Använda isbergstabeller med OneLake
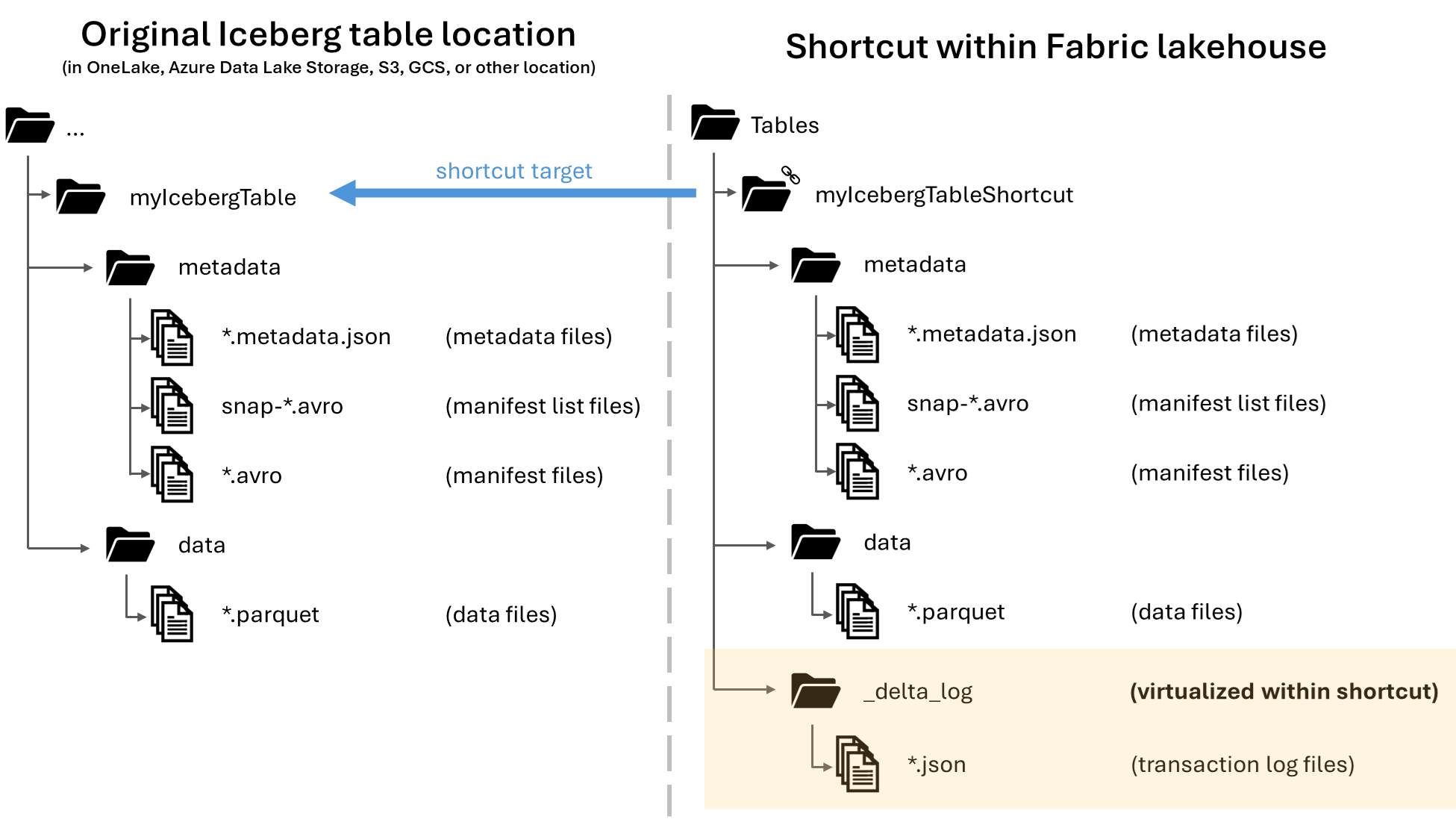
I Microsoft OneLake kan du skapa genvägar till dina Apache Iceberg-tabeller, vilket gör att de kan användas i många olika infrastrukturarbetsbelastningar. Den här funktionen möjliggörs genom en funktion som kallas metadatavirtualisering, vilket gör att Iceberg-tabeller kan tolkas som Delta Lake-tabeller ur genvägens perspektiv. När du skapar en genväg till en isbergstabellmapp genererar OneLake automatiskt motsvarande Delta Lake-metadata (Delta-loggen) för den tabellen, vilket gör Delta Lake-metadata tillgängliga via genvägen.
