Skapa HDInsight-kluster med Azure Data Lake Storage Gen1 med hjälp av Azure Portal
Lär dig hur du använder Azure Portal för att skapa ett HDInsight-kluster med Azure Data Lake Storage Gen1 som standardlagring eller ytterligare lagring. Även om ytterligare lagring är valfritt för ett HDInsight-kluster rekommenderar vi att du lagrar dina affärsdata i de ytterligare lagringskontona.
Förutsättningar
Kontrollera att du uppfyller följande krav innan du börjar:
- En Azure-prenumeration. Gå till Hämta kostnadsfri utvärderingsversion av Azure.
- Ett Azure Data Lake Storage Gen1-konto. Följ anvisningarna från Kom igång med Azure Data Lake Storage Gen1 med hjälp av Azure Portal. Du måste också skapa en rotmapp för kontot. I den här artikeln används en rotmapp med namnet /clusters .
- ett Microsoft Entra tjänstens huvudnamn. Den här instruktionsguiden innehåller instruktioner om hur du skapar ett huvudnamn för tjänsten i Microsoft Entra ID. Men om du vill skapa ett huvudnamn för tjänsten måste du vara Microsoft Entra administratör. Om du är administratör kan du hoppa över det här kravet och fortsätta.
Anteckning
Du kan bara skapa ett huvudnamn för tjänsten om du är Microsoft Entra administratör. Din Microsoft Entra-administratör måste skapa ett huvudnamn för tjänsten innan du kan skapa ett HDInsight-kluster med Data Lake Storage Gen1. Dessutom måste tjänstens huvudnamn skapas med ett certifikat, enligt beskrivningen i Skapa ett tjänsthuvudnamn med certifikat.
Skapa ett HDInsight-kluster
I det här avsnittet skapar du ett HDInsight-kluster med Data Lake Storage Gen1 som standard eller ytterligare lagring. Den här artikeln fokuserar bara på den del av konfigurationen av Data Lake Storage Gen1. Allmän information om och procedurer för att skapa kluster finns i Skapa Hadoop-kluster i HDInsight.
Skapa ett kluster med Data Lake Storage Gen1 som standardlagring
Så här skapar du ett HDInsight-kluster med en Data Lake Storage Gen1 som standardlagringskonto:
Logga in på Azure-portalen.
Följ Skapa kluster för allmän information om hur du skapar HDInsight-kluster.
På bladet Lagring under Primär lagringstyp väljer du Azure Data Lake Storage Gen1 och anger sedan följande information:
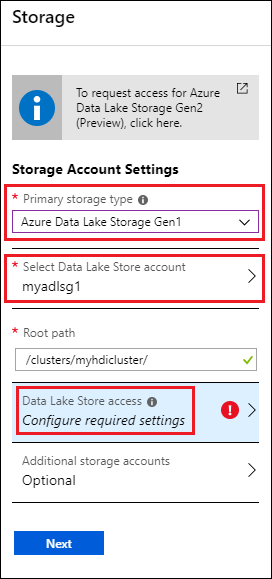
- Välj Data Lake Store-konto: Välj ett befintligt Data Lake Storage Gen1 konto. Ett befintligt Data Lake Storage Gen1 konto krävs. Se Förutsättningar.
- Rotsökväg: Ange en sökväg där de klusterspecifika filerna ska lagras. På skärmbilden är det /clusters/myhdiadlcluster/, där mappen /clusters måste finnas och mappen myhdicluster skapas i portalen. Myhdicluster är klusternamnet.
- Data Lake Store-åtkomst: Konfigurera åtkomst mellan Data Lake Storage Gen1-kontot och HDInsight-klustret. Anvisningar finns i Konfigurera Data Lake Storage Gen1 åtkomst.
- Ytterligare lagringskonton: Lägg till Azure Storage-konton som ytterligare lagringskonton för klustret. Om du vill lägga till ytterligare Data Lake Storage Gen1 konton görs genom att ge klustret behörigheter för data i fler Data Lake Storage Gen1 konton medan du konfigurerar ett Data Lake Storage Gen1 konto som den primära lagringstypen. Se Konfigurera Data Lake Storage Gen1 åtkomst.
I Data Lake Store-åtkomsten klickar du på Välj och fortsätter sedan med att skapa kluster enligt beskrivningen i Skapa Hadoop-kluster i HDInsight.
Skapa ett kluster med Data Lake Storage Gen1 som ytterligare lagring
Följande instruktioner skapar ett HDInsight-kluster med ett Azure Blob Storage-konto som standardlagring och ett lagringskonto med Data Lake Storage Gen1 som ytterligare lagringsutrymme.
Så här skapar du ett HDInsight-kluster med Data Lake Storage Gen1 som ytterligare ett lagringskonto:
Logga in på Azure-portalen.
Följ Skapa kluster för allmän information om hur du skapar HDInsight-kluster.
På bladet Lagring under Primär lagringstyp väljer du Azure Storage och anger sedan följande information:
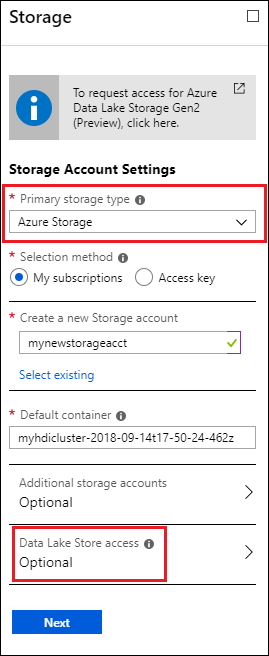
Urvalsmetod – Om du vill ange ett lagringskonto som ingår i din Azure-prenumeration väljer du Mina prenumerationer och väljer sedan lagringskontot. Om du vill ange ett lagringskonto som ligger utanför din Azure-prenumeration väljer du Åtkomstnyckel och anger sedan informationen för det externa lagringskontot.
Standardcontainer – Använd antingen standardvärdet eller ange ditt eget namn.
Ytterligare lagringskonton – Lägg till fler Azure Storage-konton som ytterligare lagring.
Data Lake Store-åtkomst – Konfigurera åtkomst mellan Data Lake Storage Gen1-kontot och HDInsight-klustret. Anvisningar finns i Konfigurera Data Lake Storage Gen1 åtkomst.
Konfigurera Data Lake Storage Gen1 åtkomst
I det här avsnittet konfigurerar du Data Lake Storage Gen1 åtkomst från HDInsight-kluster med hjälp av ett Microsoft Entra tjänstens huvudnamn.
Ange ett huvudnamn för tjänsten
Från Azure Portal kan du antingen använda ett befintligt tjänsthuvudnamn eller skapa ett nytt.
Så här skapar du ett huvudnamn för tjänsten från Azure Portal:
- Se Skapa tjänstens huvudnamn och certifikat med Microsoft Entra ID.
Så här använder du ett befintligt huvudnamn för tjänsten från Azure Portal:
Tjänstens huvudnamn bör ha ägarbehörighet för lagringskontot. Se Konfigurera behörigheter för tjänstens huvudnamn som ska vara ägare till lagringskontot.
Välj Data Lake Store-åtkomst.
På bladet Data Lake Storage Gen1 åtkomst väljer du Använd befintlig.
Välj Tjänstens huvudnamn och välj sedan ett huvudnamn för tjänsten.
Ladda upp certifikatet (.pfx-filen) som är associerat med det valda tjänstens huvudnamn och ange sedan certifikatlösenordet.
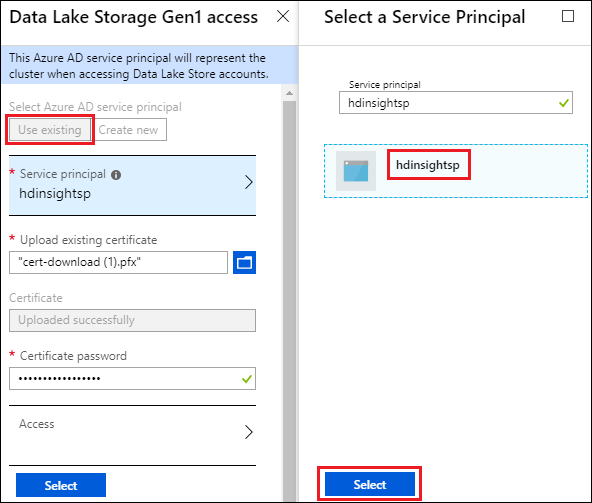
Välj Åtkomst för att konfigurera mappåtkomsten. Se Konfigurera filbehörigheter.
Konfigurera behörigheter för tjänstens huvudnamn som ägare på lagringskontot
- På bladet Access Control(IAM) för lagringskontot klickar du på Lägg till en rolltilldelning.
- På bladet Lägg till en rolltilldelning väljer du Roll som "ägare" och väljer SPN och klickar på Spara.
Konfigurera filbehörigheter
Konfigurationen skiljer sig beroende på om kontot används som standardlagring eller ett extra lagringskonto:
Används som standardlagring
- behörighet på rotnivå för Data Lake Storage Gen1-kontot
- behörighet på rotnivå för HDInsight-klusterlagringen. Till exempel mappen /clusters som användes tidigare i självstudien.
Använda som ytterligare lagring
- Behörighet i mapparna där du behöver filåtkomst.
Så här tilldelar du behörighet på lagringskontot med Data Lake Storage Gen1 på rotnivå:
På bladet Data Lake Storage Gen1 åtkomst väljer du Åtkomst. Bladet Välj filbehörigheter öppnas. Den visar alla lagringskonton i din prenumeration.
Hovra (klicka inte) musen över namnet på kontot med Data Lake Storage Gen1 för att göra kryssrutan synlig och markera sedan kryssrutan.
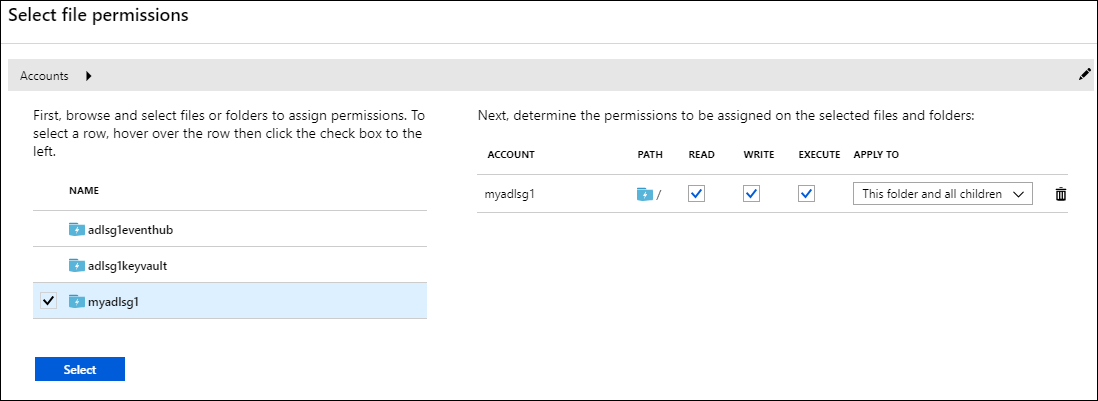
Som standard markeras alla READ, WRITE och EXECUTE .
Klicka på Välj längst ned på sidan.
Välj Kör för att tilldela behörighet.
Välj Klar.
Så här tilldelar du behörighet på ROT-nivån för HDInsight-klustret:
- På bladet Data Lake Storage Gen1 åtkomst väljer du Åtkomst. Bladet Välj filbehörigheter öppnas. Den visar alla lagringskonton med Data Lake Storage Gen1 i din prenumeration.
- På bladet Välj filbehörigheter väljer du lagringskontot med Data Lake Storage Gen1 namn för att visa dess innehåll.
- Markera roten för HDInsight-klusterlagring genom att markera kryssrutan till vänster om mappen. Enligt skärmbilden tidigare är klusterlagringsroten mappen /clusters som du angav när du valde Data Lake Storage Gen1 som standardlagring.
- Ange behörigheter för mappen. Som standard är alla läsningar, skrivning och körning markerade.
- Klicka på Välj längst ned på sidan.
- Välj Kör.
- Välj Klar.
Om du använder Data Lake Storage Gen1 som ytterligare lagring måste du endast tilldela behörighet för de mappar som du vill komma åt från HDInsight-klustret. I skärmbilden nedan ger du till exempel endast åtkomst till mappen mynewfolder i ett lagringskonto med Data Lake Storage Gen1.
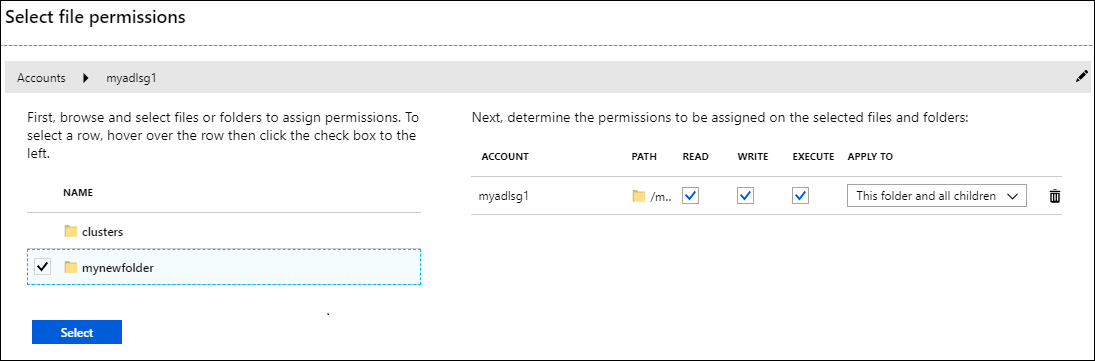
Verifiera klusterkonfigurationen
När klusterkonfigurationen är klar kontrollerar du resultatet på klusterbladet genom att utföra något av eller båda av följande steg:
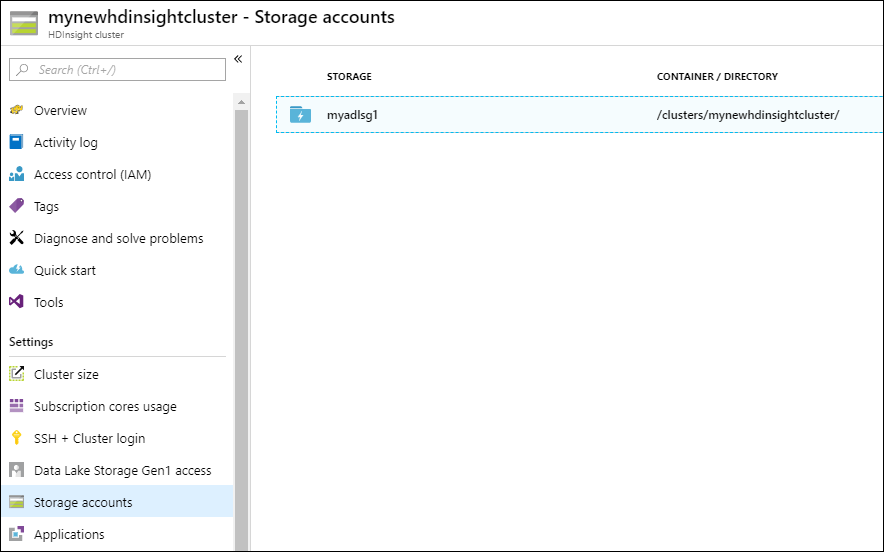
Om du vill kontrollera att den associerade lagringen för klustret är kontot med Data Lake Storage Gen1 som du har angett väljer du Lagringskonton i det vänstra fönstret.
