Använda jobbwebbläsare och jobbvy för Azure Data Lake Analytics
Viktigt!
Azure Data Lake Analytics drogs tillbaka den 29 februari 2024. Få veta mer om genom det här meddelandet.
För dataanalys kan din organisation använda Azure Synapse Analytics eller Microsoft Fabric.
Azure Data Lake Analytics-tjänsten arkiverar skickade jobb i ett frågearkiv. I den här artikeln får du lära dig hur du använder Jobbwebbläsare och Jobbvy i Azure Data Lake Tools för Visual Studio för att hitta den historiska jobbinformationen.
Som standard arkiverar Data Lake Analytics-tjänsten jobben i 30 dagar. Förfalloperioden kan konfigureras från Azure-portalen genom att konfigurera den anpassade förfalloprincipen. Du kommer inte att kunna komma åt jobbinformationen efter förfallodatum.
Förutsättningar
Se Data Lake Tools för Visual Studio-krav.
Öppna jobbwebbläsaren
Få åtkomst till jobbläsaren via Server Explorer>Azure>Data Lake Analytics>Jobs i Visual Studio. Med hjälp av jobbwebbläsaren kan du komma åt frågearkivet för ett Data Lake Analytics-konto. Jobbwebbläsaren visar Query Store till vänster, som visar grundläggande jobbinformation och Jobbvy till höger som visar detaljerad jobbinformation.
Arbetsvyn
Jobbvyn visar detaljerad information om ett jobb. Om du vill öppna ett jobb kan du dubbelklicka på ett jobb i jobbwebbläsaren eller öppna det från Data Lake-menyn genom att klicka på Jobbvy. Du bör se en dialogruta ifylld med jobb-URL:en.
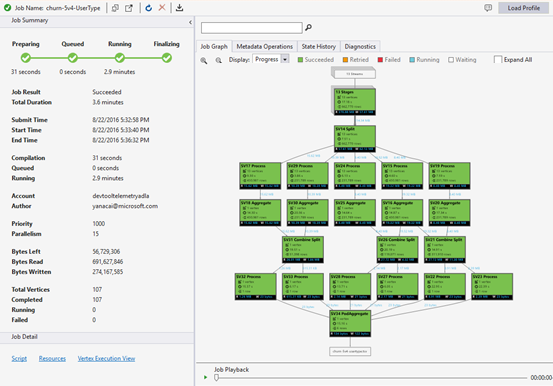
Jobbvyn innehåller:
Jobbsammanfattning
Uppdatera vyn för jobb för att se den senaste informationen om de jobb som körs.
Jobbstatus (diagram):
Jobbstatus beskriver jobbfaserna:
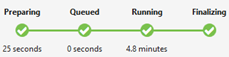
Förbereder: Ladda upp skriptet till molnet, kompilera och optimera skriptet med hjälp av kompileringstjänsten.
I kö: Jobb placeras i kö när de väntar på tillräckligt med resurser, eller om jobben överskrider maxgränsen för samtidiga jobb per konto. Prioritetsinställningen avgör sekvensen av köade jobb – desto lägre tal, desto högre prioritet.
Körs: Jobbet körs faktiskt i ditt Data Lake Analytics-konto.
Slutför: Jobbet slutförs (till exempel slutförs filen).
Jobbet kan misslyckas i varje fas. Kompileringsfel i förberedelsefasen, timeoutfel i i kö-fasen och körningsfel i körfasen, osv.
Grundläggande information
Den grundläggande jobbinformationen visas i den nedre delen av panelen Jobbsammanfattning.
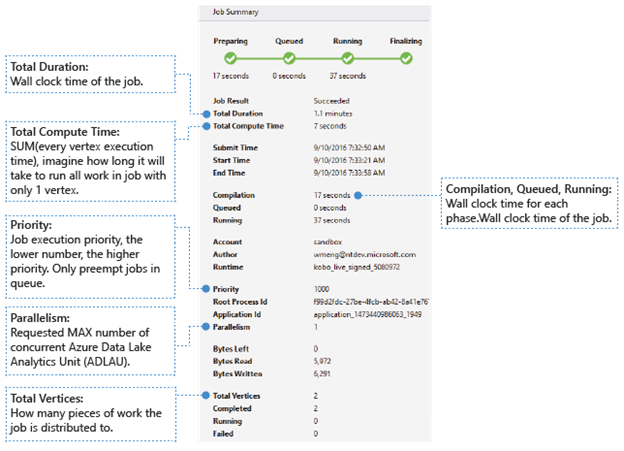
- Jobbresultat: Lyckades eller misslyckades. Jobbet kan misslyckas i varje fas.
- Total varaktighet: Klocktid (varaktighet) mellan inlämningstid och sluttid.
