Självstudie del 2: Utforska och visualisera data med hjälp av Microsoft Fabric-notebook-filer
I den här självstudien får du lära dig hur du utför undersökande dataanalys (EDA) för att undersöka och undersöka data samtidigt som du sammanfattar dess viktigaste egenskaper med hjälp av datavisualiseringstekniker.
Du använder seaborn, ett Python-datavisualiseringsbibliotek som tillhandahåller ett högnivågränssnitt för att skapa visuella objekt på dataramar och matriser. Mer information om seabornfinns i Seaborn: Statistical Data Visualization.
Du ska också använda Data Wrangler, ett anteckningsboksbaserat verktyg som ger dig en uppslukande upplevelse för utförande av undersökande dataanalys och rensning.
De viktigaste stegen i den här självstudien är:
- Läs data som lagras från en deltatabell i lakehouse.
- Konvertera en Spark DataFrame till Pandas DataFrame, som python-visualiseringsbibliotek stöder.
- Använd Data Wrangler för att utföra inledande datarensning och transformering.
- Utför undersökande dataanalys med hjälp av
seaborn.
Förutsättningar
Skaffa en Microsoft Fabric-prenumeration. Eller registrera dig för en kostnadsfri Microsoft Fabric-utvärderingsversion.
Logga in på Microsoft Fabric.
Använd upplevelseväxlaren längst ned till vänster på startsidan för att växla till Fabric.

Det här är del 2 av 5 i självstudieserien. Slutför den här självstudien genom att först slutföra:
Följ med i anteckningsboken
2-explore-cleanse-data.ipynb är anteckningsboken som medföljer den här handledningen.
För att öppna den medföljande notebook-filen för den här handledningen, följ instruktionerna i Förbered ditt system för handledningar i datavetenskap för att importera notebook-filen till din arbetsyta.
Om du hellre kopierar och klistrar in koden från den här sidan kan du skapa en ny notebook-fil.
Se till att bifoga en lakehouse till notebook- innan du börjar köra kod.
Viktig
Fäst samma sjöhus som du använde i del 1.
Läsa rådata från lakehouse
Läs rådata från avsnittet Files i lakehouse. Du laddade upp dessa data i föregående notebook. Kontrollera att du har kopplat samma lakehouse som du använde i del 1 till den här notebook-filen innan du kör den här koden.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Skapa en Pandas DataFrame från datauppsättningen
Konvertera spark DataFrame till Pandas DataFrame för enklare bearbetning och visualisering.
df = df.toPandas()
Visa rådata
Utforska rådata med display, gör lite grundläggande statistik och visa diagramvyer. Observera att du först måste importera de bibliotek som krävs, till exempel Numpy, Pnadas, Seabornoch Matplotlib för dataanalys och visualisering.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Använda Data Wrangler för att utföra inledande datarensning
För att utforska och transformera pandas-DataFrames i din notebook, starta Data Wrangler direkt från din notebook.
Not
Data Wrangler kan inte öppnas när notebook-kerneln är upptagen. Cellkörningen måste slutföras innan Data Wrangler startas.
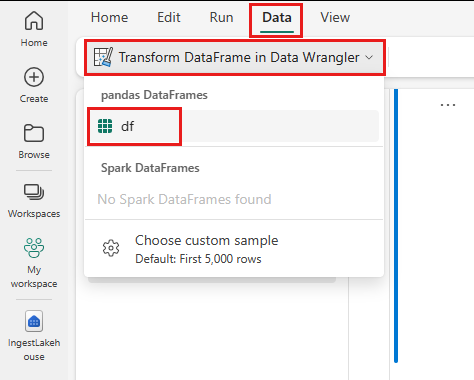
- I menyraden för anteckningsboken, på fliken Data, välj Starta Data Wrangler. Du ser en lista över aktiverade Pandas DataFrames tillgängliga för redigering.
- Välj den dataram som du vill öppna i Data Wrangler. Eftersom den här notebook-filen bara innehåller en DataFrame
dfväljer dudf.
Data Wrangler startar och genererar en beskrivande översikt över dina data. Tabellen i mitten visar varje datakolumn. Panelen Sammanfattning bredvid tabellen visar information om DataFrame. När du väljer en kolumn i tabellen uppdateras sammanfattningen med information om den valda kolumnen. I vissa fall är den data som visas och sammanfattas en förenklad bild av dataramen. När detta händer visas varningsbilden i sammanfattningsfönstret. Hovra över den här varningen om du vill visa text som förklarar situationen.

