Självstudie: Skapa, utvärdera och poängsätta en förutsägelsemodell för omsättning
I den här självstudien visas ett exempel från slutpunkt till slutpunkt på ett Synapse-Datavetenskap arbetsflöde i Microsoft Fabric. Scenariot bygger en modell för att förutsäga om bankkundernas omsättning är eller inte. Omsättningsräntan, eller attritionsgraden, innebär den ränta med vilken bankkunder avslutar sin verksamhet med banken.
Den här självstudien beskriver följande steg:
- Installera anpassade bibliotek
- Läsa in data
- Förstå och bearbeta data genom undersökande dataanalys och visa användningen av funktionen Fabric Data Wrangler
- Använd scikit-learn och LightGBM för att träna maskininlärningsmodeller och spåra experiment med funktionerna för autologgning av MLflow och Infrastrukturresurser
- Utvärdera och spara den slutliga maskininlärningsmodellen
- Visa modellprestanda med Power BI-visualiseringar
Förutsättningar
Skaffa en Microsoft Fabric-prenumeration. Eller registrera dig för en kostnadsfri utvärderingsversion av Microsoft Fabric.
Logga in på Microsoft Fabric.
Använd upplevelseväxlaren till vänster på startsidan för att växla till Synapse Datavetenskap upplevelse.

- Om det behövs skapar du ett Microsoft Fabric Lakehouse enligt beskrivningen i Skapa ett sjöhus i Microsoft Fabric.
Följ med i en notebook-fil
Du kan välja något av följande alternativ för att följa med i en notebook-fil:
- Öppna och kör den inbyggda notebook-filen i Datavetenskap-upplevelsen
- Ladda upp din notebook-fil från GitHub till Datavetenskap upplevelse
Öppna den inbyggda notebook-filen
Exempelanteckningsboken kundomsättning medföljer den här självstudien.
Så här öppnar du självstudiekursens inbyggda exempelanteckningsbok i Synapse Datavetenskap upplevelse:
Gå till startsidan för Synapse Datavetenskap.
Välj Använd ett exempel.
Välj motsvarande exempel:
- Från standardfliken för arbetsflöden från slutpunkt till slutpunkt (Python) om exemplet är för en Python-självstudie.
- Från fliken Arbetsflöden från slutpunkt till slutpunkt (R) om exemplet är för en R-självstudie.
- Om exemplet är för en snabb självstudie på fliken Snabbsjälvstudier.
Koppla ett lakehouse till notebook-filen innan du börjar köra kod.
Importera anteckningsboken från GitHub
Notebook-filen AIsample – Bank Customer Churn.ipynb medföljer den här självstudien.
Om du vill öppna den medföljande notebook-filen för den här självstudien följer du anvisningarna i Förbereda systemet för självstudier för datavetenskap för att importera anteckningsboken till din arbetsyta.
Om du hellre vill kopiera och klistra in koden från den här sidan kan du skapa en ny notebook-fil.
Se till att bifoga ett lakehouse i notebook-filen innan du börjar köra kod.
Steg 1: Installera anpassade bibliotek
För utveckling av maskininlärningsmodeller eller ad hoc-dataanalys kan du snabbt behöva installera ett anpassat bibliotek för Apache Spark-sessionen. Du har två alternativ för att installera bibliotek.
- Använd de infogade installationsfunktionerna (
%pipeller%conda) i notebook-filen för att installera ett bibliotek, endast i den aktuella notebook-filen. - Du kan också skapa en Infrastrukturmiljö, installera bibliotek från offentliga källor eller ladda upp anpassade bibliotek till den och sedan kan din arbetsyteadministratör koppla miljön som standard för arbetsytan. Alla bibliotek i miljön blir sedan tillgängliga för användning i alla notebook-filer och Spark-jobbdefinitioner på arbetsytan. Mer information om miljöer finns i skapa, konfigurera och använda en miljö i Microsoft Fabric.
I den här självstudien använder du %pip install för att installera imblearn biblioteket i notebook-filen.
Kommentar
PySpark-kerneln startas om efter %pip install körningar. Installera de bibliotek som behövs innan du kör andra celler.
# Use pip to install libraries
%pip install imblearn
Steg 2: Läs in data
Datamängden i churn.csv innehåller omsättningsstatus för 10 000 kunder, tillsammans med 14 attribut som omfattar:
- Kreditpoäng
- Geografiskt läge (Tyskland, Frankrike, Spanien)
- Kön (man, kvinna)
- Ålder
- Anställningstid (antal år som personen var kund på banken)
- Kontosaldo
- Beräknad lön
- Antal produkter som en kund har köpt via banken
- Kreditkortsstatus (oavsett om en kund har ett kreditkort eller inte)
- Aktiv medlemsstatus (oavsett om personen är en aktiv bankkund eller inte)
Datamängden innehåller även kolumner för radnummer, kund-ID och kundens efternamn. Värden i dessa kolumner bör inte påverka kundens beslut att lämna banken.
En kunds bankkontostängningshändelse definierar omsättningen för den kunden. Datamängdskolumnen Exited refererar till kundens övergivande. Eftersom vi har lite kontext om dessa attribut behöver vi inte bakgrundsinformation om datauppsättningen. Vi vill förstå hur dessa attribut bidrar till statusen Exited .
Av dessa 10 000 kunder lämnade endast 2037 kunder (ungefär 20 %) banken. På grund av förhållandet mellan klassobalanser rekommenderar vi generering av syntetiska data. Förväxlingsmatrisens noggrannhet kanske inte har relevans för obalanserad klassificering. Vi kanske vill mäta noggrannheten med hjälp av området under precisionsåterkallningskurvan (AUPRC).
