Utveckla, utvärdera och poängsätta en prognosmodell för superbutiksförsäljning
I den här självstudien visas ett exempel från slutpunkt till slutpunkt på ett Synapse-Datavetenskap arbetsflöde i Microsoft Fabric. Scenariot skapar en prognosmodell som använder historiska försäljningsdata för att förutsäga produktkategoriförsäljning i ett superstore.
Prognostisering är en viktig tillgång i försäljningen. Den kombinerar historiska data och förutsägelsemetoder för att ge insikter om framtida trender. Prognostisering kan analysera tidigare försäljning för att identifiera mönster och lära sig av konsumentbeteende för att optimera lager-, produktions- och marknadsföringsstrategier. Den här proaktiva metoden förbättrar anpassningsbarhet, svarstider och övergripande prestanda för företag på en dynamisk marknadsplats.
Den här självstudien beskriver följande steg:
- Läsa in data
- Använda undersökande dataanalys för att förstå och bearbeta data
- Träna en maskininlärningsmodell med ett programvarupaket med öppen källkod och spåra experiment med MLflow och funktionen För automatisk loggning av infrastrukturresurser
- Spara den slutliga maskininlärningsmodellen och gör förutsägelser
- Visa modellprestanda med Power BI-visualiseringar
Förutsättningar
Skaffa en Microsoft Fabric-prenumeration. Eller registrera dig för en kostnadsfri utvärderingsversion av Microsoft Fabric.
Logga in på Microsoft Fabric.
Använd upplevelseväxlaren till vänster på startsidan för att växla till Synapse Datavetenskap upplevelse.

- Om det behövs skapar du ett Microsoft Fabric Lakehouse enligt beskrivningen i Skapa ett sjöhus i Microsoft Fabric.
Följ med i en notebook-fil
Du kan välja något av följande alternativ för att följa med i en notebook-fil:
- Öppna och kör den inbyggda notebook-filen i Synapse Datavetenskap-upplevelsen
- Ladda upp din notebook-fil från GitHub till Synapse Datavetenskap-upplevelsen
Öppna den inbyggda notebook-filen
Exempelanteckningsboken Försäljningsprognos medföljer den här självstudien.
Så här öppnar du självstudiekursens inbyggda exempelanteckningsbok i Synapse Datavetenskap upplevelse:
Gå till startsidan för Synapse Datavetenskap.
Välj Använd ett exempel.
Välj motsvarande exempel:
- Från standardfliken för arbetsflöden från slutpunkt till slutpunkt (Python) om exemplet är för en Python-självstudie.
- Från fliken Arbetsflöden från slutpunkt till slutpunkt (R) om exemplet är för en R-självstudie.
- Om exemplet är för en snabb självstudie på fliken Snabbsjälvstudier.
Koppla ett lakehouse till notebook-filen innan du börjar köra kod.
Importera anteckningsboken från GitHub
Notebook-filen AIsample – Superstore Forecast.ipynb medföljer den här självstudien.
Om du vill öppna den medföljande notebook-filen för den här självstudien följer du anvisningarna i Förbereda systemet för självstudier för datavetenskap för att importera anteckningsboken till din arbetsyta.
Om du hellre vill kopiera och klistra in koden från den här sidan kan du skapa en ny notebook-fil.
Se till att bifoga ett lakehouse i notebook-filen innan du börjar köra kod.
