Apache Spark-rådgivare för råd i realtid om notebook-filer
Apache Spark-rådgivaren analyserar kommandon och kod som körs av Apache Spark och visar råd i realtid för Notebook-körningar. Apache Spark-rådgivaren har inbyggda mönster som hjälper användarna att undvika vanliga misstag. Den ger rekommendationer för kodoptimering, utför felanalys och letar upp rotorsaken till fel.
Inbyggda råd
Spark-rådgivaren, ett verktyg som är integrerat med Impulse, tillhandahåller inbyggda mönster för att identifiera och lösa problem i Apache Spark-program. I den här artikeln beskrivs några av de mönster som ingår i verktyget.
Du kan öppna fönstret Senaste körningar baserat på vilken typ av råd du behöver.
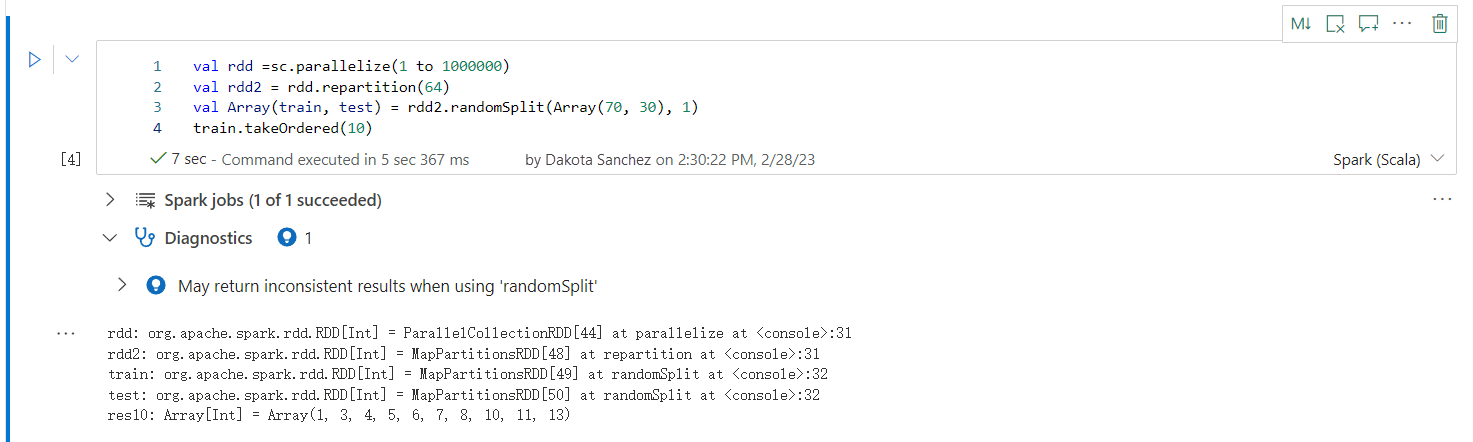
Kan returnera inkonsekventa resultat när du använder "randomSplit"
Inkonsekventa eller felaktiga resultat kan returneras när du arbetar med metoden randomSplit . Använd Apache Spark-cachelagring (RDD) innan du använder metoden randomSplit().
Metoden randomSplit() motsvarar att utföra sample() på dataramen flera gånger. Där varje exempel förfinar, partitioner och sorterar din dataram i partitioner. Datadistributionen mellan partitioner och sorteringsordningen är viktig för både randomSplit() och sample(). Om du antingen ändrar på datareplicering kan det finnas dubbletter eller saknade värden mellan delningar. Och samma exempel som använder samma frö kan ge olika resultat.
Dessa inkonsekvenser kanske inte inträffar vid varje körning, men för att eliminera dem helt cachelagrar du dataramen, partitionerar om en kolumn eller använder aggregeringsfunktioner som groupBy.
Tabell-/vynamn används redan
Det finns redan en vy med samma namn som den skapade tabellen, eller så finns det redan en tabell med samma namn som den skapade vyn. När det här namnet används i frågor eller program returneras endast vyn oavsett vilken som skapades först. För att undvika konflikter byter du namn på antingen tabellen eller vyn.
Det går inte att identifiera ett tips
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
Det går inte att hitta ett angivet relationsnamn
Det går inte att hitta de relationer som anges i tipset. Kontrollera att relationerna är rättstavade och tillgängliga inom omfånget för tipset.