- Den här tabellen visar en förhandsgranskning av
churn.csvdata:
| CustomerID | Surname | CreditScore | Geografi | Kön | Ålder | Ämbete | Saldo | NumOfProducts | HasCrCard | IsActiveMember | EstimatedSalary | Har slutat |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | Hargrave | 619 | Frankrike | Kvinna | 42 | 2 | 0,00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Hill | 608 | Spanien | Kvinna | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
Ladda ned datauppsättningen och ladda upp till lakehouse
Definiera dessa parametrar så att du kan använda den här notebook-filen med olika datauppsättningar:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
Den här koden laddar ned en offentligt tillgänglig version av datauppsättningen och lagrar sedan datauppsättningen i en Infrastruktursjöhus:
Viktigt!
Lägg till ett lakehouse i anteckningsboken innan du kör det. Om du inte gör det uppstår ett fel.
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Börja spela in den tid som krävs för att köra notebook-filen:
# Record the notebook running time
import time
ts = time.time()
Läsa rådata från lakehouse
Den här koden läser rådata från avsnittet Filer i lakehouse och lägger till fler kolumner för olika datumdelar. När du skapar den partitionerade deltatabellen används den här informationen.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Skapa en Pandas DataFrame från datauppsättningen
Den här koden konverterar Spark DataFrame till en Pandas DataFrame för enklare bearbetning och visualisering:
df = df.toPandas()
Steg 3: Utföra undersökande dataanalys
Visa rådata
