Objektidentifiering med snabb R-CNN
Innehållsförteckning
- Sammanfattning
- Installation
- Kör leksaksexemplet
- Träna på Pascal VOC-data
- Träna CNTK Fast R-CNN på dina egna data
- Teknisk information
- Algoritminformation
Sammanfattning

Den här självstudien beskriver hur du använder Fast R-CNN i CNTK Python-API:et. Snabb R-CNN med BrainScript och cnkt.exe beskrivs här.
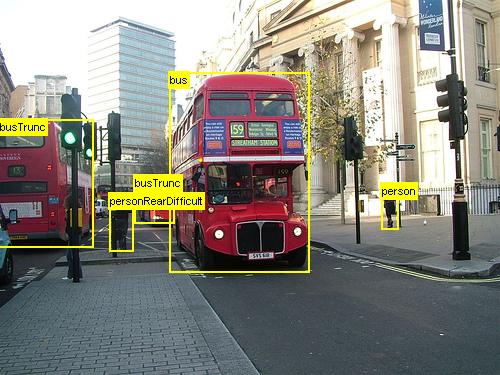
Ovanstående är exempel på bilder och objektkommentarer för datamängden för livsmedel (vänster) och Pascal VOC-datauppsättningen (höger) som används i den här självstudien.
Fast R-CNN är en objektidentifieringsalgoritm som föreslogs av Ross Girshick 2015. Dokumentet godkänns i ICCV 2015 och arkiveras på https://arxiv.org/abs/1504.08083. Snabb R-CNN bygger på tidigare arbete för att effektivt klassificera objektförslag med hjälp av djupa convolutional-nätverk. Jämfört med tidigare arbete använder Fast R-CNN ett schema för intressepooler som gör det möjligt att återanvända beräkningarna från de convolutional lagren.
Installation
Om du vill köra koden i det här exemplet behöver du en CNTK Python-miljö (se här för installationshjälp). Installera följande ytterligare paket i din cntk Python-miljö
pip install opencv-python easydict pyyaml dlib
Förkompilerade binärfiler för regression av avgränsningsrutor och icke-maximal undertryckning
Mappen Examples\Image\Detection\utils\cython_modules innehåller förkompilerade binärfiler som krävs för att köra Snabb R-CNN. De versioner som för närvarande finns på lagringsplatsen är Python 3.5 för Windows och Python 3.5, 3.6 för Linux, alla 64-bitars. Om du behöver en annan version kan du kompilera den enligt stegen som beskrivs i
- Linux: https://github.com/rbgirshick/py-faster-rcnn
- Windows: https://github.com/MrGF/py-faster-rcnn-windows
Kopiera binärfilerna genererade cython_bbox och (och/eller gpu_nms) från $FRCN_ROOT/lib/utils till $CNTK_ROOT/Examples/Image/Detection/utils/cython_modulescpu_nms .
Exempeldata och baslinjemodell
Vi använder en förtränad AlexNet-modell som grund för Fast-R-CNN-träning (för VGG eller andra basmodeller finns i Använda en annan basmodell. Både exempeldatauppsättningen och den förtränade AlexNet-modellen kan laddas ned genom att köra följande Python-kommando från FastRCNN-mappen:
python install_data_and_model.py
- Lär dig hur du använder en annan basmodell
- Lär dig hur du kör Snabba R-CNN på Pascal VOC-data
- Lär dig hur du kör Fast R-CNN på dina egna data
Kör leksaksexemplet
Träna och utvärdera snabb R-CNN-körning
python run_fast_rcnn.py
Resultaten för träning med 2 000 ROIs på Grocery med AlexNet som basmodell bör se ut ungefär så här:
AP for gerkin = 1.0000
AP for butter = 1.0000
AP for joghurt = 1.0000
AP for eggBox = 1.0000
AP for mustard = 1.0000
AP for champagne = 1.0000
AP for orange = 1.0000
AP for water = 0.5000
AP for avocado = 1.0000
AP for tomato = 1.0000
AP for pepper = 1.0000
AP for tabasco = 1.0000
AP for onion = 1.0000
AP for milk = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
Mean AP = 0.9479
Om du vill visualisera de förutsagda avgränsningsrutorna och etiketterna på bilderna öppnar FastRCNN_config.py du FastRCNN från mappen och ställer in
__C.VISUALIZE_RESULTS = True
Bilderna sparas i FastRCNN/Output/Grocery/ mappen om du kör python run_fast_rcnn.py.