Viktigt!
Den här funktionen är i förhandsversion.
Även om den här artikeln innehåller vägledning för att skriva isbergstabeller från Snowflake till OneLake, är den här funktionen avsedd att fungera med isbergstabeller med Parquet-datafiler.
Skapa en genväg till en isbergstabell
Om du redan har en Iceberg-tabell på en lagringsplats som stöds av OneLake-genvägar följer du de här stegen för att skapa en genväg och låta tabellen Iceberg visas med Delta Lake-formatet.
Leta upp ditt isbergsbord. Ta reda på var din Iceberg-tabell lagras, som kan finnas i Azure Data Lake Storage, OneLake, Amazon S3, Google Cloud Storage eller en S3-kompatibel lagringstjänst.
Kommentar
Om du använder Snowflake och inte är säker på var isbergstabellen lagras kan du köra följande instruktion för att se lagringsplatsen för din Iceberg-tabell.
SELECT SYSTEM$GET_ICEBERG_TABLE_INFORMATION('<table_name>');Om du kör den här instruktionen returneras en sökväg till metadatafilen för tabellen Iceberg. Den här sökvägen anger vilket lagringskonto som innehåller tabellen Iceberg. Här är till exempel relevant information för att hitta sökvägen till en Isbergstabell som lagras i Azure Data Lake Storage:
{"metadataLocation":"azure://<storage_account_path>/<path_within_storage>/<table_name>/metadata/00001-389700a2-977f-47a2-9f5f-7fd80a0d41b2.metadata.json","status":"success"}Din isbergstabellmapp måste innehålla en
metadatamapp som i sig innehåller minst en fil som slutar på.metadata.json.I infrastruktursjöhuset skapar du en ny genväg i området Tabeller i ett icke-schemaaktiverat sjöhus.
Kommentar
Om du ser scheman, till exempel
dbounder mappen Tabeller i ditt lakehouse, är lakehouse schemaaktiverat och är ännu inte kompatibelt med den här funktionen.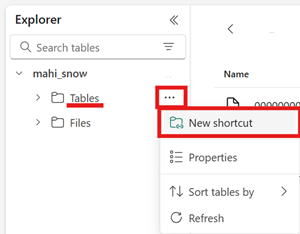
Som målsökväg för genvägen väljer du mappen Iceberg table (Isbergstabell). Tabellen Iceberg innehåller mapparna
metadataochdata.När genvägen har skapats bör du automatiskt se den här tabellen som en Delta Lake-tabell i ditt lakehouse, som är redo att användas i hela Infrastrukturresurser.
Om den nya genvägen till isbergstabellen inte visas som en användbar tabell kontrollerar du avsnittet Felsökning .
Skriva ett isbergsbord till OneLake med hjälp av Snowflake
Om du använder Snowflake i Azure kan du skriva Iceberg-tabeller till OneLake genom att följa dessa steg:
Kontrollera att din Infrastrukturkapacitet finns på samma Azure-plats som din Snowflake-instans.
Identifiera platsen för infrastrukturresurskapaciteten som är associerad med fabric lakehouse. Öppna inställningarna för arbetsytan Infrastruktur som innehåller ditt lakehouse.
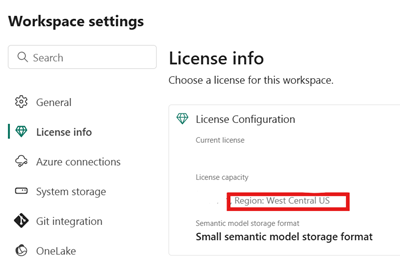
I det nedre vänstra hörnet av ditt Snowflake på Azure-kontogränssnittet kontrollerar du Azure-regionen för Snowflake-kontot.