Utforska rådata med display, beräkna viss grundläggande statistik och visa diagramvyer. Du måste först importera de bibliotek som krävs för datavisualisering, till exempel seaborn. Seaborn är ett Python-datavisualiseringsbibliotek och tillhandahåller ett högnivågränssnitt för att skapa visuella objekt på dataramar och matriser.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Använda Data Wrangler för att utföra inledande datarensning
Starta Data Wrangler direkt från notebook-filen för att utforska och transformera Pandas-dataramar. På menyfliken Data i anteckningsboken använder du listrutan Data Wrangler för att bläddra bland de aktiverade Pandas DataFrames som är tillgängliga för redigering. Välj den dataram som du vill öppna i Data Wrangler.
Kommentar
Det går inte att öppna Data Wrangler när notebook-kerneln är upptagen. Cellkörningen måste slutföras innan du startar Data Wrangler. Läs mer om Data Wrangler.
När Data Wrangler har lanserats genereras en beskrivande översikt över datapanelen, enligt följande bilder. Översikten innehåller information om dimensionen för DataFrame, eventuella saknade värden osv. Du kan använda Data Wrangler för att generera skriptet för att släppa raderna med saknade värden, duplicerade rader och kolumner med specifika namn. Sedan kan du kopiera skriptet till en cell. Nästa cell visar det kopierade skriptet.
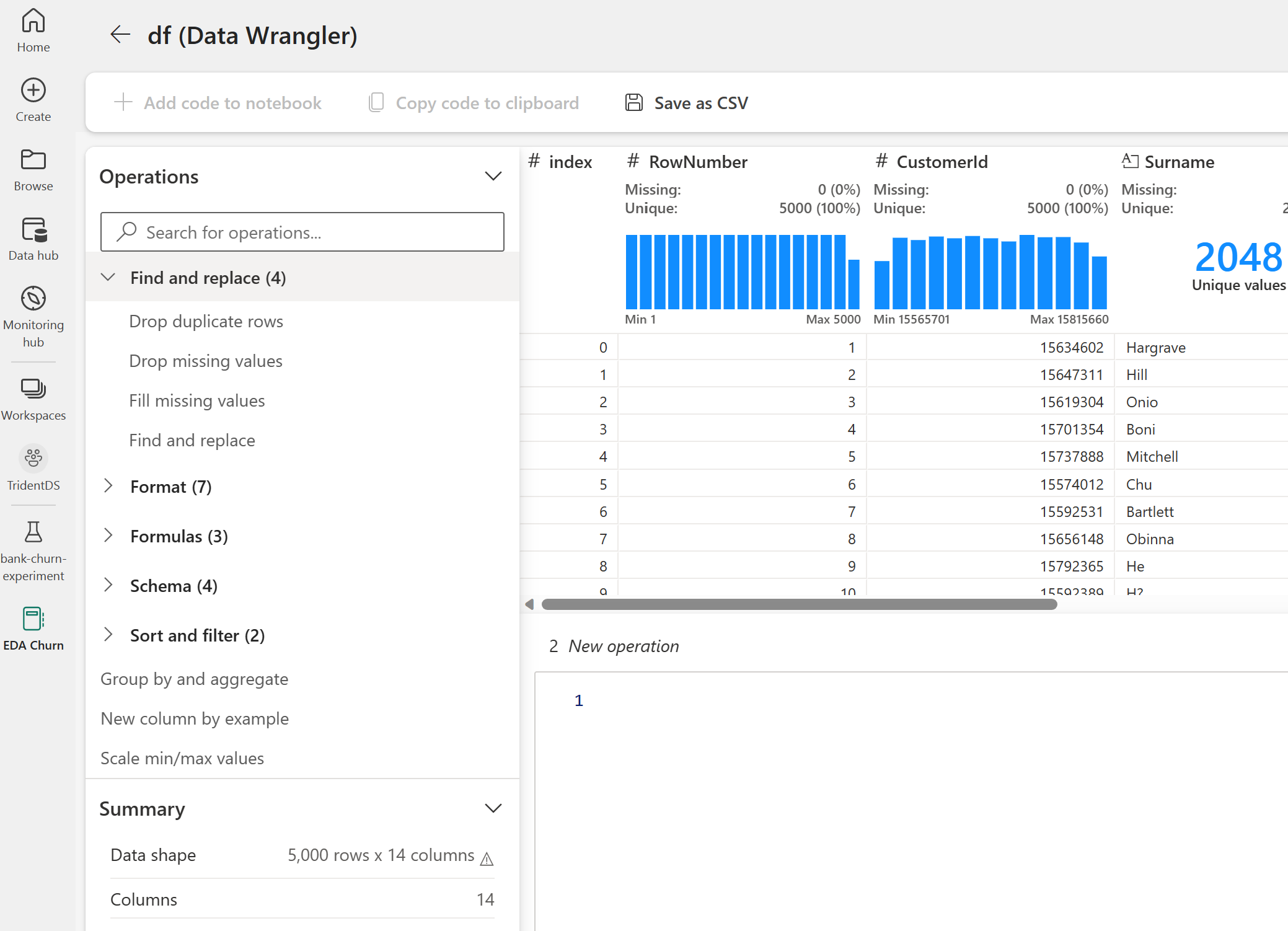
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
Fastställa attribut
Den här koden bestämmer de kategoriska attributen, numeriska attributen och målattributen:
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
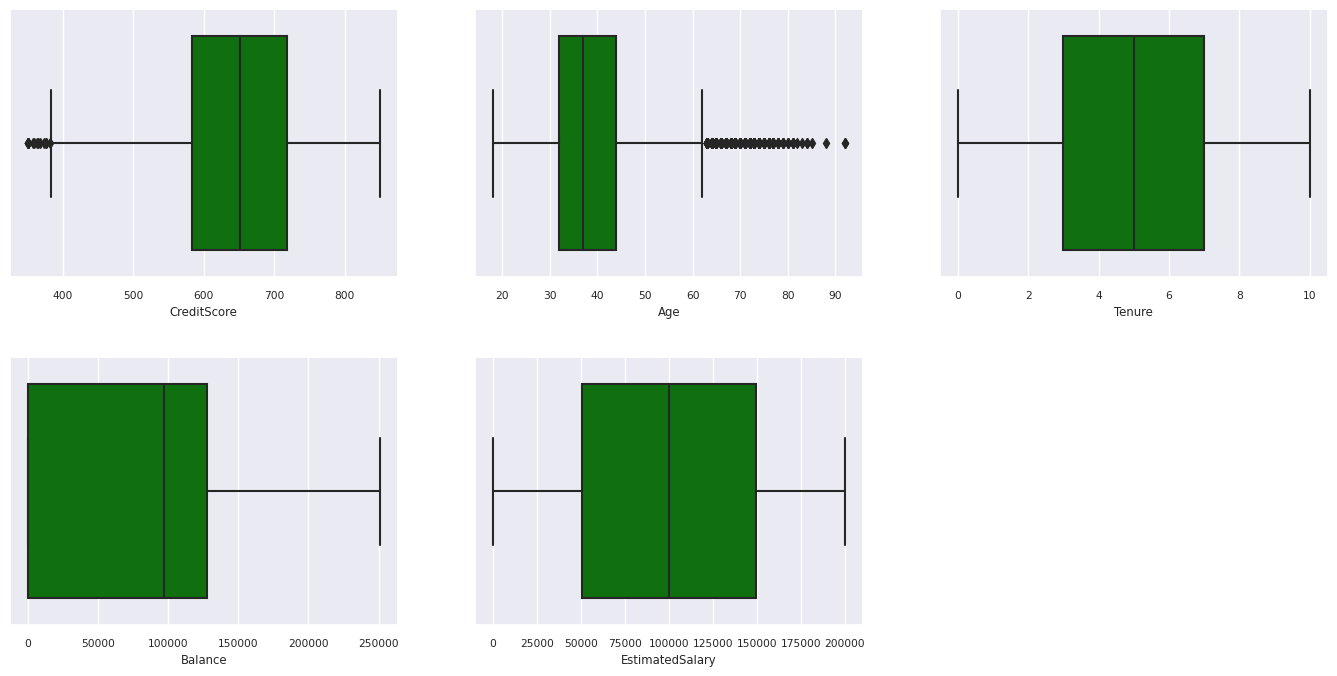
Visa sammanfattningen med fem nummer
Använd lådritningar för att visa sammanfattningen med fem nummer
- minimipoängen
- första kvartilen
- median
- tredje kvartilen
- högsta poäng
för de numeriska attributen.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])
Visa distributionen av utgångna och icke-avslutade kunder
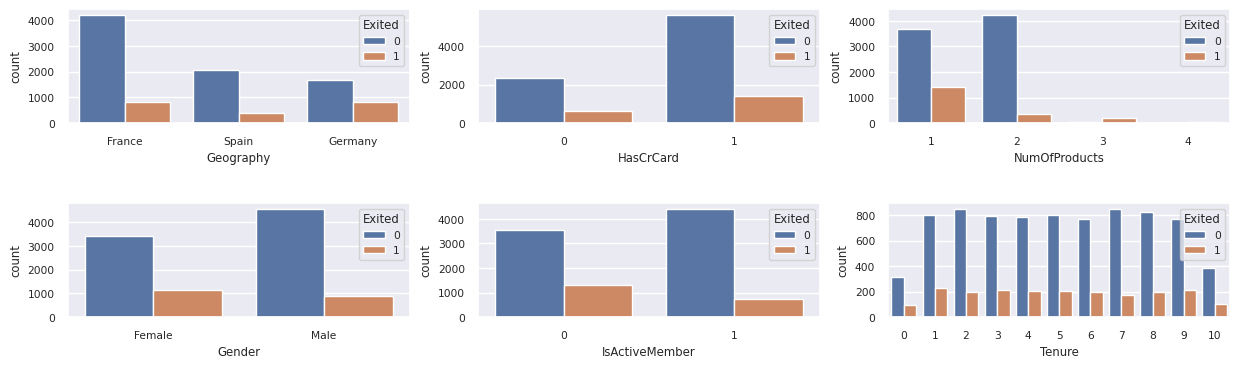
Visa fördelningen av utgångna jämfört med icke-utgångna kunder över de kategoriska attributen:
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
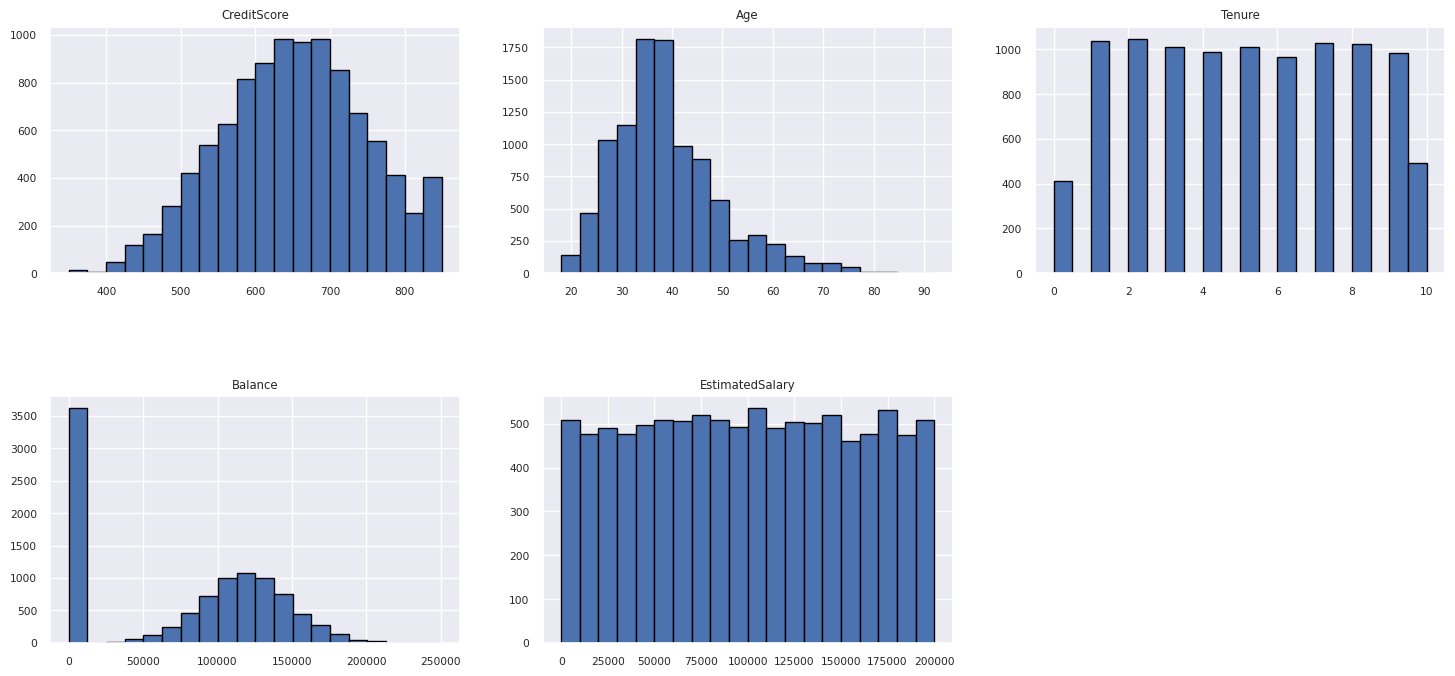
Visa fördelningen av numeriska attribut
Använd ett histogram för att visa frekvensfördelningen för numeriska attribut:
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
Utföra funktionsframställning
Den här funktionstekniken genererar nya attribut baserat på de aktuella attributen:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Använda Data Wrangler för att utföra kodning med en frekvent kodning
Med samma steg för att starta Data Wrangler, som vi nämnde tidigare, använder du Data Wrangler för att utföra kodning med en frekvent kodning. Den här cellen visar det kopierade genererade skriptet för kodning med en frekvent kodning:
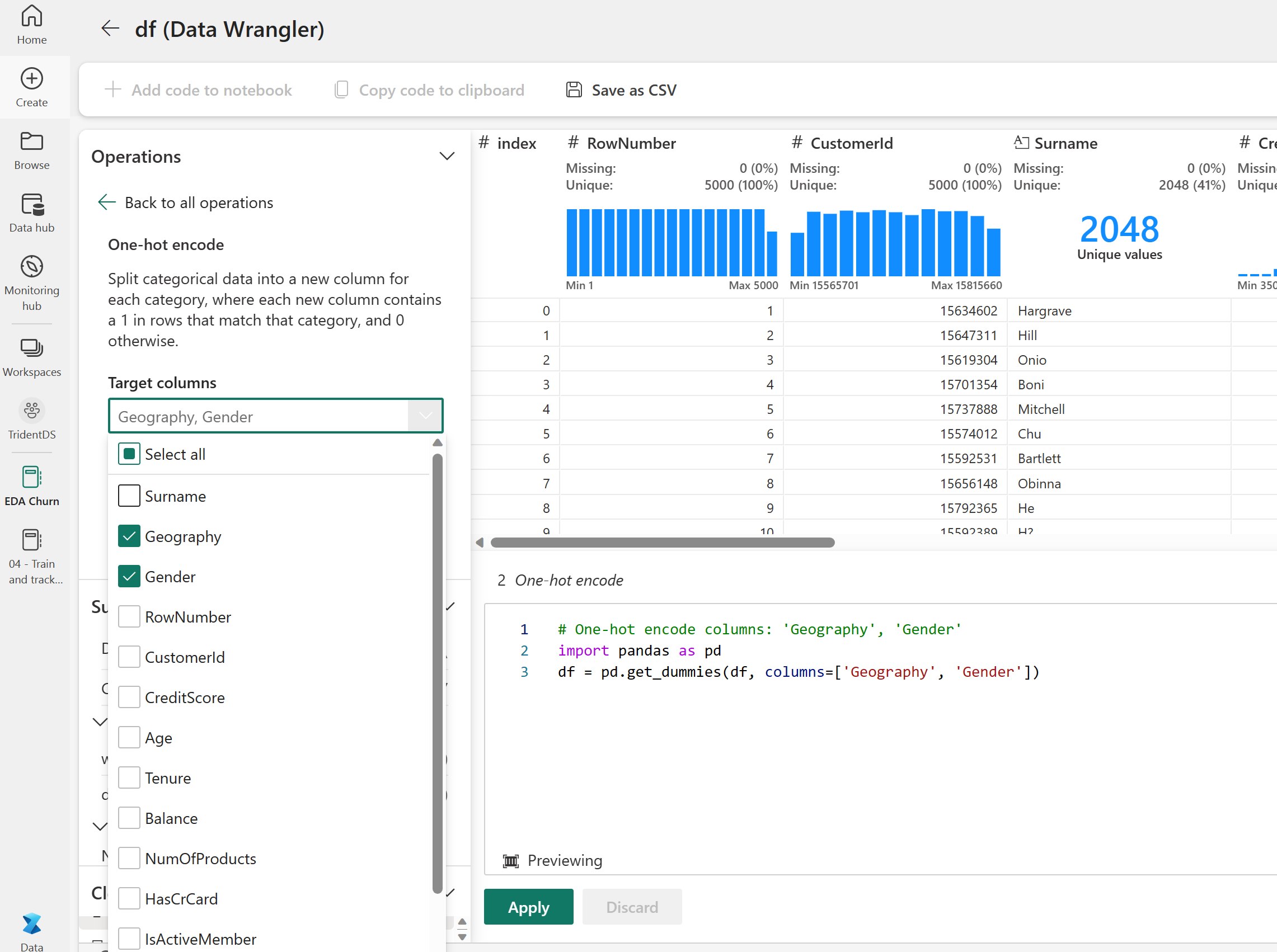
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
Skapa en deltatabell för att generera Power BI-rapporten
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Sammanfattning av observationer från den undersökande dataanalysen