Träna på Pascal VOC
Kör följande skript för att ladda ned Pascal-data och skapa anteckningsfilerna för Pascal i CNTK-format:
python Examples/Image/DataSets/Pascal/install_pascalvoc.py
python Examples/Image/DataSets/Pascal/mappings/create_mappings.py
dataset_cfg Ändra i get_configuration() -metoden run_fast_rcnn.py för till
from utils.configs.Pascal_config import cfg as dataset_cfg
Nu är du inställd på att träna på Pascal VOC 2007-data med hjälp av python run_fast_rcnn.py. Se upp för att träningen kan ta en stund.
Träna på dina egna data
Förbereda en anpassad datauppsättning
Alternativ 1: Visual Object Tagging Tool (rekommenderas)
Visual Object Tagging Tool (VOTT) är ett plattformsoberoende anteckningsverktyg för taggning av video- och bildtillgångar.

VOTT tillhandahåller följande funktioner:
- Datorassisterad taggning och spårning av objekt i videor med hjälp av Camshift-spårningsalgoritmen.
- Exportera taggar och tillgångar till CNTK Fast-RCNN-format för att träna en objektidentifieringsmodell.
- Köra och validera en tränad CNTK-objektidentifieringsmodell på nya videor för att generera starkare modeller.
Kommentera med VOTT:
- Ladda ned den senaste versionen
- Följ Readme för att köra ett taggningsjobb
- När du har taggat Exportera taggar till datauppsättningskatalogen
Alternativ 2: Använda anteckningsskript
För att träna en CNTK Fast R-CNN-modell på din egen datauppsättning tillhandahåller vi två skript för att kommentera rektangulära regioner på bilder och tilldela etiketter till dessa regioner.
Skripten lagrar anteckningarna i rätt format enligt det första steget i körningen av Fast R-CNN (A1_GenerateInputROIs.py).
Lagra först bilderna i följande mappstruktur
<your_image_folder>/negative– bilder som används för träning som inte innehåller några objekt<your_image_folder>/positive– bilder som används för träning som innehåller objekt<your_image_folder>/testImages– bilder som används för testning som innehåller objekt
För negativa avbildningar behöver du inte skapa några anteckningar. För de andra två mapparna använder du de angivna skripten:
- Kör
C1_DrawBboxesOnImages.pyför att rita avgränsningsrutor på bilderna.- I skriptuppsättningen
imgDir = <your_image_folder>(/positiveeller/testImages) innan den körs. - Lägg till anteckningar med musmarkören. När alla objekt i en bild har kommenterats skriver du .bboxes.txt-filen genom att trycka på "n" och fortsätter sedan till nästa bild, "u" ångrar (d.v.s. tar bort) den sista rektangeln och "q" avslutar anteckningsverktyget.
- I skriptuppsättningen
- Kör
C2_AssignLabelsToBboxes.pyför att tilldela etiketter till avgränsningsrutorna.- I skriptuppsättningen
imgDir = <your_image_folder>(/positiveeller/testImages) innan du kör... - ... och anpassa klasserna i skriptet så att de återspeglar dina objektkategorier, till exempel
classes = ("dog", "cat", "octopus"). - Skriptet läser in dessa manuellt kommenterade rektanglar för varje bild, visar dem en i taget och ber användaren att ange objektklassen genom att klicka på respektive knapp till vänster i fönstret. Grundsanningsanteckningar som markerats som antingen "osäkra" eller "exkluderade" utesluts helt från vidare bearbetning.
- I skriptuppsättningen
Träna på anpassad datauppsättning
När du har lagrat avbildningarna i den beskrivna mappstrukturen och kommenterat dem kör du
python Examples/Image/Detection/utils/annotations/annotations_helper.py
när du har ändrat mappen i skriptet till din datamapp. Skapa slutligen en MyDataSet_config.py i utils\configs mappen enligt de befintliga exemplen:
__C.CNTK.DATASET == "YourDataSet":
__C.CNTK.MAP_FILE_PATH = "../../DataSets/YourDataSet"
__C.CNTK.CLASS_MAP_FILE = "class_map.txt"
__C.CNTK.TRAIN_MAP_FILE = "train_img_file.txt"
__C.CNTK.TEST_MAP_FILE = "test_img_file.txt"
__C.CNTK.TRAIN_ROI_FILE = "train_roi_file.txt"
__C.CNTK.TEST_ROI_FILE = "test_roi_file.txt"
__C.CNTK.NUM_TRAIN_IMAGES = 500
__C.CNTK.NUM_TEST_IMAGES = 200
__C.CNTK.PROPOSAL_LAYER_SCALES = [8, 16, 32]
Observera att __C.CNTK.PROPOSAL_LAYER_SCALES inte används för Fast R-CNN, endast för Faster R-CNN.