Varje åtgärd som du gör kan användas med klick, uppdatera datavisningen i realtid och generera kod som du kan spara tillbaka till notebook-filen som en återanvändbar funktion.
Resten av det här avsnittet vägleder dig genom stegen för att utföra datarensning med Data Wrangler.
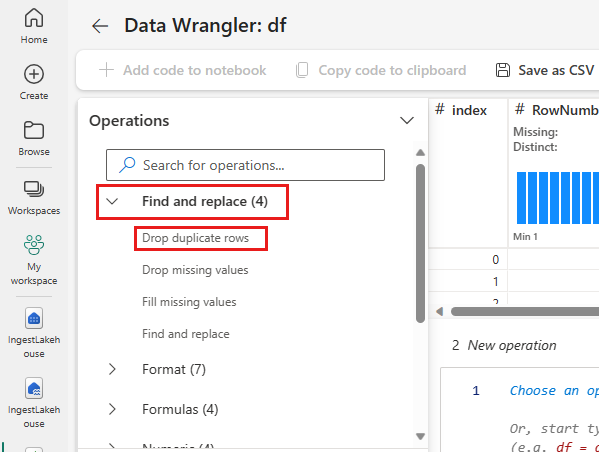
Ta bort duplikatrader
På den vänstra panelen finns en lista över åtgärder (till exempel Sök efter och ersätt, Format, Formler, numeriska) som du kan utföra på datauppsättningen.
Expandera Sök och ersätt och välj Ta bort dubblettrader.
En panel visas där du kan välja den lista med kolumner som du vill jämföra för att definiera en dubblettrad. Välj RowNumber och CustomerId.
I mittenpanelen finns en förhandsgranskning av resultatet av den här åtgärden. Under förhandsversionen finns koden för att utföra åtgärden. I det här fallet verkar data vara oförändrade. Men eftersom du tittar på en trunkerad vy är det en bra idé att ändå tillämpa åtgärden.
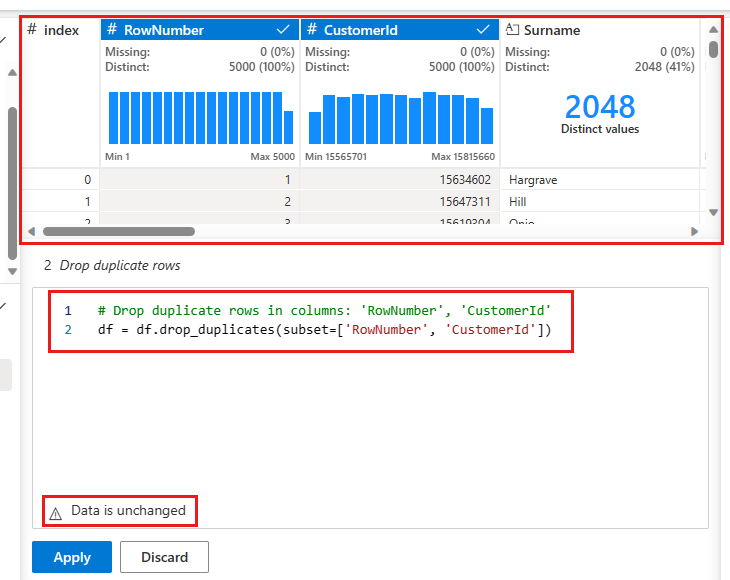
Välj Använd (antingen vid sidan eller längst ned) för att gå till nästa steg.

Ta bort rader med data som saknas
Använd Data Wrangler för att släppa rader med data som saknas i alla kolumner.
Välj Ta bort saknade värden från Sök och ersätt.
Välj Markera alla från Målkolumner.
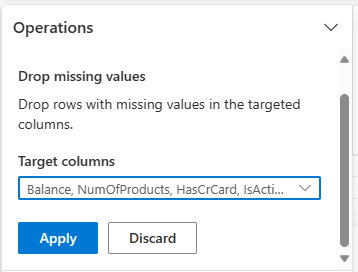
Välj Använd för att gå vidare till nästa steg.

Ta bort kolumner
Använd Data Wrangler för att släppa kolumner som du inte behöver.
Expandera Schema och välj Ta bort kolumner.
Välj RowNumber, CustomerId, Efternamn. Dessa kolumner visas i rött i förhandsversionen för att visa att de har ändrats av koden (i det här fallet borttagna.)
