Stream data från Azure Storage Blob till Azure Data Lake Storage Gen1 med hjälp av Azure Stream Analytics
I den här artikeln får du lära dig hur du använder Azure Data Lake Storage Gen1 som utdata för ett Azure Stream Analytics-jobb. Den här artikeln visar ett enkelt scenario som läser data från en Azure Storage-blob (indata) och skriver data till Data Lake Storage Gen1 (utdata).
Förutsättningar
Innan du påbörjar de här självstudierna måste du ha:
En Azure-prenumeration. Se Hämta en kostnadsfri utvärderingsversion av Azure.
Azure Storage-konto. Du använder en blobcontainer från det här kontot för att mata in data för ett Stream Analytics-jobb. I den här självstudien förutsätter vi att du har ett lagringskonto med namnet storageforasa och en container i kontot storageforasacontainer. När du har skapat containern laddar du upp en exempeldatafil till den.
Ett Data Lake Storage Gen1 konto. Följ anvisningarna i Kom igång med Azure Data Lake Storage Gen1 med hjälp av Azure Portal. Anta att du har ett Data Lake Storage Gen1 konto med namnet myadlsg1.
Skapa ett Stream Analytics-jobb
Du börjar med att skapa ett Stream Analytics-jobb som innehåller en indatakälla och ett utdatamål. I den här självstudien är källan en Azure-blobcontainer och målet är Data Lake Storage Gen1.
Logga in på Azure Portal.
Klicka på Stream Analytics-jobb i den vänstra rutan och klicka sedan på Lägg till.

Anteckning
Se till att du skapar ett jobb i samma region som lagringskontot, annars medför du ytterligare kostnader för att flytta data mellan regioner.
Skapa blobindata för jobbet
Öppna sidan för Stream Analytics-jobbet. Klicka på fliken Indata i den vänstra rutan och klicka sedan på Lägg till.

Ange följande värden på bladet Ny indata .

För Indataalias anger du ett unikt namn för jobbets indata.
Som Källtyp väljer du Dataström.
För Källa väljer du Blob Storage.
För Prenumeration väljer du Använd bloblagring från den aktuella prenumerationen.
För Lagringskonto väljer du det lagringskonto som du skapade som en del av förutsättningarna.
För Container väljer du den container som du skapade i det valda lagringskontot.
I Format för händelseserialisering väljer du CSV.
För Avgränsare väljer du fliken.
För Kodning väljer du UTF-8.
Klicka på Skapa. Portalen lägger nu till indata och testar anslutningen till den.
Skapa ett Data Lake Storage Gen1 utdata för jobbet
Öppna sidan för Stream Analytics-jobbet, klicka på fliken Utdata, klicka på Lägg till och välj Data Lake Storage Gen1.

Ange följande värden på bladet Nya utdata .

- För Utdataalias anger du ett unikt namn för jobbets utdata. Det här är ett eget namn som används i frågor för att dirigera frågeutdata till det här Data Lake Storage Gen1 kontot.
- Du uppmanas att godkänna åtkomst till Data Lake Storage Gen1-kontot. Klicka på Auktorisera.
På bladet Nya utdata fortsätter du att ange följande värden.

Som Kontonamn väljer du det Data Lake Storage Gen1 konto som du redan har skapat där du vill att jobbutdata ska skickas till.
För Sökvägsprefixmönster anger du en filsökväg som används för att skriva dina filer inom det angivna Data Lake Storage Gen1-kontot.
Om du använde en datumtoken i prefixsökvägen i datumformatet kan du välja det datumformat som filerna är ordnade i.
Om du använde en tidstoken i prefixsökvägen i tidsformat anger du tidsformatet som filerna är ordnade i.
I Format för händelseserialisering väljer du CSV.
För Avgränsare väljer du fliken.
För Kodning väljer du UTF-8.
Klicka på Skapa. Portalen lägger nu till utdata och testar anslutningen till den.
Köra Stream Analytics-jobbet
Om du vill köra ett Stream Analytics-jobb måste du köra en fråga från fliken Fråga. I den här självstudien kan du köra exempelfrågan genom att ersätta platshållarna med jobbets indata- och utdataalias, enligt skärmbilden nedan.

Klicka på Spara överst på skärmen och klicka sedan på Starta på fliken Översikt. I dialogrutan väljer du Anpassad tid och anger sedan aktuellt datum och tid.

Klicka på Start för att starta jobbet. Det kan ta upp till ett par minuter att starta jobbet.
Om du vill utlösa jobbet för att välja data från bloben kopierar du en exempeldatafil till blobcontainern. Du kan hämta en exempeldatafil från Azure Data Lake Git-lagringsplatsen. I den här självstudien kopierar vi filen vehicle1_09142014.csv. Du kan använda olika klienter, till exempel Azure Storage Explorer, för att ladda upp data till en blobcontainer.
På fliken Översikt under Övervakning kan du se hur data bearbetades.
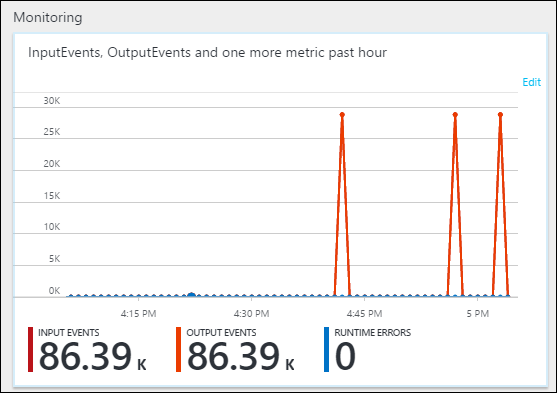
Slutligen kan du kontrollera att jobbets utdata är tillgängliga i Data Lake Storage Gen1-kontot.

Observera att utdata skrivs till en mappsökväg som anges i Data Lake Storage Gen1 utdatainställningar (
streamanalytics/job/output/{date}/{time}) i fönstret Data Explorer.