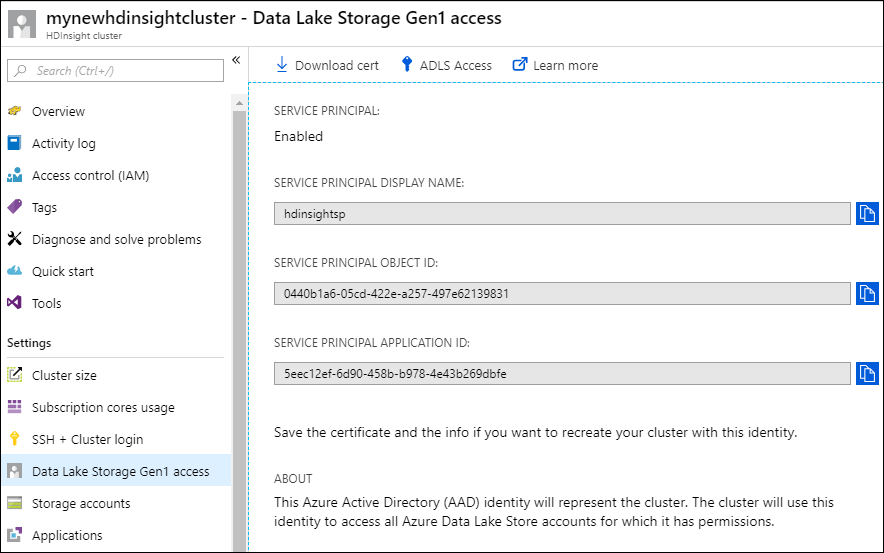
Kontrollera att tjänstens huvudnamn är korrekt kopplat till HDInsight-klustret genom att välja Data Lake Storage Gen1 åtkomst i det vänstra fönstret.
Exempel
När du har konfigurerat klustret med Data Lake Storage Gen1 som lagring kan du se de här exemplen på hur du använder HDInsight-kluster för att analysera de data som lagras i Data Lake Storage Gen1.
Köra en Hive-fråga mot data i en Data Lake Storage Gen1 (som primär lagring)
Om du vill köra en Hive-fråga använder du Gränssnittet för Hive-vyer i Ambari-portalen. Anvisningar om hur du använder Ambari Hive-vyer finns i Använda Hive-vyn med Hadoop i HDInsight.
När du arbetar med data i en Data Lake Storage Gen1 finns det några strängar att ändra.
Om du till exempel använder klustret som du skapade med Data Lake Storage Gen1 som primär lagring är sökvägen till data: adl://< data_lake_storage_gen1_account_name>/azuredatalakestore.net/path/to/file. En Hive-fråga för att skapa en tabell från exempeldata som lagras i Data Lake Storage Gen1 ser ut som följande instruktion:
CREATE EXTERNAL TABLE websitelog (str string) LOCATION 'adl://hdiadlsg1storage.azuredatalakestore.net/clusters/myhdiadlcluster/HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/'
Beskrivningar:
-
adl://hdiadlsg1storage.azuredatalakestore.net/är roten för kontot med Data Lake Storage Gen1. -
/clusters/myhdiadlclusterär roten för de klusterdata som du angav när du skapade klustret. -
/HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/är platsen för exempelfilen som du använde i frågan.
Köra en Hive-fråga mot data i en Data Lake Storage Gen1 (som ytterligare lagring)
Om klustret som du skapade använder Blob Storage som standardlagring finns inte exempeldata i lagringskontot med Data Lake Storage Gen1 som används som ytterligare lagring. I så fall överför du först data från Blob Storage till lagringskontot med Data Lake Storage Gen1 och kör sedan frågorna enligt föregående exempel.
Information om hur du kopierar data från Blob Storage till ett lagringskonto med Data Lake Storage Gen1 finns i följande artiklar:
- Använd Distcp för att kopiera data mellan Azure Blob Storage och Data Lake Storage Gen1
- Använd AdlCopy för att kopiera data från Azure Blob Storage till Data Lake Storage Gen1
Använda Data Lake Storage Gen1 med ett Spark-kluster
Du kan använda ett Spark-kluster för att köra Spark-jobb på data som lagras i en Data Lake Storage Gen1. Mer information finns i Använda HDInsight Spark-kluster för att analysera data i Data Lake Storage Gen1.