Steg 1: Läs in data
Datamängden innehåller 9 995 instanser av försäljning av olika produkter. Den innehåller även 21 attribut. Den här tabellen kommer från den Superstore.xlsx fil som används i den här notebook-filen:
| Rad-ID | Order-ID | Orderdatum | Transportdatum | Leveransläge | Kund-ID | Kundnamn | Segment | Country | City | Tillstånd | Postnummer | Region | Produkt-ID | Kategori | Underkategori | Produktnamn | Sales | Kvantitet | Rabatt | TB |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | USA-2015-108966 | 2015-10-11 | 2015-10-18 | Standardklass | SO-20335 | Sean O'Donnell | Konsument | USA | Fort Lauderdale | Florida | 33311 | Södra | FUR-TA-10000577 | Möbler | Tabeller | Bretford CR4500 Series Slim Rektangulär tabell | 957.5775 | 5 | 0,45 | -383.0310 |
| 11 | CA-2014-115812 | 2014-06-09 | 2014-06-09 | Standardklass | Standardklass | Brosina Hoffman | Konsument | USA | Los Angeles | Kalifornien | 90032 | Västra | FUR-TA-10001539 | Möbler | Tabeller | Rektangulära konferenstabeller för Chromcraft | 1706.184 | 9 | 0.2 | 85.3092 |
| 31 | USA-2015-150630 | 2015-09-17 | 2015-09-21 | Standardklass | TB-21520 | Tracy Blumstein | Konsument | USA | Philadelphia | Pennsylvania | 19140 | Östra | OFF-EN-10001509 | Kontorsmateriel | Kuvert | Poly String Tie Kuvert | 3.264 | 2 | 0.2 | 1.1016 |
Definiera dessa parametrar så att du kan använda den här notebook-filen med olika datauppsättningar:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
Ladda ned datauppsättningen och ladda upp till lakehouse
Den här koden laddar ned en offentligt tillgänglig version av datauppsättningen och lagrar den sedan i en Infrastruktursjöhus:
Viktigt!
Se till att lägga till ett sjöhus i anteckningsboken innan du kör det. Annars får du ett fel.
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Konfigurera MLflow-experimentspårning
Microsoft Fabric samlar automatiskt in värdena för indataparametrar och utdatamått för en maskininlärningsmodell när du tränar den. Detta utökar funktionerna för autologgning av MLflow. Informationen loggas sedan till arbetsytan, där du kan komma åt och visualisera den med MLflow-API:erna eller motsvarande experiment på arbetsytan. Mer information om automatisk loggning finns i Autologgning i Microsoft Fabric.
Om du vill inaktivera automatisk loggning av Microsoft Fabric i en notebook-session anropar mlflow.autolog() du och anger disable=True:
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
Läsa rådata från lakehouse
Läs rådata från avsnittet Filer i lakehouse. Lägg till fler kolumner för olika datumdelar. Samma information används för att skapa en partitionerad deltatabell. Eftersom rådata lagras som en Excel-fil måste du använda Pandas för att läsa den:
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
Steg 2: Utföra undersökande dataanalys
Importera bibliotek
Importera de bibliotek som krävs innan någon analys:
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
Visa rådata
Granska en delmängd av data manuellt för att bättre förstå själva datauppsättningen display och använd funktionen för att skriva ut DataFrame. Dessutom kan vyerna Chart enkelt visualisera delmängder av datamängden.
display(df)
Den här notebook-filen fokuserar främst på att prognostisera Furniture kategoriförsäljningen. Detta påskyndar beräkningen och hjälper till att visa modellens prestanda. Den här notebook-filen använder dock anpassningsbara tekniker. Du kan utöka dessa tekniker för att förutsäga försäljningen av andra produktkategorier.
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
Förbearbeta data
Verkliga affärsscenarier behöver ofta förutsäga försäljning i tre olika kategorier:
- En specifik produktkategori
- En specifik kundkategori
- En specifik kombination av produktkategori och kundkategori
Släpp först onödiga kolumner för att förbearbeta data. Vissa kolumner (Row ID, Order ID,Customer IDoch Customer Name) är onödiga eftersom de inte har någon inverkan. Vi vill prognostisera den totala försäljningen, i hela delstaten och regionen, för en specifik produktkategori (Furniture), så att vi kan släppa kolumnerna State, Region, Country, Cityoch Postal Code . Om du vill prognostisera försäljningen för en viss plats eller kategori kan du behöva justera förbearbetningssteget i enlighet med detta.
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
Datamängden struktureras dagligen. Vi måste sampla om kolumnen Order Date, eftersom vi vill utveckla en modell för att prognostisera försäljningen varje månad.
Gruppera först kategorin Order Dateefter Furniture . Beräkna sedan summan av Sales kolumnen för varje grupp för att fastställa den totala försäljningen för varje unikt Order Date värde. Omsampla Sales om kolumnen med MS frekvensen för att aggregera data per månad. Slutligen beräknar du medelvärdet för försäljning för varje månad.
