Självstudie: Skapa, utvärdera och poängsätta ett rekommendationssystem
I den här handledningen presenteras ett genomgående exempel på ett Synapse Data Science-arbetsflöde i Microsoft Fabric. Scenariot skapar en modell för onlineboksrekommendationer.
Handledningen täcker följande steg:
- Ladda upp data till ett sjöhus
- Utföra undersökande analys av data
- Träna en modell och logga den med MLflow
- Läs in modellen och gör förutsägelser
Vi har många typer av rekommendationsalgoritmer tillgängliga. I den här självstudien används algoritmen Alternating Least Squares (ALS) för matrisfaktorisering. ALS är en modellbaserad filtreringsalgoritm för samarbete.

ALS försöker uppskatta klassificeringsmatrisen R som produkten av två matriser med lägre rang, U och V. Här gäller R = U * V:t. Dessa approximeringar kallas vanligtvis faktor matriser.
ALS-algoritmen är iterativ. Varje iteration innehåller en av faktormatriserna konstant, medan den löser den andra med hjälp av metoden för minst kvadrater. Den innehåller sedan den nyligen lösta faktormatriskonstanten medan den löser den andra faktormatrisen.

Förutsättningar
Skaffa en Microsoft Fabric-prenumeration. Eller registrera dig för en kostnadsfri Microsoft Fabric-utvärderingsversion.
Logga in på Microsoft Fabric.
Använd upplevelseväxlaren längst ner till vänster på startsidan för att växla till Fabric.

