Självstudie: skapa, utvärdera och poängsätta en modell för felidentifiering för datorer
I den här självstudien visas ett exempel från slutpunkt till slutpunkt på ett Synapse-Datavetenskap arbetsflöde i Microsoft Fabric. Scenariot använder maskininlärning för en mer systematisk metod för feldiagnos, för att proaktivt identifiera problem och vidta åtgärder före ett faktiskt datorfel. Målet är att förutsäga om en dator skulle uppleva ett fel baserat på processtemperatur, rotationshastighet osv.
Den här självstudien beskriver följande steg:
- Installera anpassade bibliotek
- Läsa in och bearbeta data
- Förstå data genom undersökande dataanalys
- Använd scikit-learn, LightGBM och MLflow för att träna maskininlärningsmodeller och använda funktionen För automatisk loggning av infrastrukturresurser för att spåra experiment
- Poängsätta de tränade modellerna med funktionen Infrastruktur
PREDICT, spara den bästa modellen och läs in modellen för förutsägelser - Visa inlästa modellprestanda med Power BI-visualiseringar
Förutsättningar
Skaffa en Microsoft Fabric-prenumeration. Eller registrera dig för en kostnadsfri utvärderingsversion av Microsoft Fabric.
Logga in på Microsoft Fabric.
Använd upplevelseväxlaren till vänster på startsidan för att växla till Synapse Datavetenskap upplevelse.

- Om det behövs skapar du ett Microsoft Fabric Lakehouse enligt beskrivningen i Skapa ett sjöhus i Microsoft Fabric.
Följ med i en notebook-fil
Du kan välja något av följande alternativ för att följa med i en notebook-fil:
- Öppna och kör den inbyggda notebook-filen i Datavetenskap-upplevelsen
- Ladda upp din notebook-fil från GitHub till Datavetenskap upplevelse
Öppna den inbyggda notebook-filen
Exempelanteckningsboken Datorfel medföljer den här självstudien.
Så här öppnar du självstudiekursens inbyggda exempelanteckningsbok i Synapse Datavetenskap upplevelse:
Gå till startsidan för Synapse Datavetenskap.
Välj Använd ett exempel.
Välj motsvarande exempel:
- Från standardfliken för arbetsflöden från slutpunkt till slutpunkt (Python) om exemplet är för en Python-självstudie.
- Från fliken Arbetsflöden från slutpunkt till slutpunkt (R) om exemplet är för en R-självstudie.
- Om exemplet är för en snabb självstudie på fliken Snabbsjälvstudier.
Koppla ett lakehouse till notebook-filen innan du börjar köra kod.
Importera anteckningsboken från GitHub
Notebook-filen AISample – Predictive Maintenance medföljer den här självstudien.
Om du vill öppna den medföljande notebook-filen för den här självstudien följer du anvisningarna i Förbereda systemet för självstudier för datavetenskap för att importera anteckningsboken till din arbetsyta.
Om du hellre vill kopiera och klistra in koden från den här sidan kan du skapa en ny notebook-fil.
Se till att bifoga ett lakehouse i notebook-filen innan du börjar köra kod.
Steg 1: Installera anpassade bibliotek
För utveckling av maskininlärningsmodeller eller ad hoc-dataanalys kan du snabbt behöva installera ett anpassat bibliotek för Apache Spark-sessionen. Du har två alternativ för att installera bibliotek.
- Använd de infogade installationsfunktionerna (
%pipeller%conda) i notebook-filen för att installera ett bibliotek, endast i den aktuella notebook-filen. - Du kan också skapa en Infrastrukturmiljö, installera bibliotek från offentliga källor eller ladda upp anpassade bibliotek till den och sedan kan din arbetsyteadministratör koppla miljön som standard för arbetsytan. Alla bibliotek i miljön blir sedan tillgängliga för användning i alla notebook-filer och Spark-jobbdefinitioner på arbetsytan. Mer information om miljöer finns i skapa, konfigurera och använda en miljö i Microsoft Fabric.
I den här självstudien använder du %pip install för att installera imblearn biblioteket i notebook-filen.
Kommentar
PySpark-kerneln startas om efter %pip install körningar. Installera de bibliotek som behövs innan du kör andra celler.
# Use pip to install imblearn
%pip install imblearn
Steg 2: Läs in data
Datauppsättningen simulerar loggning av en tillverkningsdators parametrar som en tidsfunktion, vilket är vanligt i industriella miljöer. Den består av 10 000 datapunkter som lagras som rader med funktioner som kolumner. Här följer exempel på några funktioner:
En unik identifierare (UID) som sträcker sig från 1 till 1 0000
Produkt-ID, bestående av bokstaven L (för låg), M (för medel) eller H (för hög), för att indikera produktkvalitetsvarianten och ett variantspecifikt serienummer. Varianter av låg, medelhög och hög kvalitet utgör 60 %, 30 % respektive 10 % av alla produkter
Lufttemperatur, i grader Kelvin (K)
Processtemperatur, i grader Kelvin
Rotationshastighet, i varv per minut (RPM)
Vridmoment, i Newton-Meter (Nm)
Verktygsslitage, på några minuter. Kvalitetsvarianterna H, M och L lägger till 5, 3 respektive 2 minuters verktygsslitage till det verktyg som används i processen
En datorfeletikett för att ange om datorn misslyckades i den specifika datapunkten. Den här specifika datapunkten kan ha något av följande fem oberoende fellägen:
- Fel vid verktygsslitage (TWF): verktyget byts ut eller misslyckas vid en slumpmässigt vald användningstid för verktyget, mellan 200 och 240 minuter
- Fel vid värmeavledning (HDF): värmeavslutning orsakar ett processfel om skillnaden mellan lufttemperaturen och processtemperaturen är mindre än 8,6 K och verktygets rotationshastighet är mindre än 1 380 RPM
- Strömavbrott (PWF): produkten av vridmoment och rotationshastighet (i rad/s) är lika med den effekt som krävs för processen. Processen misslyckas om den här kraften understiger 3 500 W eller överskrider 9 000 W
- OverStrain Failure (OSF): om produkten av verktygets slitage och vridmoment överstiger 11 000 nm för L-produktvarianten (12 000 för M, 13 000 för H), misslyckas processen på grund av överträning
- Slumpmässiga fel (RNF): varje process har en felchans på 0,1 %, oavsett processparametrar
Kommentar
Om minst ett av ovanstående fellägen är sant misslyckas processen och etiketten "datorfel" är inställd på 1. Maskininlärningsmetoden kan inte avgöra vilket felläge som orsakade processfelet.
Ladda ned datauppsättningen och ladda upp till lakehouse
Anslut till containern Azure Open Datasets och läs in datauppsättningen Förutsägande underhåll. Den här koden laddar ned en offentligt tillgänglig version av datauppsättningen och lagrar den sedan i en Infrastruktursjöhus:
Viktigt!
Lägg till ett lakehouse i anteckningsboken innan du kör det. Annars får du ett fel. Information om hur du lägger till ett sjöhus finns i Anslut lakehouses och notebook-filer.
# Download demo data files into the lakehouse if they don't exist
import os, requests
DATA_FOLDER = "Files/predictive_maintenance/" # Folder that contains the dataset
DATA_FILE = "predictive_maintenance.csv" # Data file name
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/MachineFaultDetection"
file_list = ["predictive_maintenance.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
När du har laddat ned datamängden till lakehouse kan du läsa in den som en Spark DataFrame:
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}raw/{DATA_FILE}")
.cache()
)
df.show(5)
Den här tabellen visar en förhandsgranskning av data:
| UDI | Produkt-ID | Typ | Lufttemperatur [K] | Processtemperatur [K] | Rotationshastighet [rpm] | Vridmoment [Nm] | Verktygsslitage [min] | Mål | Feltyp |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | M | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | Inget fel |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | Inget fel |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | Inget fel |
| 4 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | Inget fel |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40,0 | 9 | 0 | Inget fel |
Skriva en Spark DataFrame till en lakehouse delta-tabell
Formatera data (till exempel ersätta blankstegen med understreck) för att underlätta Spark-åtgärder i efterföljande steg:
# Replace the space in the column name with an underscore to avoid an invalid character while saving
df = df.toDF(*(c.replace(' ', '_') for c in df.columns))
table_name = "predictive_maintenance_data"
df.show(5)
Den här tabellen visar en förhandsgranskning av data med omformaterade kolumnnamn:
| UDI | Product_ID | Typ | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | Mål | Failure_Type |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | M | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | Inget fel |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | Inget fel |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | Inget fel |
| 4 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | Inget fel |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40,0 | 9 | 0 | Inget fel |
# Save data with processed columns to the lakehouse
df.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Steg 3: Förbearbeta data och utföra undersökande dataanalys
Konvertera Spark DataFrame till en Pandas DataFrame för att använda Pandas-kompatibla populära ritbibliotek.
Dricks
För en stor datamängd kan du behöva läsa in en del av datamängden.
data = spark.read.format("delta").load("Tables/predictive_maintenance_data")
SEED = 1234
df = data.toPandas()
df.drop(['UDI', 'Product_ID'],axis=1,inplace=True)
# Rename the Target column to IsFail
df = df.rename(columns = {'Target': "IsFail"})
df.info()
Konvertera specifika kolumner i datauppsättningen till flyttal eller heltalstyper efter behov och mappa strängar ('L', 'M', 'H') till numeriska värden (0, 1, 2):
# Convert temperature, rotational speed, torque, and tool wear columns to float
df['Air_temperature_[K]'] = df['Air_temperature_[K]'].astype(float)
df['Process_temperature_[K]'] = df['Process_temperature_[K]'].astype(float)
df['Rotational_speed_[rpm]'] = df['Rotational_speed_[rpm]'].astype(float)
df['Torque_[Nm]'] = df['Torque_[Nm]'].astype(float)
df['Tool_wear_[min]'] = df['Tool_wear_[min]'].astype(float)
# Convert the 'Target' column to an integer
df['IsFail'] = df['IsFail'].astype(int)
# Map 'L', 'M', 'H' to numerical values
df['Type'] = df['Type'].map({'L': 0, 'M': 1, 'H': 2})
Utforska data genom visualiseringar
# Import packages and set plotting style
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
sns.set_style('darkgrid')
# Create the correlation matrix
corr_matrix = df.corr(numeric_only=True)
# Plot a heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True)
plt.show()
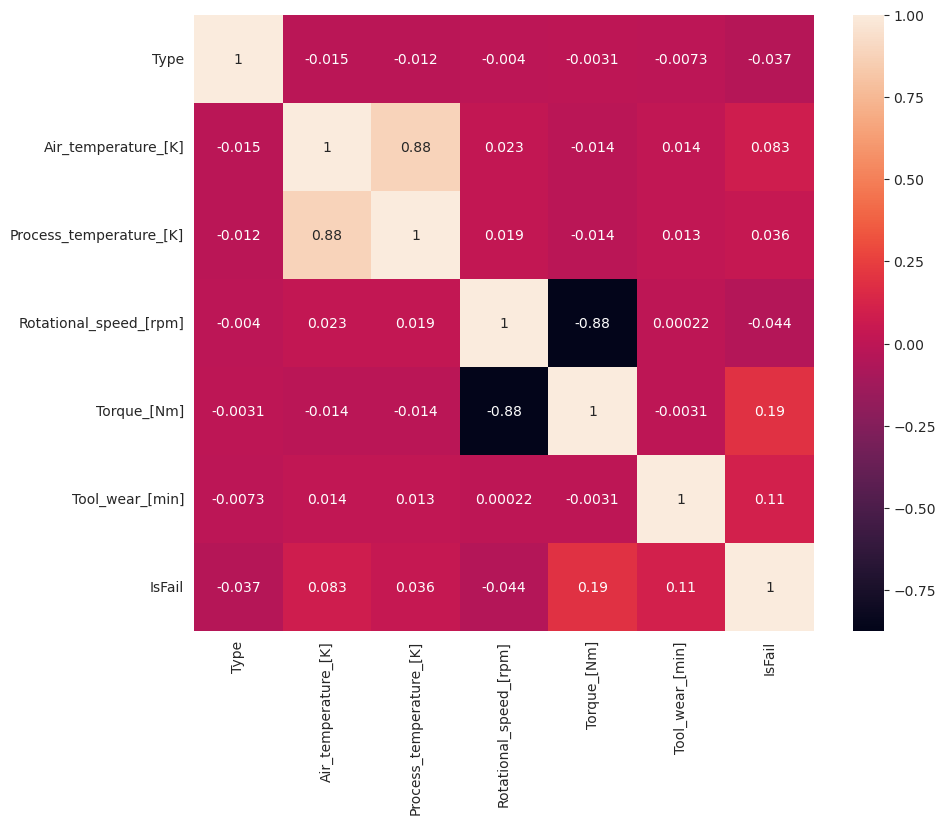
Som förväntat korrelerar fel (IsFail) med de valda funktionerna (kolumner). Korrelationsmatrisen visar att Air_temperature, Process_temperature, Rotational_speed, Torqueoch Tool_wear har den högsta korrelationen med variabeln IsFail .
# Plot histograms of select features
fig, axes = plt.subplots(2, 3, figsize=(18,10))
columns = ['Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']
data=df.copy()
for ind, item in enumerate (columns):
column = columns[ind]
df_column = data[column]
df_column.hist(ax = axes[ind%2][ind//2], bins=32).set_title(item)
fig.supylabel('count')
fig.subplots_adjust(hspace=0.2)
fig.delaxes(axes[1,2])
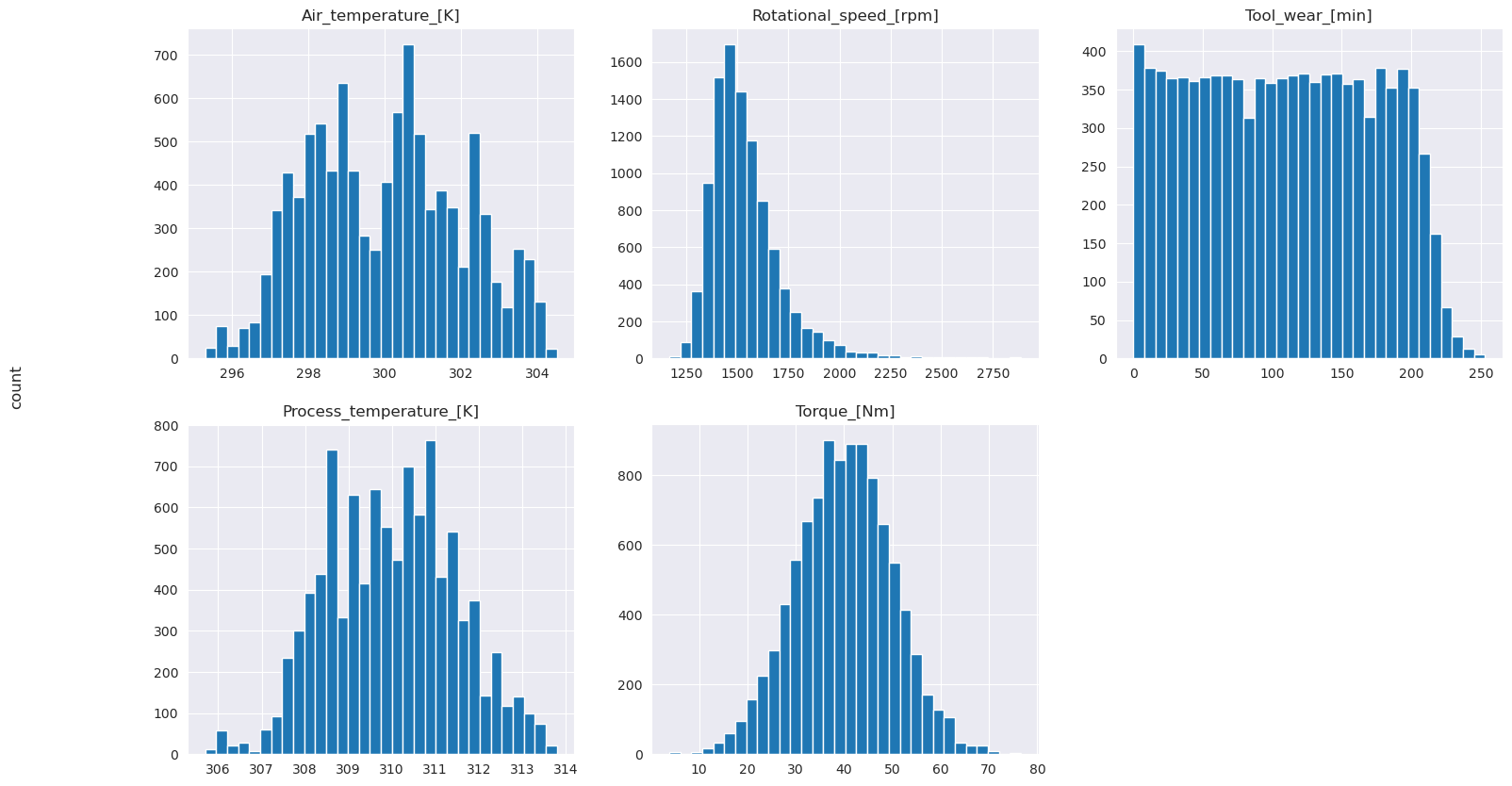
Som de ritade graferna visar är variablerna Air_temperature, Process_temperature, Rotational_speed, Torqueoch Tool_wear inte glesa. De verkar ha god kontinuitet i funktionsutrymmet. Dessa diagram bekräftar att träning av en maskininlärningsmodell för den här datamängden sannolikt ger tillförlitliga resultat som kan generalisera till en ny datamängd.
Kontrollera målvariabeln för obalans i klassen
Räkna antalet exempel för misslyckade och otrogna datorer och inspektera databalansen för varje klass (IsFail=0, IsFail=1):
# Plot the counts for no failure and each failure type
plt.figure(figsize=(12, 2))
ax = sns.countplot(x='Failure_Type', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
# Plot the counts for no failure versus the sum of all failure types
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
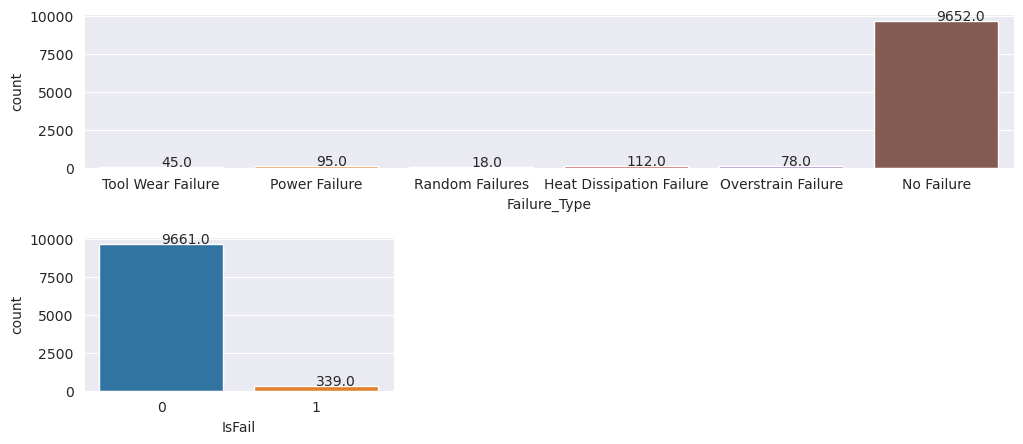
Diagrammet anger att klassen no-failure (visas som IsFail=0 i det andra diagrammet) utgör de flesta av exemplen. Använd en översamplingsteknik för att skapa en mer balanserad träningsdatauppsättning:
# Separate features and target
features = df[['Type', 'Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']]
labels = df['IsFail']
# Split the dataset into the training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# Ignore warnings
import warnings
warnings.filterwarnings('ignore')
# Save test data to the lakehouse for use in future sections
table_name = "predictive_maintenance_test_data"
df_test_X = spark.createDataFrame(X_test)
df_test_X.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Översampla för att balansera klasser i träningsdatauppsättningen
Den tidigare analysen visade att datamängden är mycket obalanserad. Denna obalans blir ett problem, eftersom minoritetsklassen har för få exempel för modellen för att effektivt lära sig beslutsgränsen.
SMOTE kan lösa problemet. SMOTE är en ofta använd översamplingsteknik som genererar syntetiska exempel. Den genererar exempel för minoritetsklassen baserat på de euklidiska avstånden mellan datapunkter. Den här metoden skiljer sig från slumpmässig översampling eftersom den skapar nya exempel som inte bara duplicerar minoritetsklassen. Metoden blir en effektivare teknik för att hantera obalanserade datamängder.
# Disable MLflow autologging because you don't want to track SMOTE fitting
import mlflow
mlflow.autolog(disable=True)
from imblearn.combine import SMOTETomek
smt = SMOTETomek(random_state=SEED)
X_train_res, y_train_res = smt.fit_resample(X_train, y_train)
# Plot the counts for both classes
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=pd.DataFrame({'IsFail': y_train_res.values}))
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
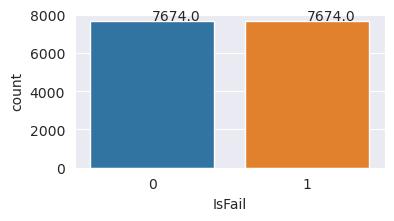
Du har balanserat datamängden. Nu kan du gå över till modellträning.
Steg 4: Träna och utvärdera modellerna
MLflow registrerar modeller, tränar och jämför olika modeller och väljer den bästa modellen i förutsägelsesyfte. Du kan använda följande tre modeller för modellträning:
- Slumpmässig skogsklassificerare
- Logistisk regressionsklassificerare
- XGBoost-klassificerare
Träna en slumpmässig skogsklassificerare
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from mlflow.models.signature import infer_signature
from sklearn.metrics import f1_score, accuracy_score, recall_score
mlflow.set_experiment("Machine_Failure_Classification")
mlflow.autolog(exclusive=False) # This is needed to override the preconfigured autologging behavior
with mlflow.start_run() as run:
rfc_id = run.info.run_id
print(f"run_id {rfc_id}, status: {run.info.status}")
rfc = RandomForestClassifier(max_depth=5, n_estimators=50)
rfc.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
rfc,
"machine_failure_model_rf",
signature=signature,
registered_model_name="machine_failure_model_rf"
)
y_pred_train = rfc.predict(X_train)
# Calculate the classification metrics for test data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = rfc.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
# Print the classification metrics
print("F1 score_test:", f1_test)
print("Accuracy_test:", accuracy_test)
print("Recall_test:", recall_test)
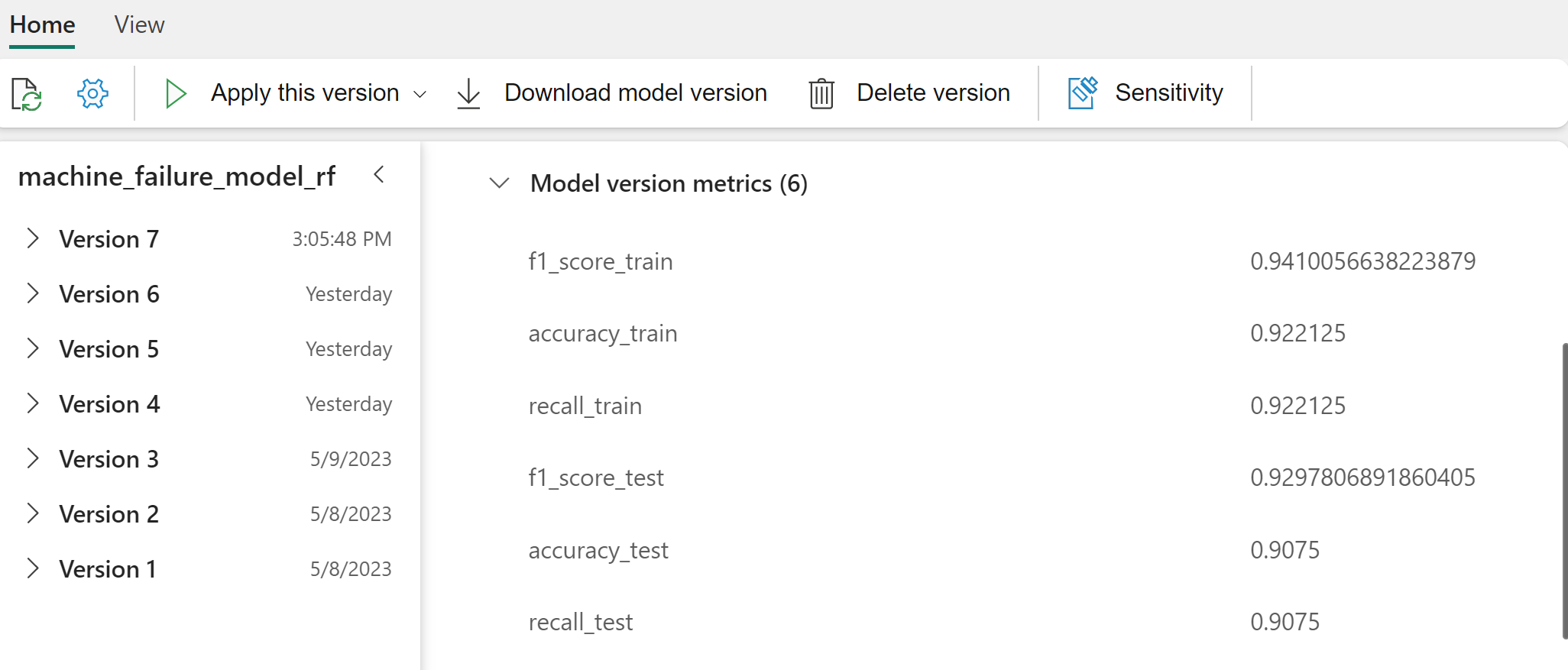
Från utdata ger både tränings- och testdatamängderna en F1-poäng, noggrannhet och återkallande av cirka 0,9 när du använder den slumpmässiga skogsklassificeraren.
Träna en logistisk regressionsklassificerare
from sklearn.linear_model import LogisticRegression
with mlflow.start_run() as run:
lr_id = run.info.run_id
print(f"run_id {lr_id}, status: {run.info.status}")
lr = LogisticRegression(random_state=42)
lr.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
lr,
"machine_failure_model_lr",
signature=signature,
registered_model_name="machine_failure_model_lr"
)
y_pred_train = lr.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = lr.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
Träna en XGBoost-klassificerare
from xgboost import XGBClassifier
with mlflow.start_run() as run:
xgb = XGBClassifier()
xgb_id = run.info.run_id
print(f"run_id {xgb_id}, status: {run.info.status}")
xgb.fit(X_train_res.to_numpy(), y_train_res.to_numpy())
signature = infer_signature(X_train_res, y_train_res)
mlflow.xgboost.log_model(
xgb,
"machine_failure_model_xgb",
signature=signature,
registered_model_name="machine_failure_model_xgb"
)
y_pred_train = xgb.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = xgb.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
Steg 5: Välj den bästa modellen och förutsäga utdata
I föregående avsnitt tränade du tre olika klassificerare: slumpmässig skog, logistisk regression och XGBoost. Nu kan du välja att antingen programmatiskt komma åt resultaten eller använda användargränssnittet (UI).
För alternativet UI-sökväg navigerar du till din arbetsyta och filtrerar modellerna.
Välj enskilda modeller för information om modellprestanda.
Det här exemplet visar hur du programmatiskt kommer åt modellerna via MLflow:
runs = {'random forest classifier': rfc_id,
'logistic regression classifier': lr_id,
'xgboost classifier': xgb_id}
# Create an empty DataFrame to hold the metrics
df_metrics = pd.DataFrame()
# Loop through the run IDs and retrieve the metrics for each run
for run_name, run_id in runs.items():
metrics = mlflow.get_run(run_id).data.metrics
metrics["run_name"] = run_name
df_metrics = df_metrics.append(metrics, ignore_index=True)
# Print the DataFrame
print(df_metrics)
Även om XGBoost ger de bästa resultaten på träningsuppsättningen presterar den dåligt på testdatauppsättningen. Den dåliga prestandan indikerar överanpassning. Den logistiska regressionsklassificeraren presterar dåligt på både tränings- och testdatauppsättningar. På det hela taget skapar slumpmässig skog en bra balans mellan träningsprestanda och undvikande av överanpassning.
I nästa avsnitt väljer du den registrerade slumpmässiga skogsmodellen och utför en förutsägelse med funktionen PREDICT :
from synapse.ml.predict import MLFlowTransformer
model = MLFlowTransformer(
inputCols=list(X_test.columns),
outputCol='predictions',
modelName='machine_failure_model_rf',
modelVersion=1
)
Med det MLFlowTransformer objekt som du skapade för att läsa in modellen för slutsatsdragning använder du Transformer-API:et för att poängsätta modellen på testdatauppsättningen:
predictions = model.transform(spark.createDataFrame(X_test))
predictions.show()
Den här tabellen visar utdata:
| Typ | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | Förutsägelser |
|---|---|---|---|---|---|---|
| 0 | 300.6 | 309.7 | 1639,0 | 30,4 | 121.0 | 0 |
| 0 | 303.9 | 313.0 | 1551.0 | 36,8 | 140.0 | 0 |
| 1 | 299.1 | 308.6 | 1491.0 | 38.5 | 166.0 | 0 |
| 0 | 300.9 | 312.1 | 1359.0 | 51.7 | 146.0 | 1 |
| 0 | 303.7 | 312.6 | 1621.0 | 38,8 | 182.0 | 0 |
| 0 | 299.0 | 310.3 | 1868.0 | 24,0 | 221.0 | 1 |
| 2 | 297.8 | 307.5 | 1631,0 | 31,3 | 124.0 | 0 |
| 0 | 297.5 | 308.2 | 1327.0 | 56.5 | 189.0 | 1 |
| 0 | 301.3 | 310.3 | 1460.0 | 41.5 | 197.0 | 0 |
| 2 | 297.6 | 309.0 | 1413.0 | 40.2 | 51,0 | 0 |
| 1 | 300.9 | 309.4 | 1724.0 | 25,6 | 119.0 | 0 |
| 0 | 303.3 | 311.3 | 1389.0 | 53.9 | 39.0 | 0 |
| 0 | 298.4 | 307.9 | 1981.0 | 23.2 | 16.0 | 0 |
| 0 | 299.3 | 308.8 | 1636.0 | 29,9 | 201.0 | 0 |
| 1 | 298.1 | 309.2 | 1460.0 | 45.8 | 80,0 | 0 |
| 0 | 300.0 | 309.5 | 1728.0 | 26,0 | 37,0 | 0 |
| 2 | 299.0 | 308.7 | 1940.0 | 19.9 | 98.0 | 0 |
| 0 | 302.2 | 310.8 | 1383.0 | 46.9 | 45.0 | 0 |
| 0 | 300.2 | 309.2 | 1431,0 | 51.3 | 57,0 | 0 |
| 0 | 299.6 | 310.2 | 1468,0 | 48,0 | 9.0 | 0 |
Spara data i lakehouse. Data blir sedan tillgängliga för senare användning – till exempel en Power BI-instrumentpanel.
# Save test data to the lakehouse for use in the next section.
table_name = "predictive_maintenance_test_with_predictions"
predictions.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Steg 6: Visa Business Intelligence via visualiseringar i Power BI
Visa resultatet i ett offlineformat med en Power BI-instrumentpanel.
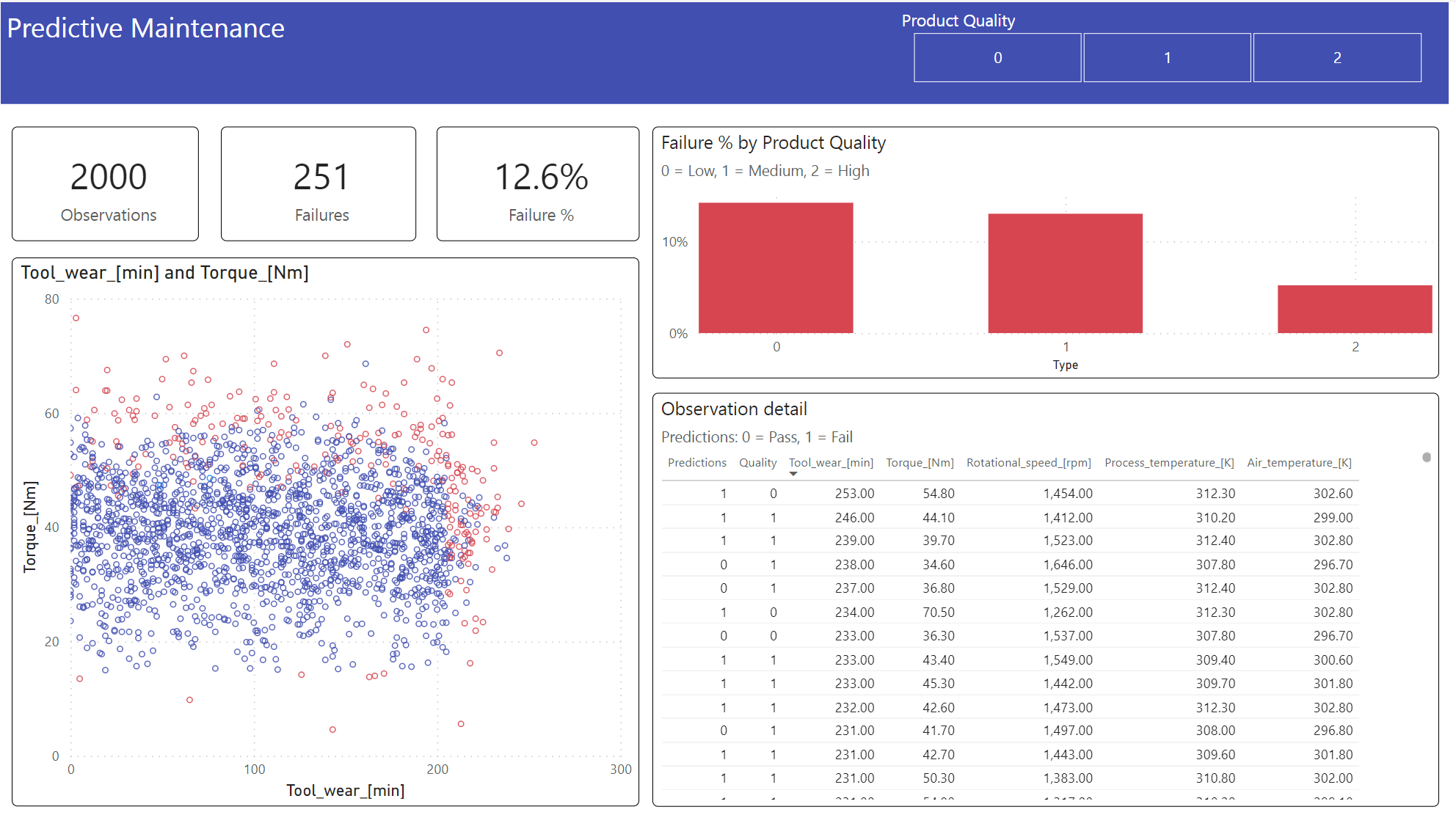
Instrumentpanelen visar det Tool_wear och Torque skapar en märkbar gräns mellan misslyckade och otrogna fall, som förväntat från den tidigare korrelationsanalysen i steg 2.