Transformera data genom att köra en notebook-fil
Med notebook-aktiviteten i pipeline kan du köra Notebook som skapats i Microsoft Fabric. Du kan skapa en Notebook-aktivitet direkt via användargränssnittet för Infrastruktur. Den här artikeln innehåller en stegvis genomgång som beskriver hur du skapar en Notebook-aktivitet med hjälp av Data Factory-användargränssnittet.
Lägga till en notebook-aktivitet i en pipeline
I det här avsnittet beskrivs hur du använder en Notebook-aktivitet i en pipeline.
Förutsättningar
För att komma igång måste du uppfylla följande krav:
- Ett klientkonto med en aktiv prenumeration. Skapa ett konto utan kostnad.
- En arbetsyta skapas.
- En notebook-fil skapas på din arbetsyta. Information om hur du skapar en ny notebook-fil finns i Så här skapar du Microsoft Fabric-notebook-filer.
Skapa aktiviteten
Skapa en ny pipeline på din arbetsyta.
Sök efter Notebook i fönstret Pipelineaktiviteter och välj den för att lägga till den i pipelinearbetsytan.
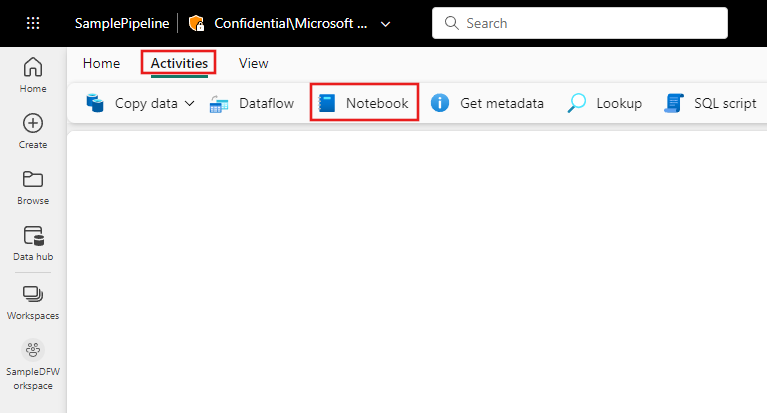
Välj den nya notebook-aktiviteten på arbetsytan om den inte redan är markerad.
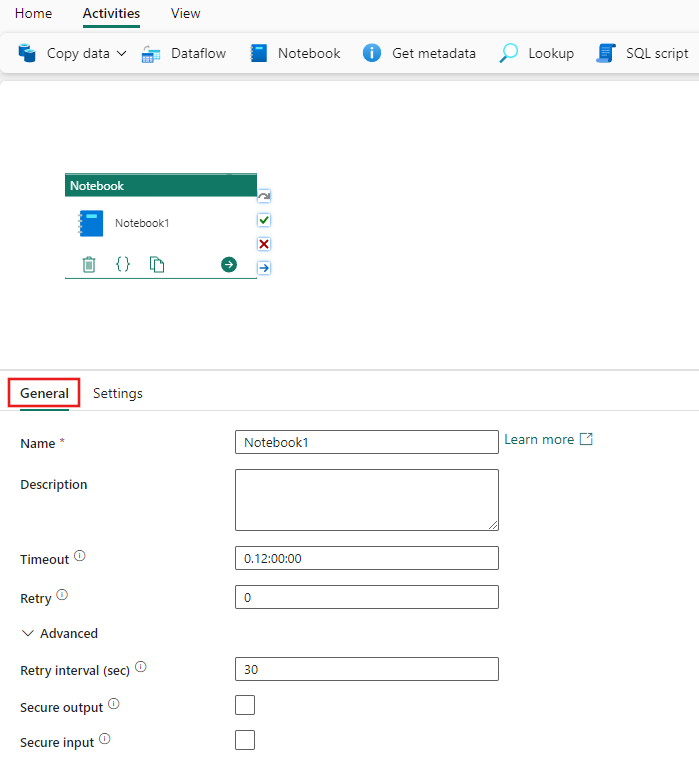
Se vägledningen allmänna inställningar för att konfigurera fliken Allmänna inställningar.
