Justera Azure Data Lake Storage Gen1 för prestanda
Data Lake Storage Gen1 stöder högt dataflöde för I/O-intensiv analys och dataflytt. I Data Lake Storage Gen1 är det viktigt att använda alla tillgängliga dataflöden – mängden data som kan läsas eller skrivas per sekund – för att få bästa möjliga prestanda. Detta uppnås genom att utföra så många läsningar och skrivningar parallellt som möjligt.
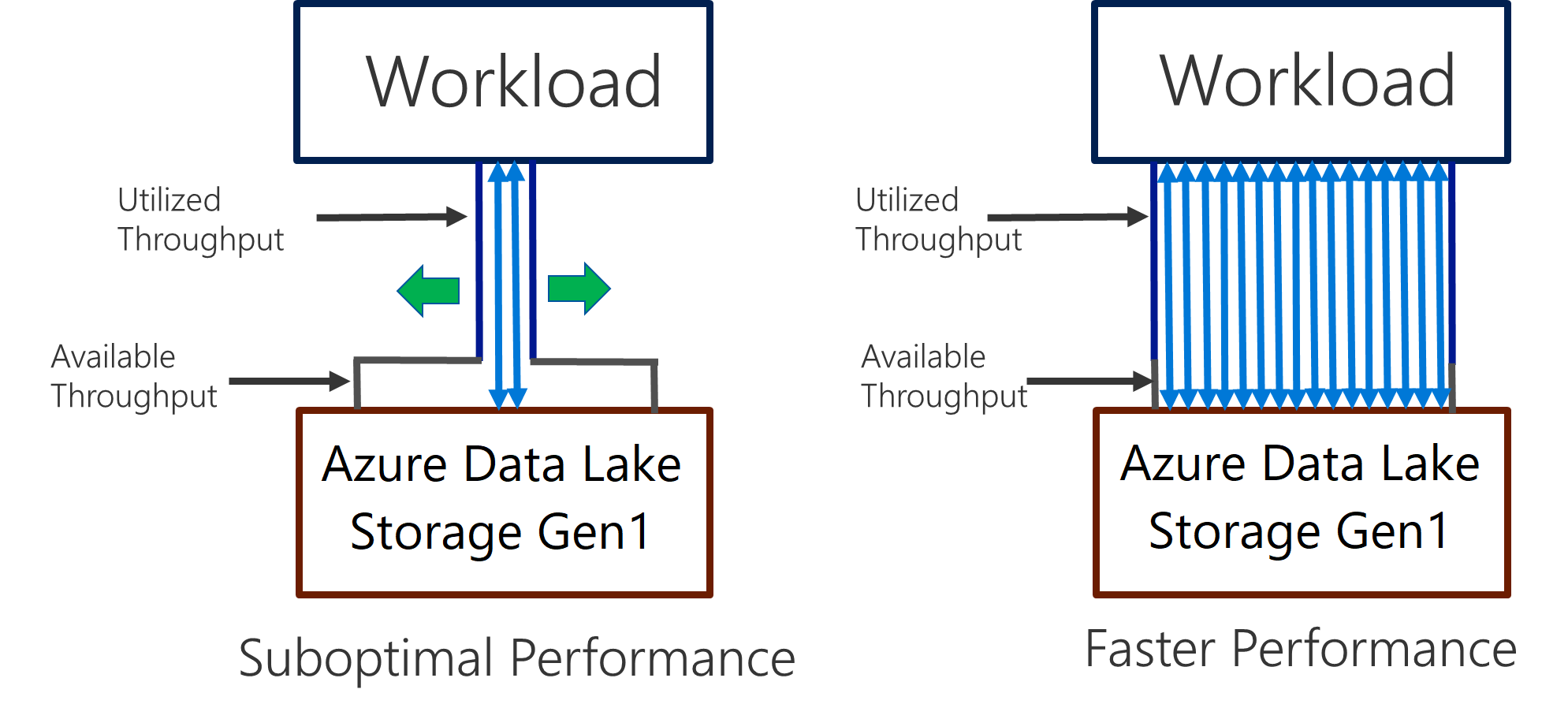
Data Lake Storage Gen1 kan skalas för att tillhandahålla det dataflöde som krävs för alla analysscenarion. Som standard ger ett Data Lake Storage Gen1-konto automatiskt tillräckligt dataflöde för att uppfylla behoven i en bred kategori av användningsfall. I de fall där kunder stöter på standardgränsen kan Data Lake Storage Gen1-kontot konfigureras för att ge mer dataflöde genom att kontakta Microsofts support.