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
Visa effekten av Order Date på Sales för Furniture kategorin:
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
Innan någon statistisk analys måste du importera statsmodels Python-modulen. Den innehåller klasser och funktioner för uppskattning av många statistiska modeller. Det ger också klasser och funktioner för att utföra statistiska tester och statistisk datautforskning.
import statsmodels.api as sm
Utföra statistisk analys
En tidsserie spårar dessa dataelement med angivna intervall för att fastställa variationen av dessa element i tidsseriemönstret:
Nivå: Den grundläggande komponenten som representerar medelvärdet för en viss tidsperiod
Trend: Beskriver om tidsserierna minskar, förblir konstanta eller ökar över tid
Säsongsvariation: Beskriver den periodiska signalen i tidsserien och letar efter cykliska förekomster som påverkar de ökande eller minskande tidsseriemönstren
Brus/Residual: Refererar till slumpmässiga variationer och variabilitet i tidsseriedata som modellen inte kan förklara.
I den här koden ser du dessa element för datamängden efter förbearbetningen:
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
Diagrammet beskriver säsongsvariationer, trender och brus i prognosdata. Du kan avbilda de underliggande mönstren och utveckla modeller som gör korrekta förutsägelser som är motståndskraftiga mot slumpmässiga variationer.
Steg 3: Träna och spåra modellen
Nu när du har tillgängliga data definierar du prognosmodellen. I den här notebook-filen använder du prognosmodellen som kallas säsongsbaserad autoregressivt integrerat glidande medelvärde med exogena faktorer (SARIMAX). SARIMAX kombinerar komponenter för autoregressiv (AR) och glidande medelvärde (MA), säsongsvariationer och externa prediktorer för att göra korrekta och flexibla prognoser för tidsseriedata.
Du kan också använda autologgning av MLflow och Infrastrukturresurser för att spåra experimenten. Här läser du in deltatabellen från lakehouse. Du kan använda andra deltatabeller som betraktar lakehouse som källa.
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
Justering av hyperparametrar
SARIMAX tar hänsyn till de parametrar som ingår i ARIMA-läget (regular autoregressive Integrated Moving Average) (p, d, q) och lägger till säsongsparametrarna (P, D, Q, s). Dessa SARIMAX-modellargument kallas ordning (p, d, q) respektive säsongsordning (P, D, Q, s). Därför måste vi först justera sju parametrar för att träna modellen.
Ordningsparametrarna:
p: AR-komponentens ordning, som representerar antalet tidigare observationer i tidsserien som används för att förutsäga det aktuella värdet.Den här parametern bör vanligtvis vara ett heltal som inte är negativt. Vanliga värden ligger i intervallet
0till3, även om högre värden är möjliga, beroende på de specifika dataegenskaperna. Ett högrepvärde anger ett längre minne av tidigare värden i modellen.d: Differentieringsordningen, som representerar antalet gånger som tidsserien måste skiljas åt, för att uppnå stationaritet.Den här parametern ska vara ett heltal som inte är negativt. Vanliga värden finns i intervallet
0till2.0Värdetdbetyder att tidsserien redan är stationär. Högre värden anger antalet differentieringsåtgärder som krävs för att göra den stationär.q: Ordningen på MA-komponenten, som representerar antalet tidigare feltermer för vitt brus som används för att förutsäga det aktuella värdet.Den här parametern ska vara ett heltal som inte är negativt. Vanliga värden ligger i intervallet
0till3, men högre värden kan vara nödvändiga för vissa tidsserier. Ett högreqvärde indikerar ett starkare beroende av tidigare felvillkor för att göra förutsägelser.