- Total beräkningstid: Summan av exekveringstid för varje vertex, du kan betrakta det som tiden då jobbet exekveras i endast en vertex. Hänvisa till Totalt antal hörn för att hitta mer information om hörn.
- Inlämnings-/Start-/Sluttid: Den tidpunkt då Data Lake Analytics-tjänsten tar emot inlämning av jobbet/börjar köra jobbet/lyckas avsluta jobbet eller inte.
- Kompilering/kö/körning: Tid på väggklockan som spenderades under fasen Förbereda/köa/köra.
- Konto: Data Lake Analytics-kontot som används för att köra jobbet.
- Författare: Den användare som skickade jobbet, det kan vara en verklig persons konto eller ett systemkonto.
- Prioritet: Jobbets prioritet. Desto lägre tal, desto högre prioritet. Det påverkar bara sekvensen för jobben i kön. Att ange en högre prioritet påverkar inte pågående jobb.
- Parallellitet: Det begärda maximala antalet samtidiga Azure Data Lake Analytics-enheter (ADLAUs), även kallade noder. För närvarande är ett hörn lika med en virtuell dator med två virtuella kärnor och sex GB RAM-minne, men detta kan uppgraderas i framtida Data Lake Analytics-uppdateringar.
- Byte kvar: Byte som måste bearbetas tills jobbet har slutförts.
- Läsning/skrivning av byte: Byte som har lästs/skrivits sedan jobbet började köras.
- Totalt antal hörn: Jobbet delas upp i många arbetsdelar, varje arbetsdel kallas för ett hörn. Det här värdet beskriver hur många arbetsdelar jobbet består av. Du kan betrakta ett hörn som en grundläggande processenhet, även kallad Azure Data Lake Analytics Unit (ADLAU), och hörn kan köras parallellt.
- Slutförda/pågående/misslyckade: Antalet slutförda/pågående/misslyckade noder. Noder kan misslyckas på grund av både användarkod och systemfel, men systemet försöker automatiskt flera gånger att köra om misslyckade noder. Om vertexet fortfarande misslyckas efter flera försök, misslyckas hela jobbet.
Jobbdiagram
Ett U-SQL-skript representerar logiken i att transformera indata till utdata. Under förberedelsefasen kompileras och optimeras skriptet till en fysisk körningsplan. Job Graph visar den fysiska körningsplanen. Följande diagram illustrerar processen:
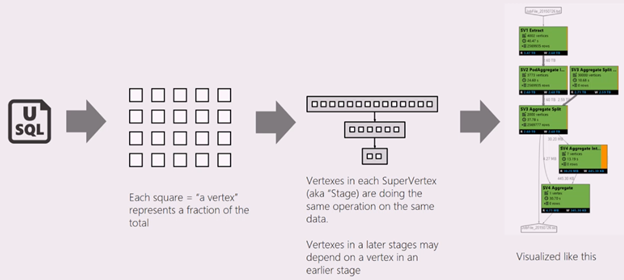
Ett jobb delas upp i många arbetsdelar. Varje del av arbetet kallas en Vertex. Hörnen grupperas som Super Vertex (kallas även fas) och visualiseras som ett jobbdiagram. De gröna skyltarna i jobbdiagrammet visar faserna.
Varje nod i en fas utför samma typ av arbete med olika delar av samma data. Om du till exempel har en fil med en terabyte data och det finns hundratals noder som läser från den, läser var och en en del. Dessa hörn grupperas i samma fas och utför samma arbete på olika delar av samma indatafil.
-
Vid ett visst stadium visas vissa tal på skylten.
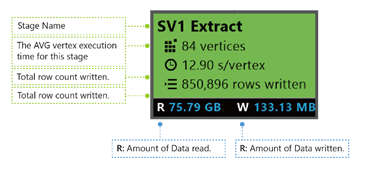
SV1-extrahering: Stadiets namn anges med ett nummer och en driftsmetod.
84 hörn: Det totala antalet hörn i det här steget. Bilden anger hur många arbetsstycken som delas upp i det här steget.
12,90 s/vertex: Den genomsnittliga exekveringstiden per vertex för denna fas. Den här siffran beräknas med summan av (varje exekveringstid för hörn) delat med (totalt antal hörn). Vilket innebär att om du kunde tilldela alla hörn som bearbetas parallellt slutförs hela fasen på 12,90 s. Det innebär också att om allt arbete i det här steget utförs seriellt skulle kostnaden vara #vertices * AVG-tid.
850 895 rader skrivna: Totalt antal rader skrivna i den här fasen.
R/W: Mängden data som lästs/skrivits i det här steget i byte.
Färger: Färger används på scenen för att indikera olika nodstatus.
- Grönt anger att hörnet är lyckat.
- Orange anger att brytpunkten görs om. Den omsökta noden misslyckades men omsöktes automatiskt och framgångsrikt av systemet, och den övergripande fasen har slutförts framgångsrikt. Om noden försöker igen men ändå misslyckas, blir färgen röd och hela uppgiften misslyckas.