Datainhämtning
När du matar in data från ett källsystem till Data Lake Storage Gen1 är det viktigt att tänka på att källmaskinvaran, källnätverksmaskinvaran och nätverksanslutningen till Data Lake Storage Gen1 kan vara flaskhalsen.
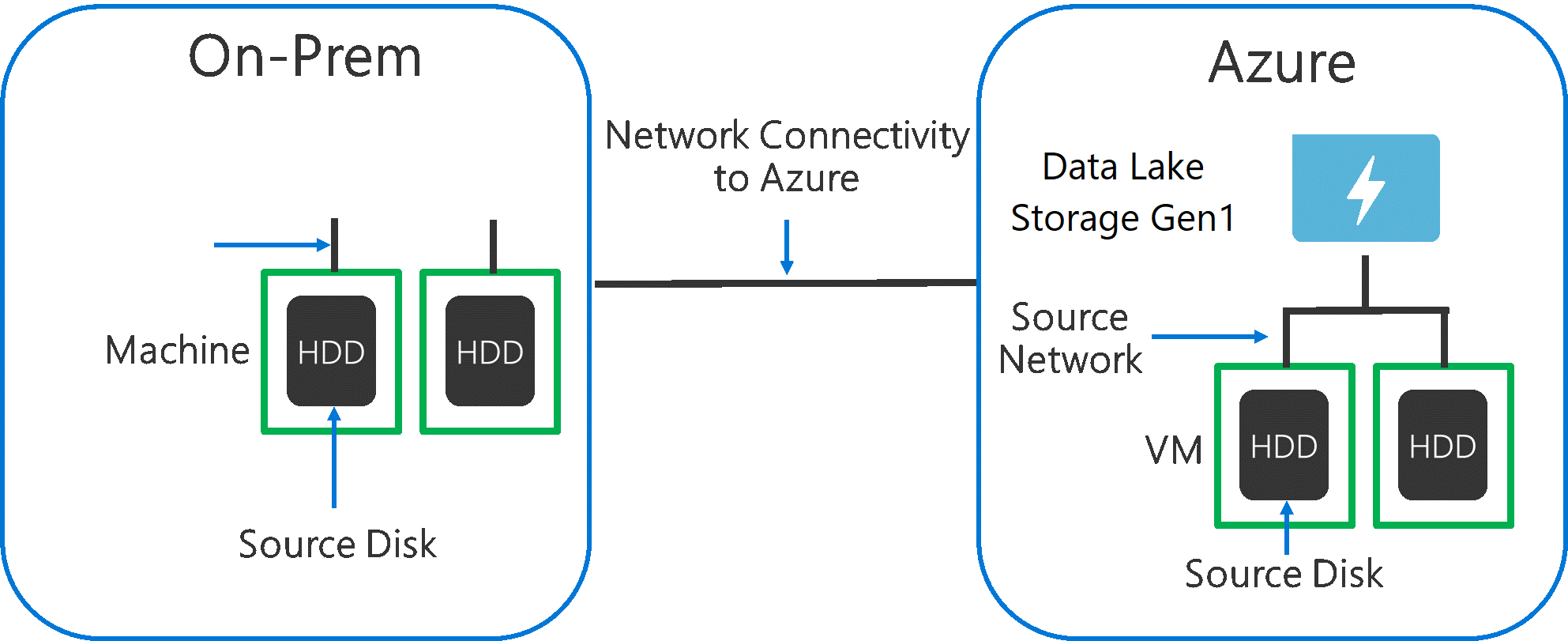
Det är viktigt att se till att dataflytten inte påverkas av dessa faktorer.