Parametrarna för säsongsordning:
P: Säsongsordningen för AR-komponenten, som liknarpmen för säsongsdelenD: Säsongsordningen för differentiering, som liknardmen för säsongsdelenQ: Ma-komponentens säsongsordning, som liknarqmen för säsongsdelens: Antalet tidssteg per säsongscykel (till exempel 12 för månadsdata med årssäsong)
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
SARIMAX har andra parametrar:
enforce_stationarity: Om modellen ska framtvinga stationaritet på tidsseriedata innan den passar SARIMAX-modellen.Om
enforce_stationarityär inställtTruepå (standard) anger det att SARIMAX-modellen ska framtvinga stationaritet på tidsseriedata. SARIMAX-modellen tillämpar sedan automatiskt differentiering på data, för att göra den stationär, enligt orderdochD, innan den passar modellen. Detta är vanligt eftersom många tidsseriemodeller, inklusive SARIMAX, förutsätter att data är stationära.För en icke-stationär tidsserie (till exempel uppvisar den trender eller säsongsvariationer) är det bra att ange
enforce_stationaritytillTrueoch låta SARIMAX-modellen hantera differentiering för att uppnå stationärhet. För en stationär tidsserie (till exempel en utan trender eller säsongsvariationer) anger duenforce_stationarityför attFalseundvika onödiga skillnader.enforce_invertibility: Styr om modellen ska framtvinga inverterbarhet på de uppskattade parametrarna under optimeringsprocessen.Om
enforce_invertibilityär inställtTruepå (standard) anger det att SARIMAX-modellen ska framtvinga inverterbarhet för de uppskattade parametrarna. Inverterbarhet säkerställer att modellen är väldefinierad och att de uppskattade AR- och MA-koefficienterna landar inom intervallet för stationaritet.Invertibility enforcement hjälper till att säkerställa att SARIMAX-modellen följer de teoretiska kraven för en stabil tidsseriemodell. Det hjälper också till att förhindra problem med modelluppskattning och stabilitet.
Standardvärdet är en AR(1) modell. Detta refererar till (1, 0, 0). Det är dock vanligt att prova olika kombinationer av orderparametrarna och säsongsordningsparametrarna och utvärdera modellprestanda för en datauppsättning. Lämpliga värden kan variera från en tidsserie till en annan.
Bestämning av de optimala värdena omfattar ofta analys av funktionen autocorrelation (ACF) och en partiell autokorrelationsfunktion (PACF) för tidsseriedata. Det omfattar också ofta användning av urvalskriterier för modeller – till exempel Akaike-informationskriteriet (AIC) eller BIC (Bayesian Information Criterion).
Justera hyperparametrar:
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
Efter utvärdering av föregående resultat kan du fastställa värdena för både orderparametrarna och säsongsordningsparametrarna. Valet är order=(0, 1, 1) och seasonal_order=(0, 1, 1, 12), som erbjuder lägsta AIC (till exempel 279,58). Använd dessa värden för att träna modellen.
Träna modellen
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
Den här koden visualiserar en tidsserieprognos för försäljningsdata för möbler. De ritade resultaten visar både observerade data och enstegsprognosen, med en skuggad region för konfidensintervall.
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
Använd predictions för att utvärdera modellens prestanda genom att jämföra den med de faktiska värdena. Värdet predictions_future anger framtida prognostisering.
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
Steg 4: Poängsätta modellen och spara förutsägelser
Integrera de faktiska värdena med de prognostiserade värdena för att skapa en Power BI-rapport. Lagra dessa resultat i en tabell i lakehouse.
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Steg 5: Visualisera i Power BI
Power BI-rapporten visar ett genomsnittligt absolut procentuellt fel (MAPE) på 16,58. MAPE-måttet definierar noggrannheten för en prognosmetod. Den representerar noggrannheten i de prognostiserade kvantiteterna, i jämförelse med de faktiska kvantiteterna.
MAPE är ett enkelt mått. En MAPE på 10 % representerar att den genomsnittliga avvikelsen mellan de prognostiserade värdena och de faktiska värdena är 10 %, oavsett om avvikelsen var positiv eller negativ. Standarder för önskvärda MAPE-värden varierar mellan olika branscher.
Den ljusblå linjen i den här grafen representerar de faktiska försäljningsvärdena. Den mörkblå linjen representerar de prognostiserade försäljningsvärdena. Jämförelse av faktisk och prognostiserad försäljning visar att modellen effektivt förutsäger försäljningen för Furniture kategorin under de första sex månaderna 2023.
