Felsöka vårddatalösningar i Microsoft Fabric
Den här artikeln innehåller information om vissa problem eller fel som du kan se när du använder vårddatalösningar i Microsoft Fabric och hur du kan lösa dem. Artikeln innehåller också vägledning för programövervakning.
Om problemet kvarstår när du har följt anvisningarna i den här artikeln skapar du ett incidentärende för supportteamet.
Felsöka distributionsproblem
Ibland kan du stöta på tillfälliga problem när du distribuerar vårddatalösningar till Fabric-arbetsytan. Här är några vanliga problem och lösningar på problem som kan åtgärdas:
Det går inte att skapa lösningen eller tar för lång tid.
Fel: Skapandet av vårdslösningen pågår i mer än 5 minuter och/eller misslyckas.
Orsak: Det här felet uppstår om det finns en annan vårdslösningen som delar samma namn eller som nyligen har tagits bort.
Lösning: Om du nyligen har tagit bort en lösning väntar du i 30 till 60 minuter innan du försöker distribuera igen.
Det gick inte att distribuera funktionen.
Fel: Det går inte att distribuera vårddatalösningar.
Lösning: Kontrollera om funktionen visas under avsnittet Hantera distribuerade funktioner.
- Om funktionen inte finns med i tabellen kan du försöka distribuera den igen. Välj funktionspanelen och välj sedan knappen Distribuera till arbetsyta.
- Om funktionen visas i tabellen med statusvärdet Distributionen misslyckades distribuerar du om funktionen. Du kan också skapa en ny miljö för vårddatalösningar och distribuera om funktionen där.
Felsöka oidentifierade tabeller
När deltatabeller skapas i sjöhuset för första gången kan de tillfälligt visas som "oidentifierade" eller tomma i vyn utforskarpanelen. De bör dock visas korrekt under mappen tabeller efter några minuter.

Kör datapipeline
Följ dessa steg för att köra exempeldatan från början till slut:
Kör en Spark SQL-instruktion från en notebook-fil för att ta bort alla tabeller från ett sjöhus. Här är ett exempel:
lakehouse_name = "<lakehouse_name>" tables = spark.sql(f"SHOW TABLES IN {lakehouse_name}") for row in tables.collect(): spark.sql(f"DROP TABLE {lakehouse_name}.{row[1]}")Använd OneLake filutforskaren för att ansluta till OneLake i din Windows File Explorer.
Navigera till din arbetsytemapp i Windows utforskaren. Under
<solution_name>.HealthDataManager\DMHCheckpointtar du bort alla motsvarande mappar i<lakehouse_id>/<table_name>. Du kan också använda Microsoft Spark Utilities (MSSparkUtils) för Fabric för att ta bort mappen.Kör datapipelines igen och börja med den kliniska datainmatningen i bronssjöhuset.
Övervaka Apache Spark-appar med Azure Log Analytics
Programloggarna Apache Spark skickas till en Azure Log Analytics workspace-instans som du kan köra frågor mot. Använd den här Kusto-exempelfrågan för att filtrera loggarna som är specifika för vårddatalösningar:
AppTraces
| where Properties['LoggerName'] contains "Healthcaredatasolutions"
or Properties['LoggerName'] contains "DMF"
or Properties['LoggerName'] contains "RMT"
| limit 1000
Notebook-datorns konsolloggar loggar RunId för varje körning. Du kan använda det här värdet för att hämta loggar för en specifik körning enligt följande exempelfråga:
AppTraces
| where Properties['RunId'] == "<RunId>"
Allmän övervakningsinformation finns i Använda Fabric övervakningshubb.
Använda OneLake utforskaren
Program OneLake-utforskaren integrerar sömlöst OneLake med Windows-filutforskare. Du kan använda OneLake-utforskaren för att visa alla mappar eller filer som distribuerats på din Fabric-arbetsyta. Du kan också se exempeldata, OneLake-filer och -mappar samt kontrollpunktsfilerna.