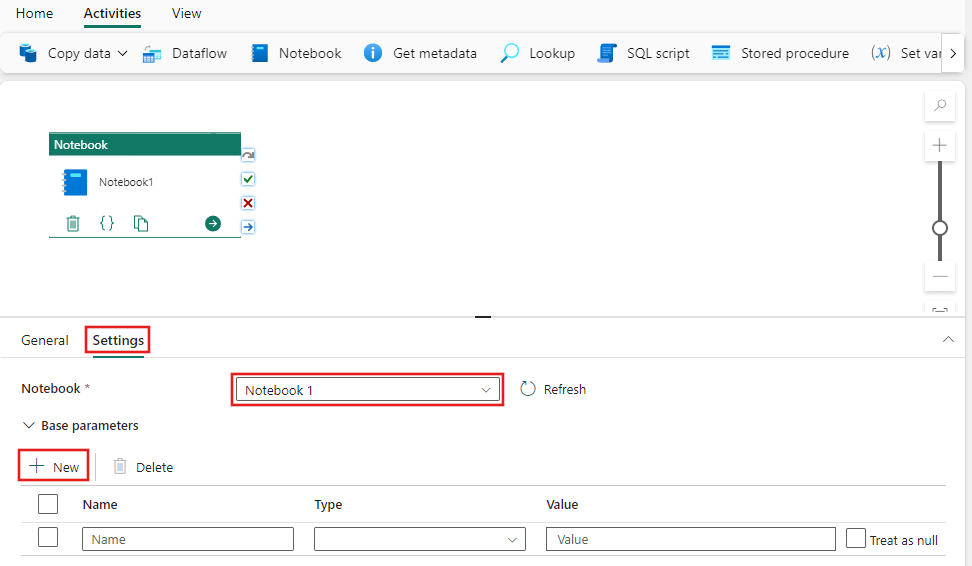
Inställningar för notebook-filer
Välj fliken Inställningar, välj en befintlig anteckningsbok i listrutan Notebook och ange eventuella parametrar som ska skickas till notebook-filen.
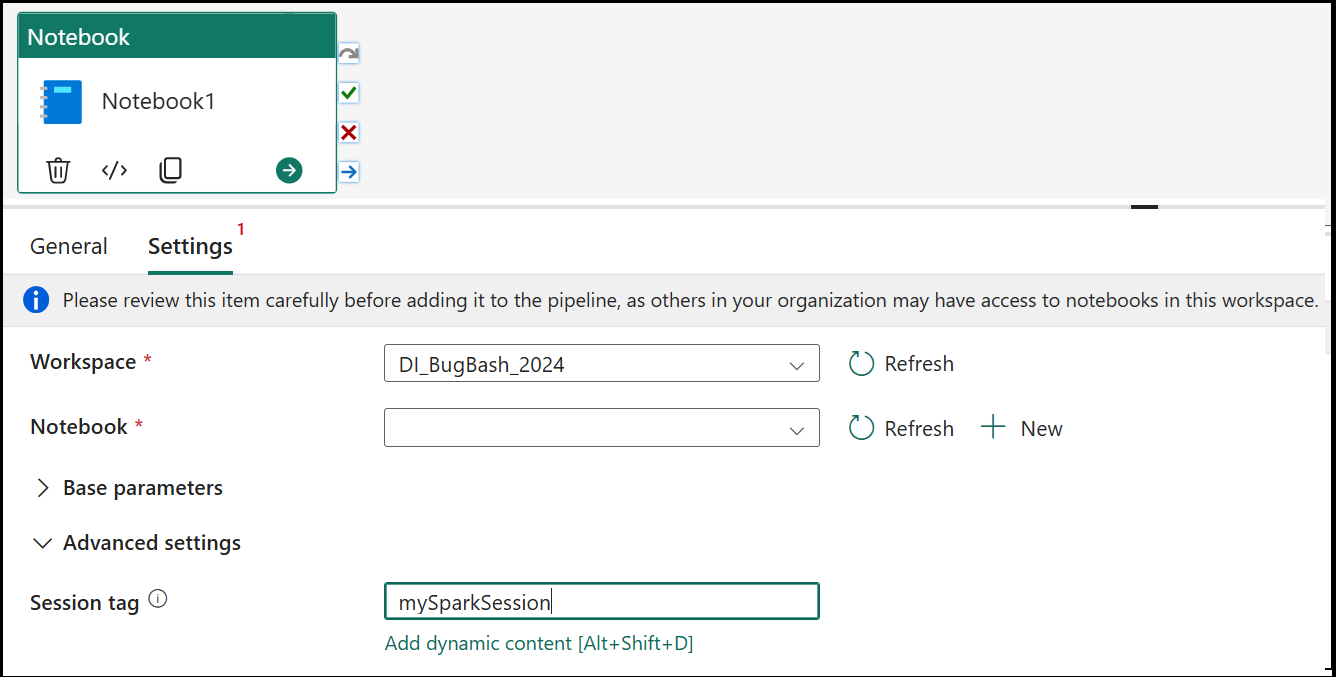
Sessionstagg
För att minimera hur lång tid det tar att köra notebook-jobbet kan du ange en sessionstagg. Om du anger sessionstaggen instrueras Spark att återanvända alla befintliga Spark-sessioner, vilket minimerar starttiden. Valfritt godtyckligt strängvärde kan användas för sessionstaggen. Om det inte finns någon session skapas en ny med taggvärdet.
Kommentar
För att kunna använda sessionstaggen måste alternativet Hög samtidighet för pipeline som kör flera notebook-filer vara aktiverat. Det här alternativet finns i läget Hög samtidighet för Spark-inställningar under arbetsyteinställningarna

Spara och köra eller schemalägga pipelinen
Växla till fliken Start överst i pipelineredigeraren och välj knappen Spara för att spara din pipeline. Välj Kör för att köra den direkt eller Schemalägg för att schemalägga den. Du kan också visa körningshistoriken här eller konfigurera andra inställningar.