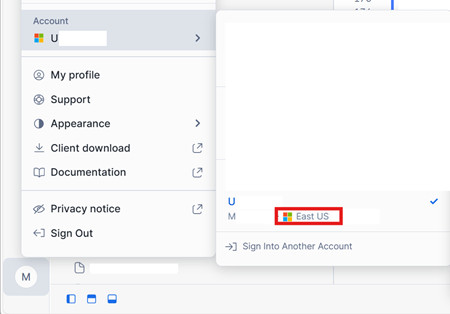
Om dessa regioner är olika måste du använda en annan infrastrukturkapacitet i samma region som ditt Snowflake-konto.
Öppna menyn för området Filer i ditt lakehouse, välj Egenskaper och kopiera URL:en (HTTPS-sökvägen) för mappen.
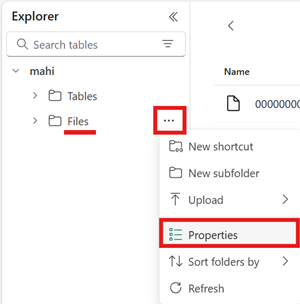
Identifiera ditt klient-ID för Infrastruktur. Välj din användarprofil i det övre högra hörnet i användargränssnittet för infrastrukturresurser och hovra över informationsbubblan bredvid ditt klientnamn. Kopiera klientorganisations-ID :t.
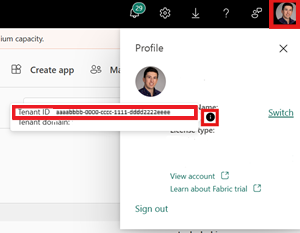
I Snowflake konfigurerar du din
EXTERNAL VOLUMEmed hjälp av sökvägen till mappen Filer i ditt lakehouse. Mer information om hur du konfigurerar externa Snowflake-volymer finns här.Kommentar
Snowflake kräver att URL-schemat är
azure://, så se till att ändrahttps://tillazure://.CREATE OR REPLACE EXTERNAL VOLUME onelake_exvol STORAGE_LOCATIONS = ( ( NAME = 'onelake_exvol' STORAGE_PROVIDER = 'AZURE' STORAGE_BASE_URL = 'azure://<path_to_Files>/icebergtables' AZURE_TENANT_ID = '<Tenant_ID>' ) );I det här exemplet lagras alla tabeller som skapats med den här externa volymen i Infrastruktursjöhuset i
Files/icebergtablesmappen .Nu när den externa volymen har skapats kör du följande kommando för att hämta medgivande-URL:en och namnet på det program som Snowflake använder för att skriva till OneLake. Det här programmet används av andra externa volymer i ditt Snowflake-konto.
DESC EXTERNAL VOLUME onelake_exvol;Utdata från det här kommandot returnerar
AZURE_CONSENT_URLegenskaperna ochAZURE_MULTI_TENANT_APP_NAME. Anteckna båda värdena. Namnet på azure-appen för flera klientorganisationer ser ut som<name>_<number>, men du behöver bara samla in<name>delen.Öppna medgivande-URL:en från föregående steg på en ny webbläsarflik. Om du vill fortsätta godkänner du de nödvändiga programbehörigheterna om du uppmanas att göra det.
I Infrastruktur öppnar du arbetsytan och väljer Hantera åtkomst och sedan Lägg till personer eller grupper. Ge programmet som används av din externa Snowflake-volym de behörigheter som krävs för att skriva data till lakehouses på din arbetsyta. Vi rekommenderar att du beviljar rollen Deltagare .
Tillbaka i Snowflake använder du din nya externa volym för att skapa ett isbergsbord.