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Ett tips i frågan förhindrar att ett annat tips tillämpas
Den valda frågan innehåller ett tips som förhindrar att ett annat tips tillämpas.
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Aktivera "spark.advise.divisionExprConvertRule.enable" för att minska spridningen av avrundningsfel
Den här frågan innehåller uttrycket med dubbel typ. Vi rekommenderar att du aktiverar konfigurationen "spark.advise.divisionExprConvertRule.enable", vilket kan bidra till att minska divisionsuttrycken och minska spridningen av avrundningsfel.
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
Aktivera "spark.advise.nonEqJoinConvertRule.enable" för att förbättra frågeprestanda
Den här frågan innehåller tidskrävande koppling på grund av villkoret "Eller" i frågan. Vi rekommenderar att du aktiverar konfigurationen "spark.advise.nonEqJoinConvertRule.enable", vilket kan hjälpa till att konvertera kopplingen som utlöses av "Or"-villkoret till SMJ eller BHJ för att påskynda frågan.
Användarupplevelse
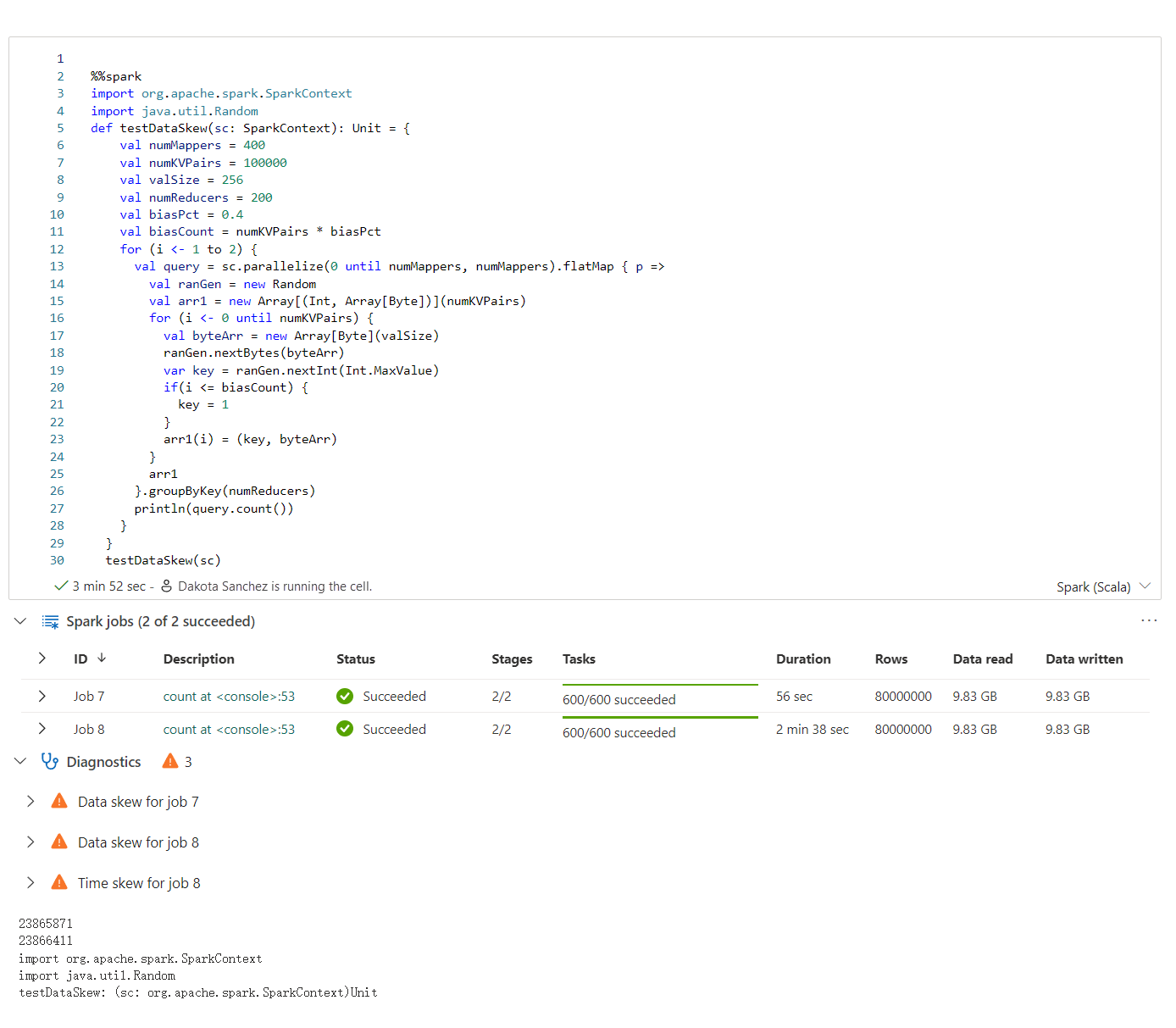
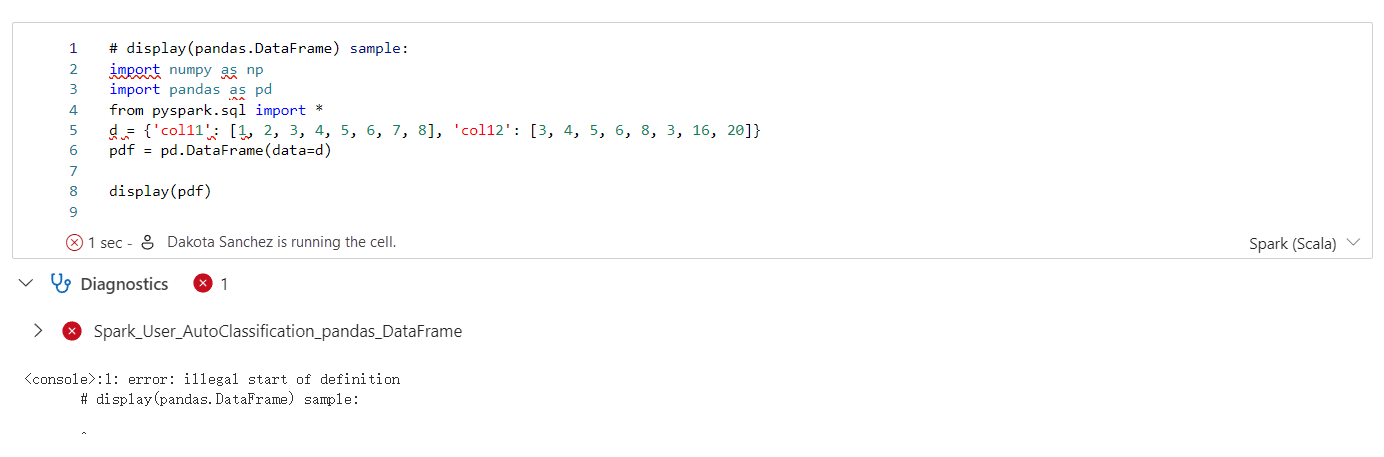
Apache Spark-rådgivaren visar råd, inklusive information, varningar och fel, vid Notebook-cellutdata i realtid.
Information om
Varning
Fel
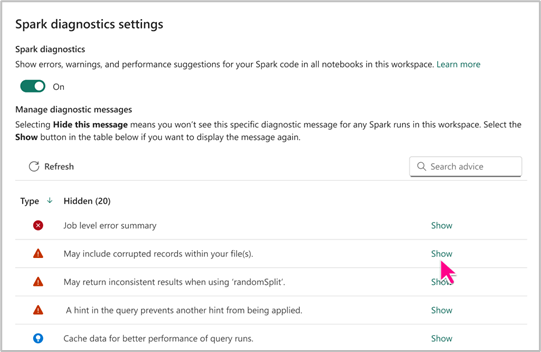
Inställning för Spark Advisor
Med inställningen Spark Advisor kan du välja om du vill visa eller dölja specifika typer av Spark-råd efter dina behov. Dessutom har du flexibiliteten att aktivera eller inaktivera Spark Advisor för dina notebook-filer på en arbetsyta baserat på dina inställningar.
Du kan komma åt Spark Advisor-inställningarna på fabric Notebook-nivån för att dra nytta av dess fördelar och säkerställa en produktiv redigeringsupplevelse för notebook-filer.