- De flesta av kunderna kommer från Frankrike. Spanien har den lägsta omsättningstakten, jämfört med Frankrike och Tyskland.
- De flesta kunder har kreditkort
- Vissa kunder är båda över 60 år och har kreditpoäng under 400. De kan dock inte betraktas som extremvärden
- Mycket få kunder har fler än två bankprodukter
- Inaktiva kunder har en högre omsättningsfrekvens
- Kön och anställningsår har liten inverkan på en kunds beslut att stänga ett bankkonto
Steg 4: Utföra modellträning och spårning
Med data på plats kan du nu definiera modellen. Använd slumpmässiga skogs- och LightGBM-modeller i den här notebook-filen.
Använd biblioteken scikit-learn och LightGBM för att implementera modellerna med några rader kod. Dessutom kan du använda MLfLow och Fabric Autologging för att spåra experimenten.
Det här kodexemplet läser in deltatabellen från lakehouse. Du kan använda andra deltatabeller som själva använder lakehouse som källa.
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Generera ett experiment för att spåra och logga modellerna med hjälp av MLflow
Det här avsnittet visar hur du genererar ett experiment och anger modell- och träningsparametrarna och bedömningsmåtten. Dessutom visas hur du tränar modellerna, loggar dem och sparar de tränade modellerna för senare användning.
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
Automatisk loggning registrerar automatiskt både indataparametervärdena och utdatamåtten för en maskininlärningsmodell, eftersom modellen tränas. Den här informationen loggas sedan till din arbetsyta, där MLflow-API:erna eller motsvarande experiment på arbetsytan kan komma åt och visualisera den.
När det är klart liknar experimentet den här bilden:
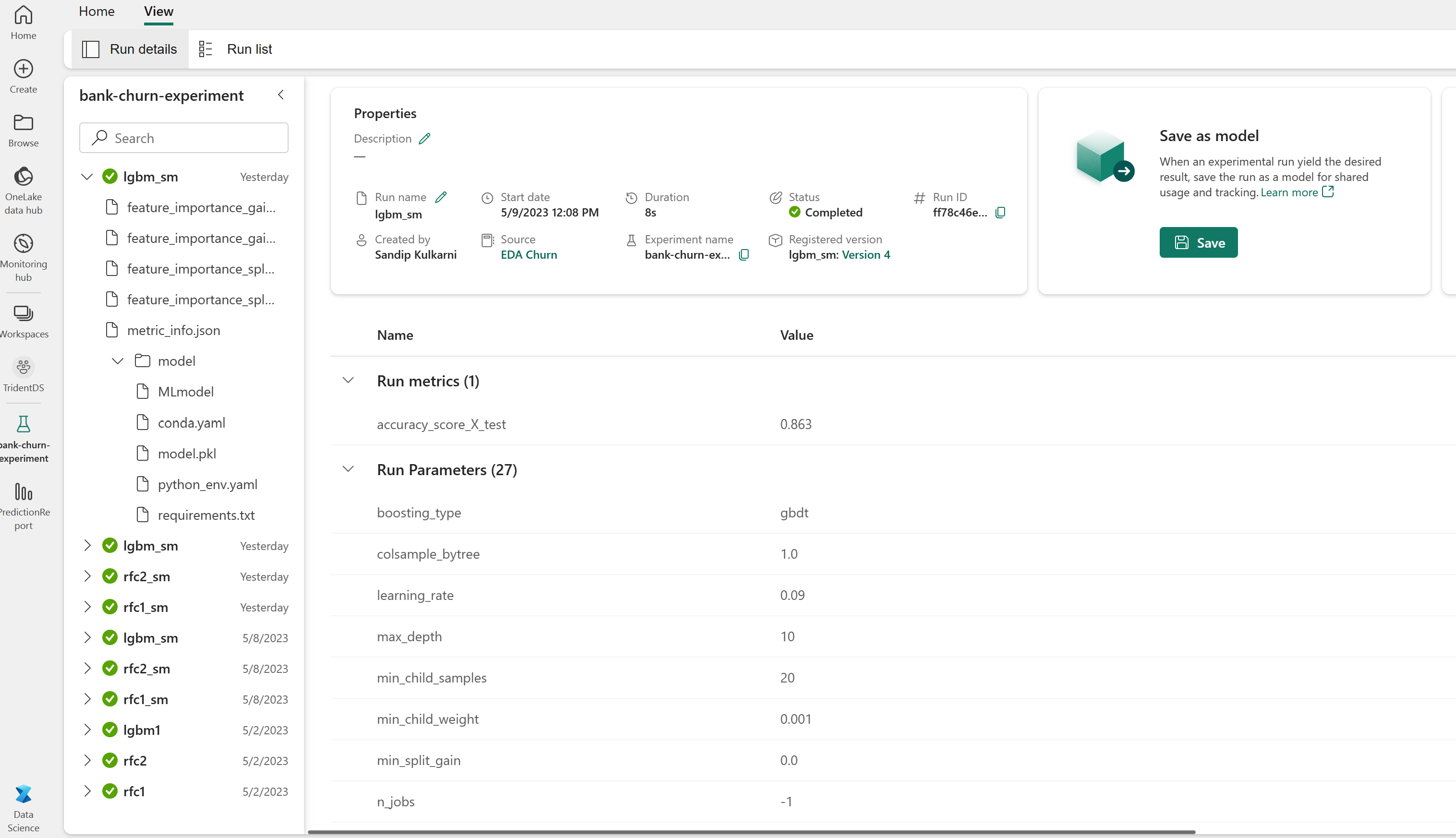
Alla experiment med deras respektive namn loggas och du kan spåra deras parametrar och prestandamått. Mer information om automatisk loggning finns i Autologgning i Microsoft Fabric.
Ange specifikationer för experiment och automatisk loggning
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
Importera scikit-learn och LightGBM
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Förbereda tränings- och testdatauppsättningar
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
Tillämpa SMOTE på träningsdata
Obalanserad klassificering har ett problem eftersom den har för få exempel på minoritetsklassen för att en modell effektivt ska kunna lära sig beslutsgränsen. För att hantera detta är Synthetic Minority Oversampling Technique (SMOTE) den mest använda tekniken för att syntetisera nya exempel för minoritetsklassen. Få åtkomst till SMOTE med det imblearn bibliotek som du installerade i steg 1.
Använd endast SMOTE på träningsdatauppsättningen. Du måste lämna testdatamängden i den ursprungliga obalanserade fördelningen för att få en giltig uppskattning av modellens prestanda på de ursprungliga data. Det här experimentet representerar situationen i produktionen.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Mer information finns i SMOTE och Från slumpmässig översampling till SMOTE och ADASYN. Webbplatsen imbalanced-learn är värd för dessa resurser.
Träna modellen
Använd Random Forest för att träna modellen med ett maximalt djup på fyra och med fyra funktioner:
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
Använd Random Forest för att träna modellen med ett maximalt djup på åtta och med sex funktioner:
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
Träna modellen med LightGBM:
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Visa experimentartefakten för att spåra modellprestanda
Experimentkörningarna sparas automatiskt i experimentartefakten. Du hittar artefakten på arbetsytan. Ett artefaktnamn baseras på det namn som används för att ange experimentet. Alla tränade modeller, deras körningar, prestandamått och modellparametrar loggas på experimentsidan.
Så här visar du dina experiment:
- Välj din arbetsyta i den vänstra panelen.
- Leta upp och välj experimentnamnet, i det här fallet sample-bank-churn-experiment.
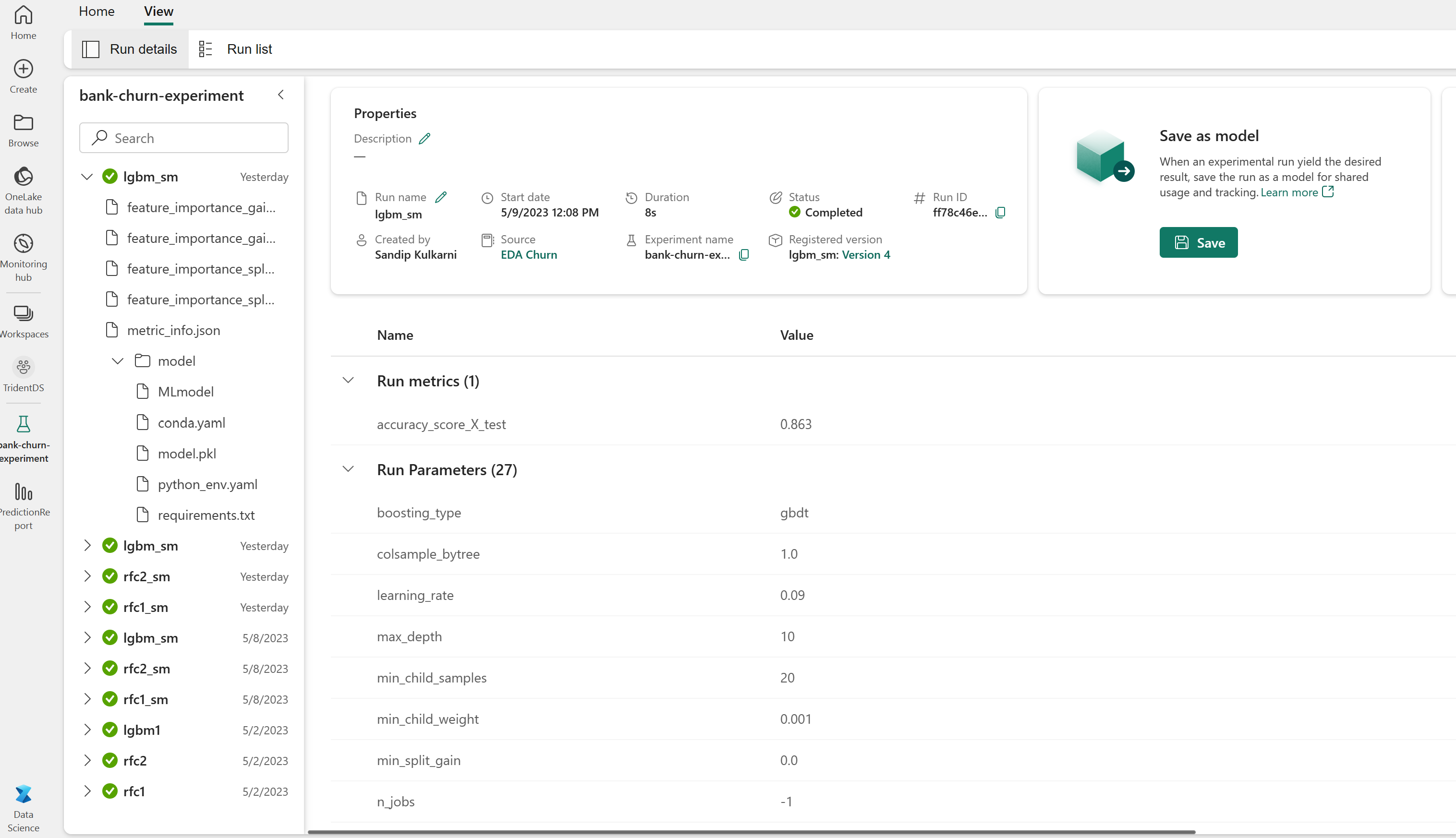
Steg 5: Utvärdera och spara den slutliga maskininlärningsmodellen
Öppna det sparade experimentet från arbetsytan för att välja och spara den bästa modellen:
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
Utvärdera prestanda för de sparade modellerna på testdatauppsättningen
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
Visa true/false positives/negatives med hjälp av en förvirringsmatris
Om du vill utvärdera klassificeringens noggrannhet skapar du ett skript som ritar förvirringsmatrisen. Du kan också rita en förvirringsmatris med hjälp av SynapseML-verktyg, som du ser i exemplet Bedrägeriidentifiering.
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
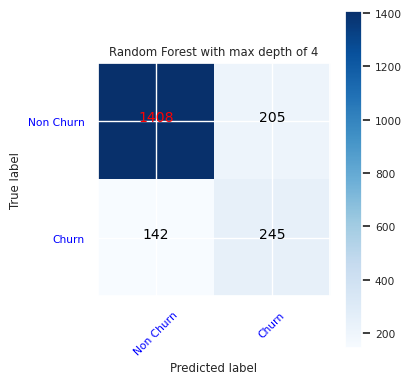
Skapa en förvirringsmatris för den slumpmässiga skogsklassificeraren, med ett maximalt djup på fyra, med fyra funktioner:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
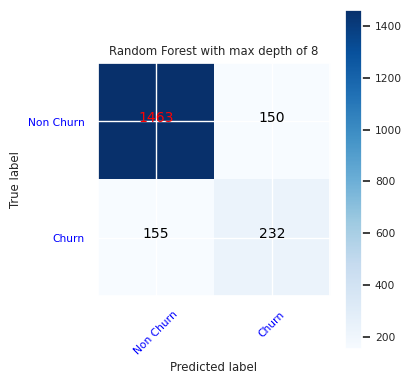
Skapa en förvirringsmatris för den slumpmässiga skogsklassificeraren med maximalt åtta djup, med sex funktioner:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
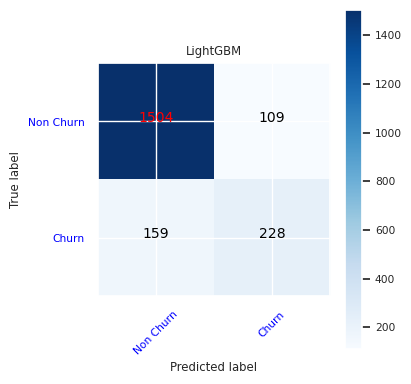
Skapa en förvirringsmatris för LightGBM:
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()
Spara resultat för Power BI
Spara deltaramen i lakehouse för att flytta modellförutsägelseresultatet till en Power BI-visualisering.