CREATE OR REPLACE ICEBERG TABLE MYDATABASE.PUBLIC.Inventory ( InventoryId int, ItemName STRING ) EXTERNAL_VOLUME = 'onelake_exvol' CATALOG = 'SNOWFLAKE' BASE_LOCATION = 'Inventory/';Med den här instruktionen skapas en ny isbergstabellmapp med namnet Inventory i mappsökvägen som definieras i den externa volymen.
Lägg till lite data i din Iceberg-tabell.
INSERT INTO MYDATABASE.PUBLIC.Inventory VALUES (123456,'Amatriciana');Slutligen kan du skapa en OneLake-genväg till ditt Iceberg-bord i området Tabeller i samma sjöhus. Med den genvägen visas din Iceberg-tabell som en Delta Lake-tabell för förbrukning i infrastrukturarbetsbelastningar.
Felsökning
Följande tips kan hjälpa dig att se till att dina isbergstabeller är kompatibla med den här funktionen:
Kontrollera mappstrukturen för isbergstabellen
Öppna din Iceberg-mapp i det lagringsutforskareverktyg som du föredrar och kontrollera kataloglistan för din Iceberg-mapp på dess ursprungliga plats. Du bör se en mappstruktur som i följande exempel.
../
|-- MyIcebergTable123/
|-- data/
|-- snow_A5WYPKGO_2o_APgwTeNOAxg_0_1_002.parquet
|-- snow_A5WYPKGO_2o_AAIBON_h9Rc_0_1_003.parquet
|-- metadata/
|-- 00000-1bdf7d4c-dc90-488e-9dd9-2e44de30a465.metadata.json
|-- 00001-08bf3227-b5d2-40e2-a8c7-2934ea97e6da.metadata.json
|-- 00002-0f6303de-382e-4ebc-b9ed-6195bd0fb0e7.metadata.json
|-- 1730313479898000000-Kws8nlgCX2QxoDHYHm4uMQ.avro
|-- 1730313479898000000-OdsKRrRogW_PVK9njHIqAA.avro
|-- snap-1730313479898000000-9029d7a2-b3cc-46af-96c1-ac92356e93e9.avro
|-- snap-1730313479898000000-913546ba-bb04-4c8e-81be-342b0cbc5b50.avro
Om du inte ser metadatamappen eller om du inte ser filer med tilläggen som visas i det här exemplet kanske du inte har en korrekt genererad Isbergstabell.
Kontrollera konverteringsloggen
När en isbergstabell virtualiseras som en Delta Lake-tabell finns en mapp med namnet _delta_log/ i genvägsmappen. Den här mappen innehåller Delta Lake-formatets metadata (Delta-loggen) efter lyckad konvertering.
Den här mappen innehåller latest_conversion_log.txt även filen, som innehåller den senaste konverteringsförsökets information om lyckade eller misslyckade försök.
Om du vill se innehållet i den här filen när du har skapat genvägen öppnar du menyn för genvägen till Iceberg-tabellen under Området Tabeller i ditt sjöhus och väljer Visa filer.
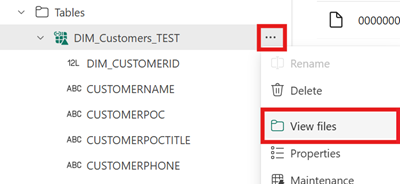
Du bör se en struktur som i följande exempel:
Tables/
|-- MyIcebergTable123/
|-- data/
|-- <data files>
|-- metadata/
|-- <metadata files>
|-- _delta_log/ <-- Virtual folder. This folder doesn't exist in the original location.
|-- 00000000000000000000.json
|-- latest_conversion_log.txt <-- Conversion log with latest success/failure details.
Öppna konverteringsloggfilen för att se den senaste konverteringstiden eller felinformationen. Om du inte ser någon konverteringsloggfil försöktes inte konverteringen.
Om konvertering inte gjordes
Om du inte ser någon konverteringsloggfil försöktes inte konverteringen. Här är två vanliga orsaker till att konvertering inte görs:
Genvägen skapades inte på rätt plats.
För att en genväg till en Iceberg-tabell ska konverteras till Delta Lake-formatet måste genvägen placeras direkt under mappen Tabeller i ett icke-schemaaktiverat sjöhus. Du bör inte placera genvägen i avsnittet Filer eller under en annan mapp om du vill att tabellen ska virtualiseras automatiskt som en Delta Lake-tabell.
Genvägens målsökväg är inte isbergsmappsökvägen.
När du skapar genvägen får mappsökvägen som du väljer på mållagringsplatsen bara vara mappen Iceberg-tabell. Den här mappen innehåller mapparna
metadataochdata.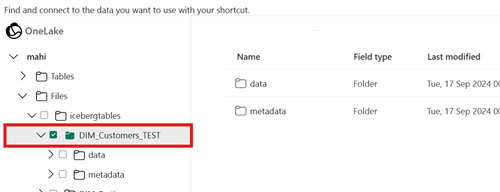
Begränsningar och överväganden
Tänk på följande tillfälliga begränsningar när du använder den här funktionen:
Datatyper som stöds
Följande iceberg-kolumndatatyper mappas till motsvarande Delta Lake-typer med hjälp av den här funktionen.
Typ av isbergskolumn Delta Lake-kolumntyp Kommentarer intintegerlonglongSe Problem med typbredd. floatfloatdoubledoubleSe Problem med typbredd. decimal(P, S)decimal(P, S)Se Problem med typbredd. booleanbooleandatedatetimestamptimestamp_ntzIsbergsdatatypen timestampinnehåller inte tidszonsinformation.timestamp_ntzDelta Lake-typen stöds inte fullt ut i infrastrukturresurser. Vi rekommenderar användning av tidsstämplar med tidszoner som ingår.timestamptztimestampOm du vill använda den här typen i Snowflake anger du timestamp_ltzsom kolumntyp när du skapar Iceberg-tabellen. Mer information om isbergsdatatyper som stöds i Snowflake finns här.stringstringbinarybinaryProblem med typbredd
Om du använder Snowflake för att skriva din Isbergstabell och tabellen innehåller kolumntyperna
INT64,doubleellerDecimalmed precision >= 10, kanske den resulterande virtuella Delta Lake-tabellen inte kan användas av alla Fabric-motorer. Du kan se fel som:Parquet column cannot be converted in file ... Column: [ColumnA], Expected: decimal(18,4), Found: INT32.Vi arbetar med en korrigering av det här problemet.
Lösning: Om du använder användargränssnittet för förhandsversionen av Lakehouse-tabellen och ser det här problemet kan du lösa det här felet genom att växla till SQL-slutpunktsvyn (övre högra hörnet, välja Lakehouse-vy, växla till SQL-slutpunkt) och förhandsgranska tabellen därifrån. Om du sedan växlar tillbaka till Lakehouse-vyn bör tabellförhandsgranskningen visas korrekt.
Om du kör en Spark-notebook-fil eller ett jobb och stöter på det här problemet kan du lösa det här felet genom att ställa in Spark-konfigurationen
spark.sql.parquet.enableVectorizedReaderpåfalse. Här är ett exempel på ett PySpark-kommando som ska köras i en Spark-notebook-fil:spark.conf.set("spark.sql.parquet.enableVectorizedReader","false")Lagring av metadata för isbergstabeller är inte portabel
Metadatafilerna i en Iceberg-tabell refererar till varandra med hjälp av absoluta sökvägsreferenser. Om du kopierar eller flyttar en Iceberg-tabells mappinnehåll till en annan plats utan att skriva om Iceberg-metadatafilerna blir tabellen oläslig för Iceberg-läsare, inklusive den här OneLake-funktionen.
Lösning:
Om du behöver flytta isbergstabellen till en annan plats för att använda den här funktionen använder du verktyget som ursprungligen skrev isbergstabellen för att skriva ett nytt isbergsbord på önskad plats.
Isbergstabeller måste vara djupare än rotnivån
Isbergstabellmappen i lagringen måste finnas i en katalog som är djupare än bucket- eller containernivå. Isbergstabeller som lagras direkt i rotkatalogen för en bucket eller container kanske inte virtualiseras till Delta Lake-formatet.
Vi arbetar med en förbättring för att ta bort det här kravet.
Lösning:
Se till att isbergstabeller lagras i en katalog som är djupare än rotkatalogen för en bucket eller container.
Isbergstabellmappar får bara innehålla en uppsättning metadatafiler
Om du släpper och återskapar en isbergstabell i Snowflake rensas inte metadatafilerna. Det här beteendet stöder
UNDROPfunktionen i Snowflake. Men eftersom genvägen pekar direkt på en mapp och mappen nu har flera uppsättningar metadatafiler i den, kan vi inte konvertera tabellen förrän du tar bort den gamla tabellens metadatafiler.För närvarande görs ett konverteringsförsök i det här scenariot, vilket kan leda till att gammalt tabellinnehåll och schemainformation visas i den virtualiserade Delta Lake-tabellen.
Vi arbetar med en korrigering där konverteringen misslyckas om fler än en uppsättning metadatafiler hittas i icebergtabellens metadatamapp.
Lösning:
Så här ser du till att den konverterade tabellen visar rätt version av tabellen:
- Se till att du inte lagrar fler än en Isbergstabell i samma mapp.
- Rensa innehållet i en isbergstabellmapp efter att du har släppt den innan du återskapar tabellen.
Metadataändringar återspeglas inte omedelbart
Om du gör metadataändringar i din Iceberg-tabell, till exempel att lägga till en kolumn, ta bort en kolumn, byta namn på en kolumn eller ändra en kolumntyp, kan det hända att tabellen inte konverteras om förrän en dataändring har gjorts, till exempel genom att lägga till en rad med data.
Vi arbetar med en korrigering som hämtar rätt senaste metadatafil som innehåller den senaste metadataändringen.
Lösning:
När du har gjort schemaändringen i isbergstabellen lägger du till en rad med data eller gör någon annan ändring i data. Efter den ändringen bör du kunna uppdatera och se den senaste vyn av tabellen i Infrastrukturresurser.
Schemaaktiverade arbetsytor stöds inte ännu
Om du skapar en iceberg-genväg i ett schemaaktiverat sjöhus sker inte konvertering för den genvägen.
Vi arbetar med en förbättring för att ta bort den här begränsningen.
Lösning:
Använd ett icke-schemaaktiverat lakehouse med den här funktionen. Du kan konfigurera den här inställningen när lakehouse skapas.
Tillgänglighetsbegränsning för region
Funktionen är ännu inte tillgänglig i följande regioner:
- Qatar, centrala
- Västra Norge
Lösning:
Arbetsytor som är kopplade till infrastrukturresurser i andra regioner kan använda den här funktionen. Se den fullständiga listan över regioner där Microsoft Fabric är tillgängligt.
Privata länkar stöds inte
Den här funktionen stöds för närvarande inte för klientorganisationer eller arbetsytor som har privata länkar aktiverade.
Vi arbetar med en förbättring för att ta bort den här begränsningen.
Begränsning av tabellstorlek
Vi har en tillfällig begränsning av storleken på isbergstabellen som stöds av den här funktionen. Det maximala antalet Parquet-datafiler som stöds är cirka 5 000 datafiler, eller ungefär 1 miljard rader, beroende på vilken gräns som påträffas först.
Vi arbetar med en förbättring för att ta bort den här begränsningen.
OneLake-genvägar måste vara samma region
Vi har en tillfällig begränsning för användningen av den här funktionen med genvägar som pekar på OneLake-platser: genvägens målplats måste finnas i samma region som själva genvägen.
Vi arbetar med en förbättring för att ta bort det här kravet.
Lösning:
Om du har en OneLake-genväg till ett isbergsbord i ett annat sjöhus, se till att det andra sjöhuset är associerat med en kapacitet i samma region.
Relaterat innehåll
- Läs mer om Säkerhet i Fabric och OneLake.
- Läs mer om OneLake-genvägar.