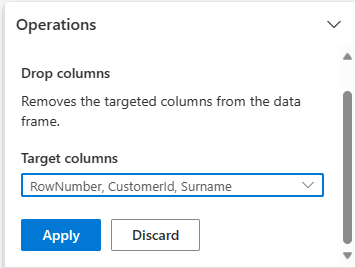
Välj Använd för att gå vidare till nästa steg.

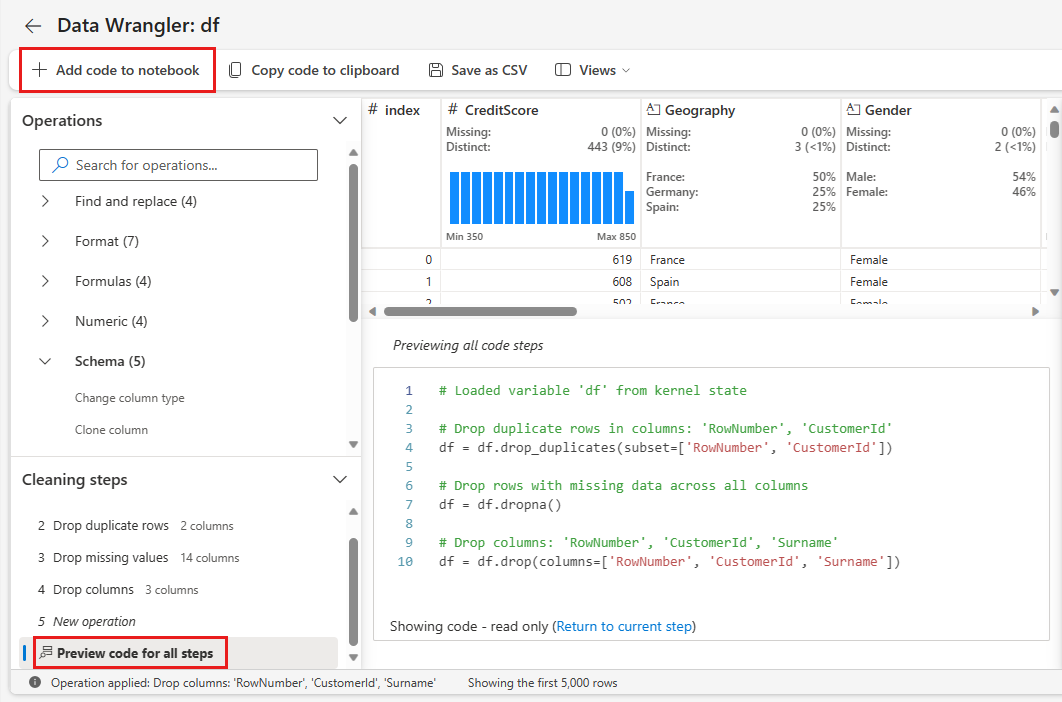
Lägga till kod i anteckningsboken
Varje gång du väljer Användskapas ett nytt steg i Rengöringssteg panelen längst ned till vänster. Längst ned i panelen väljer du förhandsversionskod för alla steg för att visa en kombination av alla separata steg.
Välj Lägg till kod i notebook-filen längst upp till vänster för att stänga Data Wrangler och lägga till koden automatiskt. Lägg till kod i notebook-filen omsluter koden i en funktion och anropar sedan funktionen.
Tips
Koden som genereras av Data Wrangler tillämpas inte förrän du kör den nya cellen manuellt.
Om du inte använde Data Wrangler kan du i stället använda nästa kodcell.
Den här koden liknar koden som skapas av Data Wrangler, men lägger till i argumentet inplace=True till vart och ett av de genererade stegen. Genom att ange inplace=Trueskriver Pandas över den ursprungliga DataFrame i stället för att skapa en ny DataFrame som utdata.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Utforska data
Visa några sammanfattningar och visualiseringar av de rensade data.