Om du vill träna och utvärdera snabb R-CNN på dina data ändrar dataset_cfg du metoden get_configuration()run_fast_rcnn.py för till
from utils.configs.MyDataSet_config import cfg as dataset_cfg
och kör python run_fast_rcnn.py.
Teknisk information
Snabb R-CNN-algoritmen förklaras i avsnittet Algoritminformation tillsammans med en översikt över hur den implementeras i CNTK Python API. Det här avsnittet fokuserar på att konfigurera Snabb R-CNN och hur du använder olika basmodeller.
Parametrar
Parametrarna är grupperade i tre delar:
- Detektorparametrar (se
FastRCNN/FastRCNN_config.py) - Datauppsättningsparametrar (se till exempel
utils/configs/Grocery_config.py) - Basmodellparametrar (se till exempel
utils/configs/AlexNet_config.py)
De tre delarna läses in och sammanfogas i get_configuration() -metoden i run_fast_rcnn.py. I det här avsnittet går vi igenom detektorparametrarna. Datauppsättningsparametrar beskrivs här, basmodellparametrar här. I följande går vi igenom de viktigaste parametrarna i FastRCNN_config.py. Alla parametrar kommenteras också i filen. Konfigurationen använder paketet EasyDict som ger enkel åtkomst till kapslade ordlistor.
# Number of regions of interest [ROIs] proposals
__C.NUM_ROI_PROPOSALS = 200 # use 2000 or more for good results
# the minimum IoU (overlap) of a proposal to qualify for training regression targets
__C.BBOX_THRESH = 0.5
# Maximum number of ground truth annotations per image
__C.INPUT_ROIS_PER_IMAGE = 50
__C.IMAGE_WIDTH = 850
__C.IMAGE_HEIGHT = 850
# Use horizontally-flipped images during training?
__C.TRAIN.USE_FLIPPED = True
# If set to 'True' conv layers weights from the base model will be trained, too
__C.TRAIN_CONV_LAYERS = True
ROI-förslagen beräknas i farten i den första epoken med hjälp av implementeringen av selektiv sökning från dlib paketet. Antalet förslag som genereras styrs av parametern __C.NUM_ROI_PROPOSALS . Vi rekommenderar att du använder omkring 2000 förslag. Regressionshuvudet tränas endast på de ROI:er som har en överlappning (IoU) med en faktaruta på minst __C.BBOX_THRESH.
__C.INPUT_ROIS_PER_IMAGE anger det maximala antalet markanteckningar per bild. CNTK kräver för närvarande att ange ett maximalt antal. Om det finns färre anteckningar kommer de att fyllas ut internt. __C.IMAGE_WIDTH och __C.IMAGE_HEIGHT är de dimensioner som används för att ändra storlek på och fylla ut indatabilderna.
__C.TRAIN.USE_FLIPPED = True utökar träningsdata genom att vända alla bilder varannan epok, d.v.s. den första epoken har alla vanliga bilder, den andra har alla bilder vända och så vidare. __C.TRAIN_CONV_LAYERS avgör om de faltningsbegränsade lagren, från indata till funktionskartan för convolutional, ska tränas eller åtgärdas. Om du åtgärdar konvlagringsvikterna innebär det att vikterna från basmodellen tas och inte ändras under träningen. (Du kan också ange hur många konverade lager du vill träna, se avsnittet Använda en annan basmodell).
# NMS threshold used to discard overlapping predicted bounding boxes
__C.RESULTS_NMS_THRESHOLD = 0.5
# If set to True the following two parameters need to point to the corresponding files that contain the proposals:
# __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE
# __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE
__C.USE_PRECOMPUTED_PROPOSALS = False
__C.RESULTS_NMS_THRESHOLD är det NMS-tröskelvärde som används för att ignorera överlappande förutsagda avgränsningsrutor i utvärderingen. Ett lägre tröskelvärde ger färre borttagningar och därmed mer förutsagda avgränsningsrutor i de slutliga utdata. Om du ställer in __C.USE_PRECOMPUTED_PROPOSALS = True läser läsaren förberäknade ROI:er från textfiler. Detta används till exempel för träning på Pascal VOC-data. Filnamnen __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE och __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE anges i Examples/Image/Detection/utils/configs/Pascal_config.py.