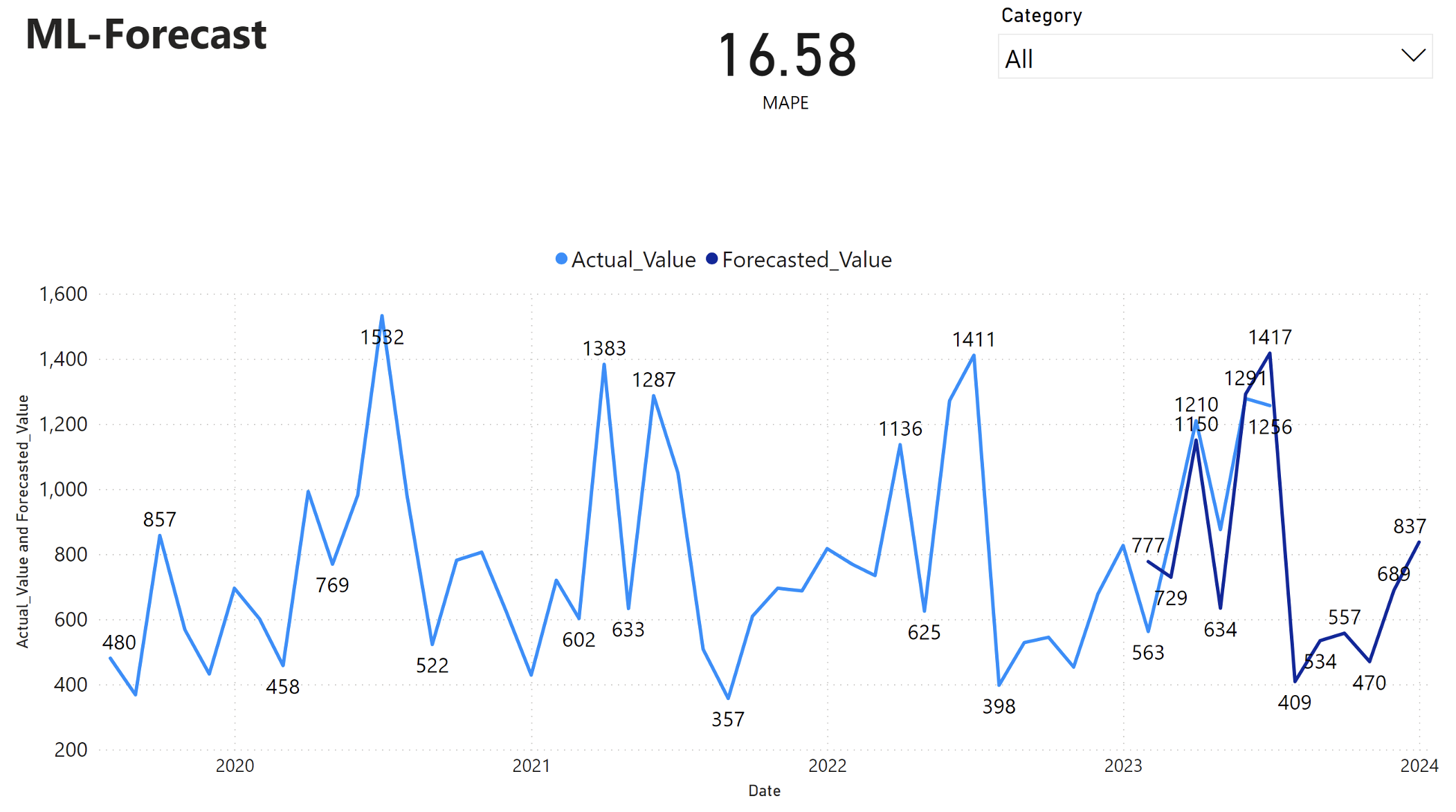
Baserat på denna observation kan vi ha förtroende för modellens prognosfunktioner, för den totala försäljningen under de senaste sex månaderna 2023 och sträcker sig till 2024. Detta förtroende kan ligga till hjälp vid strategiska beslut om lagerhantering, inköp av råvaror och andra affärsrelaterade överväganden.