Källmaskinvara
Oavsett om du använder lokala datorer eller virtuella datorer i Azure bör du noggrant välja lämplig maskinvara. För Källdiskmaskinvara föredrar du SSD:n för hårddiskar och väljer diskmaskinvara med snabbare spindlar. Använd snabbaste möjliga nätverkskort för maskinvara för källnätverk. I Azure rekommenderar vi virtuella Azure D14-datorer som har lämplig kraftfull disk- och nätverksmaskinvara.
Nätverksanslutning till Data Lake Storage Gen1
Nätverksanslutningen mellan dina källdata och Data Lake Storage Gen1 kan ibland vara flaskhalsen. När dina källdata är lokala bör du överväga att använda en dedikerad länk med Azure ExpressRoute . Om dina källdata finns i Azure är prestandan bäst när data finns i samma Azure-region som det Data Lake Storage Gen1 kontot.
Konfigurera datainmatningsverktyg för maximal parallellisering
När du har åtgärdat flaskhalsarna i källmaskinvaran och nätverksanslutningen är du redo att konfigurera dina inmatningsverktyg. I följande tabell sammanfattas nyckelinställningarna för flera populära inmatningsverktyg och innehåller artiklar om djupgående prestandajustering för dem. Mer information om vilket verktyg som ska användas för ditt scenario finns i den här artikeln.
| Verktyg | Inställningar | Mer information |
|---|---|---|
| PowerShell | PerFileThreadCount, ConcurrentFileCount | Länk |
| AdlCopy | Azure Data Lake Analytics-enheter | Länk |
| DistCp | -m (mappare) | Länk |
| Azure Data Factory | parallelCopies | Länk |
| Sqoop | fs.azure.block.size, -m (mappning) | Länk |
Strukturera datauppsättningen
När data lagras i Data Lake Storage Gen1 påverkar filstorleken, antalet filer och mappstrukturen prestanda. I följande avsnitt beskrivs metodtips inom dessa områden.
Filstorlek
Vanligtvis har analysmotorer som HDInsight och Azure Data Lake Analytics en kostnad per fil. Om du lagrar dina data som många små filer kan detta påverka prestanda negativt.
I allmänhet kan du ordna dina data i större filer för bättre prestanda. Som tumregel ordnar du datauppsättningar i filer på 256 MB eller större. I vissa fall, till exempel bilder och binära data, går det inte att bearbeta dem parallellt. I dessa fall rekommenderar vi att du håller enskilda filer under 2 GB.
Ibland har datapipelines begränsad kontroll över rådata som innehåller många små filer. Vi rekommenderar att du har en "matlagningsprocess" som genererar större filer som ska användas för underordnade program.
Organisera tidsseriedata i mappar
För Hive- och ADLA-arbetsbelastningar kan partitionsrensning av tidsseriedata hjälpa vissa frågor att bara läsa en delmängd av data, vilket förbättrar prestandan.
De pipelines som matar in tidsseriedata placerar ofta sina filer med strukturerad namngivning för filer och mappar. Följande är ett vanligt exempel för data som är strukturerade efter datum: \DataSet\ÅÅÅÅ\MM\DD\datafile_YYYY_MM_DD.tsv.
Observera att datetime-informationen visas både som mappar och i filnamnet.
För datum och tid är följande ett vanligt mönster: \DataSet\YYYY\MM\DD\HH\mm\datafile_YYYY_MM_DD_HH_mm.tsv.
Återigen bör valet du gör med mappen och filorganisationen optimeras för de större filstorlekarna och ett rimligt antal filer i varje mapp.
Optimera I/O-intensiva jobb på Hadoop- och Spark-arbetsbelastningar i HDInsight
Jobben delas in i någon av följande tre kategorier:
- PROCESSORintensiv. De här jobben har långa beräkningstider med minimala I/O-tider. Exempel är maskininlärning och bearbetningsjobb på naturligt språk.