# The basic segmentation is performed kvals.size() times. The k parameter is set (from, to, step_size)
__C.roi_ss_kvals = (10, 500, 5)
# When doing the basic segmentations prior to any box merging, all
# rectangles that have an area < min_size are discarded. Therefore, all outputs and
# subsequent merged rectangles are built out of rectangles that contain at
# least min_size pixels. Note that setting min_size to a smaller value than
# you might otherwise be interested in using can be useful since it allows a
# larger number of possible merged boxes to be created
__C.roi_ss_min_size = 9
# There are max_merging_iterations rounds of neighboring blob merging.
# Therefore, this parameter has some effect on the number of output rectangles
# you get, with larger values of the parameter giving more output rectangles.
# Hint: set __C.CNTK.DEBUG_OUTPUT=True to see the number of ROIs from selective search
__C.roi_ss_mm_iterations = 30
# image size used for ROI generation
__C.roi_ss_img_size = 200
Ovanstående parametrar konfigurerar dlibs selektiva sökning. Mer information finns på startsidan för dlib. Följande ytterligare parametrar används för att filtrera genererade ROIs w.r.t. minsta och högsta sidolängd, yta och bredd-förhållande.
# minimum relative width/height of an ROI
__C.roi_min_side_rel = 0.01
# maximum relative width/height of an ROI
__C.roi_max_side_rel = 1.0
# minimum relative area of an ROI
__C.roi_min_area_rel = 0.0001
# maximum relative area of an ROI
__C.roi_max_area_rel = 0.9
# maximum aspect ratio of an ROI vertically and horizontally
__C.roi_max_aspect_ratio = 4.0
# aspect ratios of ROIs for uniform grid ROIs
__C.roi_grid_aspect_ratios = [1.0, 2.0, 0.5]
Om selektiv sökning returnerar fler ROI:er än vad som begärts samplas de slumpmässigt. Om färre ROI:er returneras genereras ytterligare ROI:er i ett vanligt rutnät med hjälp av angivna __C.roi_grid_aspect_ratios.
Använda en annan basmodell
Om du vill använda en annan basmodell måste du välja en annan modellkonfiguration i get_configuration() metoden run_fast_rcnn.pyför . Två modeller stöds direkt:
# for VGG16 base model use: from utils.configs.VGG16_config import cfg as network_cfg
# for AlexNet base model use: from utils.configs.AlexNet_config import cfg as network_cfg
Om du vill ladda ned VGG16-modellen använder du nedladdningsskriptet i <cntkroot>/PretrainedModels:
python download_model.py VGG16_ImageNet_Caffe
Om du vill använda en annan basmodell måste du till exempel kopiera konfigurationsfilen utils/configs/VGG16_config.py och ändra den enligt basmodellen:
# model config
__C.MODEL.BASE_MODEL = "VGG16"
__C.MODEL.BASE_MODEL_FILE = "VGG16_ImageNet_Caffe.model"
__C.MODEL.IMG_PAD_COLOR = [103, 116, 123]
__C.MODEL.FEATURE_NODE_NAME = "data"
__C.MODEL.LAST_CONV_NODE_NAME = "relu5_3"
__C.MODEL.START_TRAIN_CONV_NODE_NAME = "pool2" # __C.MODEL.FEATURE_NODE_NAME
__C.MODEL.POOL_NODE_NAME = "pool5"
__C.MODEL.LAST_HIDDEN_NODE_NAME = "drop7"
__C.MODEL.FEATURE_STRIDE = 16
__C.MODEL.RPN_NUM_CHANNELS = 512
__C.MODEL.ROI_DIM = 7
Om du vill undersöka nodnamnen för basmodellen kan du använda plot() metoden från cntk.logging.graph. Observera att ResNet-modeller för närvarande inte stöds eftersom roi-poolning i CNTK ännu inte stöder roi-genomsnittlig poolning.