Fastställa kategoriska attribut, numeriska attribut och målattribut
Använd den här koden för att fastställa kategoriska attribut, numeriska attribut och målattribut.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Sammanfattning med fem tal
Visa femtalssammanfattningen (minimipoängen, den första kvartilen, medianen, den tredje kvartilen, maxpoängen) för de numeriska attributen med hjälp av rutor.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
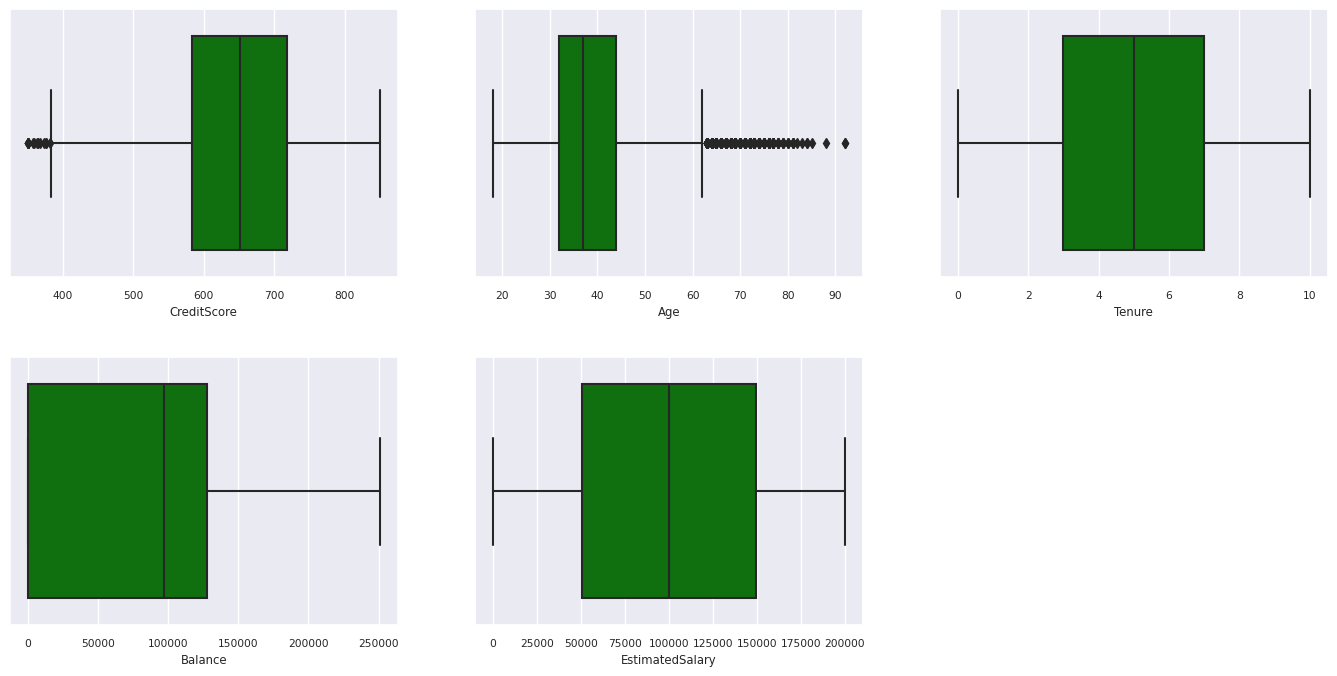
Distribution av kunder som har lämnat och som inte har lämnat
Visa fördelningen av kunder som har lämnat jämfört med de som inte har lämnat över de kategoriska attributen.
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)

Fördelning av numeriska attribut
Visa frekvensfördelningen för numeriska attribut med histogram.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Utföra funktionsframställning
Utför funktionsframställning för att generera nya attribut baserat på aktuella attribut:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Använd Data Wrangler för att utföra one-hot-kodning
Data Wrangler kan också användas för att utföra en one-hot-kodning. Om du vill göra det öppnar du Data Wrangler igen. Den här gången väljer du datan df_clean.
- Expandera Formler och välj Koda med en frekvent kodning.
- En panel visas för att välja listan över kolumner som du vill utföra en one-hot-kodning på. Välj Geografi och Kön.
Du kan kopiera den genererade koden, stänga Data Wrangler för att återgå till notebook-filen och sedan klistra in den i en ny cell. Eller välj Lägg till kod i notebook-filen längst upp till vänster för att stänga Data Wrangler och lägga till koden automatiskt.
Om du inte använde Data Wrangler kan du i stället använda nästa kodcell:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Sammanfattning av observationer från den undersökande dataanalysen
- De flesta kunder kommer från Frankrike och jämför med Spanien och Tyskland, medan Spanien har den lägsta omsättningsgraden jämfört med Frankrike och Tyskland.
- De flesta kunder har kreditkort.
- Det finns kunder vars ålder och kreditpoäng är över 60 respektive under 400, men de kan inte betraktas som avvikande värden.
- Mycket få kunder har mer än två av bankens produkter.
- Kunder som inte är aktiva har en högre omsättningshastighet.
- Kön och anställningsår verkar inte påverka kundens beslut att stänga bankkontot.
Skapa en deltatabell för rensade data
Du kommer att använda dessa data i nästa anteckningsbok i den här serien.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Nästa steg
Träna och registrera maskininlärningsmodeller med dessa data: