Objektidentifiering med snabb R-CNN
Innehållsförteckning
- Sammanfattning
- Installation
- Kör leksaksexemplet
- Kör Pascal VOC
- Träna CNTK Fast R-CNN på dina egna data
- Teknisk information
- Algoritminformation
Sammanfattning

Den här självstudien beskriver hur du använder CNTK Fast R-CNN med BrainScript och cntk.exe. Snabb R-CNN med CNTK Python API beskrivs här.
Ovanstående är exempel på bilder och objektanteckningar för livsmedelsdatauppsättningen (första bilden) och Pascal VOC-datauppsättningen (andra bilden) som används i den här självstudien.
Fast R-CNN är en objektidentifieringsalgoritm som föreslogs av Ross Girshick 2015. Dokumentet godkänns i ICCV 2015 och arkiveras på https://arxiv.org/abs/1504.08083. Snabb R-CNN bygger på tidigare arbete för att effektivt klassificera objektförslag med hjälp av djupa convolutional-nätverk. Jämfört med tidigare arbete använder Fast R-CNN ett schema för intressepooler som gör det möjligt att återanvända beräkningarna från de convolutional lagren.
Ytterligare material: en detaljerad självstudiekurs för objektidentifiering med CNTK Fast R-CNN med BrainScript (inklusive valfri SVM-utbildning och publicering av den tränade modellen som rest-API) finns här.
Installation
Om du vill köra koden i det här exemplet behöver du en CNTK Python-miljö (se här för installationshjälp). Dessutom behöver du installera några ytterligare paket. Gå till mappen FastRCNN och kör:
pip install -r requirements.txt
Känt problem: om du vill installera scikit-learn kan du behöva köra conda install scikit-learn om du använder Anaconda Python.
Du behöver ytterligare Scikit-Image och OpenCV för att köra dessa exempel.
Ladda ned motsvarande hjulpaket och installera dem manuellt. I Linux kan conda install scikit-image opencvdu .
För Windows-användare går du till http://www.lfd.uci.edu/~gohlke/pythonlibs/och laddar ned:
- Python 3.5
- scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
- opencv_python-3.2.0-cp35-cp35m-win_amd64.whl
När du har laddat ned respektive hjulbinärfiler installerar du dem med:
pip install your_download_folder/scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
[! OBS! Om du ser meddelandet Ingen modul med namnet past när du kör skripten kör pip install futuredu .
Den här självstudiekoden förutsätter att du använder 64-bitarsversionen av Python 3.5 eller 3.6, eftersom de nödvändiga Snabba R-CNN DLL-filerna under verktyg är fördefinierade för dessa versioner. Om din uppgift kräver användning av en annan Python-version kan du kompilera om dessa DLL-filer själv i rätt miljö (se nedan).
Självstudien förutsätter vidare att mappen där cntk.exe finns finns i din PATH-miljövariabel. (Om du vill lägga till mappen i sökvägen kan du köra följande kommando från en kommandorad (förutsatt att mappen där cntk.exe finns på datorn är C:\src\CNTK\x64\Release): set PATH=C:\src\CNTK\x64\Release;%PATH%.)
Förkompilerade binärfiler för regression av avgränsningsrutor och icke-maximal undertryckning
Mappen Examples\Image\Detection\FastRCNN\BrainScript\fastRCNN\utils innehåller förkompilerade binärfiler som krävs för att köra Snabb R-CNN. De versioner som för närvarande finns på lagringsplatsen är Python 3.5 och 3.6, alla 64 bitar. Om du behöver en annan version kan du kompilera den enligt följande steg:
git clone --recursive https://github.com/rbgirshick/fast-rcnn.gitcd $FRCN_ROOT/libmake- I stället
makeför kan du körapython setup.py build_ext --inplacefrån samma mapp. I Windows kan du behöva kommentera ut extra kompilering args i lib/setup.py:
ext_modules = [ Extension( "utils.cython_bbox", ["utils/bbox.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ), Extension( "utils.cython_nms", ["utils/nms.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ) ]- I stället
kopiera de genererade
cython_bboxochcython_nmsbinärfilerna från$FRCN_ROOT/lib/utilstill$CNTK_ROOT/Examples/Image/Detection/fastRCNN/utils.
Exempeldata och baslinjemodell
Vi använder en förtränad AlexNet-modell som grund för Fast-R-CNN-utbildning. Den förtränade AlexNet är tillgänglig på https://www.cntk.ai/Models/AlexNet/AlexNet.model. Lagra modellen på $CNTK_ROOT/PretrainedModels. Om du vill ladda ned data kör du
python install_grocery.py
Examples/Image/DataSets/Grocery från mappen.
Kör leksaksexemplet
I leksaksexemplet tränar vi en CNTK Fast R-CNN-modell för att identifiera matvaror i ett kylskåp.
Alla skript som krävs finns i $CNTK_ROOT/Examples/Image/Detection/FastRCNN/BrainScript.
Snabbguide
Om du vill köra leksaksexemplet kontrollerar du att i PARAMETERS.pydataset är inställt på "Grocery".
- Kör
A1_GenerateInputROIs.pyför att generera indata-ROI:er för träning och testning. - Kör
A2_RunWithBSModel.pyför att träna och testa med cntk.exe och BrainScript. - Kör
A3_ParseAndEvaluateOutput.pyför att beräkna mAP (genomsnittlig genomsnittlig precision) för den tränade modellen.
Utdata från skriptet A3 bör innehålla följande:
Evaluating detections
AP for avocado = 1.0000
AP for orange = 1.0000
AP for butter = 1.0000
AP for champagne = 1.0000
AP for eggBox = 0.7500
AP for gerkin = 1.0000
AP for joghurt = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
AP for onion = 1.0000
AP for pepper = 1.0000
AP for tomato = 0.7600
AP for water = 0.5000
AP for milk = 1.0000
AP for tabasco = 1.0000
AP for mustard = 1.0000
Mean AP = 0.9173
DONE.
Om du vill visualisera avgränsningsrutorna och förutsagda etiketter kan du köra B3_VisualizeOutputROIs.py (klicka på bilderna för att förstora):





Steginformation
A1: Skriptet A1_GenerateInputROIs.py genererar först ROI-kandidater för varje bild med hjälp av selektiv sökning.
Den lagrar dem sedan i ett CNTK-textformat som indata för cntk.exe.
Dessutom genereras de nödvändiga CNTK-indatafilerna för bilderna och de jordade sanningsetiketterna.
Skriptet genererar följande mappar och filer under FastRCNN mappen:
proc– rotmapp för genererat innehåll.grocery_2000– innehåller alla genererade mappar och filer förgroceryexemplet med hjälp av2000ROI:er. Om du kör igen med ett annat antal ROIs ändras mappnamnet på motsvarande sätt.rois– innehåller råa ROI-koordinater för varje bild som lagras i textfiler.cntkFiles- innehåller formaterade CNTK-indatafiler för bilder (train.txtoch ), ROI-koordinater (xx.rois.txt) och ROI-etiketter (xx.roilabels.txt) förtrainochtesttest.txt. (Formatinformation finns nedan.)
Alla parametrar finns i PARAMETERS.py, till exempel ändra cntk_nrRois = 2000 för att ange antalet ROI:er som används för träning och testning. Vi beskriver parametrar i avsnittet Parametrar nedan.
A2: Skriptet A2_RunWithBSModel.py kör cntk med cntk.exe och en BrainScript-konfigurationsfil (konfigurationsinformation).
Den tränade modellen lagras i mappen cntkFiles/Output för motsvarande proc undermapp.
Den tränade modellen testas separat på både träningsuppsättningen och testuppsättningen.
Under testningen för varje bild och varje motsvarande ROI förutsägs och lagras en etikett i filerna test.z och train.z i cntkFiles mappen.
A3: Utvärderingssteget parsar CNTK-utdata och beräknar mAP:en som jämför de förutsagda resultaten med grund sanningsanteckningarna.
Icke-maximal undertryckning används för att sammanfoga överlappande ROI:er. Du kan ange tröskelvärdet för icke-maximal undertryckning i PARAMETERS.py (information).
Ytterligare skript
Det finns tre valfria skript som du kan köra för att visualisera och analysera data:
B1_VisualizeInputROIs.pyvisualiserar kandidatindata-ROI:er.B2_EvaluateInputROIs.pyberäknar återkallandet av grund sannings-ROIs med avseende på kandidat-ROIs.B3_VisualizeOutputROIs.pyvisualisera avgränsningsrutorna och förutsagda etiketter.
Kör Pascal VOC
Pascal VOC-data (PASCAL Visual Object Classes) är en välkänd uppsättning standardiserade bilder för objektklassigenkänning. Träning eller testning av CNTK Fast R-CNN på Pascal VOC-data kräver en GPU med minst 4 GB RAM-minne. Alternativt kan du köra med hjälp av CPU,vilket dock tar lite tid.
Hämta Pascal VOC-data
Du behöver data från 2007 (trainval och test) och 2012 (trainval) samt förberäknade ROI:er som används i originaldokumentet.
Du måste följa mappstrukturen som beskrivs nedan.
Skripten förutsätter att Pascal-data finns i $CNTK_ROOT/Examples/Image/DataSets/Pascal.
Om du använder en annan mapp anger pascalDataDir du på PARAMETERS.py motsvarande sätt.
- Ladda ned och packa upp 2012 trainval-data till
DataSets/Pascal/VOCdevkit2012 - Ladda ned och packa upp 2007 trainval-data till
DataSets/Pascal/VOCdevkit2007 - Ladda ned och packa upp 2007-testdata i samma mapp
DataSets/Pascal/VOCdevkit2007 - Ladda ned och packa upp förberäknade ROI:er till
DataSets/Pascal/selective_search_data* http://dl.dropboxusercontent.com/s/orrt7o6bp6ae0tc/selective_search_data.tgz?dl=0
Mappen VOCdevkit2007 bör se ut så här (liknande för 2012):
VOCdevkit2007/VOC2007
VOCdevkit2007/VOC2007/Annotations
VOCdevkit2007/VOC2007/ImageSets
VOCdevkit2007/VOC2007/JPEGImages
Köra CNTK på Pascal VOC
Om du vill köra Pascal VOC-data kontrollerar du att i PARAMETERS.pydataset är inställt "pascal"på .
- Kör
A1_GenerateInputROIs.pyför att generera CNTK-formaterade indatafiler för träning och testning från nedladdade ROI-data. - Kör
A2_RunWithBSModel.pyför att träna en snabb R-CNN-modell och beräkningstestresultat. - Kör
A3_ParseAndEvaluateOutput.pyför att beräkna mAP (genomsnittlig genomsnittlig precision) för den tränade modellen.- Observera att detta är pågående arbete och att resultaten är preliminära eftersom vi tränar nya baslinjemodeller.
- Se till att ha den senaste versionen från CNTK-originalet för filerna fastRCNN/pascal_voc.py och fastRCNN/voc_eval.py för att undvika kodningsfel.
Träna på dina egna data
Förbereda en anpassad datauppsättning
Alternativ 1: Visual Object Tagging Tool (rekommenderas)
Visual Object Tagging Tool (VOTT) är ett plattformsoberoende anteckningsverktyg för taggning av video- och bildtillgångar.

VOTT innehåller följande funktioner:
- Datorassisterad taggning och spårning av objekt i videor med hjälp av Camshift-spårningsalgoritmen.
- Exportera taggar och tillgångar till CNTK Fast-RCNN-format för träning av en objektidentifieringsmodell.
- Köra och verifiera en tränad CNTK-objektidentifieringsmodell på nya videor för att generera starkare modeller.
Så här kommenterar du med VOTT:
- Ladda ned den senaste versionen
- Följ Readme för att köra ett taggningsjobb
- När du har taggat Exportera taggar till datauppsättningskatalogen
Alternativ 2: Använda anteckningsskript
För att träna en CNTK Fast R-CNN-modell på din egen datauppsättning tillhandahåller vi två skript för att kommentera rektangulära regioner på bilder och tilldela etiketter till dessa regioner.
Skripten lagrar anteckningarna i rätt format enligt det första steget i att köra Fast R-CNN (A1_GenerateInputROIs.py).
Lagra först bilderna i följande mappstruktur
<your_image_folder>/negative– bilder som används för träning som inte innehåller några objekt<your_image_folder>/positive– bilder som används för träning som innehåller objekt<your_image_folder>/testImages– bilder som används för testning som innehåller objekt
För negativa avbildningar behöver du inte skapa några anteckningar. För de andra två mapparna använder du de angivna skripten:
- Kör
C1_DrawBboxesOnImages.pyför att rita avgränsningsrutor på bilderna.- I skriptuppsättningen
imgDir = <your_image_folder>(/positiveeller/testImages) innan du kör. - Lägg till anteckningar med hjälp av musmarkören. När alla objekt i en bild har kommenterats skriver du .bboxes.txt-filen genom att trycka på "n" och fortsätter sedan till nästa bild. U ångrar (d.v.s. tar bort) den sista rektangeln och "q" avslutar anteckningsverktyget.
- I skriptuppsättningen
- Kör
C2_AssignLabelsToBboxes.pyför att tilldela etiketter till avgränsningsrutorna.- I skriptuppsättningen
imgDir = <your_image_folder>(/positiveeller/testImages) innan du kör... - ... och anpassa klasserna i skriptet för att återspegla dina objektkategorier, till exempel
classes = ("dog", "cat", "octopus"). - Skriptet läser in dessa manuellt kommenterade rektanglar för varje bild, visar dem en i taget och ber användaren att ange objektklassen genom att klicka på respektive knapp till vänster i fönstret. Markanteckningar som markerats som antingen "osäkra" eller "exkluderade" utesluts helt från vidare bearbetning.
- I skriptuppsättningen
Träna på anpassad datauppsättning
Innan du kör CNTK Fast R-CNN med skript A1-A3 måste du lägga till datauppsättningen i PARAMETERS.py:
- Ange
dataset = "CustomDataset" - Lägg till parametrarna för din datauppsättning under Python-klassen
CustomDataset. Du kan börja med att kopiera parametrarna frånGroceryParameters- Anpassa klasserna så att de återspeglar objektkategorierna. I exemplet ovan skulle detta se ut som
self.classes = ('__background__', 'dog', 'cat', 'octopus'). - Ange
self.imgDir = <your_image_folder>. - Du kan också justera fler parametrar, t.ex. för ROI-generering och rensning (se avsnittet Parametrar ).
- Anpassa klasserna så att de återspeglar objektkategorierna. I exemplet ovan skulle detta se ut som
Redo att träna på dina egna data! (Använd samma steg som för leksaksexemplet.)
Teknisk information
Parametrar
Huvudparametrarna i PARAMETERS.py är
dataset– vilken datauppsättning som ska användascntk_nrRois– hur många ROI:er som ska användas för träning och testningnmsThreshold– Tröskelvärde för icke-maximal undertryckning (inom intervallet [0,1]). Ju lägre desto fler ROI:er kombineras. Den används för både utvärdering och visualisering.
Alla parametrar för ROI-generering, till exempel minsta och högsta bredd och höjd osv., beskrivs i PARAMETERS.py under Python-klassen Parameters. De är alla inställda på ett standardvärde som är rimligt.
Du kan skriva över dem i avsnittet # project-specific parameters som motsvarar den datauppsättning som du använder.
CNTK-konfiguration
Konfigurationsfilen för CNTK BrainScript som används för att träna och testa Fast R-CNN är fastrcnn.cntk.
Den del som konstruerar nätverket är BrainScriptNetworkBuilder avsnittet i Train kommandot :
BrainScriptNetworkBuilder = {
network = BS.Network.Load ("../../../../../../../PretrainedModels/AlexNet.model")
convLayers = BS.Network.CloneFunction(network.features, network.conv5_y, parameters = "constant")
fcLayers = BS.Network.CloneFunction(network.pool3, network.h2_d)
model (features, rois) = {
featNorm = features - 114
convOut = convLayers (featNorm)
roiOut = ROIPooling (convOut, rois, (6:6))
fcOut = fcLayers (roiOut)
W = ParameterTensor{($NumLabels$:4096), init="glorotUniform"}
b = ParameterTensor{$NumLabels$, init = 'zero'}
z = W * fcOut + b
}.z
imageShape = $ImageH$:$ImageW$:$ImageC$ # 1000:1000:3
labelShape = $NumLabels$:$NumTrainROIs$ # 21:64
ROIShape = 4:$NumTrainROIs$ # 4:64
features = Input {imageShape}
roiLabels = Input {labelShape}
rois = Input {ROIShape}
z = model (features, rois)
ce = CrossEntropyWithSoftmax(roiLabels, z, axis = 1)
errs = ClassificationError(roiLabels, z, axis = 1)
featureNodes = (features:rois)
labelNodes = (roiLabels)
criterionNodes = (ce)
evaluationNodes = (errs)
outputNodes = (z)
}
På den första raden läses den förtränade AlexNet in som basmodell. Nästa två delar av nätverket klonas: convLayers innehåller de faltningslager med konstanta vikter, dvs. de tränas inte ytterligare.
fcLayers innehåller de helt anslutna lagren med förtränade vikter, som kommer att tränas ytterligare.
Nodnamnen network.featuresosv network.conv5_y . kan härledas från att titta på loggutdata för cntk.exe-anropet (som finns i loggutdata för skriptet A2_RunWithBSModel.py ).
Modelldefinitionen(model (features, rois) = ...) normaliserar först funktionerna genom att subtrahera 114 för varje kanal och pixel.
Sedan skickas de normaliserade funktionerna genom convLayers följt av ROIPooling och slutligen fcLayers.
Utdataformen (width:height) för ROI-poolningsskiktet är inställd (6:6) på eftersom det här är formens storlek som den förtränade fcLayers från AlexNet-modellen förväntar sig. Utdata från fcLayers matas in i ett kompakt lager som förutsäger ett värde per etikett (NumLabels) för varje ROI.
Följande sex rader definierar indata:
- en bild med storleken 1 000 x 1 000 x 3 (
$ImageH$:$ImageW$:$ImageC$), - grundsanningsetiketter för varje ROI (
$NumLabels$:$NumTrainROIs$) - och fyra koordinater per ROI (
4:$NumTrainROIs$) som motsvarar (x, y, w, h), alla relativa med avseende på bildens fulla bredd och höjd.
z = model (features, rois) matar in indatabilderna och ROIs i den definierade nätverksmodellen och tilldelar utdata till z.
Både kriteriet (CrossEntropyWithSoftmax) och felet (ClassificationError) anges med axis = 1 för att ta hänsyn till förutsägelsefelet per ROI.
Läsaravsnittet i CNTK-konfigurationen visas nedan. Den använder tre deserialiserare:
ImageDeserializerför att läsa bilddata. Den hämtar bildfilnamnen fråntrain.txt, skalar bilden till önskad bredd och höjd samtidigt som höjdförhållandet bevaras (utfyllnad av tomma områden med114) och transponerar tensorn så att den har rätt indataform.- En
CNTKTextFormatDeserializerför att läsa ROI-koordinaterna fråntrain.rois.txt. - En sekund
CNTKTextFormatDeserializeratt läsa ROI-etiketterna fråntrain.roislabels.txt.
Indatafilformaten beskrivs i nästa avsnitt.
reader = {
randomize = false
verbosity = 2
deserializers = ({
type = "ImageDeserializer" ; module = "ImageReader"
file = train.txt
input = {
features = { transforms = (
{ type = "Scale" ; width = $ImageW$ ; height = $ImageW$ ; channels = $ImageC$ ; scaleMode = "pad" ; padValue = 114 }:
{ type = "Transpose" }
)}
ignored = {labelDim = 1000}
}
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.rois.txt
input = { rois = { dim = $TrainROIDim$ ; format = "dense" } }
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.roilabels.txt
input = { roiLabels = { dim = $TrainROILabelDim$ ; format = "dense" } }
})
}
CNTK-indatafilformat
Det finns tre indatafiler för CNTK Fast R-CNN som motsvarar de tre deserialiserare som beskrivs ovan:
train.txtinnehåller först ett sekvensnummer på varje rad, sedan ett bildfilnamn och slutligen ett0(som för närvarande fortfarande behövs av äldre orsaker till ImageReader).
0 image_01.jpg 0
1 image_02.jpg 0
...
train.rois.txt(CNTK-textformat) innehåller i varje rad först ett sekvensnummer, sedan identifieraren|roisföljt av en sekvens med tal. Det här är grupper med fyra tal som motsvarar (x, y, w, h) för en ROI, alla relativa med avseende på bildens fulla bredd och höjd. Det finns totalt 4 * antal rois-tal per rad.
0 |rois 0.2185 0.0 0.165 0.29 ...
train.roilabels.txt(CNTK-textformat) innehåller i varje rad först ett sekvensnummer, sedan identifieraren|roiLabelsföljt av en sekvens med tal. Det här är grupper med nummer för antal etiketter (antingen noll eller ett) per ROI-kodning av grundsanningsklassen i en enhetsrepresentation. Det finns totalt antal etiketter * antal rois-tal per rad.
0 |roiLabels 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
Information om algoritmer
Snabb R-CNN
R-CNN för objektidentifiering presenterades först 2014 av Ross Girshick et al., och visade sig överträffa tidigare toppmoderna metoder på en av de stora objektigenkänningsutmaningarna i fältet: Pascal VOC. Sedan dess har två uppföljningsdokument publicerats som innehåller betydande hastighetsförbättringar: Fast R-CNN och Faster R-CNN.
Den grundläggande idén med R-CNN är att ta ett djupt neuralt nätverk som ursprungligen tränades för bildklassificering med hjälp av miljontals kommenterade bilder och ändra det för objektidentifiering. Den grundläggande idén från den första R-CNN-uppsatsen illustreras i bilden nedan (hämtad från tidningen): (1) Givet en indatabild, (2) i ett första steg genereras ett stort antal regionförslag. (3) Dessa regionförslag eller intresseregioner skickas sedan oberoende via nätverket som matar ut en vektor med t.ex. 4 096 flyttalsvärden för varje ROI. Slutligen (4) lärs en klassificerare som tar 4096 float ROI-representationen som indata och matar ut en etikett och konfidens till varje ROI.
Även om den här metoden fungerar bra när det gäller noggrannhet är det mycket kostsamt att beräkna eftersom neurala nätverk måste utvärderas för varje ROI. Snabb R-CNN åtgärdar den här nackdelen genom att bara utvärdera det mesta av nätverket (för att vara specifik: decentraliseringsskikten) en enda gång per bild. Enligt författarna leder detta till en 213 gånger snabbare under testning och en 9x hastighet upp under träning utan förlust av noggrannhet. Detta uppnås med hjälp av ett ROI-poollager som projicerar ROI på den convolutional funktionskartan och utför maximal poolning för att generera önskad utdatastorlek som följande lager förväntar sig. I AlexNet-exemplet som används i den här självstudien placeras ROI-poollagret mellan det sista convolutional-lagret och det första fullständigt anslutna lagret (se BrainScript-kod).
Den ursprungliga Caffe-implementeringen som används i R-CNN-tidningarna finns på GitHub: RCNN, Fast R-CNN och Faster R-CNN. I den här självstudien används en del av koden från dessa lagringsplatser, särskilt (men inte uteslutande) för SVM-utbildning och modellutvärdering.
SVM- och NN-utbildning
Patrick Buehler ger instruktioner om hur du tränar en SVM på CNTK Fast R-CNN-utdata (med hjälp av 4096-funktionerna från det senaste helt anslutna lagret) samt en diskussion om för- och nackdelar här.
Selektiv sökning
Selektiv sökning är en metod för att hitta en stor uppsättning möjliga objektplatser i en bild, oberoende av klassen för det faktiska objektet. Den fungerar genom att gruppera bildpunkter i segment och sedan utföra hierarkisk klustring för att kombinera segment från samma objekt till objektförslag.



För att komplettera identifierade ROI:er från selektiv sökning lägger vi till ROI:er som enhetligt täcker bilden i olika skalor och proportioner. Den första bilden visar ett exempel på utdata från Selektiv sökning, där varje möjlig objektplats visualiseras av en grön rektangel. ROIs som är för små, för stora osv. ignoreras (andra bilden) och slutligen ROIs som enhetligt täcker bilden läggs till (tredje bild). Dessa rektanglar används sedan som Regions-of-Interests (ROIs) i R-CNN-pipelinen.
Målet med ROI-genereringen är att hitta en liten uppsättning ROI:er som dock täcker så många objekt i bilden som möjligt. Den här beräkningen måste vara tillräckligt snabb och samtidigt hitta objektplatser i olika skalor och proportioner. Selektiv sökning visade sig fungera bra för den här uppgiften, med god noggrannhet för att påskynda kompromisser.
NMS (icke-maximal undertryckning)
Objektidentifieringsmetoder matar ofta ut flera identifieringar som helt eller delvis täcker samma objekt i en bild.
Dessa ROI:er måste slås samman för att kunna räkna objekt och hämta sina exakta platser i bilden.
Detta görs traditionellt med hjälp av en teknik som kallas non maximum suppression (NMS). Den version av NMS som vi använder (och som också användes i R-CNN-publikationerna) sammanfogar inte ROIs utan försöker i stället identifiera vilka ROI:er som bäst täcker de verkliga platserna för ett objekt och tar bort alla andra ROI:er. Detta implementeras genom att iterativt välja ROI med högsta konfidens och ta bort alla andra ROI som avsevärt överlappar denna ROI och klassificeras som av samma klass. Tröskelvärdet för överlappningen kan anges i PARAMETERS.py (information).
Identifieringsresultat före (första bilden) och efter (andra bilden) Icke-maximal undertryckning:

mAP (genomsnittlig genomsnittlig precision)
När modellen har tränats kan den mätas med olika kriterier, till exempel precision, träffsäkerhet, ytunderkurva osv. Ett vanligt mått som används för pascal VOC-objektigenkänningsutmaningen är att mäta genomsnittlig precision (AP) för varje klass. Följande beskrivning av Average Precision hämtas från Everingham et. al. Medelvärdet av genomsnittlig precision (mAP) beräknas genom att medelvärdet över IP-adresserna för alla klasser tas.
För en viss uppgift och klass beräknas precisions-/träffsäkerhetskurvan från en metods rangordnade utdata. Recall definieras som andelen av alla positiva exempel som rangordnas över en viss rangordning. Precision är andelen av alla exempel ovanför rangordningen som kommer från den positiva klassen. AP sammanfattar formen på precisions-/träffsäkerhetskurvan och definieras som medelprecision vid en uppsättning med elva lika fördelade träffsäkerhetsnivåer [0,0,1, . . . ,1]:
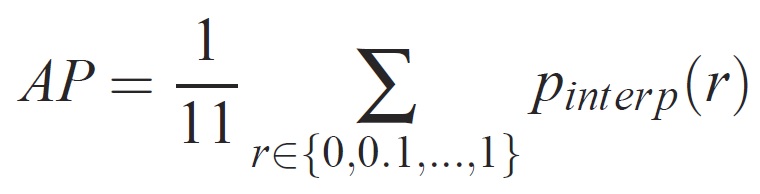
Precisionen på varje träffsäkerhetsnivå r interpoleras genom att den maximala precision som mäts för en metod för vilken motsvarande träffsäkerhet överskrider r:
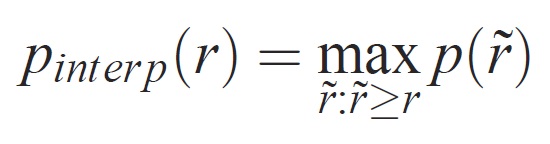
där p( ̃r) är den uppmätta precisionen vid träffsäkerhet. Avsikten med att interpolera precisions-/träffsäkerhetskurvan på detta sätt är att minska effekten av "wiggles" i precisions-/träffsäkerhetskurvan, vilket orsakas av små variationer i rangordningen av exempel. Det bör noteras att för att få en hög poäng, en metod måste ha precision på alla nivåer av återkallande - detta straffar metoder som hämtar endast en delmängd av exempel med hög precision (t.ex. sidovyer av bilar).