- Rött indikerar misslyckad, vilket innebär att en viss nod har försökt igen av systemet några gånger men ändå misslyckats. Det här scenariot gör att hela jobbet misslyckas.
- Blått innebär att en viss nod är aktiv.
- Vitt anger att toppunkten väntar. Noden kan vänta på att schemaläggas när en ADLAU blir tillgänglig, eller så kanske den väntar på indata eftersom dess indata kanske inte är redo.
Du hittar mer information om steget genom att föra muspekaren över en stat:
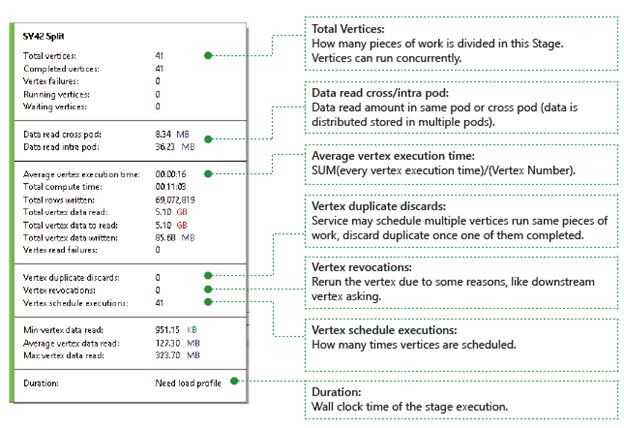
Noder: Beskriver information om noder, till exempel hur många noder totalt, hur många noder som har slutförts, om de misslyckats eller körs/väntar fortfarande osv.
Data läses över/inom pod: Filer och data lagrade i flera podar i ett distribuerat filsystem. Värdet här beskriver hur mycket data som har lästs antingen inom samma podd eller mellan olika poddar.
Total beräkningstid: Summan av exekveringstiden för varje nod i fasen, du kan betrakta det som den tid det skulle ta om allt arbete i fasen körs i endast en nod.
Data och rader som skrivits/lästs: Anger hur mycket data eller rader som har lästs/skrivits eller behöver läsas.
Läsfel för hörn: Beskriver hur många hörn som misslyckas vid läsning av data.
Vertex-dublettbortkastningar: Om en vertex körs för långsamt kan systemet schemalägga flera vertices för att utföra samma arbete. Redundanta hörn kommer att kasseras så snart ett av hörnen har slutförts framgångsrikt. Hörndublettförkastningar registrerar antalet hörn som kasseras som dupliceringar i fasen.
Återkallelser av knutpunkter: Knutpunkten lyckades, men kommer att köras om senare av vissa skäl. Om till exempel nedströmsvertex förlorar mellanliggande indata kommer den att be uppströmsvertex att köras igen.
Schemaläggning av vertexutföranden: Den totala tid som vertexerna har schemalagts.
Min/Medel/Max Vertexdata läst: Minimi/Medel/Maksvärden för varje vertexdatainsamling.
Varaktighet: Väggklocktid för hur lång tid det tar för en fas; du måste läsa in profilen för att se detta värde.
Jobbuppspelning
Data Lake Analytics kör jobb och arkiverar noderna med information om jobben, som när noderna startas, stoppas, misslyckas och hur de försöks igen osv. All information loggas automatiskt i frågelagret och lagras i dess jobbprofil. Du kan ladda ned jobbprofilen via "Läs in profil" i jobbvyn och du kan visa jobbuppspelningen när du har laddat ned jobbprofilen.
Jobbuppspelning är ett perfekt exempel på vad som hände i klustret. Det hjälper dig att övervaka jobbkörningsförloppet och visuellt identifiera prestandaavvikelser och flaskhalsar på mycket kort tid (vanligtvis mindre än 30 sekunder).
Visning av jobbvärmekarta
Jobbvärmekarta kan väljas via listrutan Visa i Jobbdiagram.
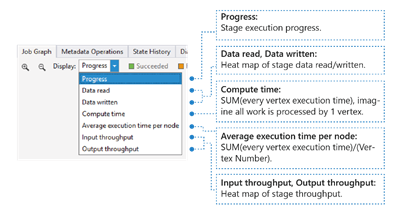
Den visar I/O-, tids- och dataflödesvärmekartan för ett jobb, där du kan hitta var jobbet tillbringar större delen av tiden, eller om ditt jobb är ett I/O-gränsjobb och så vidare.