- Minneskrävande. De här jobben använder mycket minne. Exempel är PageRank- och realtidsanalysjobb.
- I/O-intensiv. De här jobben ägnar större delen av sin tid åt att utföra I/O. Ett vanligt exempel är ett kopieringsjobb som bara utför läs- och skrivåtgärder. Andra exempel är dataförberedelsejobb som läser flera data, utför viss datatransformering och sedan skriver tillbaka data till lagret.
Följande vägledning gäller endast för I/O-intensiva jobb.
Allmänna överväganden för ett HDInsight-kluster
- HDInsight-versioner. Använd den senaste versionen av HDInsight för bästa prestanda.
- Regioner. Placera Data Lake Storage Gen1-kontot i samma region som HDInsight-klustret.
Ett HDInsight-kluster består av två huvudnoder och vissa arbetsnoder. Varje arbetsnod tillhandahåller ett visst antal kärnor och minne, vilket bestäms av VM-typen. När du kör ett jobb är YARN resursförhandlaren som allokerar tillgängligt minne och kärnor för att skapa containrar. Varje container kör de uppgifter som krävs för att slutföra jobbet. Containrar körs parallellt för att bearbeta uppgifter snabbt. Därför förbättras prestandan genom att köra så många parallella containrar som möjligt.
Det finns tre lager i ett HDInsight-kluster som kan justeras för att öka antalet containrar och använda alla tillgängliga dataflöden.
- Fysiskt lager
- YARN-lager
- Arbetsbelastningslager
Fysiskt lager
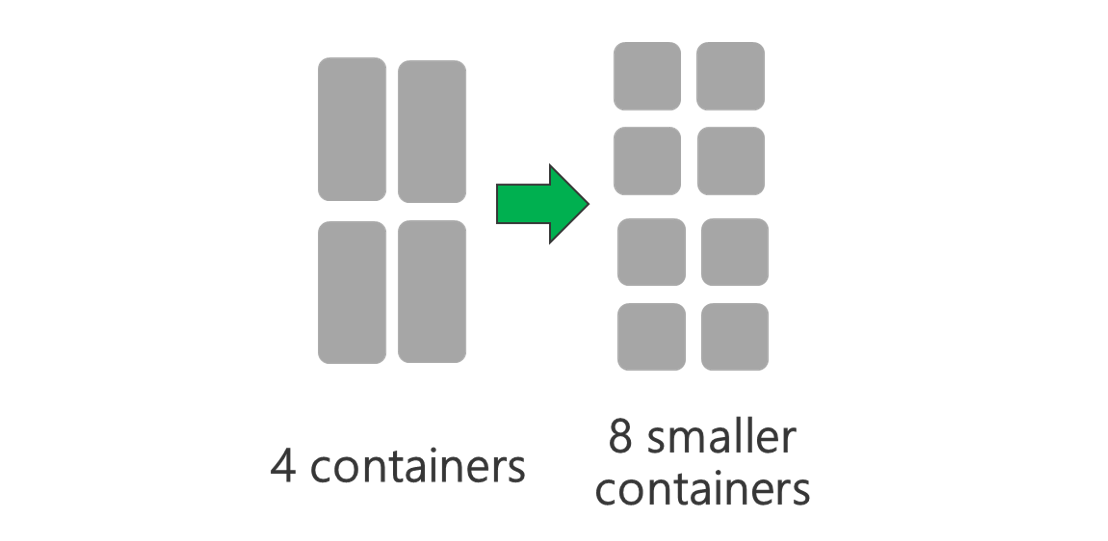
Kör kluster med fler noder och/eller större virtuella datorer. Med ett större kluster kan du köra fler YARN-containrar enligt bilden nedan.

