskning av loggning om du följer förutsättningarna för minimal loggning. Men till skillnad från att ladda in data i ett raddatalager,
TABLOCKleder det till ettX(exklusivt) lås i tabellen i stället för ettBU(massuppdateringslås) och därför kan man inte utföra parallell dataladdning. Mer information om låsning finns i Låsning och radversionering.Låsningsoptimering: Låset
Xpå en radgrupp hämtas automatiskt när data läses in i en komprimerad radgrupp. Men vid massinläsning i en deltaradgrupp hämtas ettXlås för radgruppen, men Databasmotorn hämtar fortfarande sid- och omfattningslås eftersom radgruppslåsetXinte ingår i låshierarkin.
Om du har ett icke-grupperat B-trädindex på ett kolumnlagringsindex finns det ingen låsnings- eller loggningsoptimering för själva indexet, men optimeringarna på klustrade kolumnlagringsindex enligt beskrivningen ovan är tillämpliga.
Planera massinläsningsstorlekar för att minimera deltaradgrupper
Kolumnlagringsindex presterar bäst när de flesta raderna komprimeras till kolumnarkivet och inte sitter i delta-radgrupper. Det är bäst att storleksanpassa dina laster så att raderna går direkt till kolumnarkivet och kringgår deltaarkivet så mycket som möjligt.
De här scenarierna beskriver när inlästa rader går direkt till kolumnarkivet eller när de går till deltaarkivet. I exemplet kan varje radgrupp ha 102 400–1 048 576 rader per radgrupp. I praktiken kan den maximala storleken på en radgrupp vara mindre än 1 048 576 rader när minnesbelastning uppstår.
| Rader som ska massimporteras | Rader som har lagts till i den komprimerade radgruppen | Rader som har lagts till i deltaradsgruppen |
|---|---|---|
| 102,000 | 0 | 102,000 |
| 145,000 | 145,000 Radgruppsstorlek: 145 000 |
0 |
| 1,048,577 | 1 048 576 Radgruppsstorlek: 1 048 576. |
1 |
| 2,252,152 | 2,252,152 Radgruppsstorlekar: 1 048 576, 1 048 576, 155 000. |
0 |
I följande exempel visas resultatet av att läsa in 1 048 577 rader i en tabell. Resultaten visar att det finns en komprimerad radgrupp i kolumnarkivet (som komprimerade kolumnsegment) och 1 rad i deltaarkivet.
SELECT object_id, index_id, partition_number, row_group_id, delta_store_hobt_id,
state, state_desc, total_rows, deleted_rows, size_in_bytes
FROM sys.dm_db_column_store_row_group_physical_stats;

Använd en stegtabell för att förbättra prestanda
Om du bara läser in data för att mellanlagra dem innan du kör fler transformeringar, går det mycket snabbare att ladda in tabellen till en heap-tabell jämfört med att ladda in data till en klustrad columnstore-tabell. Dessutom kommer inläsning av data till en [tillfällig tabell][Tillfälligt] också att läsas in mycket snabbare än när en tabell läses in till permanent lagring.
Ett vanligt mönster för datainläsning är att läsa in data i en mellanlagringstabell, utföra en transformering och sedan läsa in dem i måltabellen med hjälp av följande kommando:
INSERT INTO [<columnstore index>]
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
Det här kommandot läser in data i kolumnlagringsindexet på liknande sätt som bcp eller massinfogning, men i en enda batch. Om antalet rader i mellanlagringstabellen < 102400 läses raderna in i en deltaradgrupp, annars läses raderna in direkt i komprimerad radgrupp. En viktig begränsning var att den här INSERT operationen var enkeltrådad. Om du vill läsa in data parallellt kan du skapa flera mellanlagringstabeller eller utfärda INSERT/SELECT med icke-överlappande räckvidder av rader från mellanlagringstabellen. Den här begränsningen försvinner med SQL Server 2016 (13.x). Följande kommando läser in data från mellanlagringstabellen parallellt, men du måste ange TABLOCK. Det kan verka motsägelsefullt jämfört med vad som sades tidigare om bulkimporten, men den viktigaste skillnaden är att den parallella databelastningen från mellanlagringstabellen körs under samma transaktion.
INSERT INTO [<columnstore index>] WITH (TABLOCK)
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
Följande optimeringar är tillgängliga vid inläsning till ett grupperat columnstore-index från mellanlagringstabellen:
- Loggoptimering: Minskad loggning när data läses in i en komprimerad radgrupp.
-
Låsningsoptimering: När du läser in data i en komprimerad radgrupp hämtas låset
Xpå radgruppen. Men vid massinläsning i en deltaradgrupp hämtas ettXlås för radgruppen, men Databasmotorn hämtar fortfarande sid- och omfattningslås eftersom radgruppslåsetXinte ingår i låshierarkin.
Om du har ett eller flera icke-grupperade index finns det ingen låsnings- eller loggningsoptimering för själva indexet, men optimeringarna i det klustrade kolumnlagringsindexet enligt beskrivningen ovan finns fortfarande kvar.
Vad är trickle insert?
Trickle insert refererar till hur enskilda rader flyttas till kolumnlagringsindexet. Trickle-infogningar använder INSERT INTO-instruktionen . Med trickle insert skickas alla rader till deltastore. Detta är användbart för ett litet antal rader, men inte praktiskt för stora belastningar.
INSERT INTO [<table-name>] VALUES ('some value' /*replace with actual set of values*/)
Anmärkning
Samtidiga trådar som använder INSERT INTO för att infoga värden i ett grupperat kolumnlagringsindex kan infoga rader i samma deltastore-radgrupp.
När radgruppen innehåller 1 048 576 rader markeras deltaradgruppen som stängd, men den är fortfarande tillgänglig för fråge- och uppdaterings-/raderingsåtgärder, medan de nyligen infogade raderna hamnar i en befintlig eller nyligen skapad deltastore-radgrupp. Det finns en bakgrundstråd med namnet Tple mover (TM) som komprimerar de stängda deltaradgrupperna med jämna mellanrum var 5:e minut eller så. Du kan uttryckligen anropa följande kommando för att komprimera den stängda deltaradgruppen.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE
Om du vill tvinga en delta rowgroup att stängas och komprimeras kan du köra följande kommando. Du kanske vill köra det här kommandot om du är klar med att läsa in raderna och inte förväntar dig några nya rader. Genom att uttryckligen stänga och komprimera deltaradgruppen kan du spara lagring ytterligare och förbättra analysfrågans prestanda. Bästa praxis är att anropa det här kommandot om du inte förväntar dig att nya rader ska infogas.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE with (COMPRESS_ALL_ROW_GROUPS = ON)
Så här fungerar inläsning i en partitionerad tabell
För partitionerade data tilldelar databasmotorn först varje rad till en partition och utför sedan kolumnlagringsåtgärder på data i partitionen. Varje partition har egna radgrupper och minst en deltaradgrupp.