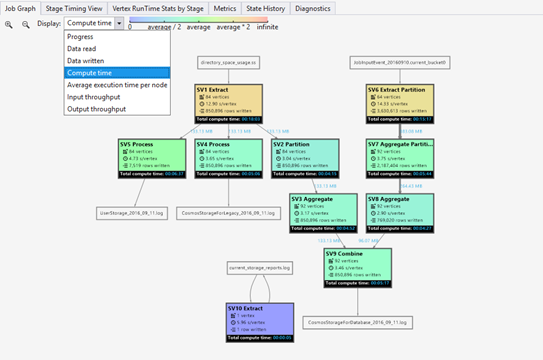
- Förlopp: Förloppet för jobbkörningen finns i Information i steginformation.
- Läsning/skrivning av data: Värmekartan över totalt antal data som lästs/skrivits i varje steg.
- Beräkningstid: Värmekartan för summan av varje hörns körningstid kan betraktas som hur lång tid det skulle ta om allt arbete i fasen utförs med endast ett hörn.
- Genomsnittlig exekveringstid per nod: Värmekarta för SUM (varje vertex exekveringstid) / (antal vertex). Vilket innebär att om du kan tilldela alla noder som körs parallellt, så görs hela fasen inom detta tidsspann.
- Dataflöde för indata/utdata: Med värmekartan för indata/utdataflöde för varje fas kan du bekräfta om ditt jobb är ett I/O-bundet jobb.
-
Metadataåtgärder
Du kan utföra vissa metadataåtgärder i ditt U-SQL-skript, till exempel skapa en databas, släppa en tabell osv. Dessa åtgärder visas i metadataåtgärden efter kompileringen. Du kan hitta påståenden, skapa entiteter, ta bort entiteter här.

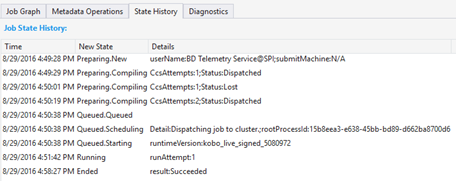
Stathistoria
Tillståndshistoriken visualiseras också i Jobbsammanfattning, men du kan få mer information här. Du hittar detaljerad information så som när jobbet har förberetts, lagts i kö, börjat köras och avslutats. Du kan också se hur många gånger jobbet har kompilerats (CcsAttempts: 1), när skickas jobbet till klustret faktiskt (detail: dispatching job to cluster) osv.
Diagnostik
Verktyget diagnostiserar jobbexekvering automatiskt. Du får aviseringar när det finns fel eller prestandaproblem i dina jobb. Observera att du måste ladda ned profilen för att få fullständig information här.
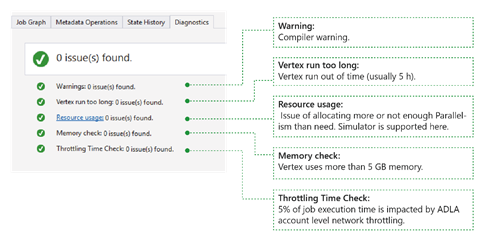
- Varningar: En avisering visas här med kompilatorvarning. Du kan klicka på länken "x problem" för att få mer information när aviseringen visas.
- Vertex tar för lång tid: Om en vertex överskrider tidsgränsen (till exempel 5 timmar), hittas problem här.
- Resursanvändning: Om du har allokerat mer eller inte tillräckligt med parallellitet än vad som behövs finns problem här. Du kan också välja Resursanvändning för att se mer information och utföra konsekvensscenarier för att hitta en bättre resursallokering (mer information finns i den här guiden).
- Minneskontroll: Om någon nod använder mer än 5 GB minne kommer problem att hittas här. Körningen kan avslutas av systemet om den använder mer minne än systemets begränsningar.
Jobbinformation
Jobbdetaljer visar detaljerad information om jobbet, inklusive script, resurser och Vertex Execution View.
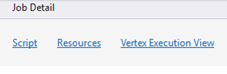
Skript
U-SQL-skriptet för jobbet lagras i frågearkivet. Du kan visa det ursprungliga U-SQL-skriptet och skicka det igen om det behövs.
Resurser
Du hittar jobbkompileringsutdata som lagras i frågearkivet via Resurser. Du kan till exempel hitta "algebra.xml" som används för att visa jobbdiagrammet, de sammansättningar som du registrerade osv. här.
Vertex-körningsvy
Den visar körningsinformation för noder. Jobbprofilen arkiverar körningslogg för varje nod, till exempel totalt antal lästa/skrivna data, körningstid, status osv. I den här vyn kan du få mer information om hur ett jobb utfördes. För mer information, se Vertex Execution View i Data Lake Tools för Visual Studio.
Nästa steg
- Information om hur du loggar diagnostik finns i Åtkomst till diagnostikloggar för Azure Data Lake Analytics
- En mer komplex fråga finns i Analysera webbplatsloggar med Azure Data Lake Analytics.
- För att använda vertex-exekveringsvyn, se Använd Vertex Execution View i Data Lake Tools för Visual Studio