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Steg 6: Få åtkomst till visualiseringar i Power BI
Få åtkomst till den sparade tabellen i Power BI:
- Till vänster väljer du OneLake-datahubben
- Välj det lakehouse som du har lagt till i den här notebook-filen
- I avsnittet Öppna den här Lakehouse väljer du Öppna
- I menyfliksområdet väljer du Ny semantisk modell. Välj
df_pred_resultsoch välj sedan Fortsätt för att skapa en ny Power BI-semantisk modell som är länkad till förutsägelserna - Välj Ny rapport från verktygen överst på sidan semantiska modeller för att öppna redigeringssidan för Power BI-rapporten
Följande skärmbild visar några exempelvisualiseringar. Datapanelen visar de deltatabeller och kolumner som ska väljas från en tabell. När du har valt lämplig kategoriaxel (x) och värdeaxel (y) kan du välja filter och funktioner – till exempel summa eller medelvärde för tabellkolumnen.
Kommentar
I den här skärmbilden beskriver det illustrerade exemplet analysen av de sparade förutsägelseresultaten i Power BI:
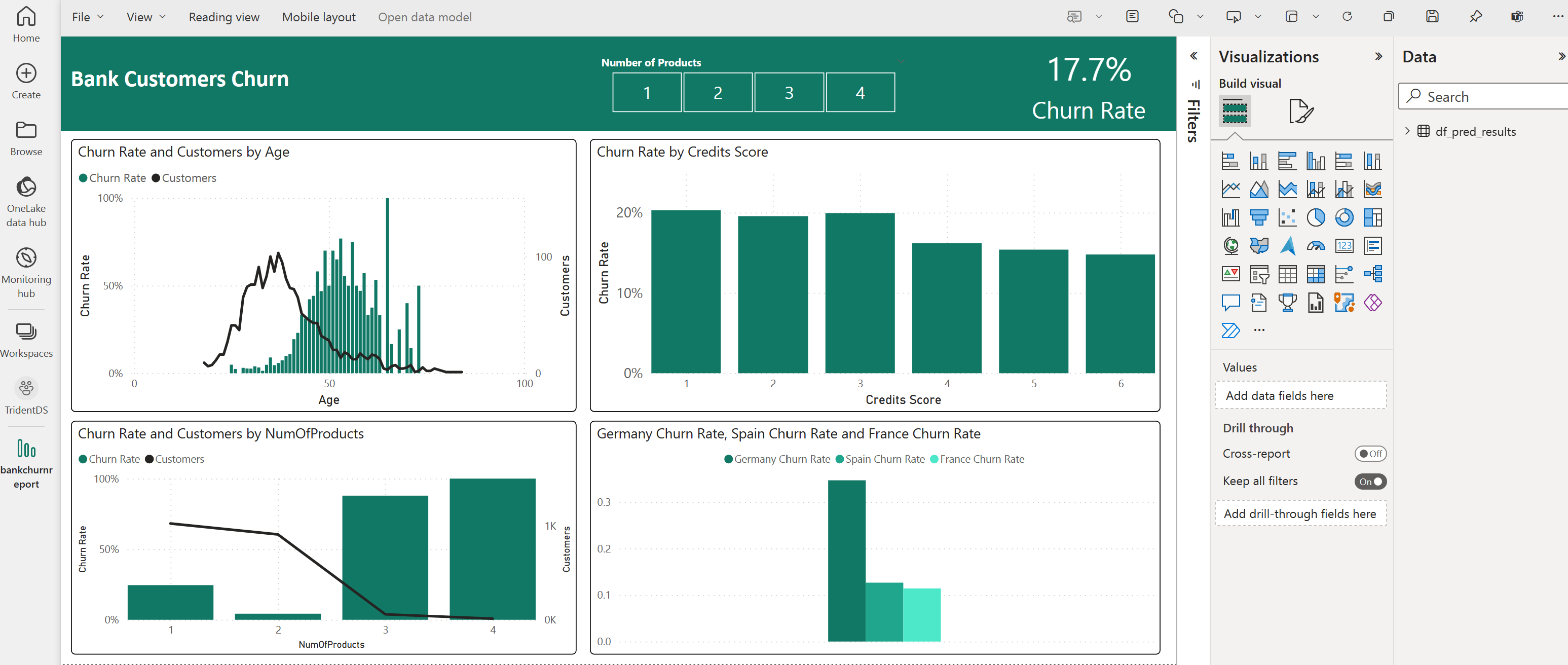
För ett verkligt användningsfall för kundomsättning kan användaren dock behöva en mer grundlig uppsättning krav för visualiseringarna för att skapa, baserat på ämnesexpertis, och vad företagets och företagsanalysteamet och företaget har standardiserat som mått.
Power BI-rapporten visar att kunder som använder mer än två av bankprodukterna har en högre omsättningsfrekvens. Få kunder hade dock mer än två produkter. (Se diagrammet i den nedre vänstra panelen.) Banken bör samla in mer data, men bör också undersöka andra funktioner som korrelerar med fler produkter.
Bankkunder i Tyskland har en högre omsättningsfrekvens jämfört med kunder i Frankrike och Spanien. (Se diagrammet i den nedre högra panelen). Baserat på rapportresultaten kan en undersökning av de faktorer som uppmuntrade kunderna att lämna företaget hjälpa.
Det finns fler medelålders kunder (mellan 25 och 45). Kunder mellan 45 och 60 tenderar att avsluta fler.
Slutligen skulle kunder med lägre kreditpoäng sannolikt lämna banken för andra finansinstitut. Banken bör utforska sätt att uppmuntra kunder med lägre kreditpoäng och kontosaldon att stanna hos banken.
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")