- Om det behövs skapar du ett Microsoft Fabric Lakehouse enligt beskrivningen i Skapa ett sjöhus i Microsoft Fabric.
Följ med i en anteckningsbok
Du kan välja något av följande alternativ för att följa med i en anteckningsbok:
- Öppna och kör den inbyggda notebook-filen.
- Ladda upp din notebook-fil från GitHub.
Öppna den inbyggda notebook-filen
Exempelbokrekommendation Anteckningsbok medföljer den här handledningen.
Om du vill öppna exempelanteckningsboken för den här självstudien följer du anvisningarna i Förbereda systemet för självstudier för datavetenskap.
Se till att ansluta ett lakehouse till notebooken innan du börjar köra kod.
Importera anteckningsboken från GitHub
Den AIsample – Book Recommendation.ipynb anteckningsfilen medföljer den här självstudien.
Om du vill öppna den medföljande notebook-filen för den här självstudien, följ anvisningarna i Förbereda systemet för självstudier för datavetenskap för att importera anteckningsboken till din arbetsyta.
Om du hellre kopierar och klistrar in koden från den här sidan kan du skapa en ny notebook-fil.
Se till att ansluta en lakehouse till notebooken innan du börjar köra kod.
Steg 1: Läs in data
Bokrekommendationsdatauppsättningen i det här scenariot består av tre separata datasamlingar.
Books.csv: Ett internationellt standardboknummer (ISBN) identifierar varje bok, med ogiltiga datum redan borttagna. Datauppsättningen innehåller även rubrik, författare och utgivare. För en bok med flera författare visar filen Books.csv endast den första författaren. URL:er pekar på Amazons webbplatsresurser för omslagsbilderna i tre storlekar.
ISBN Book-Title Book-Author År -Of-Publication Förläggare Bild –URL-S Bild –URL-M Bild-URL-l 0195153448 Klassisk mytologi Mark P. O. Morford 2002 Oxford University Press http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Kanada http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv: Klassificeringar för varje bok är antingen explicita (tillhandahålls av användare, på en skala från 1 till 10) eller implicita (observeras utan användarindata och anges av 0).
User-ID ISBN Book-Rating 276725 034545104X 0 276726 0155061224 5 Users.csv: Användar-ID:n anonymiseras och mappas till heltal. Demografiska data – till exempel plats och ålder – tillhandahålls, om de är tillgängliga. Om dessa data inte är tillgängliga är dessa värden
null.User-ID Plats Ålder 1 nyc new york usa 2 "stockton california usa" 18.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Definiera dessa parametrar så att du kan använda den här notebooken med olika datauppsättningar.
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
Ladda ned och lagra data i ett sjöhus
Den här koden laddar ned datauppsättningen och lagrar den sedan i lakehouse.
Viktig
Se till att lägga till en lakehouse- i anteckningsboken innan du kör den. Annars får du ett fel.
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Konfigurera MLflow-experimentspårning
Använd den här koden för att konfigurera MLflow-experimentspårningen. Det här exemplet inaktiverar automatisk loggning. Mer information finns i artikeln Automatisk loggning i Microsoft Fabric.
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Läsa data från lakehouse
När rätt data har placerats i lakehouse läser du de tre datauppsättningarna i separata Spark DataFrames i notebook-filen. Filsökvägarna i den här koden använder de parametrar som definierades tidigare.
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
Steg 2: Utföra undersökande dataanalys
Visa rådata
Utforska DataFrames med kommandot display. Med det här kommandot kan du visa dataramstatistik på hög nivå och förstå hur olika datauppsättningskolumner relaterar till varandra. Innan du utforskar datauppsättningarna använder du den här koden för att importera de bibliotek som krävs:
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
Använd den här koden för att titta på dataramen som innehåller bokdata:
display(df_items, summary=True)
Lägg till en _item_id kolumn för senare användning. Värdet _item_id måste vara ett heltal för rekommendationsmodeller. Den här koden använder StringIndexer för att transformera ITEM_ID_COL till index:
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
Visa DataFrame och kontrollera om _item_id-värdet ökar monotont och successivt, som förväntat:
display(df_items.sort(F.col("_item_id").desc()))
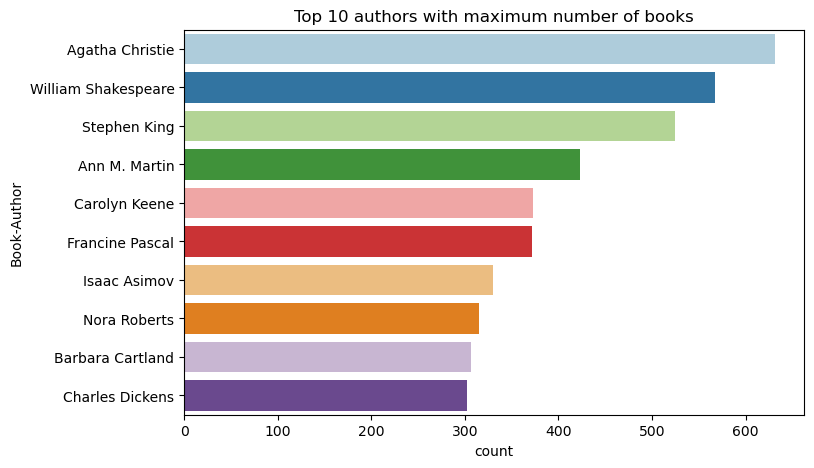
Använd den här koden för att rita de 10 främsta författarna, efter antal skrivna böcker, i fallande ordning. Agatha Christie är den ledande författaren med mer än 600 böcker, följt av William Shakespeare.
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")
Visa sedan dataramen som innehåller användardata:
display(df_users, summary=True)
Om en rad saknar ett User-ID värde släpper du den raden. Saknade värden i en anpassad datauppsättning orsakar inga problem.
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
Lägg till en _user_id kolumn för senare användning. För rekommendationsmodeller måste _user_id-värdet vara ett heltal. Följande kodexempel använder StringIndexer för att transformera USER_ID_COL till index.
Datasetet för böcker har redan en heltalskolumn User-ID. Om du lägger till en _user_id kolumn för kompatibilitet med olika datauppsättningar blir det här exemplet dock mer robust. Använd den här koden för att lägga till kolumnen _user_id:
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
Använd den här koden för att visa klassificeringsdata:
display(df_ratings, summary=True)
Hämta distinkta klassificeringar och spara dem för senare användning i en lista med namnet ratings:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
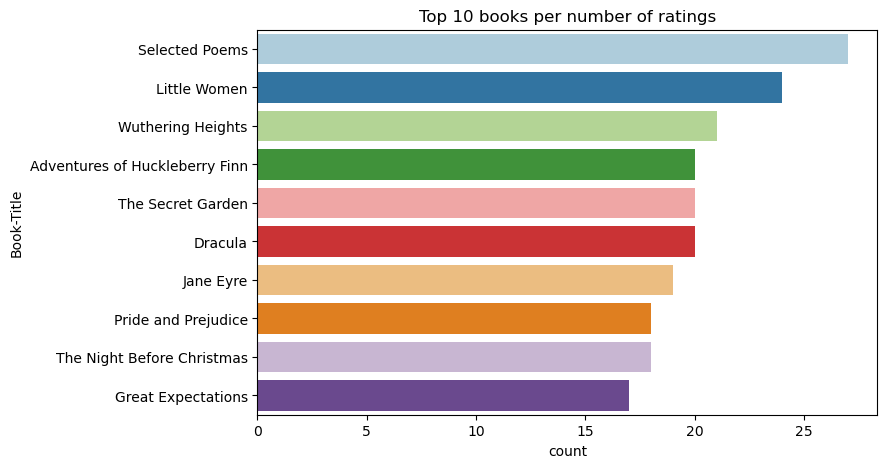
Använd den här koden om du vill visa de 10 bästa böckerna med de högsta klassificeringarna:
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
Enligt betygen är Selected Poems den mest populära boken. Adventures of Huckleberry Finn, The Secret Garden, och Dracula har samma betyg.
Sammanfoga data
Sammanfoga de tre DataFrames till en DataFrame för en mer omfattande analys:
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
Använd den här koden för att visa antalet distinkta användare, böcker och interaktioner:
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
Beräkna och rita de mest populära objekten
Använd den här koden för att beräkna och visa de 10 mest populära böckerna:
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
Tips
Använd <topn>-värdet för populära eller mest köpta rekommendationer.
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

Förbereda tränings- och testdatauppsättningar
ALS-matrisen kräver vissa dataförberedelser innan träningen. Använd det här kodexemplet för att förbereda data. Koden utför följande åtgärder:
- Omvandla klassificeringskolumnen till rätt typ
- Exempel på träningsdata med användarklassificeringar
- Dela upp data i tränings- och testdatauppsättningar
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
Sparsity refererar till glesa feedbackdata, som inte kan identifiera likheter i användarnas intresse. Om du vill ha bättre förståelse för både data och det aktuella problemet använder du den här koden för att beräkna datamängdens gleshet:
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
Steg 3: Utveckla och träna modellen
Träna en ALS-modell för att ge användarna anpassade rekommendationer.
Definiera modellen
Spark ML tillhandahåller ett praktiskt API för att skapa ALS-modellen. Modellen hanterar dock inte på ett tillförlitligt sätt problem som datasparsitet och kallstart (ger rekommendationer när användarna eller objekten är nya). För att förbättra modellens prestanda kombinerar du korsvalidering och automatisk hyperparameterjustering.
Använd den här koden för att importera de bibliotek som krävs för modellträning och utvärdering:
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
Finjustera modellhyperparametrar
Nästa kodexempel konstruerar ett parameterrutnät för att söka över hyperparametrar. Koden skapar också en regressionsutvärdering som använder RMSE (root-mean-square error) som utvärderingsmått:
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
Nästa kodexempel initierar olika modelljusteringsmetoder baserat på de förkonfigurerade parametrarna. Mer information om modelljustering finns i ML Tuning: modellval och hyperparameterjustering på Apache Spark-webbplatsen.
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
Utvärdera modellen
Du bör utvärdera moduler mot testdata. En vältränad modell bör ha höga mått på datamängden.
En överanpassad modell kan behöva en ökning av storleken på träningsdata eller en minskning av några av de redundanta funktionerna. Modellarkitekturen kan behöva ändras, eller så kan dess parametrar behöva finjusteras.
Not
Ett negativt R-kvadratvärde indikerar att den tränade modellen presterar sämre än en vågrät rät linje. Resultatet tyder på att den tränade modellen inte förklarar data.
Om du vill definiera en utvärderingsfunktion använder du den här koden:
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
Spåra experimentet med hjälp av MLflow
Använd MLflow för att spåra alla experiment och för att logga parametrar, mått och modeller. Om du vill starta modellträning och utvärdering använder du den här koden:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
Välj experimentet med namnet aisample-recommendation från arbetsytan för att visa den loggade informationen för träningskörningen. Om du har ändrat experimentnamnet väljer du det experiment som har det nya namnet. Den loggade informationen liknar den här bilden:

Steg 4: Läs in den slutliga modellen för bedömning och gör förutsägelser
När du har slutfört modellträningen och sedan valt den bästa modellen läser du in modellen för bedömning (kallas ibland slutsatsdragning). Den här koden läser in modellen och använder förutsägelser för att rekommendera de 10 främsta böckerna för varje användare:
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
Utdata liknar den här tabellen:
| _item_id | _user_id | klassificering | Book-Title |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Lasher: Liv ... |
| 786 | 7 | 6.2255826 | Pianomannens D... |
| 45330 | 7 | 4.980466 | Sinnesstämning |
| 38960 | 7 | 4.980466 | Allt han någonsin velat ha |
| 125415 | 7 | 4.505084 | Harry Potter och ... |
| 44939 | 7 | 4.3579073 | Taltos: Liv av ... |
| 175247 | 7 | 4.3579073 | Skelettsättarens ... |
| 170183 | 7 | 4,228735 | Leva den enkla ... |
| 88503 | 7 | 4.221206 | Blus ö... |
| 32894 | 7 | 3.9031885 | Vintersolstånd |
Spara förutsägelserna i lakehuset
Använd den här koden för att skriva tillbaka rekommendationerna till lakehouse:
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)