Information om algoritmer
Snabb R-CNN
R-CNN för objektidentifiering presenterades först 2014 av Ross Girshick et al., och visade sig överträffa tidigare toppmoderna metoder på en av de stora objektigenkänningsutmaningarna inom fältet: Pascal VOC. Sedan dess har två uppföljande artiklar publicerats som innehåller betydande hastighetsförbättringar: Fast R-CNN och Faster R-CNN.
Den grundläggande idén med R-CNN är att ta ett djupt neuralt nätverk som ursprungligen tränades för bildklassificering med hjälp av miljontals kommenterade bilder och ändra det för objektidentifiering. Den grundläggande idén från den första R-CNN-artikeln illustreras i figuren nedan (hämtad från tidningen): (1) Givet en indatabild, (2) i ett första steg, genereras ett stort antal regionförslag. (3) Dessa regionförslag, eller intresseregioner ( ROI), skickas sedan var och en oberoende via nätverket som matar ut en vektor med t.ex. Slutligen (4) lärs en klassificerare som tar 4096 float ROI-representationen som indata och matar ut en etikett och konfidens till varje ROI.

Även om den här metoden fungerar bra när det gäller noggrannhet är det mycket kostsamt att beräkna eftersom det neurala nätverket måste utvärderas för varje ROI. Snabb R-CNN åtgärdar den här nackdelen genom att bara utvärdera de flesta av nätverket (som ska vara specifika: faltningsskikten) en gång per bild. Enligt författarna leder detta till en 213 gånger snabbare under testning och en 9x hastighet upp under träning utan förlust av noggrannhet. Detta uppnås genom att använda ett ROI-poollager som projicerar ROI på den faltningsbara funktionskartan och utför maximal poolning för att generera önskad utdatastorlek som följande lager förväntar sig.
I AlexNet-exemplet som används i den här självstudien placeras ROI-poollagret mellan det sista convolutional-lagret och det första helt anslutna lagret. I CNTK Python API-koden som visas nedan realiseras detta genom kloning av två delar av nätverket, conv_layers och fc_layers. Indatabilden normaliseras sedan först, push-överförs genom conv_layers, skiktet roipooling och fc_layers slutligen läggs prediktions- och regressionshuvudena till som förutsäger klassetiketten respektive regressionskoefficienterna per kandidat-ROI.
def create_fast_rcnn_model(features, roi_proposals, label_targets, bbox_targets, bbox_inside_weights, cfg):
# Load the pre-trained classification net and clone layers
base_model = load_model(cfg['BASE_MODEL_PATH'])
conv_layers = clone_conv_layers(base_model, cfg)
fc_layers = clone_model(base_model, [cfg["MODEL"].POOL_NODE_NAME], [cfg["MODEL"].LAST_HIDDEN_NODE_NAME], clone_method=CloneMethod.clone)
# Normalization and conv layers
feat_norm = features - Constant([[[v]] for v in cfg["MODEL"].IMG_PAD_COLOR])
conv_out = conv_layers(feat_norm)
# Fast RCNN and losses
cls_score, bbox_pred = create_fast_rcnn_predictor(conv_out, roi_proposals, fc_layers, cfg)
detection_losses = create_detection_losses(...)
pred_error = classification_error(cls_score, label_targets, axis=1)
return detection_losses, pred_error
def create_fast_rcnn_predictor(conv_out, rois, fc_layers, cfg):
# RCNN
roi_out = roipooling(conv_out, rois, cntk.MAX_POOLING, (6, 6), spatial_scale=1/16.0)
fc_out = fc_layers(roi_out)
# prediction head
cls_score = plus(times(fc_out, W_pred), b_pred, name='cls_score')
# regression head
bbox_pred = plus(times(fc_out, W_regr), b_regr, name='bbox_regr')
return cls_score, bbox_pred
Den ursprungliga Caffe-implementeringen som används i R-CNN-tidningarna finns på GitHub: RCNN, Fast R-CNN och Faster R-CNN.
SVM- eller NN-utbildning
Patrick Buehler ger instruktioner om hur du tränar en stödvektormaskin på CNTK Fast R-CNN-utdata (med hjälp av 4096-funktionerna från det senaste helt anslutna lagret) samt en diskussion om för- och nackdelar här.
Selektiv sökning
Selektiv sökning är en metod för att hitta en stor uppsättning möjliga objektplatser i en bild, oberoende av klassen för det faktiska objektet. Det fungerar genom att gruppera bildpunkter i segment och sedan utföra hierarkisk klustring för att kombinera segment från samma objekt till objektförslag.