Använd virtuella datorer med mer nätverksbandbredd. Mängden nätverksbandbredd kan vara en flaskhals om nätverksbandbredden är mindre än Data Lake Storage Gen1 dataflödet. Olika virtuella datorer har olika storlekar på nätverksbandbredd. Välj en VM-typ som har största möjliga nätverksbandbredd.
YARN-lager
Använd mindre YARN-containrar. Minska storleken på varje YARN-container för att skapa fler containrar med samma mängd resurser.
Beroende på din arbetsbelastning finns det alltid en minsta YARN-containerstorlek som behövs. Om du väljer en för liten container uppstår problem med att dina jobb har slut på minne. Vanligtvis bör YARN-containrar inte vara mindre än 1 GB. Det är vanligt att se 3 GB YARN-containrar. För vissa arbetsbelastningar kan du behöva större YARN-containrar.
Öka antalet kärnor per YARN-container. Öka antalet kärnor som allokeras till varje container för att öka antalet parallella uppgifter som körs i varje container. Detta fungerar för program som Spark, som kör flera uppgifter per container. För program som Hive som kör en enda tråd i varje container är det bättre att ha fler containrar i stället för fler kärnor per container.
Arbetsbelastningslager
Använd alla tillgängliga containrar. Ange att antalet aktiviteter ska vara lika med eller större än antalet tillgängliga containrar så att alla resurser används.
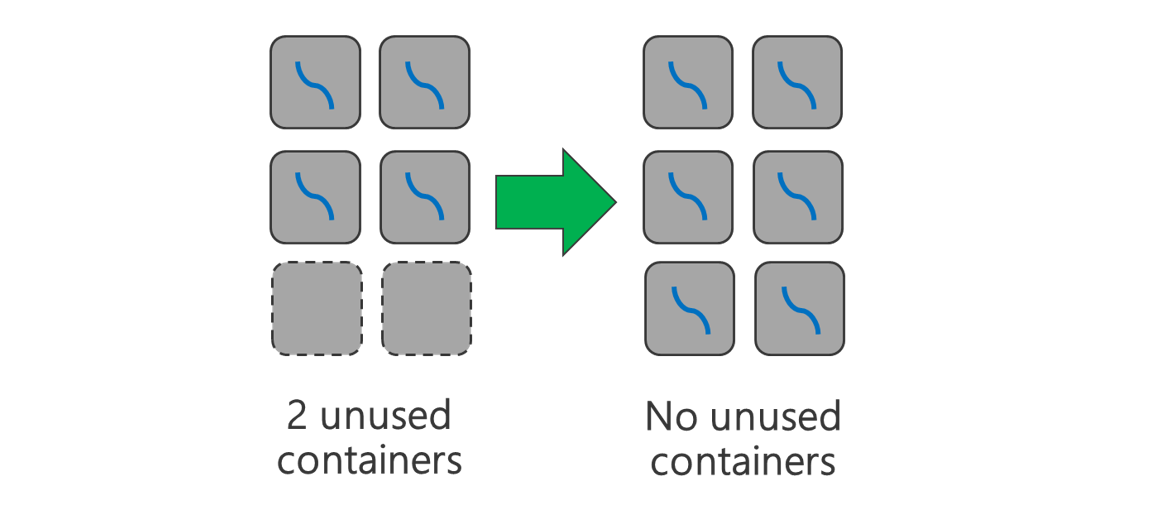
Misslyckade aktiviteter är kostsamma. Om varje aktivitet har en stor mängd data att bearbeta resulterar fel i en aktivitet i ett dyrt återförsök. Därför är det bättre att skapa fler uppgifter, som var och en bearbetar en liten mängd data.
Förutom de allmänna riktlinjerna ovan har varje program olika parametrar tillgängliga för att justera för det specifika programmet. I tabellen nedan visas några av parametrarna och länkarna för att komma igång med prestandajustering för varje program.
| Arbetsbelastning | Parameter för att ange uppgifter |
|---|---|
| Spark på HDInsight |
|
| Hive på HDInsight |
|
| MapReduce på HDInsight |
|
| Storm på HDInsight |
|