Använd Azure Storage Explorer
Du kan också använda Azure Storage Explorer för att:
Återställ Spark-körningsversionen på Fabric-arbetsytan
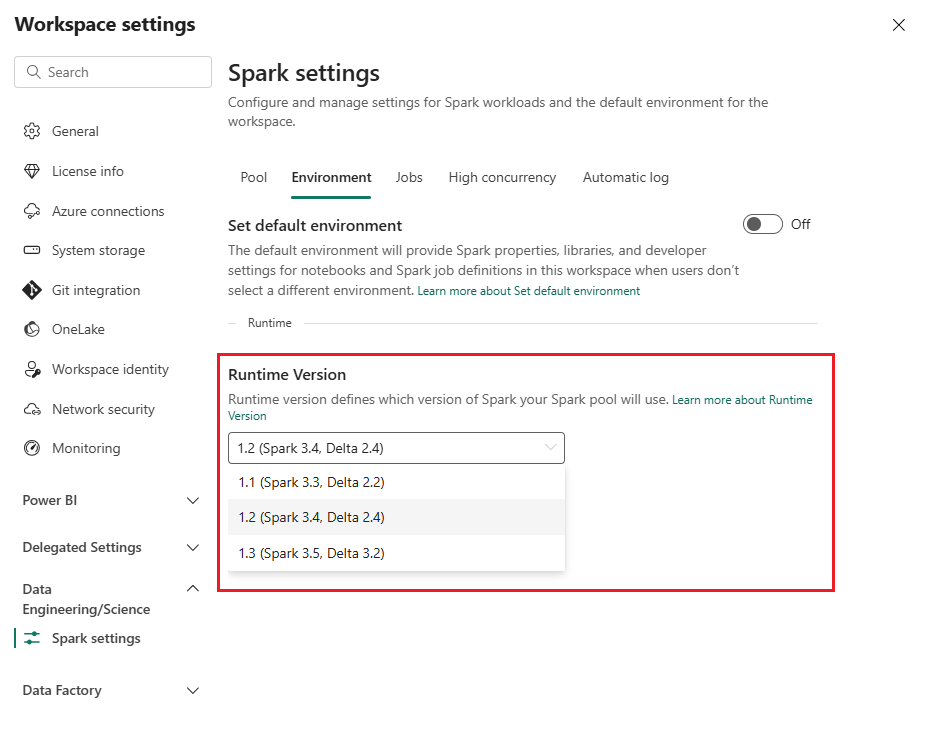
Som standard använder alla nya Fabric-arbetsytor den senaste Fabric-körningsversionen, som för närvarande är Runtime 1.3. Vårddatalösningar har dock endast stöd för Runtime 1.2.
När du har distribuerat vårddatalösningar till din arbetsyta, se till att standardversionen av Fabric-körningen är inställd på Runtime 1.2 (Apache Spark 3.4 och Delta Lake 2.4). Annars kan körningarna av din datapipeline och notebook-fil misslyckas. Mer information finns i Stöd för flera körningar i Fabric.
Följ dessa steg för att granska/uppdatera Fabric-körningsversionen:
Gå till arbetsytan för dina vårddatalösningar och välj Inställningar för arbetsyta.
På inställningssidan för arbetsytan expanderar du listrutan Datateknik/vetenskap och väljer Spark-inställningar.
På fliken Miljö uppdaterar du värdet Körningsversion till 1.2 (Spark 3.4, Delta 2.4) och sparar ändringarna.

Uppdatera användargränssnittet för infrastruktur och OneLake-filutforskaren
Ibland kanske du märker att Fabric-användargränssnittet eller OneLake-utforskaren inte alltid uppdaterar innehållet efter varje notebook-körning. Om du inte ser det förväntade resultatet i användargränssnittet när du har kört ett körningssteg (till exempel att skapa en ny mapp eller sjöhus eller mata in nya data i en tabell) kan du prova att uppdatera artefakten (tabell, sjöhus, mapp). Den här uppdateringen kan ofta lösa avvikelser innan du utforskar andra alternativ eller undersöker vidare.