För att komplettera de identifierade ROI:erna från selektiv sökning lägger vi till ROI:er som täcker bilden i olika skalor och proportioner. Bilden till vänster visar ett exempel på utdata från Selektiv sökning, där varje möjlig objektplats visualiseras av en grön rektangel. ROI:er som är för små, för stora osv. ignoreras (i mitten) och slutligen läggs ROIs som täcker bilden enhetligt (höger). Dessa rektanglar används sedan som Intresseregioner (ROIs) i R-CNN-pipelinen.
Målet med ROI-generering är att hitta en liten uppsättning ROI:er som dock täcker så många objekt i bilden som möjligt. Den här beräkningen måste vara tillräckligt snabb, samtidigt som du hittar objektplatser på olika skalor och proportioner. Selektiv sökning visade sig fungera bra för den här uppgiften, med god noggrannhet för att påskynda kompromisser.
NMS (icke-maximal undertryckning)
Metoder för objektidentifiering matar ofta ut flera identifieringar som helt eller delvis täcker samma objekt i en bild.
Dessa ROI:er måste slås samman för att kunna räkna objekt och hämta sina exakta platser i bilden.
Detta görs traditionellt med hjälp av en teknik som kallas Non Maximum Suppression (NMS). Den version av NMS som vi använder (och som också användes i R-CNN-publikationerna) sammanfogar inte ROIs utan försöker istället identifiera vilka ROI:er som bäst täcker de verkliga platserna för ett objekt och tar bort alla andra ROI:er. Detta implementeras genom att iterativt välja ROI med högsta konfidens och ta bort alla andra ROI som avsevärt överlappar denna ROI och klassificeras som av samma klass. Tröskelvärdet för överlappningen kan anges i PARAMETERS.py (information).
Identifieringsresultat före (vänster) och efter (höger) Icke-maximal undertryckning:


mAP (genomsnittlig genomsnittlig precision)
När modellen har tränats kan den mätas med olika kriterier, till exempel precision, träffsäkerhet, area-under-kurva osv. Ett vanligt mått som används för Pascal VOC-objektigenkänningsutmaningen är att mäta genomsnittlig precision (AP) för varje klass. Följande beskrivning av Genomsnittlig precision hämtas från Everingham et. al. Genomsnittlig genomsnittlig precision (mAP) beräknas genom att medelvärdet över IP-adresserna för alla klasser tas.
För en viss uppgift och klass beräknas precisions-/träffsäkerhetskurvan från en metods rankade utdata. Träffsäkerhet definieras som andelen av alla positiva exempel som rangordnas ovanför en viss rangordning. Precision är andelen av alla exempel ovanför rangordningen som kommer från den positiva klassen. AP sammanfattar formen på precisions-/träffsäkerhetskurvan och definieras som medelprecision vid en uppsättning med elva lika fördelade träffsäkerhetsnivåer [0,0,1, . . . ,1]:
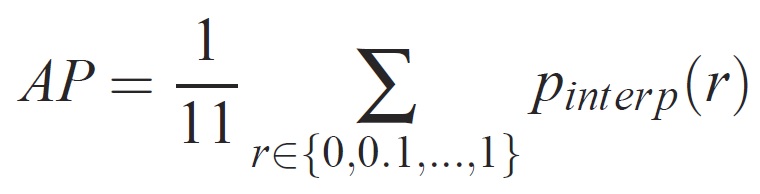
Precisionen på varje träffsäkerhetsnivå r interpoleras genom att den maximala precisionen som mäts för en metod för vilken motsvarande träffsäkerhet överskrider r:
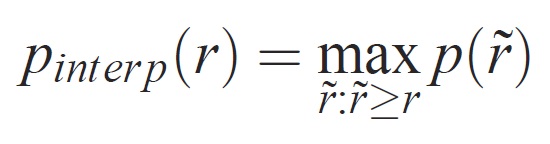
där p( ̃r) är den uppmätta precisionen vid träffsäkerhet. Avsikten med att interpolera precisions-/träffsäkerhetskurvan på detta sätt är att minska effekten av "viggles" i precisions-/träffsäkerhetskurvan, vilket orsakas av små variationer i rangordningen av exempel. Det bör noteras att för att få en hög poäng måste en metod ha precision på alla träffsäkerhetsnivåer – detta straffar metoder som endast hämtar en delmängd av exempel med hög precision (t.ex. sidovyer av bilar).