Mata in data i ditt lager med hjälp av datapipelines
Gäller för:✅ Warehouse i Microsoft Fabric
Datapipelines är ett alternativ till att använda kommandot COPY via ett grafiskt användargränssnitt. En datapipeline är en logisk gruppering av aktiviteter som tillsammans utför en datainmatningsuppgift. Med pipelines kan du hantera aktiviteter för att extrahera, transformera och läsa in (ETL) i stället för att hantera var och en individuellt.
I den här självstudien skapar du en ny pipeline som läser in exempeldata till ett lager i Microsoft Fabric.
Kommentar
Vissa funktioner från Azure Data Factory är inte tillgängliga i Microsoft Fabric, men begreppen är utbytbara. Du kan lära dig mer om Azure Data Factory och pipelines på pipelines och aktiviteter i Azure Data Factory och Azure Synapse Analytics. En snabbstart finns i Snabbstart: Skapa din första pipeline för att kopiera data.
Skapa en datapipeline
Om du vill skapa en ny pipeline navigerar du till din arbetsyta, väljer knappen +Ny och väljer Datapipeline.
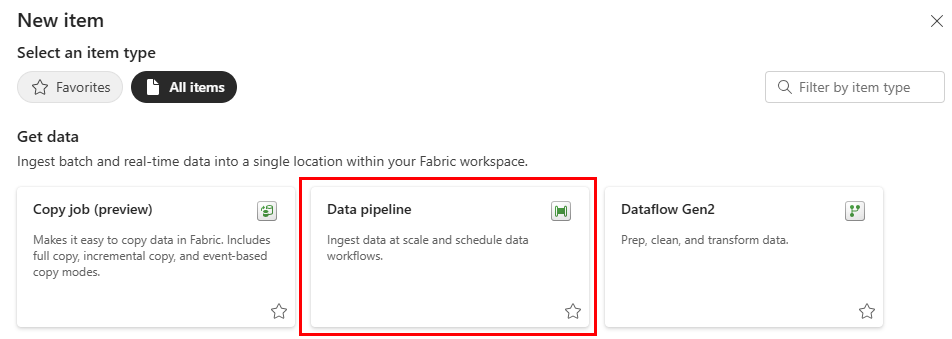
I dialogrutan Ny pipeline anger du ett namn för den nya pipelinen och väljer Skapa.
Du hamnar i området pipelinearbetsyta där du ser tre alternativ för att komma igång: Lägga till en pipelineaktivitet, Kopiera data och Välj en uppgift att starta.
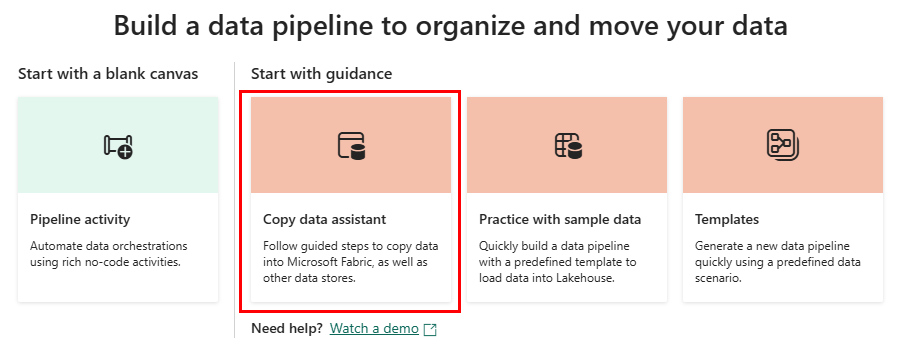
Vart och ett av dessa alternativ erbjuder olika alternativ för att skapa en pipeline:
- Lägg till pipelineaktivitet: Det här alternativet startar pipelineredigeraren, där du kan skapa nya pipelines från grunden med hjälp av pipelineaktiviteter.
- Kopiera data: Det här alternativet startar en stegvis assistent som hjälper dig att välja en datakälla, ett mål och konfigurera datainläsningsalternativ som kolumnmappningar. När den är klar skapar den en ny pipelineaktivitet med en kopieringsdataaktivitet som redan har konfigurerats åt dig.
- Välj en uppgift att starta: Det här alternativet startar en uppsättning fördefinierade mallar som hjälper dig att komma igång med pipelines baserat på olika scenarier.
Välj alternativet Kopiera data för att starta kopieringsassistenten.
Den första sidan i kopieringsdataassistenten hjälper dig att välja dina egna data från olika datakällor, eller välja från ett av de angivna exemplen för att komma igång. I den här självstudien använder vi COVID-19 Data Lake-exemplet . Välj det här alternativet och välj Nästa.

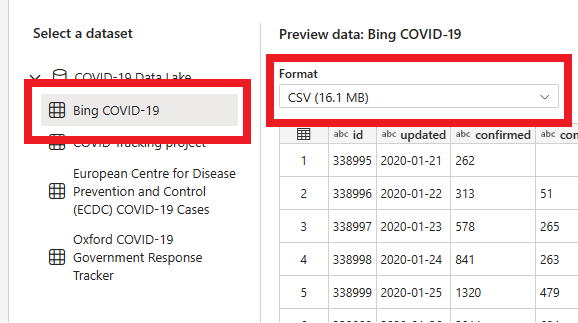
På nästa sida kan du välja en datauppsättning, källfilformatet och förhandsgranska den valda datauppsättningen. Välj Bing COVID-19, CSV-format och välj Nästa.
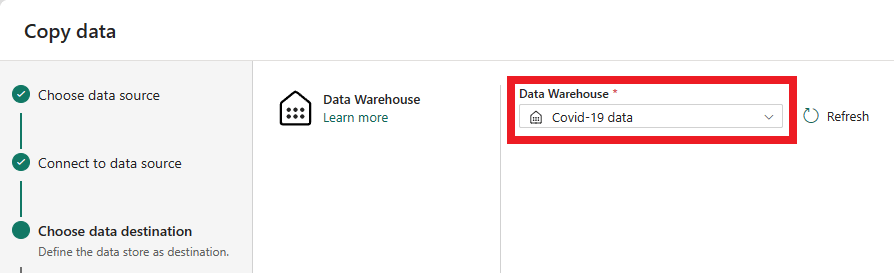
På nästa sida, Datamål, kan du konfigurera typen av målarbetsyta. Vi läser in data till ett lager på vår arbetsyta, så välj fliken Lager och alternativet Informationslager . Välj Nästa.

Nu är det dags att välja det lager som data ska läsas in i. Välj önskat lager i listrutan och välj Nästa.
Det sista steget för att konfigurera målet är att ange ett namn på måltabellen och konfigurera kolumnmappningarna. Här kan du välja att läsa in data till en ny tabell eller till en befintlig tabell, ange ett schema och tabellnamn, ändra kolumnnamn, ta bort kolumner eller ändra deras mappningar. Du kan acceptera standardinställningarna eller justera inställningarna efter dina önskemål.
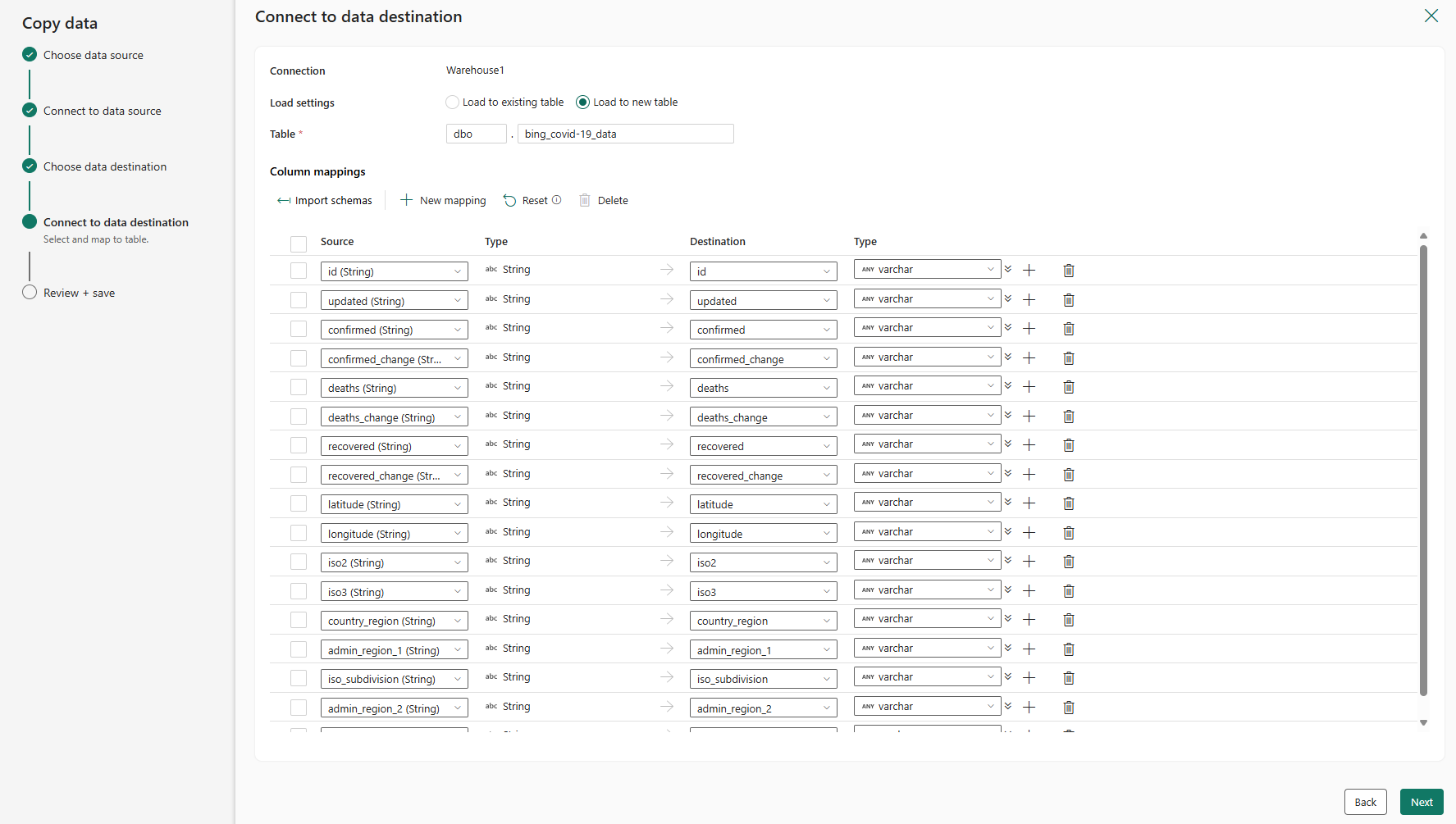
När du är klar med att granska alternativen väljer du Nästa.
På nästa sida får du möjlighet att använda mellanlagring eller tillhandahålla avancerade alternativ för datakopieringsåtgärden (som använder T-SQL COPY-kommandot). Granska alternativen utan att ändra dem och välj Nästa.
Den sista sidan i assistenten innehåller en sammanfattning av kopieringsaktiviteten. Välj alternativet Starta dataöverföring omedelbart och välj Spara + Kör.
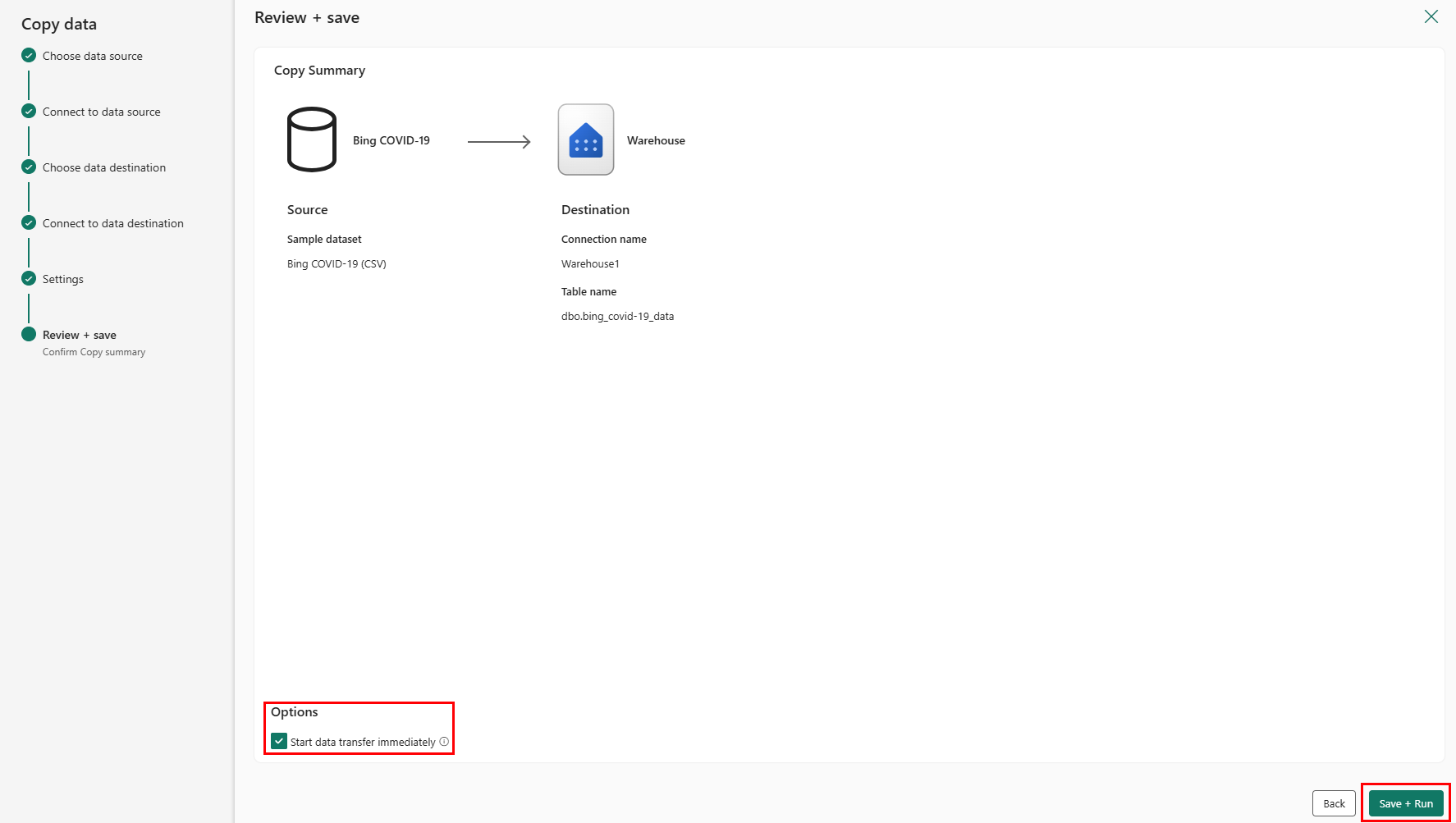
Du dirigeras till området för pipelinearbetsytan, där en ny kopieringsdataaktivitet redan har konfigurerats åt dig. Pipelinen börjar köras automatiskt. Du kan övervaka statusen för din pipeline i fönstret Utdata :

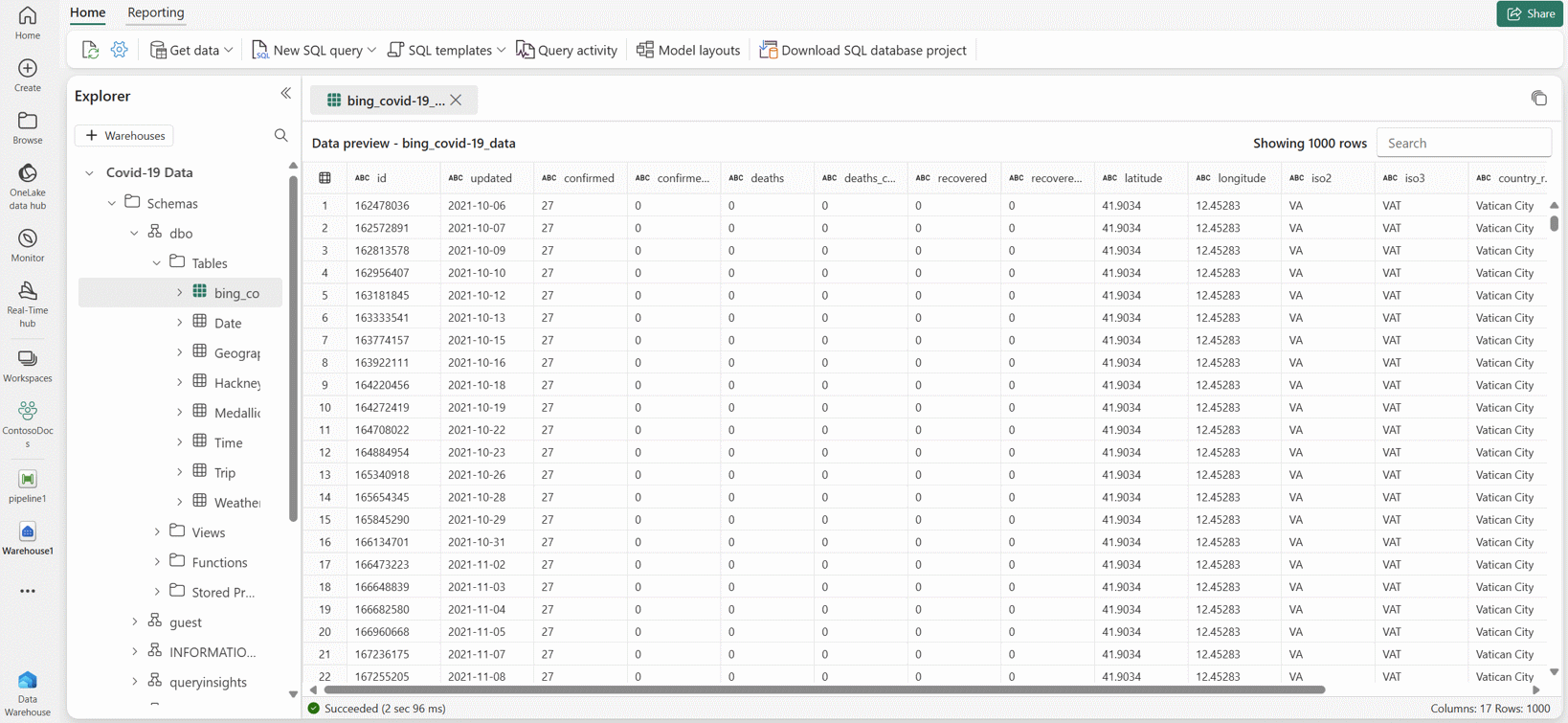
Efter några sekunder slutförs pipelinen. Om du går tillbaka till ditt lager kan du välja tabellen för att förhandsgranska data och bekräfta att kopieringsåtgärden har slutförts.







Mer information om datainmatning i ditt lager i Microsoft Fabric finns i:
- Mata in data i informationslagret
- Mata in data i ditt lager med copy-instruktionen
- Mata in data i ditt lager med Hjälp av Transact-SQL